运算电路以及运算方法与流程
本公开涉及运算电路以及运算方法,例如涉及适用于使用多个运算器并行地实施的运算的运算电路以及运算方法。
背景技术:
在图像处理、声纹分析、机器人技术等进行模式识别的大量的领域中,经常使用被称为卷积神经网络(cnn:convolutionalneuralnetwork)的运算方法。一般,cnn包括进行卷积运算的卷积层、计算局部统计量的池化层(poolinglayer)、以及全连接层(fullyconnectedlayer)。卷积层通过一边在输入特征映像上以像素单位扫描内核(还被称为滤波器),一边反复进行输入特征映像的对应部分与内核的积和运算(multiply-and-addoperation),对最终的积和运算结果进行非线性变换,生成输出特征映像。
这些层中的主要的运算是0值要素多的大规模的矩阵(a)与矢量(x)之积、以及偏置(b)的和的运算(ax+b)。以往,通过利用使用多个运算器的并行处理装置处理运算,缩短运算所花费的时间。
作为使0值要素多的大规模的矩阵(a)和矢量(x)的运算高速化的技术,例如,日本特开2009-251724号公报(专利文献1)公开具有多个运算流水线的矢量处理器。该矢量处理器在成为1个矢量运算命令的运算对象的数据数并非流水线数的整数倍的情况下,使未执行命令的流水线执行接下来的矢量运算命令。由此,实施并行处理的高速化。
另外,日本特开2003-67360号公报(专利文献2)公开以预定的地址顺序读出n个数据并进行积和运算的积和运算装置。该积和运算装置在n个数据包含值0的情况下,在生成储存数据的存储装置的地址时,不生成与作为值0的数据对应的地址。由此,不实施作为值0的数据的积和运算,运算量被削减,实现运算的高速化。
现有技术文献
专利文献
专利文献1:日本特开2009-251724号公报
专利文献2:日本特开2003-67360号公报
技术实现要素:
具有多个运算器的并行运算装置中的矩阵(a)和矢量(x)的积的运算处理基本上大致分为(i)各运算器从外部的装置取入成为运算的对象的矩阵(a)的要素和偏置(b)、输入的矢量(x)的处理、(ii)多个运算器使用取入的数据并行地执行运算的处理、以及(iii)各运算器将运算的结果输出到外部的装置的处理来构成。
根据这样的结构,在并行运算的并行性高时,运算处理时间被缩短,所以易于同时发生从各运算器向外部装置的访问的要求。在同时发生多个访问要求的情况下,需要对来自各运算器的访问要求附加顺序而重新排列等调解,来自外部的装置的数据输入处理(i)和数据输出处理(iii)的处理时间未缩短。因此,尽管并行运算处理被高速化,但是整体的处理时间受到数据输入处理(i)和数据输出处理(iii)的限制,作为结果,无法将整体的处理时间缩短到想象的程度。
专利文献1公开并行运算处理的高速化的技术,但未公开与上述叙述的数据输入处理(i)或者数据输出处理(iii)的处理时间的缩短有关的技术。
另外,专利文献2公开通过不生成与作为值0的数据对应的地址而使运算高速化的技术,但未公开与并行运算处理中的上述叙述的数据输入处理(i)或者数据输出处理(iii)的处理时间的缩短有关的技术。
本公开是考虑上述课题而完成的,其目的在于提供一种能够缩短整体的处理时间的运算电路以及运算方法。
一个实施方式的运算电路具备:并行运算电路,包括构成为对包含非零要素和零要素的系数矩阵从右乘以输入矢量,并将运算结果输出到输出矢量的多个运算器;以及输入接口,包括多个存储电路。运算电路对各运算器,按照应运算的顺序,供给应由该运算器运算的矢量的要素。多个运算器与多个存储电路分别对应。各存储电路具有:输入存储电路,存储输入矢量的要素;以及系数存储电路,具备环形缓冲器,并且,在该环形缓冲器中储存构成系数矩阵的行或者列矢量的要素。输入矢量的要素以及系数矩阵的要素具有指定应乘以该要素的顺序的索引。输入接口构成为将输入矢量和系数矩阵的各要素,根据该要素具有的索引,分别依照顺序,储存到与多个运算器中的1个运算器对应的输入存储电路和系数存储电路的环形缓冲器。各运算器构成为依次执行存储电路的系数矩阵的行或者列矢量的要素和输入矢量的对应的要素的乘法,根据该要素的索引,将该乘法的结果累计到输出矢量的对应的要素。
根据上述实施方式,将输入矢量的要素或者构成系数矩阵的行或者列矢量的要素,根据该要素具有的索引,按照应运算的顺序,储存到与多个运算器中的1个运算器对应的输入存储电路和系数存储电路的环形缓冲器。由此,能够在各运算器实施运算之前,经由输入存储电路或者系数存储电路,按照应运算的顺序,仅准备该运算器的运算所需的输入矢量的要素和构成系数矩阵的行或者列矢量的要素。因此,不需要要素的重排处理,能够缩短并行运算所花费的整体的处理时间。
另外,构成系数矩阵的行或者列矢量的要素被储存到环形缓冲器,所以在反复一边使输入矢量变化一边使用系数矩阵的同一行或者列矢量的要素的运算的情况下,能够在各运算的开始时省略使系数存储电路初始化的处理。另外,通过省略初始化处理,能够缩短并行运算所花费的整体的处理时间。
附图说明
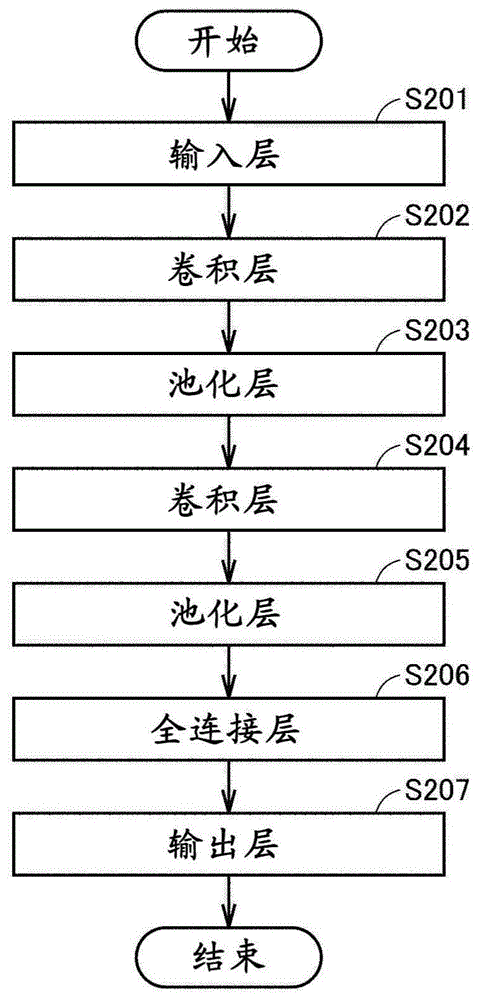
图1是示出利用cnn的运算处理的流程图。
图2是用于说明卷积运算的图。
图3是用于说明特征映像以及内核的展开的图。
图4是将本实施方式1所涉及的运算电路12的结构的一个例子与周边电路关联起来示出的图。
图5是将图4的运算器clk和输入输出数据关联起来说明的图。
图6是示出本实施方式1所涉及的输入i/f和输出i/f的结构的图。
图7是示出本实施方式1所涉及的输入存储电路、输出存储电路、以及系数存储电路的结构的一个例子的图。
图8是示意性地说明本实施方式1所涉及的存储方式的图。
图9是示出本实施方式1所涉及的输入变换电路的结构的一个例子的图。
图10是示出本实施方式1所涉及的输出变换电路的结构的一个例子的图。
图11是示出图5所示的运算器clk和应运算的要素的关联的具体例的图。
图12是说明本实施方式1所涉及的并行处理的流程图。
图13是示出本实施方式2所涉及的运算电路12a的输入i/f和输出i/f的结构的图。
图14是示出图13的输入通知电路133c的结构的图。
图15是示出本实施方式3所涉及的运算电路12b的输入i/f和输出i/f的结构的图。
图16是将图15的输出通知电路143的结构与周边电路关联起来示出的图。
图17是示出本实施方式4所涉及的运算电路12b的输入i/f和输出i/f的结构的图。
图18是示出本实施方式5所涉及的运算电路12d的输入i/f和输出i/f的结构的图。
图19是示出本实施方式6所涉及的运算电路12e的输入i/f和输出i/f的结构的图。
图20是示出本实施方式7所涉及的运算电路12f的输入i/f和输出i/f的结构的图。
图21是示出本实施方式8所涉及的运算电路的结构的图。
图22是示出本实施方式9所涉及的运算电路的结构的图。
图23是示出本实施方式10所涉及的运算电路的结构的图。
图24是示意地示出能够执行本发明的各实施方式所涉及的运算电路的依照“矩阵实例(matrixcase)”的运算的结构的一个例子的图。
图25是示意地示出能够执行本发明的各实施方式所涉及的运算电路的依照“矩阵实例”的运算的结构的其他例子的图。
(附图标记说明)
12、12a、12b、12c、12d、12e、12f、12g、12h、12i、12j、12k:运算电路;17:端口;61:外部输入装置;62:外部存储装置;63:外部输出装置;x:输入矢量;111、a:系数矩阵;121:并行运算电路;124:共享存储器;131、131a:输入变换电路;132、132d:系数存储电路;133:输入存储电路;133a、133b:二重化输入存储电路;133c:输入通知电路;141:输出变换电路;142:输出存储电路;142a、142b:二重化输出存储电路;143、143i:输出通知电路;clk:运算器;ck、cn、mik、mok:存储电路。
具体实施方式
以下,参照附图,详细说明各实施方式。此外,对同一或者相当的部分附加同一参照符号,不反复其说明。此外,该公开所涉及的运算电路以及运算方法适用于cnn中的卷积运算,但不限于cnn而还能够应用于其他领域。
实施方式1.
[cnn的处理]
最初,简单说明cnn。图1是示出利用cnn的运算处理的流程图。
参照图1,cnn包括输入层s201、卷积层s202、s204、池化层s203、s205、全连接层s206、以及输出层s207。
输入层s201接受图像数据等处理对象的数据的输入。输出层s207输出进行数据处理后的最终结果。在图1中,为了简化,将卷积层和池化层的组合(s202、s203;s204、s205)反复2次,但也可以进而反复多次。
将卷积层的输入数据称为输入特征映像,将卷积层的输出数据称为输出特征映像。卷积层s202、s204一边在输入特征映像上以像素单位扫描内核(还被称为滤波器),一边反复进行输入特征映像的对应部分与内核的积和运算,对最终的积和运算结果进行非线性变换,由此生成输出特征映像。内核的要素(还被称为“权重”)事先通过学习决定。后面将参照图2详细叙述卷积运算。
池化层s203、s205通过进行如将输出特征映像的局部区域集中为一个要素那样的动作,减小特征映像的空间尺寸。池化层s203、s205例如取得局部区域的最大值、或者使包含于局部区域的要素平均化。
全连接层s206与输出层s207邻接地设置1个或者多个层。全连接层的s206的各神经元具有与邻接层的所有神经元的结合。
[卷积运算]
图2是用于说明卷积运算的图。如图2所示,通过作为输入特征映像的输入数据100和内核101的卷积运算,生成输出数据102。通过对输出数据102的各要素加上偏置进而施加活性化函数,生成输出特征数据。作为活性化函数,例如使用relu(rectifiedlinearunit)等非线性函数。
在图2的例子中,为了简化,将输入数据尺寸设为(7,7),将内核尺寸设为(3,3)。也可以为了调整输出数据尺寸,用固定数据(例如0)填入输入数据100的周围104。将其称为填充。在图2的输入数据100中,应用宽度为1且值为0的填充。
在卷积运算中,一边在包括填充的部分的输入数据100上使内核101以一定间隔滑动,一边对内核101的要素和对应的输入数据100的要素进行乘法,求出它们的和。即,执行积和运算。积和运算的结果被储存到输出数据102的对应的要素。将使内核101滑动的间隔称为步幅。在图2的情况下,步幅是1。
具体而言,在内核101的配置与图2的粗的实线的框103对应的情况下,作为积和运算结果的“30”被储存到输出数据102的对应的要素106的位置。在内核101的配置与图2的粗的虚线的框105对应的情况下,作为积和运算结果的“13”被储存到输出数据102的对应的要素107的位置。
[特征映像以及内核的展开]
图3是用于说明特征映像以及内核的展开的图。在本实施方式1的情况下,为了缩短卷积运算的处理时间,通过将特征映像的各行接合,特征映像被展开成1列。
具体而言,参照图2以及图3,通过将图2的输入数据100的各行接合,生成图3的输入矢量110。与输入数据100对应的输入矢量110的要素数是7×7=49。图2的输出数据102也通过针对每个行接合而被展开成1列。与输出数据102对应的输出矢量的要素数也是49。
图2的内核101以在从右乘以输入矢量110时生成与图2的输出数据102对应的输出矢量的方式,展开成矩阵。由此,生成系数矩阵111。系数矩阵111的行数是第1行至第49行的49,系数矩阵111的列数是第1列至第49列的49。此外,在图3所示的系数矩阵111中,空白部分的方格的要素是0。
具体而言,系数矩阵111的第1行是(3,2,0,0,0,0,0,1,3,0,…,0),相当于图2的内核101位于特征映像上的粗的虚线的框105的情况。通过执行该系数矩阵111的第1行与输入矢量110的积和运算,生成储存于图2的输出数据102的对应的要素107的位置的数据“13”。
同样地,系数矩阵111的第9行是(3,2,1,0,0,0,0,1,3,2,0,0,0,0,2,1,3,0,…,0),相当于图2的内核101位于特征映像上的粗的实线的框103的情况。通过执行该系数矩阵111的第9行与输入矢量110的积和运算,生成储存于图2的输出数据102的对应的要素106的位置的数据“30”。
在图2中未应用填充的情况下,在与输入数据100对应的输入矢量110中无变更,其要素数是49。输出数据102的数据尺寸成为(5,5),所以与输出数据102对应的输出矢量的要素数成为5×5=25。另外,与内核101对应的系数矩阵111的行数成为25,其列数成为49。
在卷积运算中执行的矩阵运算式一般用式(1)表示。即,卷积运算的输出矢量f是通过对系数矩阵a从右乘以输入矢量x并对其运算结果加上偏置矢量b而得到的。在此,系数矩阵a的特征在于,包含比较多的值为0的要素这一点。
[数学式1]
在本说明书中,将输出矢量f的要素设为f1、…、fn。将第i个输出矢量f的要素记载为fi或者f(i)。将输入矢量x的要素设为x1、…、xm。将第j个输入矢量x的要素记载为xj或者x(j)。将偏置矢量b的要素设为b1、…、bn。将第i个偏置矢量b的要素记载为bi或者b(i)。另外,系数矩阵a由第1至第n这n行和第1至第m这m列构成。将第i行第j列的系数矩阵a的要素记载为aij或者a(i,j)。在本实施方式1中,作为各要素的索引的值ij、或者j是该要素的标识符,并且还能够指定应运算该要素的后述运算器clk、该要素的运算器clk的指定以及应运算的顺序。
另外,在卷积运算中,如nvidia公司的技术文献“cudnn:efficientprimitivesfwordeeplearning”第4页的“figure1:convolutionlowering”所示,还有用系数矩阵(fm)表现系数,并且输入以及输出也并非矢量而表现为矩阵(dm,om)的实例。将该实例称为“矩阵实例”。在矩阵实例中的卷积运算中,计算矩阵与矩阵之积。
[运算电路的概略性的结构]
图4是将本实施方式1所涉及的运算电路12的结构的一个例子与周边电路关联起来示出的图。运算电路12是“运算装置”的一个实施例。参照图4,运算电路12具备作为用于控制运算电路12内的各部的专用电路的控制电路30、具有分别实施积和运算的多个运算器clk(k=1、2、3…n)的并行运算电路121、输入i/f(interface的简称)122以及输出i/f(interface)123。运算电路12具有多个运算器clk。各运算器clk与系数矩阵a的各行对应地设置。
在运算电路12中,在实施用式(1)表示的矩阵运算的情况下,各运算器clk与其他运算器clk并行地执行积和运算。
控制电路30具备处理器31、和包括例如非易失性的存储介质的存储器32。在存储器32中,储存有用于控制运算电路12的控制程序150。
运算电路12经由总线45连接将用于运算的数据输入到运算电路12的外部输入装置61、将来自该运算电路12的运算结果输出到外部的外部输出装置63以及sram(staticrandomaccessmemory,静态随机存取存储器)等外部存储装置62。
外部输入装置61、外部存储装置62以及外部输出装置63经由总线40,连接具备存储器50的cpu(centralprocessingunit,中央处理单元)51。存储器50储存系数矩阵a、输入矢量x及偏置矢量b、以及运算电路12的运算结果。
cpu51控制外部输入装置61、外部存储装置62以及外部输出装置63。例如,cpu51从存储器50读出系数矩阵a、输入矢量x以及偏置矢量b,经由外部输入装置61或者外部存储装置62输出到运算电路12的输入i/f122。外部输出装置63输入来自输出i/f123的运算结果,将输入的运算结果经由总线40输出到cpu51。cpu51将来自外部输出装置63的运算结果储存到存储器51。另外,来自输出i/f123的运算结果也可以储存到外部存储装置62。外部存储装置62和外部输出装置63经由有线或者无线的多个线路与输出i/f123连接。输出i/f123具备连接各线路的端口17。
此外,存储器51也可以并非cpu50而与总线40连接。另外,也可以外部存储装置62具备存储器50。
[运算器的结构]
图5是将图4的运算器clk和输入输出数据关联起来说明的图。参照图5,运算器clk包括累加器t1、乘法器t2、加法器t3以及寄存器t4。对运算器clk连接有可从运算器clk读出的系数存储电路132以及输入存储电路133。“输入存储电路”是在并行运算电路121与外部装置之间存储向并行运算电路121的输入的电路。系数存储电路132以及输入存储电路133包含于图4的输入i/f122。在图5中,示出并行运算装置的多个运算器clk中的1个,但其他运算器也具有同样的结构。
在系数存储电路132中,储存系数矩阵a的第k个行的要素ak1~akn、和偏置矢量b的第k个要素bk。另外,在输入存储电路133中,储存输入矢量x的要素x1~xn。
(积和运算处理)
在运算器clk中,累加器t1以及寄存器t4预先储存有初始值(例如0)。在开始了积和运算处理时,乘法器t2与时钟同步地,从系数存储电路132读出要素akm,从输入存储电路133读出要素xm,对读出的要素akm乘以要素xm来计算积,将计算出的积通过覆盖写入储存到寄存器t4。加法器t3计算寄存器t4的积与储存于累加器t1的累加值sum的和,将计算出的和输出到累加器t1。累加器t1对从输入存储电路133读出的要素bk与来自加法器t3的和进行加法,将加法结果加到累加值sum。由此,1次的运算处理结束。这样的由系数存储电路132的要素akm和输入存储电路133的对应的要素xm的积、以及累加值sum的和构成的积和运算被反复n次。
这样,各运算器clk与其他运算器clk独立地,将分配的行的积和运算,反复系数存储电路132的要素akm以及对应的输入存储电路133的要素xm的组的总数(m个)。其结果,将各运算器clk的累加器t1的累加值sum,作为输出矢量f的要素fk,输出到输出i/f123。
[输入i/f和输出i/f的结构]
图6是示出本实施方式1所涉及的输入i/f和输出i/f的结构的图。在图6中,将输入i/f和输出i/f的结构与除了控制电路30以外的周边电路关联起来示出。在图6中,并行运算电路121连接共享存储器124。共享存储器124构成为通过各运算器clk能够写入以及能够读出。参照图6,输入i/f122包括输入变换电路131、系数存储电路132以及输入存储电路133。输出i/f123包括输出变换电路141以及输出存储电路142。“输出存储电路”是在并行运算电路121与外部装置之间存储来自并行运算电路121的输出的电路。
图7是示出本实施方式1所涉及的输入存储电路、输出存储电路、以及系数存储电路的结构的一个例子的图。图8是示意性地说明本实施方式1所涉及的存储方式的图。图9是示出本实施方式1所涉及的输入变换电路的结构的一个例子的图。图10是示出本实施方式1所涉及的输出变换电路的结构的一个例子的图。
参照图7(a),输入存储电路133包括多个存储电路mik(k=1,2,3,…)。多个存储电路mik分别与各运算器clk对应地设置,即与输入矢量x的各行对应地设置,构成为能够通过对应的运算器clk读出。存储电路mik包括储存输入矢量x的要素xj的多个寄存器。
参照图7(b),输出存储电路142包括多个存储电路mok(k=1,2,3,…)。多个存储电路mok构成为能够写入输出矢量f的要素fi,并且能够读出要素fi。
参照图7(c),系数存储电路132包括多个存储电路ck(k=1,2,3,…)。多个存储电路ck分别与各运算器clk对应地设置,即与系数矩阵a的各行对应地设置,构成为能够通过对应的运算器clk读出。存储电路ck例如如图8(b)所示,包括储存偏置矢量b的要素bi和系数矩阵a的要素aij的多个寄存器。
(输入变换电路)
输入变换电路131具有例如图9所示的结构。参照图9,输入变换电路131具备与系数存储电路132以及输入存储电路133的各存储电路对应的选择器13、和表格或者专用电路15。表格或者专用电路15向各选择器输出选择指令151。选择指令151表示选择来自外部存储装置62或者外部输入装置61的系数矩阵a的要素aij、输入矢量x的要素xj以及偏置矢量b的要素bi中的哪些并写入到对应的存储电路的指令。选择指令151包括例如要素aij、要素xj以及要素bi的索引的值。
具体而言,在输入变换电路131从外部存储装置62或者外部输入装置61受理到要素aij、要素xj以及要素bi时,各选择器13依照受理的要素aij、要素xj以及要素bi的索引和选择指令151,选择要素,将选择出的要素aij、要素xj以及要素bi写入到对应的存储电路mik或者存储电路ck。此时,选择器13通过选择指令151,仅选择要素aij中的非零的要素aij。然后,选择器13将选择出的要素aij以及要素bi储存到对应的存储电路ck。
另外,输入变换电路131的各选择器13依照从外部存储装置62或者外部输入装置61受理的要素xj的索引和选择指令151,选择储存到对应的存储电路mik的要素xj。在该选择中,选择器13依照选择指令151,仅选择与非零的要素aij对应的要素xj。选择器13将选择出的要素xj储存到对应的存储电路mik。
另外,输入变换电路131的选择器13在存储电路mik中储存要素xj、并且在存储电路ck中储存非零的要素aij的情况下,按照要素的索引的值表示的顺序,在对应的存储电路的寄存器中储存该要素。具体而言,选择器13在存储电路ck的多个寄存器中的、将要素aij的索引表示的值(数字)作为地址被指定地址的寄存器中,储存要素aij。另外,选择器13在存储电路ck的多个寄存器中的、与要素aij的寄存器不同的预先决定的寄存器中,储存要素bi。同样地,选择器13在存储电路mik的多个寄存器中的、将要素xj的索引表示的值(数值)作为地址被指定地址的寄存器中,储存要素xj。
由此,在存储电路ck和存储电路mik中,储存对应的运算器clk的积和运算所需的要素xj、非零的要素aij、以及要素bi。另外,在存储电路ck中,以应运算的顺序,储存非零的要素aij,在各存储电路mik中,以应运算的顺序,储存与非零的要素aij对应的要素bi。
(输入变换电路的表格或者专用电路)
在本实施方式1中,各运算器clk被分配到系数矩阵a的哪个行、和非零的要素aij和应运算的要素xj的输入矢量x中的位置是预先决定的。因此,在表格或者专用电路15中,储存有表示这样的预先决定的内容的信息,专用电路依照储存的信息,生成发往各选择器13的选择指令151,将生成的选择指令161输出到该选择器13。此外,在向运算器clk的系数矩阵a的行的分配、以及非零的要素aij和应运算的要素xj的输入矢量x中的位置不变更的情况下,表格或者专用电路15能够构成为固定的电路。
(输出变换电路)
输出变换电路141具有例如图10所示的结构。参照图10,输出变换电路141具备多个选择器14、和表格或者专用电路16。多个选择器14与输出存储电路142的多个存储电路mok分别对应。存储电路mok包括1个或者多个寄存器。
输出存储电路142储存的输出fi被输出到外部存储装置62或者外部输出装置63,但输出存储电路142能够同时输出到外部存储装置62或者外部输出装置63的输出fi的数量是预先决定的。因此,输出存储电路142具有与可同时输出的输出fi的数量相同的数量的存储电路mok。另外,多个存储电路mok分别经由端口17与外部存储装置62或者外部输出装置63连接。
输出变换电路141的各选择器14在将来自并行运算电路121的输出fi储存到存储电路mok时,根据来自表格或者专用电路16的选择指令161和输出fi的索引的值,从多个存储电路mok决定1个(即多个端口17中的1个),将输出fi储存到决定的存储电路mok。在本实施方式中,输出fi的索引还起到作为识别该输出fi的标识符的作用。选择器14在储存输出fi时,根据选择指令161和输出fi的索引决定地址,在用决定的地址被指定地址的存储电路mok的寄存器中储存输出fi。
一般,作为系数矩阵a的各行的运算结果的输出fi是从哪个运算器clk导出、将该输出fi输出到哪个端口17、以及规定送出输出fi的顺序的基准的信息是预先决定的。
表格或者专用电路16储存有上述叙述的基准信息。表格或者专用电路16根据储存的基准信息,生成发往各选择器14的选择指令161,将生成的选择指令161输出到该选择器14。
此外,在系数矩阵a的多个行与多个运算器clk分别一对一地对应的情况下,能够将运算器clk和存储电路mok直接一对一地结合,在该情况下,储存各存储电路mok的输出fi的位置(容量、寄存器的个数)仅1个即可。
表格或者专用电路16针对各选择器14输出选择指令161,该选择指令161表示选择作为来自并行运算电路121的运算结果的要素fi中的哪一个并写入到对应的存储电路mok的指令。选择指令161包括例如要素fi的索引的值。
具体而言,选择器14从来自并行运算电路121的各运算器clk的要素fi中,根据选择指令161选择要素fi,将选择出的要素fi储存到对应的存储电路mok。各存储电路mok包括多个寄存器。输出变换电路141在将要素fi储存到存储电路mok的情况下,按照依照选择指令161的顺序,将要素fi储存到该存储电路mok的寄存器。
来自上述叙述的表格或者专用电路16的选择指令161是根据如下因素预先决定的:针对来自并行运算电路121的输出(要素fi),外部存储装置62或者外部输出装置63期待的要素fi被储存的输出存储电路142的位置(地址)或者读出的顺序。
此外,存储电路mik、存储电路mok以及存储电路ck包括可指定地址的多个寄存器,但不限定于使用寄存器的结构。例如,是可指定地址的存储电路即可,也可以构成为包括例如sram。
[运算器和要素的关联的具体例]
图11是示出图5所示的运算器clk和应运算的要素的关联的具体例的图。如图11所示,根据输入变换电路131,在存储电路ck以及存储电路mik中,仅储存应由对应的运算器clk运算的非零要素aij和要素xj,并且按照应运算的顺序储存。
因此,运算器clk的乘法器t2仅通过与时钟同步地从存储电路ck以及存储电路mik依次读出要素,能够按照应运算的顺序,仅取得应由运算器clk进行积和运算的要素。
由此,即使同时发生来自各运算器clk的要素的读出要求,也无需进行在要求之间附加顺序等调解,进而也无需进行在各运算器clk中将要素按照应进行乘法的顺序排列的处理。因此,相比于需要该调解的以往的积和运算处理,能够提高整体的处理速度。
[系数存储电路的变形例]
参照图8,系数存储电路132储存系数(要素aij和要素bi)的方式包括图8(a)的第1个方式和图8(b)的第2个方式。
参照图8(a),第1个方式是如图11所示,在运算器clk的对应的存储电路ck中接着要素bi按照索引的顺序储存与系数矩阵a的1行l相当的要素aij的方式。图8(a)的第1个方式还能够将从存储电路ck读出的系数,跳过并行运算电路121,经由输出变换电路141储存到输出存储电路142。
参照图8(b),第2个方式附加本来的系数数据(要素bi和与1行l相当的要素aij)、和指定执行模式的标志f。例如,标志f针对储存于存储电路ck的各系数(要素aij或者要素bi),对并行运算电路121指示应使用该系数实施的运算等处理的种类。在本实施方式1中,执行标志指示的处理的种类包括要素aij与要素xj的积、积和运算、系数(要素aij或者要素bi)的载入、输入数据(要素xj)的载入、向共享存储器124的写入(例如运算结果(要素fj)的写入)、从共享存储器124的读出、将各系数(要素aij或者要素bi)跳过并行运算电路121经由输出变换电路141储存到输出存储电路142等。
作为进一步的其他方式,图8(b)的方式还能够变形为如图8(c)所示,存储电路ck按照索引的顺序储存与多个行l1相当的要素aij。
[各部的变形例]
运算电路12可由包括能够通过并行运算执行用上述(1)式表示的矩阵运算的多个运算器的asic(applicationspecificintegratedcircuit,专用集成电路)或者fpga(fieldprogrammablegatearray,现场可编程门阵列)构成。
另外,具备多个运算器clk的并行运算电路121是能够并行地执行多个处理(例如积和运算)的结构即可,例如并行运算电路121能够由多核处理器构成。在该情况下,多个处理器核与多个运算器clk分别对应。
另外,在本实施方式1中,能够将矩阵a的非零要素aij和输入矢量的对应的要素xj,在运算电路12的初始化处理时,经由输入变换电路131,储存到系数存储电路132。此外,在矩阵a的非零要素aij和输入矢量的对应的要素xj的值固定的情况下,系数存储电路132能够包括储存有非零要素aij和对应的要素xj的值的rom(readonlymemory,只读存储器)。
也可以为了使矩阵a和矢量x的积的计算高速化,通过2个以上的运算器clk,实施矩阵a的1行量的积和运算。在该情况下,为了取得来自各运算器clk的运算结果的和,输出存储电路142能够用于储存各运算器clk的运算结果。
另外,也可以在外部存储装置62或者外部输入装置61与运算电路12的输入变换电路131之间,追加特化为能够避免输入数据的重复的读入或者参照的卷积运算的结构。
另外,由于矩阵a小,作为输入矢量x从行线缓冲器(linebuffer)切出图像的影像部分的处理以具有与通常的卷积核的高度相同的行线数的行线缓冲器取入、和从内核系数寄存器(窗口)取入输入数据为前提。这样的行线缓冲器也可以具有如按照光栅扫描(rasterscan)的顺序取入数据,并且在取入到行线量的数据的时间点,将最久的行线用作接着取入数据的行线那样的环形缓冲器的构造。
[整体处理的流程图]
图12是说明本实施方式1所涉及的并行处理的流程图。将依照图12的流程图的处理,作为控制程序150,储存到控制电路30的存储器32。处理器31从存储器32读出控制程序150,执行读出的控制程序150。
参照图6,说明图12的处理。首先,处理器31实施初始化处理(步骤s1)。
具体而言,在初始化处理中,处理器31起动输入变换电路131,使得实施初始化处理。输入变换电路131将来自外部存储装置62或者外部输入装置61的系数矩阵a的非零的要素aij和偏置矢量b的要素bi,储存到系数存储电路132的多个存储电路cn。具体而言,如在图9中说明,与存储电路cn对应的选择器13根据要素aij和要素bi的索引以及选择指令151,将选择出的要素aij和要素bi储存到对应的存储电路cn。
如果初始化处理结束,则运算电路12转移到通常处理。在通常处理中,控制电路30的处理器31在判定从外部存储装置62或者外部输入装置61向运算电路12输出了输入矢量x的要素x1、…、xm时,使输入变换电路131将要素x1、…、xm储存到输入存储电路133(步骤s3)。具体而言,如在图9中说明,选择器13根据要素x1、…、xm的索引和选择指令151,将选择出的要素xj储存到对应的存储电路mik。
控制电路30的处理器31判断通过选择器13将矢量x的要素x1、…、xm储存到对应的存储电路mik的处理是否完成(步骤s5)。处理器31在判断为储存未完成的情况下(在步骤s5中“否”),返回到步骤s3,在判断为储存完成的情况下(在步骤s5中“是”),转移到步骤s7。在储存完成(在步骤s5中“是”)时,各存储电路ck成为以应运算的顺序储存非零的要素aij的状态,并且各存储电路mik成为以应运算的顺序储存与非零的要素aij对应的要素bi的状态。
控制电路30的处理器31使并行运算电路121实施运算(步骤s7)。在此,说明在存储电路ck中依照图8(a)所示的第1个方式储存系数数据(非零的要素aij和要素bi)的实例。
并行运算电路121的各运算器clk通过对储存于存储电路ck的要素aij的各个反复进行如下积来完成上述叙述的(积和运算处理):从对应的存储电路ck的位置(地址)读出的非零的要素aij、与从对应的存储电路mik的与该地址对应的地址读出的要素xj的积。在所有运算器clk中,同时(并行地)实施积和运算处理。
控制电路30的处理器31在所有运算器clk中结束了积和运算处理时,以将作为运算结果的累加值sum(输出fi)输出给输出变换电路141的方式,控制各运算器clk。另外,处理器31以使用控制指令将来自各运算器clk的输出fi储存到各存储电路mok的方式,控制输出变换电路141(步骤s9)。
控制电路30的处理器31判断输出fi的储存是否完成(步骤s11)。处理器31在判断为储存未完成时(在步骤s11中“否”),返回到步骤s11,在判断为储存完成时(在步骤s11中“是”),处理器31以将储存于各存储电路mok的输出fi输出到外部存储装置62或者外部输出装置63的方式,控制输出存储电路142(步骤s13)。此时,输出存储电路142从各存储电路mok按照储存的顺序读出输出fi,将读出的输出fi按照读出的顺序送出到线路。同时执行从各存储电路mok向外部存储装置62或者外部输出装置63的输出fi的送出。
控制电路30的处理器31判断运算处理是否结束(步骤s15)。处理器31在判断为结束时,结束图12的处理(在步骤s15中“是”),但在判断为未结束时(在步骤s15中“否”),返回到步骤s3。此外,根据例如来自cpu51的指令,进行步骤s15的判断。
(流程图的变形例)
在图12的流程图中,系数存储电路132的存储电路ck的储存方式是图8(a)的第1个方式,但也可以是图8(b)的第2个储存方式。
在第2个储存方式的情况下,并行运算电路121对储存于与系数存储电路132的各运算器clk对应的存储电路ck的各要素aij,实施由与该要素aij对应的标志f指示的种类的运算或者处理。在该情况下也是并行运算电路121的所有运算器clk同时动作。
在第2个储存方式的情况下,也可以为了针对并行运算电路121的各运算器clk的运算量的均衡化,对2个(以上)运算器clk分配系数矩阵a的1行量的运算而实施。在该情况下,并行运算电路121利用共享存储器124计算由进行了分配的2个(以上)运算器clk计算出的结果的和。另外,在进行分配的运算器clk的数量不多的情况下,相对全部运算数的该分配处理的数量很少,能够忽略分配处理对运算电路12的运算性能造成的影响。
根据实施方式1,能够通过输入i/f122,在仅并行运算电路121的各运算器clk能够读出的存储电路ck和mik中,在运算之前储存应由该运算器clk运算的系数数据(要素aij以及要素bi)以及输入数据(要素xj)。由此,在所有运算器clk同时(并行地)实施运算时,能够可靠地避免系数数据以及输入数据的访问(读出)的竞争,能够高速地实施并行处理。
另外,在存储电路ck中,仅储存有非零的要素aij,所以在各运算器clk中,能够从积和运算排除使用作为零的要素aij的积的运算、即不需要的乘法。由此,能够缩短从在并行运算电路121中开始利用多个运算器clk的积和运算的并行处理至得到作为处理的最终结果的输出矢量f的要素f1、…、fn为止的所需时间。
实施方式2.
实施方式2示出实施方式1的变形例。图13是示出本实施方式2所涉及的运算电路12a的输入i/f和输出i/f的结构的图。图13的运算电路12a具有与图6的输入i/f122不同的输入i/f122a。运算电路12a的其他结构与图6的其他结构相同,所以不反复说明。
参照图13,输入i/f122a代替输入变换电路131以及输入存储电路133,而具备输入变换电路131a以及输入通知电路133c。图14是示出图13的输入通知电路133c的结构的图。参照图14,输入通知电路133c具备具有图9的选择器13的功能和通知n的输出功能的多个选择器13a。多个选择器13a与运算器clk分别对应。
输入变换电路131a在从外部输入装置61或者外部存储装置62受理到输入矢量x的要素xj时,根据要素xj的索引的值,确定多个运算器clk中的、实施使用该要素xj的运算的运算器clk,仅向确定的运算器clk输出要素xj。另外,此时,在图14的输入通知电路133c中,与由输入变换电路131a确定的运算器clk对应的选择器13a向对应的运算器clk输出运算的通知n。接受到通知n的运算器clk从系数存储电路132的存储电路ck读出要素aij和要素bi,实施使用读出的要素aij和要素bi以及从输入变换电路131要素xj的积和运算。
根据实施方式2,例如在从外部输入装置61或者外部存储装置62向运算电路12传送要素xj的速度是低速的情况下,如图13的运算电路12a,代替通过输入存储电路133存储要素xj,而输入变换电路131a将要素xj直接输入到运算器clk。
由此,能够不需要用于输入存储电路133的存储器资源。进而,能够使未从输入通知电路133c接受到通知的运算器clk即无需进行使用该要素xj的运算的运算器clk休止。因此,能够减小运算电路12的电路规模和功耗。
实施方式3.
实施方式3示出实施方式1的变形例。图15是示出本实施方式3所涉及的运算电路12b的输入i/f和输出i/f的结构的图。图15的运算电路12b具有与图6的输出i/f123不同的输出i/f123b。运算电路12b的其他结构与图6的其他结构相同,所以不反复说明。
参照图15,输出i/f123b具备输出变换电路141、输出存储电路142以及输出通知电路143。图16是将图15的输出通知电路143的结构与周边电路关联起来示出的图。参照图16,输出通知电路143具备表格144以及判断电路145。在表格144中,储存有识别应送出到外部存储装置62或者外部输出装置63的输出fi的例如索引信息。索引信息表示外部存储装置62或者外部输出装置63所需要的种类或者个数的输出fi。
判断电路145实施监视经由输出变换电路141从各运算器clk送出的输出fi的监视处理1451。在监视处理1451中,读取例如输出fi的索引。判断电路145在根据监视的结果判断为从并行运算电路121输出了表格144的索引信息表示的必要的种类或者个数的所有输出fi时,将通知n1输出到外部存储装置62或者外部输出装置63。外部存储装置62或者外部输出装置63直至从判断电路145输出通知n1为止是休止,在从判断电路145受理到通知n1时起动而受理来自输出存储电路142的输出fi。
根据实施方式3,在例如从外部存储装置62或者外部输出装置63向总线40的数据输出是低速的情况下,在直至从输出通知电路143输出通知n1为止的期间,即在不需要向总线40的数据输出的期间,能够使外部存储装置62或者外部输出装置63休止。由此,能够减少外部存储装置62或者外部输出装置63的功耗量。
实施方式4.
实施方式4示出实施方式1的变形例。图17是示出本实施方式4所涉及的运算电路12b的输入i/f和输出i/f的结构的图。图17的运算电路12c具备实施方式2的输入i/f122a和实施方式3的输出i/f123b。
由此,在从外部输入装置61或者外部存储装置62向运算电路12c传送数据的速度、或者外部存储装置62或者外部输出装置63向总线40输出数据的速度是低速的情况下,能够得到实施方式2和实施方式3中的两方的优点。即,能够不需要用于输入存储电路133的存储器资源。进而,能够使无需实施运算的运算器clk休止。另外,不会使外部存储装置62或者外部输出装置63始终动作而能够休止。
实施方式5.
实施方式5示出实施方式1的变形例。图18是示出本实施方式5所涉及的运算电路12d的输入i/f和输出i/f的结构的图。图18的运算电路12d具有与图6的输入i/f122不同的输入i/f122d。运算电路12d的其他结构与图6的其他结构相同,所以不反复说明。
参照图18,输入i/f122d具备输入变换电路131、系数存储电路132、二重化输入存储电路133a以及二重化输入存储电路133b。通过二重化输入存储电路133a、133b,图6的输入存储电路133被二重化。二重化输入存储电路133a、133b的各个具有与在实施方式1中说明的输入存储电路133相同的结构,能够进行同样的动作。
控制电路30的处理器31将二重化输入存储电路133a、133b的一方的功能切换为如受理来自外部输入装置61或者外部存储装置62的要素xj那样的功能,将另一方的功能切换为向并行运算电路121输出要素xj的功能。处理器31在二重化输入存储电路133a、133b的各个完成了各动作时,将一方的功能切换为向并行运算电路121输出要素xj的功能,将另一方的功能切换为如受理来自外部输入装置61或者外部存储装置62的要素xj那样的功能。
根据实施方式5,在从外部输入装置61或者外部存储装置62向运算电路12d传送要素xj的速度是高速时,通过使用二重化输入存储电路133a、133b,运算电路12d能够同时实施从外部输入装置61或者外部存储装置62接收要素xj的处理、和利用并行运算电路121的运算处理。因此,能够使利用运算电路12d的运算速度高速化。
实施方式6.
实施方式6示出实施方式1的变形例。图19是示出本实施方式6所涉及的运算电路12e的输入i/f和输出i/f的结构的图。图19的运算电路12e具有与图6的输出i/f123不同的输出i/f123e。运算电路12e的其他结构与图6的其他结构相同,所以不反复说明。
参照图19,输出i/f123e具备输出变换电路141、二重化输出存储电路142a以及二重化输出存储电路142b。通过二重化输出存储电路142a、142b,图6的输出存储电路142被二重化。二重化输出存储电路142a、142b的各个具有与在实施方式1中说明的输出存储电路142相同的结构,能够进行同样的动作。
控制电路30的处理器31将二重化输出存储电路142a、142b的一方的功能切换为将从并行运算电路121经由输出变换电路141的输出fi储存到存储电路mok的功能,将另一方的功能切换为从存储电路mok读出输出fi并将读出的输出fi送出到外部存储装置62或者外部输出装置63的功能。处理器31在二重化输出存储电路142a、142b的各个完成各动作时,将一方的功能切换为从存储电路mok读出输出fi并送出到外部存储装置62或者外部输出装置63的功能,将另一方的功能切换为将从并行运算电路121经由输出变换电路141的输出fi储存到存储电路mok的功能。
实施方式6例如能够在被要求从运算电路12向外部存储装置62或者外部输出装置63高速送出输出fi的情况下应用。具体而言,通过输出存储电路被二重化,运算电路12能够同时(并行地)实施输出向外部存储装置62或者外部输出装置63的输出fi的处理、和利用并行运算电路121的运算处理,能够使运算电路12的运算处理进一步高速化。
实施方式7.
实施方式7示出实施方式1的变形例。图20是示出本实施方式7所涉及的运算电路12f的输入i/f和输出i/f的结构的图。图20的运算电路12f具备实施方式5的二重化输入存储电路133a、133b以及实施方式6的二重化输出存储电路142a、142b。
实施方式7的运算电路12f分别二重化地具备输入存储电路以及输出存储电路。根据运算电路12f,从外部输入装置61或者外部存储装置62高速地输出的要素xj的受理、向外部存储装置62或者外部输出装置63的输出fi的高速的送出、以及利用并行运算电路121的运算处理能够同时进行。
实施方式8.
实施方式8示出实施方式1的变形例。图21是示出本实施方式8所涉及的运算电路的结构的图。图21的运算电路具有运算电路12g、和与运算电路12g连接的运算电路12h。运算电路12g删除了实施方式1的运算电路12的输出i/f123,其他与运算电路12相同。运算电路12h具备输入i/f122h、并行运算电路121以及输出i/f123。输入i/f122h具备输入输出变换电路131h、系数存储电路132以及输入存储电路133。在图21中,除了输入输出变换电路131h以外的其他结构与实施方式1的运算电路12具备的结构相同,所以不反复说明。
输入输出变换电路131h直接受理来自运算电路12g的多个运算器clk的输出fi,从受理的输出fi,针对运算电路12h的每个运算器clk,确定应由该运算器clk运算的输出fi。然后,输入输出变换电路131h将确定的输出fi,依照应运算的顺序,储存到与该运算器clk对应的输入存储电路133的存储电路mik。在图21中,运算电路12连接2个,但连接的个数也可以是3个以上。
根据实施方式8,能够连接2个以上的运算电路12。例如,能够在lsi(large-scaleintegration)电路内,连接2个以上的运算电路12。这样,在如连接2个以上的运算电路12那样的情况下,通过在连接运算电路彼此的连接部中具备输入输出变换电路131h,能够以利用输入输出变换电路131h的1次的处理,完成基于输出变换电路141以及输入变换电路131的使用选择器14(或者选择器13)的2个处理。因此,即使连接多个运算电路,也能够实现处理的高速化。
实施方式9.
实施方式9示出实施方式1的变形例。图22是示出本实施方式9所涉及的运算电路的结构的图。图22的运算电路具有运算电路12g、和与运算电路12g连接的运算电路12i。运算电路12g删除了实施方式1的运算电路12的输出i/f123,其他与运算电路12相同,所以不反复说明。
运算电路12i具备输入i/f122h、并行运算电路121以及输出i/f123b。并行运算电路121以及输出i/f123b与实施方式3所示相同。输入i/f122i具备在实施方式8中示出的输入输出变换电路131h、输出通知电路143i、系数存储电路132以及输入存储电路133。输入输出变换电路131h、系数存储电路132以及输入存储电路133与实施方式3或者实施方式8所示相同,所以不反复说明。
输出通知电路143i向运算电路12i的各运算器clk输出通知n2。具体而言,在输入输出变换电路131h将来自前级的运算电路12g的多个运算器clk的输出fi储存到与运算电路12i的各运算器clk对应的存储电路mik时,输出通知电路143i判定在该存储电路mik中是否储存有应先于该输出fi运算的输出fi。输出通知电路143i例如根据输出fi的索引的值,实施该判定。输出通知电路143i在判定为在存储电路mik中储存有应先运算的所有输出fi时,向与该存储电路mik对应的运算器clk输出通知n2。由此,运算器clk能够在接受到在对应的存储电路mik中储存有积和运算的开始所需的所有要素xj(即输出fi)的通知n2时,开始积和运算。
此外,在图22中,连接2个运算电路12,但连接的个数也可以是3个以上。
根据实施方式9,能够连接实施方式3所示的2个以上的运算电路12b。例如,在lsi电路内连接2个以上的运算电路12b那样的情况下,通过在连接部中具备输入输出变换电路131h,能够以利用输入输出变换电路131h的1次的处理,完成输出变换电路141的处理以及利用输入变换电路131的处理这2个处理。因此,即使连接多个运算电路,也能够实现处理的高速化。
实施方式10.
实施方式10示出实施方式1的变形例。图23是示出本实施方式10所涉及的运算电路的结构的图。图23的运算电路具有运算电路12j、和与运算电路12j连接的运算电路12k。运算电路12j从在实施方式7中示出的运算电路12f删除输出i/f123,其他结构与运算电路12f的其他结构相同,所以不反复说明。另外,运算电路12k具备输入i/f122k、并行运算电路121、以及输出i/f123e。输入i/f122k具备输入输出变换电路131k、二重化输入存储电路133a、133b以及系数存储电路132。运算电路12k中的除了输入输出变换电路131k以外的其他结构与实施方式7的运算电路12f的其他结构相同,所以不反复说明。
输入输出变换电路131k直接受理来自运算电路12j的多个运算器clk的输出fi,根据受理的输出fi,针对运算电路12k的每个运算器clk,确定应由该运算器clk运算的输出fi。输入输出变换电路131k将确定的输出fi,依照应运算的顺序储存到与该运算器clk对应的输入存储电路133的存储电路mik。在此,连接2个运算电路,但连接的个数也可以是3个以上。
根据实施方式10,能够连接实施方式7所示的2个以上的运算电路12f。例如,在lsi电路内连接2个以上的运算电路12f那样的情况下,通过在连接部中具备输入输出变换电路131k,能够以利用输入输出变换电路131k的1次的处理,完成输出变换电路141的处理以及输入变换电路131的处理这2个处理。因此,即使连接多个运算电路,也能够实现处理的高速化。
(各实施方式的变形例)
各实施方式所涉及的运算电路也可以如图24那样变形。图24是示意地示出能够执行本发明的各实施方式所涉及的运算电路的依照“矩阵实例”的运算的结构的一个例子的图。实施方式1.~实施方式8.的运算电路可构成为能够计算如图24所示的依照“矩阵实例”的积和运算。在图24中,示出能够执行n×n的系数矩阵a、和与输入数据100相当的n×n的矩阵x的积和运算的运算器clk。
参照图24,运算器clk具有与图11所示同样的结构,所以不反复说明。在图24中,对运算器clk连接能够从运算器clk读出的系数存储电路132r、储存偏置矢量b的要素的系数存储电路132以及输入存储电路133。输入存储电路133具有与图11所示同样的结构。系数存储电路132r如虚线所示具备环形缓冲器。
运算器clk的积和运算的结果被储存到存储电路amok。存储电路amok包括n个寄存器rg。因此,存储电路amok(k=1、2、…、n)具备与矩阵的维数(n×n个)相同的数量的寄存器rg。
在图24中,示出运算器具备的多个运算器clk中的1个,但其他运算器clk也具有同样的结构。矩阵x视为由n个列矢量构成,在图24的输入存储电路133中,按照列优先的顺序,输入矩阵x的要素。在图24的输入存储电路133中,例如储存有矩阵x的第k个列的要素xk1~xkn。
运算器clk与实施方式1~8的情况同样地,针对矩阵x的每列,反复矩阵x的1列量的积和运算。运算器clk实施系数矩阵a的第k个行与矩阵x的各列的积和运算,输出n个积和运算的值(与输出fi相当)。在该积和运算中,也选择系数矩阵a的第k个行的要素中的非零的要素aij,实施使用选择出的非零要素aij的积和运算。为简化说明,设为系数矩阵a的第k个行不包含非零要素aij。
从运算器clk输出的n个积和运算的值被分别储存到存储电路amok的n个寄存器rg。在图24中示出例如在运算器clk执行了使用矩阵x的第k个列的积和运算的情况下,将该积和运算的值储存到存储电路amok的第k个寄存器rg(用斜线表示的寄存器rg)的状态。
在运算器clk(k=1、2、…n)结束了积和运算时,在输出存储电路的存储电路amok(k=1、2、…n)具备的(n×n个)的寄存器rg中,储存系数矩阵a与矩阵x的积和运算的结果。
在此,作为实施方式的背景,在运算器clk反复积和运算的过程中,矩阵x的第k个列的积和运算完成,之后开始下列(第k+1个列)的积和运算时,需要在开始该下列的积和运算之前,使运算器clk的系数矩阵a的输入初始化。例如,需要能够从系数矩阵a的第k个行的开头的要素起开始读出那样的初始化。因此,下列的积和运算的开始有可能延迟该初始化所花费的时间。
为了避免这样的延迟,在图24中,系数矩阵a的第k个行的要素被储存到系数存储电路132r的环形缓冲器。由此,图24的运算器clk在完成了矩阵x的第k个列的积和运算时,无需上述初始化,而能够开始下列(第k+1个列)的积和运算。因此,能够高速地实施“矩阵实例”中的积和运算。
此外,如在实施方式1.~实施方式8.中说明的系数矩阵a与输入矢量x的积和运算中,也能够使用具备环形缓冲器的系数存储电路。因此,通过应用图24的运算电路,能够在矩阵×矢量的积和运算以及依照“矩阵实例”的矩阵×矩阵的积和运算这两方中实现积和运算的高速化。
(各实施方式的进一步的变形例)
说明各实施方式的进一步的变形例。各实施方式所涉及的运算电路也可以如图25那样变形。图25是示意地示出能够执行本发明的各实施方式所涉及的运算电路的依照“矩阵实例”的运算的结构的其他例子的图。实施方式1.~实施方式8.的运算电路能够应用如图25所示的运算电路。在图25中,也与图24同样地,示出能够执行n×n的系数矩阵a、和n×n的矩阵x的积和运算的运算器clk。
图25的运算器clk、系数存储电路132以及132r、输入存储电路133以及存储电路amok的结构与图24的它们的结构相同,所以不反复这些说明。在图25中,运算电路具备输出接口123r。输出接口123r具备包括n个存储电路amok(k=1、2、…、n)的输出存储电路142r。
在图25中,与图24的实例不同,将矩阵x的要素按照行优先的顺序储存到输入存储电路133,将系数矩阵a的第k个列的要素储存到系数存储电路132r。这样,在使用图25的运算器clk的积和运算中,视为矩阵x由行矢量构成,系数矩阵a由列矢量构成。
图25的运算器clk在将矩阵x的第k个行矢量(该行矢量的所有要素xk1~xkn)储存到了输入存储电路133时,执行使用储存的要素xk1~xkn和系数矩阵a的第k个列的要素ak1~akn的积和运算。在该积和运算中,选择要素ak1~akn中的非零的要素aij,实施使用选择出的非零要素aij的积和运算。为简化说明,设为系数矩阵a的第k个列不包括非零要素aij。
在完成了使用系数矩阵a以及矩阵x的积和运算时,在输出存储电路142r的n个存储电路amok具备的n×n个寄存器rg中,分别作为要素tij储存积和运算结果的值。因此,在输出存储电路142r中,储存(n×n)维的矩阵t。
处理器31决定应从矩阵t读出的要素tij的顺序,以依照决定的顺序从寄存器rg读出要素tij的方式,向输出接口123r输出控制指令cm。例如,设想在具备图25的运算器clk的运算电路12的输出级连接接下来的(其他)运算电路12的情况。在该情况下,控制指令cm包括如下指定:作为接下来的运算电路12的输入数据,设为依照列优先顺序的输入数据、或者设为依照行优先顺序的输入数据。输出接口123r依照控制指令cm,从n×n个寄存器rg读出要素tij。由此,接下来的运算电路12能够按照列优先的顺序或者行优先的顺序,接收输入数据的矩阵x的要素xij。
根据图25,在接下来的运算电路12作为输入(即矩阵x)受理运算电路12执行矩阵与矩阵的积和运算而得到的矩阵t的情况下,接下来的运算电路12在实施积和运算处理时,无需实施将矩阵x的要素xij按照列优先的顺序或者行优先的顺序重排的处理。
具体而言,通常,在经由外部输入装置61或者外部存储装置62传送给运算电路12的矩阵x是图像等的情况下,外部输入装置61或者外部存储装置62将矩阵x的要素xij按照行优先的顺序输出到运算电路12。因此,在将矩阵t的要素xij不重排而输出到接下来的运算电路12的情况下,接下来的运算电路12需要在开始累计处理之前,将矩阵t的要素tij按照行优先的顺序重排。相对于此,在图25中,输出接口123r依照控制指令cm,从输出存储电路142r读出要素tij。
具体而言,处理器31根据例如成为积和运算处理的对象的输入数据(即矩阵t的要素tij)的种类,设定控制指令cm。该种类可包括图像。在处理器31中,如果输入数据的种类是图像,则在控制指令cm中设定“行优先”的读出指令,否则设定“列优先”的读出指令。
输出接口123r在控制指令cm表示“行优先”的读出指令时,从n×n个寄存器rg,依照索引,以行优先的顺序读出要素tij,并且在控制指令cm表示“列优先”的读出指令时,依照索引,以列优先的顺序读出要素tij。这样,根据输入数据的种类(是否为图像等),接下来的运算电路12能够受理将矩阵t的要素tij依照列优先以及行优先中的某一方排列的输入(即矩阵x),能够省略矩阵x的要素xij的重排处理。由此,运算电路12能够高速地实施积和运算处理。
应认为本次公开的实施方式在所有方面为例示而不是限制性的。本发明的范围并非上述说明而基于权利要求书示出,意图包括与权利要求书均等的意义以及范围内的所有变更。
权利要求书(按照条约第19条的修改)
1.一种运算电路,具备:
并行运算电路,包括多个运算器;以及
输入接口,包括多个存储电路,
所述多个运算器构成为与所述多个存储电路分别对应,
各所述多个运算器构成为进行使用了储存到对应的所述存储电路的数据的运算,
各所述存储电路具有:
输入存储电路,存储输入数据;以及
系数存储电路,存储系数数据,
所述输入数据以及所述系数数据具有指定应运算该数据的所述运算器以及该数据应被运算的顺序的索引,
所述输入接口构成为将来自外部装置的所述输入数据以及所述系数数据分别根据该数据具有的所述索引并依照所述顺序储存到与所述多个运算器中的1个运算器对应的所述输入存储电路以及所述系数存储电路。
2.根据权利要求1所述的运算电路,其中,
所述输入存储电路包括二重化的输入存储电路,
所述二重化的输入存储电路的一方构成为储存来自所述外部装置的所述输入数据,在储存完成时,能够通过对应的所述运算器读出输入数据,
所述二重化的输入存储电路的另一方构成为通过对应的所述运算器读出输入数据而读出完成时,储存来自所述外部装置的所述输入数据。
3.一种运算电路,具备:
并行运算电路,包括多个运算器;以及
输入接口,包括多个存储电路,
所述多个运算器构成为与所述多个存储电路分别对应,
各所述多个运算器构成为进行使用了系数数据以及输入数据的运算,
各所述存储电路具有系数存储电路,该系数存储电路存储所述系数数据,
所述输入接口还包括输入电路,该输入电路将来自外部装置的所述系数数据储存到与各所述运算器对应的所述存储电路,
所述输入数据以及所述系数数据具有识别应运算该数据的所述运算器以及该数据应被运算的顺序的索引,
所述输入电路构成为将来自所述外部装置的所述系数数据根据该数据具有的所述索引并依照所述顺序储存到与所述多个运算器中的1个所述运算器对应的所述系数存储电路,
所述输入接口在从所述外部装置受理到所述输入数据时,向该输入数据的所述索引表示的所述运算器输出该输入数据。
4.根据权利要求1至3中的任意一项所述的运算电路,其中,
各所述运算器构成为对包含非零要素和零要素的系数矩阵从右乘以输入矢量并将运算结果输出到输出矢量,
所述输入数据包括所述输入矢量的要素,
所述系数数据包括所述系数矩阵的要素,
各所述运算器进而构成为依次执行对应的所述输入矢量的要素和所述系数矩阵的对应的要素的乘法,将该乘法的结果累计到所述输出矢量的要素。
5.根据权利要求4所述的运算电路,其中,
所述并行运算电路进而构成为对所述系数矩阵从右乘以输入矩阵,并将运算结果输出到输出矩阵,
所述输入矢量包括构成所述输入矩阵的行或者列矢量,
构成所述输出矩阵的行或者列矢量包括与各所述运算器对应的所述输出矢量。
6.根据权利要求5所述的运算电路,其中,
还具备输出接口,该输出接口包括构成为储存所述输出矩阵的多个输出存储电路,
所述多个输出存储电路构成为与所述多个运算器分别对应,
各所述输出存储电路构成为储存来自对应的所述运算器的所述输出矢量,
所述输出接口构成为根据所述索引,以列优先或者行优先从所述多个输出存储电路读出所述输出矩阵的要素。
7.根据权利要求6所述的运算电路,其中,
所述输出接口构成为依照控制指令,以所述列优先或者所述行优先从所述多个输出存储电路读出所述输出矩阵的要素。
8.根据权利要求7所述的运算电路,其中,
在将所述输出矩阵作为所述输入矩阵输出给其他所述运算电路时,所述控制指令包括根据所述输出矩阵的要素表示的数据的种类而依照列优先以及行优先中的某一方的读出指令。
9.根据权利要求8所述的运算电路,其中,
所述数据的种类包括图像。
10.根据权利要求4至9中的任意一项所述的运算电路,其中,
所述系数存储电路包括环形缓冲器,
所述系数存储电路构成为在所述环形缓冲器中储存构成所述系数矩阵的行或者列矢量的要素。
11.根据权利要求10所述的运算电路,其中,
所述要素具有的索引进而指定应运算该要素的所述运算器,
所述输入接口构成为将来自外部装置的所述系数矩阵的所述行或者列矢量的要素根据该要素具有的所述索引并依照所述顺序写入到与所述多个运算器中的1个所述运算器对应的所述系数存储电路的环形缓冲器。
12.根据权利要求1至11中的任意一项所述的运算电路,其中,
所述运算电路还具备共享存储器,该共享存储器构成为储存所述多个运算器中的1个运算器的运算结果,能够从其他所述运算器读出。
13.根据权利要求6至9中的任意一项所述的运算电路,其中,
所述输出接口还包括:输出电路;以及多个端口,将来自各所述运算器的所述输出矢量输出到所述外部装置,
所述多个输出存储电路与所述多个端口分别对应,
所述输出电路构成为在从各所述运算器受理到所述输出矢量的要素时,根据预先决定的基准信息和该要素的所述索引,从所述多个输出存储电路中选择1个输出存储电路,在选择出的输出存储电路中储存该要素。
14.根据权利要求13所述的运算电路,其中,
所述输出电路进而构成为依照基于所述预先决定的基准信息和所述输出矢量的要素的所述索引的顺序,在所述选择出的输出存储电路中储存该要素。
15.根据权利要求13或者14所述的运算电路,其中,
所述输出电路在预先决定的数量的要素储存于所述多个输出存储电路时,经由所述多个端口,输出所述多个输出存储电路的所述要素。
16.根据权利要求15所述的运算电路,其中,
所述输出电路在所述预先决定的数量的要素储存于所述多个输出存储电路时,将经由所述多个端口输出该要素的意思的通知,输出到所述外部装置。
17.根据权利要求13至16中的任意一项所述的运算电路,其中,
各所述输出存储电路包括二重化的输出存储电路,
所述二重化的输出存储电路的一方构成为储存来自所述运算器的所述输出矢量的要素,在储存完成时,通过对应的所述端口读出要素,
所述二重化的输出存储电路的另一方构成为通过对应的所述端口读出所述要素而读出完成时,储存来自所述运算器的所述输出矢量的要素。
18.根据权利要求4所述的运算电路,其中,
所述外部装置包括其他所述运算电路,所述输入矢量包括从其他所述运算电路具备的各所述运算器输出的矢量。
19.根据权利要求4所述的运算电路,其中,
所述运算电路用于执行卷积神经网络中的卷积层的运算,
所述输入矢量是将输入到所述卷积层的特征映像展开为一列而成的,
所述系数矩阵与在所述卷积层中利用的内核对应。
20.一种运算方法,使用包括多个运算器的并行运算电路,其中,
所述并行运算电路包括构成为与各所述多个运算器对应并能够从该运算器读出的存储电路,
所述运算方法具备:从装置受理用于运算的系数数据或者输入数据,
所述输入数据以及所述系数数据具有指定应运算该数据的所述运算器以及该数据应被运算的顺序的索引,
所述运算方法还具备:
在受理到所述系数数据或者所述输入数据时,根据所述输入数据或者所述系数数据具有的所述索引,确定所述多个运算器中的1个所述运算器;以及
依照基于所述受理的输入数据或者系数数据具有的所述索引的所述顺序,将该受理的输入数据或者系数数据储存到与确定的所述运算器对应的所述存储电路。
21.一种运算方法,使用包括多个运算器的并行运算电路,其中,
所述并行运算电路包括构成为与各所述多个运算器对应并能够从该运算器读出的存储电路,
所述存储电路包括储存用于运算的系数数据的电路,
所述运算方法具备:从装置受理用于运算的输入数据,
所述输入数据以及所述系数数据具有指定应运算该数据的所述运算器以及该数据应被运算的顺序的索引,
所述存储电路构成为将所述系数数据依照基于该系数数据具有的所述索引的所述顺序储存,
所述运算方法还具备:
在受理到所述输入数据时,根据所述输入数据具有的所述索引,确定所述多个运算器中的1个所述运算器;以及
依照基于所述受理的输入数据具有的所述索引的所述顺序,将该输入数据输出到确定的所述运算器。
- 还没有人留言评论。精彩留言会获得点赞!