神经网络加速器的系统和体系结构的制作方法
相关申请
本申请要求于2017年12月4日提交的美国临时申请62/594,106的优先权,其全部内容通过引用合并于此。
本公开涉及硬件处理器,尤其涉及硬件处理器以及神经网络加速器电路的相关系统和体系结构。
背景技术:
处理器是实现指令集体系结构(isa)的硬件处理装置(例如,中央处理单元(cpu)或图形处理单元(gpu)),该指令集体系结构包含对数据元素进行操作的指令。向量处理器(或阵列处理器)可以实现isa,其包含对数据元素的向量进行操作的指令。向量是包含有序标量数据元素的单向数组。通过对包含多个数据元素的向量进行操作,向量处理器与仅支持对单个数据元素进行操作的标量指令的标量处理器相比,可实现显著的性能提升。
附图说明
通过以下给出的详细描述和本公开的各个实施例的附图,将更充分地理解本公开。然而,不应将附图用于将本公开限制于特定实施例,而仅是为了解释和理解。
图1示出了根据本公开的实施方式的包括通用处理器技术的简单神经网络(gsnn)加速器电路的系统。
图2示出了根据本公开的实施方式的3×3过滤器。
图3示出了根据本公开的实施方式的一组过滤器。
图4示出了根据本公开的实施方式的八个电路条的组合。
图5示出了根据本公开的实施方式的两种存储器寻址方案。
图6示出了根据本公开的实施方式的加速器电路。
图7示出了根据本公开的实施方式的使用一组寄存器作为处理器与加速器电路之间的接口的系统。
图8描绘了根据本公开的实施方式的通过处理器来操作gsnn加速器电路的方法的流程图。
图9详细示出了根据本公开的实施方式的gsnn加速器电路。
具体实施方式
可以采用处理器,尤其是向量处理器来执行复杂的计算,例如神经网络应用。神经网络被广泛用于人工智能(ai)应用中。本公开中的神经网络是人工神经网络,其可以在电路上实施以基于输入数据做出决策。神经网络可以包括一层或多层节点。这些层可以是输入层、隐藏层或输出层中的任何一个。
输入层可以包括接触于输入数据的节点,并且输出层可以包括接触于输出的节点。输入层和输出层是可见层,因为可以从神经网络外部对其进行观察。输入层和输出层之间的层被称为隐藏层。隐藏层可以包括以硬件实现的节点,以执行从输入层传播到输出层的计算。可以使用一组通用的预定函数,例如过滤器函数和激活函数来进行计算。过滤器函数可以包括乘法运算和求和(也称为归约)运算。激活函数可以是全通函数、矩形函数(rect)、s型函数(sig)或双曲正切函数(tanh)中的任何一种。
可以使用过滤器函数和激活函数的不同组合来形成不同种类的神经网络。随着针对不同应用开发新的神经网络体系结构,需要一种灵活的神经网络体系结构,该体系结构可用于实施这些不同种类的神经网络以满足不同应用的需求。
本公开的实施方式提供了一种技术解决方案,该技术解决方案包括灵活的神经网络体系结构,该体系结构可以容易地适于提供不同种类的神经网络的硬件实施。根据一个实施方式的系统可以包括处理器和通信地耦合到处理器的加速器电路。处理器可以是硬件处理装置(例如,中央处理单元(cpu)或图形处理单元(gpu)),其实施包含对数据元素进行操作的指令的指令集体系结构(isa)。在一些实施方式中,处理器可以是实施包含对数据元素的向量进行操作的指令的isa的向量处理器。
处理器通常是通用处理装置。尽管可以对处理器进行编程以执行神经网络应用,但是处理器的设计并未提供最有效的体系结构来在神经网络的隐藏层中执行计算。为了提高神经网络计算的速度和效率,本公开的实施方式包括通信地耦合到处理器以向处理器提供计算支持的加速器电路。加速器电路与处理器协同工作,以实现高速和高效的神经网络实施方式。
在一个实施方式中,加速器电路是通用处理器技术的简单神经网络(gsnn)加速器电路。gsnn加速器电路可以包括用于加速神经网络的计算的硬件电路。在顶层,gsnn加速器电路是异构计算系统,其可以包括可以同时并行运行的多个可编程电路块,其中每个电路块可以指定为执行特定类型的任务(例如,输入、过滤器、后处理和输出等)。电路块可以共享一个内部存储器,其中每个电路块可以从该内部存储器读取数据和向该内部存储器写入数据。因此,电路块可以使用内部存储器传递参数数据。
加速器电路的每个电路块可以包括其自己的用于控制操作的完全可编程处理处理器。在另一个实施方式中,两个或更多个(但少于全部)电路块可以共享一个公共的完全可编程处理处理器,以控制两个或更多个电路块的操作。在另一实施方式中,一个电路块可以包括多于一个的完全可编程处理处理器,它们协同工作以控制电路块的操作。
在一个实施方式中,处理处理器可以是具有电路实施方式的精简指令集计算机(risc)处理器,以为其电路块并为与其他电路块的处理处理器进行协调而生成控制信号。每个risc处理器都是硬件处理器,可以执行根据通用指令集体系结构(isa)指定的通用指令集。此外,每个risc处理器可以执行根据它们各自的isa指定的指令,以执行专门分配给每个risc处理器的任务。gsnn加速器电路可以进一步包括通用寄存器文件,该通用寄存器文件包括通用寄存器。处理器可以实施使用通用寄存器文件来协调不同电路块中的处理处理器之间的操作的指令。例如,特殊指令可以建立从神经网络中的第一层节点(生产者)到第二层节点(消费者)的流水线操作。
在一个实施方式中,电路块(称为过滤器电路块)可以实现过滤器功能。过滤器电路块可以被组织成多个重复的电路条以实现可伸缩性,即,在不改变过滤器电路块上的过滤器处理处理器的情况下适应于不同种类的神经网络计算。每个电路条可以包括过滤器电路和专用于这些过滤器电路的内部存储器的片段。此外,过滤器电路块可以包括本地寄存器文件,该本地寄存器文件包括与存储器负载扇出机制结合的本地寄存器(即,来自生产者的一个输出馈送到消费者的最大数目的输入),支持1d、2d和具有跳过过滤功能的2d中的有效执行和数据重用。
在一个实施方式中,另一单独的电路块(称为后处理电路块)可以实现激活功能。后处理电路块可以与过滤器电路块同时并行地运行。除了激活功能之外,后处理电路块还可以提供提取功能和/或top-n功能的实施方式。在另一实施方式中,后处理电路块是共享一个公共risc处理器的过滤器电路块的组成部分,而不是两个单独的电路块。
以这种方式,gsnn加速器电路可以提供灵活的体系结构以支持处理器对不同种类的神经网络的有效执行。gsnn体系结构的灵活性允许高效地容纳不同种类的神经网络,而无需修改硬件。
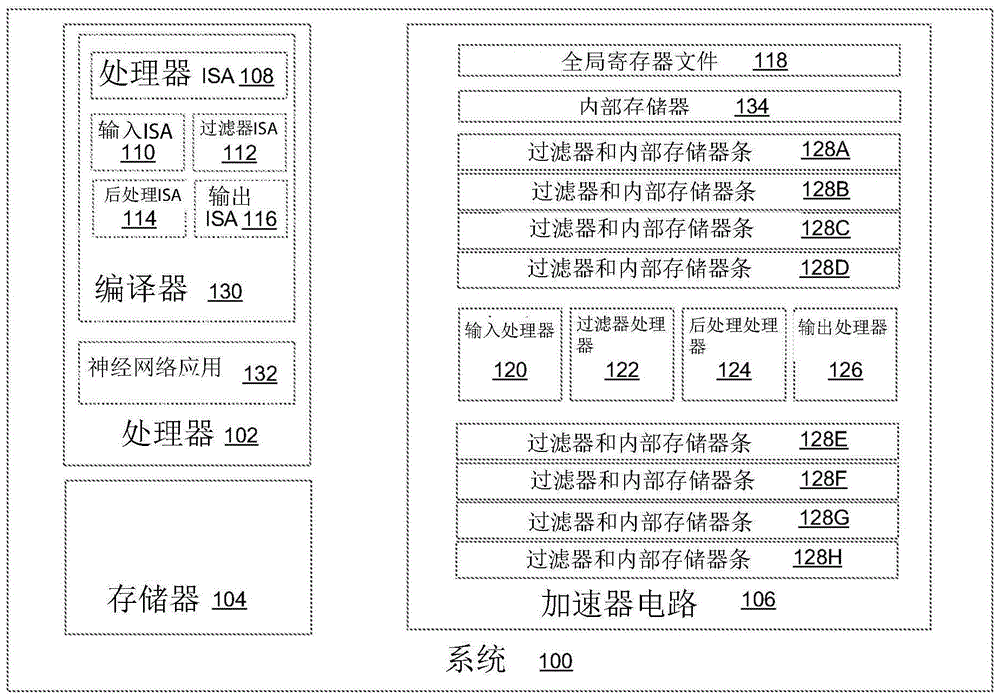
图1示出了根据本公开的实施方式的包括gsnn加速器电路的系统100。如图1所示,系统100可以包括处理器102、加速器电路104和存储器装置106。系统100可以是计算系统或片上系统(soc)。处理器102可以是硬件处理器,诸如中央处理单元(cpu)、图形处理单元(gpu)或任何合适类型的处理装置。处理器100可以包括指令执行流水线(未示出),寄存器fde(未示出)以及实施根据指令集体系结构(isa)108指定的指令的电路。这些指令可以被分解为由指令执行流水线处理的微操作(micro-op)。
在一个实施方式中,处理器100可以是向量处理器,其包括向量指令执行流水线(未示出)、向量寄存器文件(未示出)以及实施根据向量指令集体系结构(isa)指定的向量指令的电路。向量指令可以对包含一定数量的数据元素的向量进行操作。在一个实施方式中,向量指令可以是可变长度向量指令,其中可以通过指令(而不是预设)来明确指定应用于向量的操作的数量。可以直接将操作的数量指定为可变长度向量指令的立即值,或可替代地,使用存储长度值的寄存器间接指定操作的数量。因此,在可变长度向量指令的执行期间可以动态地改变操作的数量,这允许由向量指令指定的操作的数量小于(或大于)向量的长度。向量的长度被定义为向量可以容纳的最大数据元素数。为了简明起见,本公开在本文中将标量和向量处理器都称为处理器。因此,除非另外明确指定,否则处理器可以理解为标量处理器或向量处理器。
存储器装置106可以包括通信地耦合到处理器102和加速器电路104的存储装置。在一个实施方式中,存储器装置106可以存储输入至神经网络应用的输入数据112以及由神经网络应用生成的输出数据114。输入数据112可以是从应用数据中提取的特征值,例如图像数据、语音数据等,输出数据可以是由神经网络做出的决策,其中决策可以包括将图像中的对象分类为不同的类别、图像中对象的识别、或语音中短语的识别。
加速器电路104可以通信地耦合到处理器102和存储器106,以使用其中的专用电路来执行计算密集的任务。加速器电路104可以代表处理器102执行这些任务。例如,可以对处理器102进行编程,以将神经网络应用分解为多个(数百或数千个)计算任务,并将这些任务的执行委托给加速器电路104。在加速器电路104完成这些任务之后,处理器102可以接收到返回的计算结果。加速器电路104可以是专用集成电路(asic)、现场可编程门阵列(fpga)、数字信号处理器(dsp)、网络处理器等。
在一个实施方式中,如图1所示,加速器电路106可以被实施为gsnn加速器电路,其可以包括全局寄存器文件118、包括输入处理器120的输入电路块、包括过滤器处理器122的过滤器电路块、包括后处理处理器124的后处理电路块、以及包括输出处理器126的输出电路块。此外,加速器电路106可以包括内部存储器134和组织为电路条128a-128h的过滤器电路。在一个特定的实施方式中,内部存储器134可以是2mb的多排存储器装置。
在一个实施方式中,输入处理器120、过滤器处理器122、后处理处理器124和输出处理器126中的每一个可以是具有电路实施方式以生成控制相应的电路块的控制信号的精简指令集计算机(risc)处理器。因此,输入处理器120可以控制输入电路块的操作;过滤器处理器122可以控制过滤器电路块的操作;后处理处理器124可以控制后处理电路块的操作;输出处理器126可以控制输出电路块的操作。
在一个实施方式中,过滤器电路块可以包括过滤器处理器122、内部存储器134的一部分、以及实现1d、2d和具有跳过过滤功能的2d的过滤器电路。内部存储器134可以是加速器电路106上的存储器,其由输入处理器120、过滤器处理器122、后处理处理器124和输出处理器126共享。内部存储器134的一部分和过滤器电路块的过滤器电路可以根据电路条128a-128h来组织。每个电路条128a-128h可包含一定数量的过滤器电路和专用于电路条上的过滤器电路的内部存储器的相应片段。过滤器处理器122可以控制电路条128a-128h的操作。
在一个实施方式中,加速器电路106可以包括八(8)个电路条128a-128h,其中每个电路条可以包括相同的电路组件,从而实现过滤器电路块的可伸缩构造。电路条的数量可以大于或小于八(8)。但是,数字八(8)可以提供与可用的输入/输出带宽的平衡。此外,过滤器电路块可以包括寄存器结构,该寄存器结构与存储器负载扇出机制结合(即,来自生产者的一个输出馈送到消费者的最大数目的输入),支持1d、2d和具有跳过过滤功能的2d中的有效执行和数据重用。
加速器电路106还可以包括输入电路块(图1中未示出)、后处理电路块(图1中未示出)、以及可以与过滤器电路块并行运行的输出电路块(图1中未示出)。具体地,后处理电路块可以包括实施激活功能、提取功能或top-n功能中的至少一个的电路(对于可编程n,其中n是大于1的整数值)。输入电路块可以包括输入处理器120以控制从存储器104到加速器电路106的内部存储器134的数据复制。相反,输出电路块可以包括输出处理器126以控制从加速器电路106的内部存储器134到存储器104的数据复制。相反,过滤器电路块和后处理电路块可以从内部存储器读取它们的输入,并且将它们的输出写入内部存储器,从而实现与外部存储器104的隔离。
在操作中,可以将处理器102分配为执行神经网络应用132的计算。神经网络应用132可以是包括以诸如java、c++、python等的编程语言编写的源代码的程序。神经网络应用132可以是为神经网络确定合适的权重参数的训练程序,或者是基于训练后的神经网络做出决策(例如,对象识别和检测)的决策程序。为了加速程序的执行,程序员可以可选地为由加速器电路106执行的程序的源代码的某些部分提供标记。
处理器102还可执行编译器130,以将神经网络应用132的源代码转换为根据一个或多个指令集体系结构(isa)指定的机器可执行指令的序列。机器可执行指令的分类可以基于由程序员提供的标记,或者基于编译器132对源代码的分析。标记可以包括分配给电路块(例如,过滤器电路块)的任务的开始标识符和任务的结束标识符。在一个实施方式中,这些机器可执行指令可以包括由处理器102的执行流水线执行的根据处理器isa108指定的第一类指令。此外,这些机器可执行指令可以包括由输入处理器120执行的根据输入isa110指定的第二类指令;由过滤器处理器122执行的根据过滤过滤器isa112指定的第三类指令;由后处理处理器124执行的根据后处理isa114指定的第四类指令;根据输出isa116指定的第五类指令。
处理器102可以执行第一类指令以将对神经网络应用有用的数据加载到存储器104中。该数据可以是该应用的输入数据和/或神经网络应用132的系数数据。处理器102也可以执行第一类指令,以将数据存储器中的数据和指令存储器中的第二、第三、第四和第五类的指令加载到加速器电路106,以由输入处理器120、过滤器处理器122、后处理处理器124和输出处理器126执行。处理器102还可以利用完成由输入处理器120、过滤器处理器122、后处理处理器124和输出处理器126执行的任务所需的初始值来初始化全局寄存器文件118(及其相关联的影子寄存器)中的全局寄存器。
响应于接收到指令存储器中的第二类指令,输入处理器120可执行第二类指令以执行输入操作,例如,将数据从存储器104复制到加速器电路106的内部存储器134。响应于接收到指令存储器中的第三类指令,过滤器处理器122可以执行第三类指令以使用电路条128a-128h中的过滤器电路来执行过滤器操作。过滤器处理器122可以从由输入处理器120设置的内部存储器读取输入数据和参数,并将结果写入内部存储器。响应于接收到指令存储器中的第四类指令,后处理处理器124可以执行第四类指令以执行诸如激活函数、提取函数或top-n函数的后处理操作。后处理处理器124可以从由过滤器处理器122设置的内部存储器读取输入数据和参数,并将结果写入内部存储器。响应于接收到第五类指令,输出处理器125可以将结果数据从内部存储器复制到存储器104。
下面提供对过滤器电路块、后处理电路块、输入电路块和输出电路块的详细描述。
神经网络的最重要的操作是过滤器操作。过滤器电路块可以包括实现乘法和归约运算的过滤器电路,或者硬件电路中的
在一个实施方式中,如图1所示,gsnn加速器电路106可以包括过滤器电路,该过滤器电路包含具有预定数量(例如9=3×3)条目的大小的过滤器的实施方式。图2示出了根据本公开的实施方式的3×3过滤器200。如图2所示,过滤器200可以包括两个寄存器202、204,其保存的数据值可以是权重值和要被过滤的输入值。数据值可以由连接到9个乘法器以形成归约树208的9个半精度(16位)浮点数表示。为了实现更大的过滤器,过滤器200可以包括求和电路206以将归约运算符(乘法)的结果与来自另一个过滤器的部分和相加。由归约树生成的中间值可以使用半精度16位以外的表示形式来提高结果的准确性。最终结果将转换回16位半精度。
为了提高性能,本公开的实施方式可以提供包含多个并行过滤器的过滤器组。图3示出了根据本公开的实施方式的一组过滤器300。如图3所示,该组可以包括并行实施的四个过滤器(作为示例)302a-302d。在神经网络计算的情况下,所有过滤器302a-302d可能共享两个输入寄存器之一。在gsnn中,存储权重值的过滤器304可以由所有过滤器302a-302d共享,而输入寄存器306a-306d可以将输入值存储到每个单独的过滤器302a-302d。
过滤器处理器122可以执行输入指令以将输入值从内部存储器复制到输入寄存器306a-306d。输入指令可以处于不同的复制模式,例如,每条指令复制三个、六个或九个半精度值。例如,wt9(权重9直接)模式可以指示将9个半字从内部存储器复制到权重寄存器中的9个元素。wt3(权重3移位)模式可以指示从内部存储器复制三个半字,并将这三个半字移位到权重寄存器中。当程序通过从较大的2d阵列内部读取3x3阵列来聚集9个值时,使用wt3模式。在那种情况下,程序使用3次wt3读取的序列来获得9个值,每次都从一行中读取3个值。
in9(输入9移位)模式可以指示四个过滤器组中最低的三个输入寄存器的内容被向上移位,并且9个半字从存储器读取到第一输入寄存器中。为了加载所有四个输入寄存器,可以依次使用四个in9操作。
实施方式可以包括用于指定应被写入的输入寄存器的替代方法。例如,该指令可能已指定应该已经被写入寄存器0至3中的一个寄存器的9个半字。实施方式可以选择移位方法,因为它更容易编码并且允许更多并行过滤器。例如,如果使用八个并行过滤器,则移位实施方式将执行八个in9操作来加载所有八个输入寄存器,而另一种方法将需要修改编码以指定寄存器0至7(而不是寄存器0至3)。
in6(输入6复制)模式可以指示将6个半字从内部存储器复制到输入寄存器。将每个输入寄存器的内容与wt3相似地移位3次,并移入3个半字。
in9x2(输入9以步长2复制)模式可以指示将9个半字从内部存储器复制到输入寄存器。每个输入寄存器的内容与wt3相似地移位3次,并移入3个半字。该模式支持在使用步长为2的3x3大小的过滤器的卷积神经网络(cnn)中发现的数据重用模式。
在一个实施方式中,加速器电路上的电路条可以包括可以组合在一起的四个过滤器电路。图4示出了根据一个实施方式的八个电路条的组合400。如图4所示,每个电路条402a-402h可以包含四个过滤器的相应组。每个过滤器组产生四个结果。这些结果可以被写回到内部存储器134,总共32个半字写入。可替代地,可以使用跨越八个电路条的求和电路404将四个结果中的每个求和在一起,以将总共四个半字结果写入内部存储器134。
过滤器电路块还可以支持零填充。零填充可以通过将3/6/9输入值中的任何一个清零(在零掩码的控制下)来实现。可以(在过滤器掩码的控制下)禁用特定电路条的过滤器。如果过滤器被禁用,它将不会读取或写入任何值。如果进行了组合,则禁用片段的所有过滤器输出将被视为零。
在一个实施方式中,如图1所示的gsnn加速器电路106可以包括后处理电路块,该后处理电路块包含神经网络引擎所需的后处理函数的实施方式。后处理函数可以包括提取/池化、激活和排序/top-n函数。这些函数全部涉及从内部存储器134读取4/6/8个半字、执行后处理函数、以及更新寄存器的内部状态或将2/4个半字写入内部存储器134。
后处理函数可以包括压缩函数(即,提取/最大池化)。该压缩函数的操作是将n个元素的输入数据压缩为一个元素。1-4个半字可以压缩为1个半字。为了提高性能,可以并行执行多个压缩。四种可能性是:
4->l:在输入处读取8个半字,并输出2个半字
3->l:在输入处读取6个半字,并输出2个半字
2->l:在输入处读取8个半字,并输出4个半字
1->1:在输入处读取4个半字,并输出4个半字
在压缩操作期间,选择组的第一个值或选择组中所有元素的最大值。选择第一个值用于提取,并选择最大值用于最大池化。
可以可选地进一步将2/4压缩结果与后处理电路块的本地寄存器中保存的2/4值进行并行比较;将这些值中的最大值提供给输出。
输出可以写回到内部寄存器或发送到激活阶段以进行进一步处理。
该多阶段方法可以用于实现最大池化函数。例如,要实现2x2最大池化:
使用来自行n的8个元素利用最大值进行2->l压缩,并通过写入内部寄存器保存结果;
使用来自行n+1中的8个元素利用最大值进行2->l压缩,与保存的结果进行比较,然后输出4个结果
这两个操作执行4个并行使用2个操作的2x2最大池化操作。
后处理函数可以包括激活函数。来自提取阶段的2/4输出被进一步处理。存在4种可能的选择:
无(无动作标识函数):输入值被传递而不变或yi=xi
rect:将负值转换为0并传递其他值而无需改变的阶跃函数
sig:s型函数,其计算结果如下:
tanh:双曲正切函数,其计算如下:
yi=tanhxi
后处理函数可以包括top-n函数。优化实现top-n函数的逻辑电路以找到阵列中的最大的n个值和阵列中最大的n个值的相应位置,其中n是整数值。找到最大n个值的计算可以包括对阵列中所有元素的n次迭代。该逻辑电路可用于对整个阵列进行排序。如果阵列具有总共l个元素,则找到top-l将得到阵列中值的排序列表及其原始位置。
为了在内部存储器中存储的阵列中找到最大值,逻辑电路可以一次读取该阵列的四个元素,直到读取了整个阵列为止。第一次读取时,记录最大值及其位置。对于后续读取,将四个元素的最大值与记录的最大值进行比较。如果后读取的最大值较大,则保存该值及其位置。最后一次读取后,最大值和位置会在内部存储器中写出,以存储最后写入的位置和值。
对于后续搜索,忽略阵列中大于最后写入值或与最后写入值相同但位置早于或等于最后写入位置的所有值。如果找到了n个最大值,则该机制使搜索忽略先前找到的最大n个值,并搜索下一个最大值。处理完所有元素后,下一个最大值和位置将写入内部存储器并保存。
在一个实施方式中,如图1所示的gsnn加速器电路106可以包括负责将数据从外部存储器104复制到内部存储器134的输入电路块。可以将从外部存储器104读取的值指定为半精度浮点数、有符号字节或无符号字节。输入电路块可以将字节值转换为相应的半精度浮点值,其中有符号字节被视为-128至127之间的数字,而无符号字节被视为0至128之间的数字。输入电路块可以从存储器104中读取并写入内部存储器的特定存储器地址。可替代地,输入电路块可以向所有电路条128a-128h广播,以将每个值以相同偏移量写入分配给电路条128a-128h的内部存储器134的每个片段中。
在一个实施方式中,如图1所示的gsnn加速器电路106可以包括负责将数据从内部存储器复制到外部存储器104的输出电路块。从内部存储器134读取的值可以按原样作为半精度浮点数写入,或者可以转换有符号或无符号字节数。如果指定了有符号字节输出,则通过舍弃小数部分(即舍入到零)将浮点数转换为整数。如果值超出-128到127之间的范围,则正值将饱和到127,负值将饱和到-128。类似地,如果指定了无符号字节输出,则浮点值被截断,并且值将饱和为255或0。
加速器电路106可以包括内部存储器134,该内部存储器134由输入电路块、过滤器电路块、后处理电路块和输出电路块共享,并且可以由输入处理器120、过滤器处理器122、后处理引擎124和输出处理器126访问。在一个实施方式中,为了允许多个并行访问并允许以任意对齐方式访问,内部存储器134通过将存储器划分为多个阵列来实现。在gsnn加速器电路的当前实施方式中,512x128位(=16字节)形成一个阵列,并且有256个包含8kb的阵列构成一个总量为2兆字节的内部存储器。
为了寻址的目的,可以将阵列组织成偶/奇对,其中可以从偶数阵列读取地址(0至15)mod32,而从奇数阵列读取地址(16至31)mod32。每对偶数/奇数阵列可以形成一个存储体。因此,内部存储器可以包括16个存储体,每个存储体包括一个偶数阵列和一个奇数阵列,每个阵列均包含512x126位。在一个实施方式中,可以将阵列进一步分组为存储器片段,其中分配给相应电路条的每个存储器片段可以与内部存储器的256kb相关联。因此,地址nmod256*1024属于片段n。以这种方式,可以将地址指定为相对于片段的起始地址处于特定偏移量处。可替代地,可以将地址指定为属于偶数/奇数阵列对的存储体中的一行。图5示出了根据本公开的实施方式的两个存储器寻址方案500。如图5所示,内部存储器可以使用第一方案502,使用片段标识符和偏移量来寻址。当使用该方案访问内部存储器时,指令可以使用片段标识符来寻址内部存储器的片段,并用相对于片段的起始位置的偏移量来寻址特定位置。
可替代地,可以使用存储体和行来寻址内部存储器,如使用第二方案504所示。在一个实施方式中,所有地址可以与半字边界对齐。这意味着地址的位0应该在位置0对齐。存储体的偶/奇对配置允许从任何2字节边界开始读取多达9个半字。例如,要从内部地址oxloe开始写入4字节的数据,过滤器处理器122或后处理处理器124可以将2字节写入存储体0的偶数阵列的行8的末尾,并将2字节写入存储体0的奇数阵列的行8的开始。类似地,为了读取从地址0x13ffo开始的18字节的数据,过滤器处理器122或后处理处理器124可以从存储体4的奇数阵列的最后一行读取16字节,并从下一个存储体(即5)的偶数阵列的第一行读取2字节。虽然可以从属于不同存储体的偶/奇阵列中获取值,但是如果存储体属于不同片段,则不允许这样做。因此,不可能在同一访问中从存储体15的末尾和存储体16的开头进行读取,因为存储体15和存储体16属于不同的片段。
存储器读取或写入可以是全局访问或按片段访问。在全局访问中,地址是指内部存储器134中的存储器位置的范围。该连续范围被读取或写入。在按片段访问中,地址是指对内部存储器134的连续范围的同时访问,每片一个。地址中的偏移量可用于标识每个片段的存储器范围,并且在每个片段中读取/写入该偏移量。
在以下总结的不同情况下,来自各个块的访问可以是全局的或按片段的访问:
·过滤器数据读取是按片段操作;
·如果在组合模式下运行,过滤器部分和读取为全局操作,否则为按片段操作;
·如果在组合模式下运行,写入过滤器结果为全局操作,否则为按片段操作;
·后读取是全局操作;
·后写入是全局操作;
·如果广播,输入写入是按片段操作,否则是全局操作;以及
·输出写入是全局操作。
输入电路块、过滤器电路块、后处理电路块和输出电路块中的每一个可包括处理器,以控制相应电路块的操作。每个处理器可以是简单的32位哈佛体系结构risc处理器。四个处理器可以各自包括它们自己的寄存器、指令存储器和数据存储器,并且彼此同时运行。还有一组共享的全局寄存器。图6示出了根据本公开的实施方式的加速器电路600。如图6所示,加速器电路600可以包括输入处理器602a、过滤器处理器602b、后处理处理器602c和输出处理器602d。输入处理器602a、过滤器处理器602b、后处理处理器602c和输出处理器602d中的每一个可各自包括各自的指令存储器604a-604d、数据存储器606a-606d和本地寄存器608a-608d。输入处理器602a、过滤器处理器602b、后处理处理器602c和输出处理器602d可以共享全局寄存器610。这些处理器可以为它们各自的电路块生成控制信号和存储器读/写地址,并且可以通过使用共享状态协调处理器的动作。
在一个实施方式中,每个处理器可以具有以下状态:
·32位程序计数器(pc),用于存储要执行的下一条指令的地址;
·16个32位本地寄存器,$r0...$rl5;
·16个共享的32位全局寄存器,$g0...$gl5;
·16kb字(32位)寻址的数据存储器:以及
·16kb字(32位)寻址的指令存储器。
如图1所示,输入处理器602a、过滤器处理器602b、后处理处理器602c和输出处理器602d可以各自执行根据它们各自的isa110、112、114、116指定的指令。根据isa,寄存器字段可以存储5位标识符,允许识别32个寄存器。值0-15代表寄存器$r0-$rl5,而值16-31可以代表全局寄存器$g0-$gl5。所有立即地址(用于分支和存储器操作)都是绝对地址,而不是相对于程序计数器(pc)的地址。此外,地址是32位(字)数量。指令存储器604a-604d中的指令和数据存储器606a-606d中存储的数据都是32位字。应当注意,处理器专用的本地指令和数据存储器不同于用于馈送各个电路块的内部存储器。
每个引擎可以与用于为其所控制的块生成控制的特殊指令相关联。这些指令可以采用表1中指定的格式。
表1
输入处理器可以执行根据输入isa110指定的以下指令:
复制(copy)
将通用寄存器rt设置为rb中的值。
复制立即(copyimmediate)
将通用寄存器rt设置为经零扩展后的imm字段中的16位值。
复制上部(copyupper)
将通用寄存器rt设置为左移16位的rb中的值。
复制上部立即(copyupperimmediate)
将通用寄存器rt设置为左移16次的imm字段中的16位值。
加(add)
将通用寄存器rt设置为ra和rb中的值之和。
加立即(addimmediate)
将通用寄存器rt设置为ra中的值与经零扩展后的imm字段中的16位值之和。
减(subtract)
将通用寄存器rt设置为ra中的值与rb中的值之差。
减立即(subtractimmediate)
将通用寄存器rt设置为ra中的值与经零扩展后的imm字段中的16位值之间的差。
右移(shiftright)
将通用寄存器rt设置为右移了rbmod32次的ra中的值,其中移入了零。
右移立即(shiftrightimmediate)
将通用寄存器rt设置为右移了imm字段的低5位的ra中的值,其中移入了零。
算术右移(shiftrightarithmetic)
将通用寄存器rt设置为右移了rbmod32次的ra中的值,其中移入ra的符号。
右移立即(shiftrightimmediate)
将通用寄存器rt设置为右移imm字段的低5位的ra中的值,其中移入ra的符号。
左移(shiftleft)
将通用寄存器rt设置为左移rbmod32次的ra中的值,其中移入零。
左移立即(shiftleftimmediate)
将通用寄存器rt设置为左移imm字段的低5位的ra中的值,其中移入零。
乘(multiply)
将通用寄存器rt设置为ra中的值与rb的低16位的乘积的低32位。
乘立即(muliplyimmediate)
将通用寄存器rt设置为ra中的值与imm字段的乘积的低32位。
或(or)
将通用寄存器rt设置为ra和rb中的值的按位或(bit-wiseor)。
或立即(orimmediate)
将通用寄存器rt设置为ra中的值与经零扩展的imm字段中的16位值的按位或。
与(and)
将通用寄存器rt设置为按位和的ra和rb的值。
与立即(andimmediate)
将通用寄存器rt设置为ra中的值与经零扩展的imm字段中的16位值的按位与(bit-wiseand)。
异或(exclusiveor)
将通用寄存器rt设置为ra和rb中的值的按位异或。
异或立即
将通用寄存器rt设置为ra中的值与经零扩展的imm字段中的16位值的按位异或。
补码与(complementandand)
将通用寄存器rt设置为值ra的补码与rb中的值的按位与。
补码与立即(complementandandimmediate)
将通用寄存器rt设置为值ra的补码与经零扩展的imm中的16位值的按位与。
加载(load)
将通用寄存器rt设置为引擎数据存储器中的字,该字地址为rb与经符号扩展的编码在off中的11位值之和。
加载绝对(loadabsolute)
将通用寄存器rt设置为引擎数据存储器中的字,该字地址为经零扩展的imm字段中的16位值。
加载更新(loadupdate)
将通用寄存器rt设置为引擎数据存储器中的字,该字地址为rb与经符号扩展的编码在off中的11位值之和。存储在寄存器rb中的值增加经符号扩展的off的值。
rb是本地寄存器。
store(存储)
将引擎数据存储器中的字设置为寄存器ra中存储的值,该字地址为rb与经符号扩展的编码在off中的11位值之和。
存储绝对(storeabsolute)
将引擎数据存储器中位于地址imm的字设置为存储在寄存器ra中的值。
存储更新(storeupdate)
将引擎数据存储器中的字设置为寄存器ra中存储的值,该字地址为rb与经符号扩展的编码在off中的11位值之和。寄存器rb中存储的值增加经符号扩展的off中的值。
rb是本地寄存器。
跳转(jump)
如上面的伪代码所示,jump指令在执行时可以基于条件码(cc)的值将通用寄存器ra中的值与0进行比较。如果结果为真(true),则将rb中的值加载到pc中,其中0b000的cc值总是为真,因此无条件执行跳转。obloo的cc值未定义。
跳转绝对(jumpabsolute)
如上面的伪代码所示,jumpabsolute指令在执行时可以基于条件码将通用寄存器ra中的值与0进行比较。如果结果为真,则将指令的imm字段中的值加载到pc中。obooo的cc值总是为真,因此无条件执行跳转。ob100的cc值未定义。
等待(wait)
如上面的伪代码所示,wait指令在执行时可以基于条件码将通用寄存器ra中的值与0进行比较。如果结果为假(false),则重复该指令。obooo的值总是为真,因此该指令为空操作指令。ob100的cc值未定义。
该指令可用于协调引擎之间的活动。通常,ra是全局寄存器。引擎将等待全局寄存器,直到另一个引擎写入该寄存器。
调用(call)
将通用寄存器rt设置为下一条指令的地址,并将pc设置为寄存器rb的值。
调用立即(callimmediate)
将通用寄存器rt设置为下一条指令的地址,并将pc设置为经零扩展的imm字段中的16位值的值。
输入(input)
input是用于控制输入电路块的特殊指令。参见下述inputi指令的详细信息。在input指令中,使用rb中的值代替在inputi指令中编码的立即值。
输入立即(inputimmediate)
inputi是用于控制输入块的特殊指令。该指令隐含地使用$r8、$r9、$rlo、$rl2、$rl3和$rl5,并更新$r8、$r9和$rlo:
·从外部存储器中由$rl5和$rlo连接而形成的地址处读取值。之所以使用连接,是因为外部地址可能大于32位。
·基于typ,读入的值可以被视为半精度值或字节。如果它们是字节,则将它们转换为等效的半精度值;
·可能转换后的值在由$r9标识的地址处写入内部存储器。基于mod字段的值,这可以是单个全局写入,也可以是对所有片段的广播。如果是广播,则将$r9中的值视为每个片段的偏移量,并将转换后的值在该偏移量处写入每个片段。否则,$r9被视为一个地址,并将该值写入该地址;
·读取的字节数由size(sz)字段指定;每次执行该指令,它将读取16*(sz+1)个字节;
·该指令以$rl2中的值增加$r9中的值,并以$rl3中的值增加$rlo中的值;以及
·如果lp字段为1,则指令将隐含地循环递减$r8,直到$r8为0。
过滤器处理器可以执行根据过滤器isa112指定的以下指令:
过滤(filter)
filter是控制过滤器电路块的特殊指令。有关详细信息,请参见filteri指令。在filter指令中,使用rb中的值代替在filteri指令中编码的立即值。
过滤立即(filterimmediate)
filteri是控制过滤器块的特殊指令。该指令隐含地使用$r8到$rl5,并可能更新$r8到$rll。
·控制大部分是按片段进行的。$rl5可以包含八个位,代表八个片段中的相应片段的启用/禁用标志。通过将$rl5中的一位设置为1,过滤器处理器122可以禁用相应片段中的过滤。
·filteri指令可从内部存储器中的$rlo指定的地址读取一个值;根据data字段的值,可以读取3、6或9的值;
·如果相应的mask位为高,则可以将这些值清零;
·将值写入weight或intput内部寄存器;
·如果发生以下情况,过滤器操作的唯一动作可能是加载指令:
οkind是oboo;
οkind为oblo,并且$r8中的值不是0mod2;或者
οkind是oxbl1,并且$r8中的值不是0mod4;
·否则,将在每个片段中计算出weight和input的4个点积;
·如果mod为1(即按片段)且sum为1(即部分和),则使用$rl1从每个片段读取4个值以提供偏移量,并将其添加到每个点积中;
·如果mod为1(即按片段),则将最后4个和写入每个片段中的$r9中的偏移量处的存储器中;
·否则,如果mod为0(即全局),则每个启用的片段中的所有4个和相加在一起,给出4个值;
·如果mod为0(即全局),并且sum为1(即部分和),则使用$rll作为地址从存储器中全局读取4个值,并将其加到这4个和中的每一个;
·如果mod为0(即全局),则将最后4个和写入存储器的$r9中的地址处;
·该指令以$rl3中的值增加$rlo中的值;
·如果过滤器计算结果,则以$rl2中的值增加$r9中的值;
·如果过滤器计算结果,且sum=obl,则以$rl4中的值增加$rl1中的值;以及
·如果lp字段为1,则指令将隐含地地循环递减$r8中的值,直到$r8中的值为0。
后处理处理器可以执行根据后处理isa114指定的以下指令:
后(post)
post是控制后处理电路块的特殊指令。有关详细信息,请参见下面的posti指令的说明。在post指令中,使用rb中的值代替posti指令中编码的立即值。
后立即(postimmediate)
posti是控制后处理电路块的特殊指令。该指令隐含地使用$r8、$r9、$rl0、$rl2和$rl3,并可能更新$r8至$r10。存在两种可能的操作模式;第一种是压缩[kind=0b00或kind=0b01]。
·posti指令在执行时可以从内部存储器中$rlo中指定的地址读取值;根据col字段的值,可以读取4、6或8的值;
ο如果col为oboo,则为4
ο如果col为obol或oblo,则为8
ο如果col为oblo,则为6
·基于col的值将这些值分为四组或两组;
ο如果col是oboo,则分为1个4组
ο如果col为obol,则分为2个4组
ο如果col为oblo,则分为3个2组
ο如果col为ob11,则分为4个2组
·通过取组的最大值(如果kind==oboo)或组的第一个元素(如果kind==oblo)来压缩组。如果col为oboo,则没有变化;
·如果row不为零,则计算压缩元素的最大值和内部状态reg中保存的值;
·如果row为obol并且$r8不是0mod2,或者row是ob11并且$r8不是0mod4,则最大值将保存在内部寄存器reg中;
·否则,最大值将被发送到激活电路;
·根据act字段的值,将以下函数之一应用于最大值:
ο恒等函数(act=oboo)
ο阶跃函数(act==obol)
οs型函数(act=oblo)
ο双曲正切函数(tanh)(act=0bl1)
·2个或4个函数结果的和在$r9中存储的地址处写入存储器;
·该指令以$rl3中的值增加$rlo中的值;
·如果post指令计算结果,则以$rl1中的值增加$r9中的值;
·如果lp字段为1,则指令将隐含地循环递减$r8中的值,直到$r8中的值为0。
第二种操作模式是top-n搜索[kind=0bl0]。
·如果ctl是obl1或oblo,则初始化内部状态
ο如果ctl是ob11,则将save_max/save_pos设置为+inf和0,
ο如果ctl为oblo,则将curr_max/curr_pos(先前确定的最大值/位置)复制到save_max/save_pos,或者
ο将curr_count重置为0;
·从内部存储器中在$rl0中指定的地址处读取四个输入值;
·对于每个输入值,post指令确定给定save_max/save_pos是否可接受。如果为如下,则可接受:
ο该值小于save_max,或者
ο该值等于save_max,但该值的位置大于save_pos
·对于每个可接受的输入值,如果它大于当前最大值,则其值和位置被保存在curr_max和curr_pos中;
·如果ctl为ob01,则将curr_max和curr_pos写入存储器的$r9中的地址处;
·指令以将$rl3中的值增加$rl0中的值;
·如果post指令计算结果,则以$rll中的值增加$r9中的值;以及
·如果lp字段为1,则指令将隐含地循环递减$r8中的值,直到$r8中的值为0。
输出处理器可以执行根据输出isa114指定的以下指令:
输出(output)
output是控制输出电路块的特殊指令。有关详细信息,参见下述outputi指令。在output指令中,使用rb中的值代替在outputi指令中编码的立即值。
输出立即(outputimmediate)
outputi是控制输入块的特殊指令。该指令隐含地使用$r8、$r9、$r10、$r12、$r13和$r15,并更新$r8、$r9和$r10。
·执行outputi指令时,可以从内部存储器中$r10中指定的地址处读取八个值;
·基于typ中指定的类型,读入的八个值可以被视为半精度值或字节。如果它们是字节,则将它们转换为等效的半精度值;
·可能转换后的值被写入外部存储器104的由存储在$rl5和$r9中的值连接而形成的地址处。因为外部地址可能大于32位,所以需要连接。
该指令将$r9中的值增加$rl2中的值,并将$rl0中的值增加$rl3中的值;以及
·如果lp字段为1,则指令将隐含地循环递减$r8中的值,直到$r8中的值为0。
处理器102可以使用一组寄存器来设置gsnn加速器电路106的任务,而gsnn加速器电路106可以使用该组寄存器将加速器电路在操作期间的状态传达给处理器102。图7示出了根据本发明的实施方式的系统700,其使用一组寄存器作为处理器与加速器电路之间的接口。如图7所示,类似于图1所示的系统,系统700可以包括处理器102和加速器电路106,加速器电路106可以进一步包括输入电路块、过滤器电路块、后处理电路块、和输出电路块。加速器电路106可以进一步包括一组寄存器,以用作处理器102和加速器电路106之间的接口。
寄存器接口可以包括控制寄存器($ctrl)702、下一个任务寄存器($next)704、axiqos寄存器($qos)706、错误寄存器($err)708、影子寄存器($s0-$sl5)710、以及全局寄存器($g0-$15)712。控制寄存器($ctrl)702可以包含中断挂起标志和中断允许标志以及各种复位控制标志。错误寄存器($err)708可以记录不同种类的错误。axiqos寄存器($qos)706可以包含用于外部存储器总线接口的控制。下一个任务寄存器($next)704可以包含全局寄存器的掩码,当下一个任务开始时,它们可能会被覆盖。影子寄存器($s0-$s15)710可以包含在$next寄存器704的控制下可以用来覆盖全局寄存器($g0-$15)712的值。
处理器102可以读取和写入全局寄存器($g0-$15)712以及与每个处理器相关联的数据和指令存储器。处理器(输入、过滤器、后处理、输出)可通过写入全局寄存器$gl5来触发中断并发出任务完成信号。如果将指示位31被设置的值写入$gl5,则表示任务结束。如果将指示位30被设置的值写入$gl5,则会向处理器产生中断,通常指示需要处理器干预的某种情况。
以下描述了不同寄存器的状态:
控制寄存器(sctrl)
控制寄存器具有以下字段:
·resetb[位0]:清零时,gsnn重置。启动时,resetb清零;
·stall[位2、3]:当两个位都置位时,四个处理器(输入、过滤器、后处理、和输出)暂停;没有指令被执行。
οen_stall[位2]:设置为启用暂停
οstall[位3]:检测到错误情况时将自动被置位;
·en_interrupt[位4-7]:当en_interrupt置位,并将其相应的interrupt位置位时,向控制处理器102发出中断
οen_copy_int[位4]:启用copyjnt[位8]中断,
οenjjnavailjnt[位5]:启用unavail_int[位9]中断,
οen_gl5_int[位6]:启用g15_int[位10]中断,
οen_err_int[位7]:启用err_int[位11]中断;
·interrupt[位8-11]:当interrupt字段中的一位被置位时,在假定相应的en_interrupt位被置位的情况下,它将向处理器102发出中断。
οcopyjnt[位8]:写$gl5,置位31位,置位$next寄存器的位15,
οunava1l_int[位9]:写$g15,置位31位,$next的位15被清零,
οg15_int[位10]:写$g15,置位30位,
οerr_int[位11]:遇到错误情况。
控制处理器102可以通过写入位置0x200c0/0x200c4/0x200c8来修改控制寄存器。这些会导致对控制寄存器的不同修改,
·0x200c0[copy]:正在写入的值复制到控制寄存器,
·0x200c4[set-on-l]:正在写入的值与控制寄存器进行或运算,
·0x200c8[clear-on-l]:正在写入的值的补码与控制寄存器进行与运算。
处理器可以使用地址0x200c0读取控制寄存器。
错误寄存器($err)
错误寄存器记录以下几种错误:
·in[位0、1]:格式错误的输入块外部读地址:
οin_align[位0]:地址未16b对齐,
οin_page[位1]:读取的字节跨越4kb边界;
·out[位2]:格式错误的输出块外部写地址
οout_align[位2]:地址未8b/16b对齐(字节写入/半字写入);
·bresp[位4-5]:外部(axi)总线向写操作返回了非零的bresp,并将该值复制到bresp字段;
·rresp[位6-7]:外部(axi)总线向写操作返回了非零的rresp,并将该值复制到rresp字段;
·collision[位8-14]:存在从不同的读/写端口对相同存储体的同时访问。collision字段对所有冲突的端口都有位。这些是:
οin_res_coll[位8]:输入单元写端口;
οfilt_data_coll[位9]:过滤器单元数据读端口;
οfilt_psum_coll[位10]:过滤器单元部分和读端口;
οfilt_res_coll[位11]:过滤器单元写端口;
οpost_data_coll[位12]:后单元数据读端口;
οpost_res_coll[位13]:后单元结果写端口;
οoutput_data_coll[位14]:输出单元读端口;
可以使用地址0x200f0从处理器102访问错误寄存器。
qos寄存器($qos)
axi外部存储器总线使用arqos[位0-3j/awqos[位4-7]字段。
可以使用地址0x200e0从处理器102访问qos寄存器。
下一个寄存器(snext)
下一个寄存器可以控制将影子寄存器复制到全局寄存器。如果将snext寄存器的位15设置为1,并且将位31设置为1写入sgl5,则如果下一个寄存器的位i为1,则将影子寄存器$si复制到全局寄存器$gi。由于仅在置位了位15时才进行复制,因此这意味着sgl5将总是被复制。复制后,snext的位15被清除。
处理器可以在地址0x200d0访问下一个寄存器snext。
影子寄存器($so-$s15)
存在16个32位影子寄存器$s0-$sl5。当发生复制事件时,可以在$next寄存器的控制下将影子寄存器复制到相应的全局寄存器中
影子寄存器i可以由处理器在地址0x20040+4*i处访问。
全局寄存器($g0-$g15)
存在16个32位全局寄存器$g0-$g15。当发生复制事件时,可以在$next寄存器的控制下将影子寄存器复制到相应的全局寄存器。
处理器可以将全局寄存器用作其常规指令的一部分。
写入$g15被特殊处理:
·如果$g15的位31写为1,并且snext的位15为1,则发生复制事件。
ο在snext寄存器中的位的控制下,影子寄存器被复制到全局寄存器;
οsnext寄存器的位15被清除;
ο置位sctrl寄存器中的copy_int位。
·如果sg15的位31写为1,并且snext的位15为0,则发生复制不可用事件;置位sctrl寄存器中的unavail_int位。
·如果将sg15的位30写为1,则置位sctrl寄存器中的g15_int。
处理器可以在地址0x200i0+4*i访问全局寄存器i。
引擎指令/数据存储器
处理器102可以访问引擎的指令和数据存储器中的字。每个处理器有16kb的指令和16kb的数据存储器。用于访问每个存储器的地址范围是:
0x00000...0x03fff:输入处理器指令存储器
0x04000...0x07fff:输入处理器数据存储器
0x08000...oxobfff:过滤器处理器指令存储器
oxocooo...oxoffff:过滤器处理器数据存储器
0x10000...0x13fff:后处理器指令存储器
0x14000...0x17fff:后处理器数据存储器
0x18000...oxlnfff:输出处理器指令存储器
oxlcooo...oxlffff:输出处理器数据存储器
处理器102可以使用与处理器相关联的指令和数据存储器来加载分配给加速器电路106的任务。为了使用gsnn加速器电路106执行神经网络计算,处理器102可以初始化gsnn加速器电路106,将神经网络应用划分成任务,设置gsnn加速器电路106通过链接将由gsnn加速器电路106上的处理器流水线执行的任务以执行任务,并请求gsnn加速器电路106开始执行任务。任务可能包括3x3卷积神经网络(cnn)过滤器、3x3cnn过滤器的变体、大于3x3的cnn过滤器等。
图8描绘了根据本公开的实施方式的通过处理器来操作gsnn加速器电路的方法800的流程图。方法800可以由处理装置执行,该处理装置可以包括硬件(例如,电路、专用逻辑)、计算机可读指令(例如,在通用计算机系统或专用机器上运行)或两者的组合。方法800及其单独的函数、例程、子例程或操作中的每一个可以由执行该方法的处理装置的一个或多个处理器来执行。在某些实施方式中,方法800可以由单个处理线程执行。可替代地,方法800可以由两个或更多个处理线程执行,每个线程执行该方法的一个或多个单独的函数、例程、子例程或操作。
为了简化说明,将本公开的方法描绘和描述为一系列动作。然而,根据本公开的动作可以以各种顺序和/或同时发生,并且具有本文未呈现和描述的其他动作。此外,可能不需要所有示出的动作来实现根据所公开的主题的方法。另外,本领域技术人员将理解并认识到,所述方法可以可替代地经由状态图或事件被表示为一系列相互关联的状态。另外,应当认识到,在本说明书中公开的方法能够被存储在制造产品上,以便于将这样的方法传输和转移到计算装置。本文所使用的术语“制造产品”旨在涵盖可从任何计算机可读装置或存储介质访问的计算机程序。在一个实施方式中,方法800可以由如图1所示的处理器102执行。
在802,处理器102可以初始化通信地耦合到处理器的gsnn加速器电路,以执行神经网络应用。如图1-7所述,gsnn加速器电路可以包括输入电路块、过滤器电路块、后处理电路块和输出电路块。每个电路块可以包括相应的处理器,该处理器可以是32位risc处理器。每个处理器可以执行根据该处理器特定的指令集体系结构(isa)指定的相应指令。例如,输入电路块可以包括输入处理器,以执行根据输入isa指定的指令;过滤器电路块可以包括过滤器处理器,以执行根据过滤器isa指定的指令;后处理电路块可以包括后处理处理器,以执行根据过滤器isa指定的指令;输出电路块可以包括输出处理器,以执行根据过滤器isa指定的指令。每个处理器可以与指令存储器和数据存储器相关联。加速器电路可以进一步包括通用寄存器和电路块共享的内部存储器。加速器电路可以包括一组寄存器,其可以用作与处理器102通信的外部接口。
加速器电路在启动时可以处于复位状态。处理器102可以将适当的值写入控制寄存器和全局寄存器以开始加速器电路的操作。例如,处理器102可以通过将指示符值(例如,设置为“1”)写入控制寄存器(sctrl)的resetb位来使加速器电路退出复位。将标志值写入控制寄存器可以使能在加速器电路处生成的所有中断,并在发生错误时暂停加速器电路。
在804处,处理器102可确定由输入电路块、过滤器电路块、后处理电路块或输出电路块中的一个或多个执行的神经网络应用的任务。任务可以包括代码段,该代码段包含由不同电路块执行的指令。例如,输入代码段可以包括由输入处理器执行的根据输入isa指定的指令;过滤器代码段可以包括由过滤器处理器执行的根据过滤器isa指定的指令;后处理代码段可以包括由后处理处理器执行的根据后处理isa指定的指令;输出处理代码段可以包括由输出处理器执行的根据输出isa指定的指令。处理器可以将这些代码段存储到相应的指令存储器,并将与这些代码段的执行相关联的数据存储到与处理器相关的数据存储器。
在806,处理器102可以将每个任务分配给输入电路块、过滤器电路块、后处理电路块和输出电路块中的相应的一个。分配给特定电路块的任务可以包括根据电路块的处理器的isa指定的指令。处理器102可以将这些指令存储在处理器的指令存储器中。在一个实施方式中,处理器102可以设置加速器电路通过链接由加速器电路上的处理器的流水线执行的任务来执行任务。gsnn加速器电路被设计为使用下一个寄存器$next、影子寄存器和全局寄存器$g15支持任务的链接。为了在当前任务正在加速器电路上运行的同时将待执行任务排队,处理器可以将与执行新任务相关联的期望值写入相应的影子寄存器,并将这些影子寄存器的掩码写入下一个寄存器。在一个实施方式中,全局寄存器的期望值包括$g15的新值,并建议将该值的31位和30位清零,否则它们将启动新请求或中断。
可以对在gsnn上运行的任务进行编程,以使得当任务完成时,该任务将通过写入$g15并置位位31向处理器发出信号通知完成。这可能会触发影子寄存器到全局寄存器的复制,从而开始新任务。$ctrl寄存器的copy_int位将被置位;如果还将en_ctl_int位置位,则将向处理器发送一个中断,通知处理器调度下一个任务。
在一个实施方式中,如果用于任务的参数的数据大小不适合全局寄存器(例如,数据大小超过全局寄存器的容量),则与该任务的处理器相关联的数据存储器的区域可以被预订并用于存储参数。处理器可以通过将一些参数写入数据存储器,然后将地址传递给影子寄存器中的那些参数块来链接命令。在该实施方式中,影子寄存器用于存储数据存储器的地址,该地址存储下一个任务的参数。
在一个实施方式中,处理器可以形成用于协调任务执行的执行流水线。例如,输入处理器可以填充用于过滤器处理器的输入寄存器,然后过滤器处理器处理输入寄存器中的数据。因此,公共流水线可包括将数据提供给过滤器电路块的输入电路块、将数据提供给后处理电路块的过滤器电路块、以及将数据提供给输出电路块的后处理电路块。较早的阶段被称为生产者,而随后的阶段被称为消费者。处理器102可以使用全局寄存器来协调流水线的每个阶段。例如,全局寄存器$gl可以用于协调两个阶段之间的操作。在任务开始时,$gl中的值是已知值,例如,值0。输入寄存器的消费者可以等待全局寄存器为非零。生产者填充消费者的输入寄存器,然后将该值设置为1,指示输入寄存器已准备好被读取。然后,生产者等待消费者发出信号,表明消费者已经读取了存储在输入寄存器中的数据。该指示可以通过将寄存器$gl的值清为0来实现。以这种方式,流水线的不同阶段可以协同工作而无需调用原子指令。这在以下代码序列中示出:
如果有两个输入寄存器允许生产者在消费者处理前一个阶段时填充下一个阶段(所谓的乒乓缓冲区),则协调代码可以使用两个全局寄存器。可以是每个缓冲区一个,或者可以使用读指针和写指针的更通用的方法。对读指针使用一个全局寄存器以及对写指针使用一个全局寄存器的好处是,它可以扩展到深度大于2的生产者消费者队列。
在808,处理器102可以指示加速器电路开始执行任务。处理器102可以通过将控制寄存器中的位标志设置为1来启动执行。
在810,处理器102可以从执行任务的加速器电路接收结果。响应于接收结果,处理器可以基于结果来执行神经网络应用。
神经网络应用的常见任务是对数据的阵列进行操作的3x3cnn过滤器。下面提供使用由加速器电路的处理器执行的指令来执行cnn过滤的示例。假设3x3过滤器在大小为66x66的输入阵列上操作,产生大小为64x64的输出,并同时处理8个输入通道。
首先,加载过滤器权重:
copyi$rl0,l.filter
filteronce,wt9,inactive
然后,将前两行的4列移入
copyi$rl0,l.image
copyi$rl3,132#每个输入行相距66个元素=132b
filteronce,in6,inactive
filteronce,in6,inactive
在完成了64次迭代的主循环完成之后,产生64行4列过滤输出,该输出已在8个输入通道中求和。
copyi$r8,64
copyi$r9,l.result
copyi$rl2,128#每行相距64个元素=128b
filterloop,in6,direct,global
该代码然后可以产生其他15x4列的结果。需要修改读写指针,以指向下一个起点
addi$rlo,$rl0,-124
addi$r9,$r9,-120
总而言之,代码的执行可以处理16组4列。这可以通过使用跳转指令对16个计数循环进行编程来实现。放在一起:
该代码可以被构造为处理3x3过滤器的变体。如果需要8个以上的输入通道,则可以将这些通道分成8组。第一组计算如上。在随后的组中,将使用部分和模式而不是直接模式,并将前一组的部分和添加到过滤器中。如果通道总数不是8的倍数,则可以将$r15设置为屏蔽某些数目的输入通道。
如果将偏置添加到过滤器输出,则第一过滤器将不使用直接过滤器。取而代之的是,使用部分和模式,并且将偏置用作初始部分和。
可以将5x5或更大的过滤器分解为多个3x3过滤器。首先,通过零填充将较大的过滤器转换为最接近的3的倍数。因此,可以将5x5过滤器转换为6x6过滤器。然后,每个3x3过滤器将分别在输入通道的适当部分上运行。在一个实施方式中,可以将wt3和掩码应用于较大过滤器的不同部分,而不是将过滤器显式地填充为零。
本公开的实施方式可以在神经网络应用的全连接层中提供数据重用。在全连接层中重用的数据可以是输入数据。在一个实施方式中,处理器102可以将输入的负载分散在过滤器电路块中的所有电路条上。一次将输入的9个元素加载到权重寄存器中。然后,使用指令filterin9,x4,global将4组过滤器加载到过滤器电路块的输入寄存器中。在每4次加载后,过滤器电路块就可以执行4次72抽头卷积,得到4个不同输出通道的结果。
图9详细示出了根据本公开的实施方式的gsnn加速器电路900。如图9所示,gsnn加速器电路900可以包括输入电路块902、过滤器电路块904、后处理电路块906和输出电路块908、包括通用寄存器910的通用寄存器文件、内部存储器912和外部接口914。输入电路块902、过滤器电路块904、后处理电路块906、和输出电路块908可各自包括相应的输入处理器916a、过滤器处理器916b、后处理处理器916c、输出处理器916d,各自相应的指令存储器918a、918b、918c、918d以及各自相应的数据存储器920a、920b、920c、920d。可替代地,两个或三个电路块可以共享一个公共处理处理器。
输入电路块902、过滤器电路块904、后处理电路块906和输出电路块908可各自进一步包括各自相应的本地寄存器922a、922b、922c、922d和各自相应的程序计数器(pc)924a、924b、924c、924d。指令存储器918a、918b、918c、918d可以存储代码段,其包含从分配给gsnn900的外部处理装置(例如,计算机系统、cpu或gpu)接收的任务指令,以执行神经网络应用。数据存储器920a、920b、920c、920d可以存储与由gsnn加速器电路900执行这些任务相关联的数据。本地寄存器922a、922b、922c、922d可以用于存储与执行这些指令相关联的输入值和结果。程序计数器924a、924b、924c、924d可用于加载将由相应处理器执行的下一条指令的地址。可以从内部存储器912获取输入值,并且还可以将结果写入内部存储器912。
为了进一步提高神经网络计算的效率和伸缩性,过滤器电路块904可以进一步包括一个或多个电路条932a-932h。电路条932a-932h中的每一个可以包括过滤器电路的相同电路元件以及分配给相应的电路条的内部存储器的片段。然后,可以在不需要改变过滤器电路块904的操作原理的情况下,将电路条添加到过滤器电路块904或从过滤器电路块904减去电路条。在一个实施方式中,过滤器电路块904可以包括八个电路条932a-932h。八个电路条932a-932h中的每个可以包括四个过滤器电路和一个内部存储器片段。电路条932a-932h可以将地址存储到分配给相应电路条的存储器片段930a-930h。每个过滤器电路可以包括n×ncnn过滤器的电路实施方式,其中n可以是3的整数值(或任何合适的整数值)
外部处理装置可以通过将由它们各自的处理器916a-916d执行的包括指令的代码段放置在指令存储器918a-918d中,将任务分配给输入电路块902、过滤器电路块904、后处理电路块906和输出电路块908中的任何一个。可以根据它们各自的isa(例如,输入isa、过滤器isa、后处理isa、输出isa)指定存储在不同指令存储器中的指令。外部处理装置可以使用通用寄存器910和外部接口914来协调分配给加速器电路900的不同任务的执行。外部接口可以包括影子寄存器926、控制寄存器($ctrl)、错误寄存器($err)、服务质量寄存器($qos)和下一个寄存器($next)。
在一个实施方式中,输入电路块902、过滤器电路块904、后处理电路块906、和输出电路块908可以形成执行流水线,其意义是可以将来自较早阶段的结果传递给下一个阶段。例如,输入电路块902可以将结果写到过滤器电路块904的本地寄存器922b中,作为过滤器电路块904的输入值;过滤器电路块904可以将结果写到后处理电路块906的寄存器922c中,作为到后处理电路块906的输入值;后处理电路块906可以将结果写入输出电路块908的寄存器922d,作为输出电路块908的输入值。此外,外部处理装置可以使用下一个寄存器($next)形成任务的执行序列并使用通用寄存器910来控制特定任务的开始。
以下示例涉及另外的实施例。该实施方式的示例1是加速器电路,其包括内部存储器,用于存储从与处理器相关联的存储器接收的数据;输入电路块,包括输入处理器以执行第一任务,所述第一任务包括根据第一指令体系结构(isa)指定的第一指令;过滤器电路块,包括过滤器处理器以执行第二任务,所述第二任务包括根据第二isa指定的第二指令;后处理电路块,包括后处理处理器以执行第三任务,所述第三任务包括根据第三isa指定的第三指令;以及输出电路块,包括输出处理器以执行第四任务,所述第四任务包括根据第四isa指定的第四指令,其中所述输入处理器、所述过滤器处理器、后过滤器处理器、或所述输出处理器中的至少两个同时执行它们相应的任务。
在示例2中,示例1的主题还可以提供:输入电路块还包括第一指令存储器、第一数据存储器和第一程序计数器(pc),其中第一指令存储器用于存储第一指令,其中第一pc用于存储将由第一处理器执行的当前第一指令的地址,以及其中输入处理器用于使用存储在第一数据存储器中的第一数据来执行第一指令以执行第一任务,过滤器电路块进一步包括第二指令存储器、第二数据存储器和第二pc,其中第二指令存储器用于存储第二指令,其中第二pc用于存储将由第二处理器执行的当前第二指令的地址,以及其中过滤器处理器用于使用存储在第二数据存储器中的第二数据来执行第二指令以执行第二任务,后处理电路块还包括第三指令存储器、第三数据存储器、第三pc,其中第三指令存储器用于存储第三指令,其中第三pc用于存储将由第三处理器执行的当前第三指令的地址,以及其中后处理处理器用于使用存储在第三数据存储器中的第三数据来执行第三指令以执行第三任务,以及输出电路块还包括第四指令存储器、第四数据存储器、第四pc,其中第四指令存储器用于存储第四指令,其中第四pc用于存储将由第四处理器执行的当前第四指令的地址,以及其中输出处理器用于使用存储在第四数据存储器中的第四数据来执行第四指令以执行第四任务,以及其中输入处理器、过滤器处理器、后处理处理器或输出处理器中的每一个是被设计为具有各自唯一指令集的精简指令集计算机(risc)处理器。
在示例3中,示例2的主题还可以包括:其中输入处理器、过滤器处理器、后处理处理器或输出处理器中的每一个是被设计为具有各自唯一指令集的精简指令集计算机(risc)处理器,还包括用于响应于复制事件而将被复制的内容存储到多个通用寄存器的多个影子寄存器,以及接口电路,该接口电路包括:控制寄存器,用于存储至所述处理器的多个中断;错误寄存器,用于存储指示不同种类的错误的发生的多个错误标志;下一个寄存器,用于存储用于选择将被复制到所述多个通用寄存器的所述多个影子寄存器的内容的掩码,以及服务质量寄存器,用于存储对与所述处理器相关联的存储器的控制。
在示例4中,示例2的主题可以进一步提供:所述过滤器电路块还包括多个电路条,所述多个电路条中的每一个包括多个过滤器电路,以及分配给多个过滤器电路的内部存储器的片段。
在示例5中,示例2的主题可以进一步提供八个相同的电路条,其中,八个相同的电路条中的电路条包括四个三乘三卷积神经网络(cnn)过滤器电路,以及分配给四个三乘三cnn过滤器电路的内部存储器的片段。
在示例6中,示例5的主题可以进一步提供:过滤器电路块还包括八个相同的电路条,其中,八个相同的电路条中的电路条包括四个三乘三的卷积神经网络(cnn)过滤器电路、以及分配给四个三乘三cnn过滤器电路的内部存储器的片段。
在示例7中,示例5的主题可以进一步提供:四个三乘三cnn过滤器电路中之一包括:第一多个寄存器,用于存储权重参数;第二多个寄存器,用于存储输入值;归约树,其包括多个乘法电路,用于计算所述权重参数中的相应的一个与所述输入值中的相应的一个之间的乘积;以及求和电路,用于将来自所述多个乘法电路的结果与来自所述三乘三cnn过滤器电路中的另一个的进位结果相加。
在示例8中,示例7的主题可以进一步提供:八个相同的电路条各自输出由其中的四个三乘三cnn过滤器电路生成的四个结果,以及其中,过滤器电路块包括四个加法电路,四个加法电路的每一个对来自八个过滤器电路的四个结果中的相应一个求和。
在示例9中,示例1的主题可以进一步提供:输入处理器、过滤器处理器、后处理处理器和输出处理器形成异构计算系统,以及其中,第一任务还包括根据公共isa指定的第五指令,第二任务还包括根据公共isa指定的第六指令,第三任务还包括根据公共isa指定的第七指令,以及第四任务还包括根据公共isa指定的第七指令。
在示例10中,示例1的主题可以进一步提供:内部存储器包括多个存储器片段,并且能够通过用于标识存储器片段的片段标识符和相对于存储器片段的起始位置的偏移量来进行寻址。
在示例11中,示例1的主题可以进一步提供:内部存储器包括多个顺序编号的位阵列,其中,每对偶数编号阵列和随后的奇数编号阵列形成相应的存储体,以及其中,内部存储器能够通过用于标识存储体的存储体标识符和所述存储体中的行的行标识符来进行寻址。
在示例12中,示例1的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块形成执行流水线,以及其中所述输入电路块的所述输入处理器用于从与处理器相关联的存储器中读取,并将由所述输入电路块生成的第一结果写入内部存储器,过滤器处理器用于从内部存储器中读取第一结果,并将由过滤器电路块生成的第二结果写入内部存储器,后处理处理器用于从内部存储器读取第二结果,并将由后处理电路块生成的第三结果写入内部存储器,以及输出处理器用于从内部存储器读取第三结果,并将由输出电路块生成的第四结果写入与处理器相关联的存储器。
在示例13中,示例1的主题可以进一步提供:所述后处理电路块执行压缩函数、激活函数或top-n函数中的至少一个。
在示例14中,示例13的主题可以进一步提供:所述压缩函数具有4∶1、3∶1、2∶1或1∶1的压缩比中之一,以及其中所述压缩函数的结果是包含n个元素的输入数据的第一个元素或包含n个元素的输入数据的最大值中的一个,其中n是大于1的整数。
在示例15中,示例13的主题可以进一步提供:激活函数是阶跃函数、s型函数或双曲正切函数之一。
在示例16中,示例13的主题可以进一步提供:所述top-n函数用于确定值阵列中的n个最大值和相应的位置。
在示例17中,示例2的主题可以进一步提供:所述输入处理器用于从与所述处理器相关联的存储器中读取数据值,其中,所述数据值是半精度浮点、有符号字节或无符号字节格式之一;将数据值转换为半精度浮点格式;以及将数据值写入内部存储器。
在示例18中,示例2的主题可以进一步提供:所述第一指令包括输入指令,所述输入指令包括类型值、模式值和大小值,以及其中,为了执行所述输入指令,所述输入处理器连接输入处理器的第一本地寄存器和第二本地寄存器以形成第一存储器地址;基于所述第一存储器地址,读取与处理器相关联的存储器,以由类型值确定的格式获取数据值,其中,大小值确定与从存储器中获取的数据值相关联的字节数;以及以由模式值确定的模式将数据值写入内部存储器。
在示例19中,示例18的主题可以进一步提供:响应于确定所述模式值指示第一模式,输入处理器基于存储在第三本地寄存器中的第二存储器地址,写入所述内部存储器;以及响应于确定所述模式值指示第二模式,输入处理器以存储在第三本地寄存器中的偏移量写入多个电路条中的每一个的片段中。
在示例20中,示例18的主题可以进一步提供:类型值、模式值和大小值是立即值或存储在输入指令的目标寄存器中之一。
在示例21中,示例4的主题可以进一步提供:所述第二指令包括过滤器指令,所述过滤器指令包括和值和模式值,以及其中,为了执行过滤器指令,所述过滤器处理器:基于存储在过滤器处理器的第一本地寄存器中的第一存储器地址从内部存储器中读取数据值;对于每一个电路条:将数据值加载到与该电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果;基于和值,计算来自每个电路条的相应过滤器结果的和值;基于所述模式值,确定所述过滤器电路块是处于片段模式还是处于全局模式;响应于确定过滤器电路块处于片段模式,以存储在第二本地寄存器中的偏移量将和值写入每个片段;以及响应于确定过滤器电路块处于全局模式,在存储在所述第二本地寄存器中的存储器地址处将所述和值写入内部存储器。
在示例22中,示例21的主题可以进一步提供:所述模式值和所述和值是立即值或被存储在过滤器指令的目标寄存器中之一。
在示例23中,示例2的主题可以进一步提供:所述第三指令包括后处理指令,所述后处理指令包括控制寄存器的标识符、列值、行值、以及种类值,其中,为了执行所述后处理指令,所述后处理处理器:响应于确定种类值指示压缩模式,基于存储在第一本地寄存器中的第一存储器地址,从内部存储器读取一定数量的数据值,其中,列值指定组的数量;基于所述列值,将数据值分为多个组;基于种类值,将多个组中的每一个压缩为该组的最大值或该组的第一个元素中之一;确定压缩值和存储在阶段寄存器中的值中的最大值;将最大值存储在状态寄存器中;将激活函数应用于最大值,其中,激活函数是恒等函数、阶跃函数、s型函数或双曲正切函数中之一;以及基于存储在第二本地寄存器中的第二存储器地址,将激活函数的结果写入内部存储器;以及响应于确定种类值指示top-n模式,基于存储在第三本地寄存器中的第三存储器地址,读取数据值阵列;确定阵列中的top-n个值及其相应位置,其中n为大于1的整数;响应于确定控制值指示存储器写入,在存储在第四本地寄存器中的第四存储器地址处将top-n个值及其相应位置写入内部存储器中;以及响应于确定控制值指示寄存器写入,将top-n个值及其相应位置写入与所述后处理处理器相关联的状态寄存器中。
在示例24中,示例23的主题可以进一步提供:所述控制寄存器的标识符、所述列值、所述行值和所述种类值是立即值或被存储在后处理指令的目标寄存器中之一。
在示例25中,示例2的主题可以进一步提供:所述第四指令包括输出指令,所述输出指令包括类型值、模式值和大小值,以及其中,为了执行所述输出指令,所述输出处理器:基于存储在输出处理器的第一本地寄存器中的第一存储器地址从内部存储器读取多个数据值,其中大小值指定多个数据值的数量;连接输出处理器的第二本地寄存器和第三本地寄存器以形成第二存储器地址;以及基于第二存储器地址,以由所述类型值确定的格式将多个数据值写入与处理器关联的存储器。
在示例26中,示例25的主题可以进一步提供:类型值、模式值和大小值是立即值或被存储在输入指令的目标寄存器中之一。
在示例27中,示例1的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块中的每一个包括不同的risc硬件处理器。
在示例28中,示例1的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块中的至少两个但少于四个共享公共的risc硬件处理器。
示例29是一种系统,包括:存储器;处理器,用于执行神经网络应用,所述神经网络应用包括用于输入数据的第一任务、用于过滤数据的第二任务、用于后处理数据的第三任务、和用于输出数据的第四任务;以及加速器电路,其通信地耦合到所述存储器和所述处理器,所述加速器电路包括:内部存储器,用于存储从所述存储器接收的数据;输入电路块,其包括输入处理器以执行第一任务,所述第一任务包括根据第一指令体系结构(isa)指定的第一指令;过滤器电路块,其包括过滤器处理器以执行第二任务,所述第二任务包括根据第二isa指定的第二指令;后处理电路块,其包括后处理处理器以执行第三任务,所述第三任务包括根据第三isa指定的第三指令;以及输出电路块,其包括输出处理器以执行第四任务,所述第四任务包括根据第四isa指定的第四指令,其中输入处理器、过滤器处理器、后过滤器处理器、或输出处理器中的至少两个同时执行它们相应的任务。
在示例30中,示例29的主题可以进一步提供:所述加速器电路还包括:所述输入电路块还包括第一指令存储器、第一数据存储器和第一程序计数器(pc),其中,所述第一指令存储器用于存储所述第一指令,其中第一pc用于存储将由第一处理器执行的当前第一指令的地址,以及其中输入处理器用于使用存储在第一数据存储器中的第一数据执行第一指令以执行第一任务;过滤器电路块还包括第二指令存储器、第二数据存储器、和第二pc,其中第二指令存储器用于存储第二指令,其中第二pc用于存储将由第二处理器执行的当前第二指令的地址,以及其中过滤器处理器用于使用存储在第二数据存储器中的第二数据执行第二指令以执行第二任务;后处理电路块还包括第三指令存储器、第三数据存储器、和第三pc,其中第三指令存储器用于存储第三指令,其中第三pc用于存储将由第三处理器执行的当前第三指令的地址,以及其中后处理处理器用于使用存储在第三数据存储器中的第三数据执行第三指令以执行第三任务;以及输出电路块还包括第四指令存储器、第四数据存储器、和第四pc,其中第四指令存储器用于存储第四指令,其中第四pc用于存储将由第四处理器执行的当前第四指令的地址,以及其中所述输出处理器用于使用存储在第四数据存储器中的第四数据执行第四指令以执行第四任务,其中输入处理器、过滤器处理器、后处理处理器或输出处理器中的每一个是被设计为具有各自唯一指令集的精简指令集计算机(risc)处理器。
在示例31中,示例30的主题可以进一步提供:所述加速器电路还包括:多个通用寄存器,其用于存储第一标志位,所述第一标志位指示所述第一任务、所述第二任务、所述第三任务、或第四项任务中至少一个的执行的开始;多个影子寄存器,其用于存储响应于复制事件将被复制到多个通用寄存器中的内容;以及接口电路,包括:控制寄存器,其用于存储至处理器的多个中断,错误寄存器,其用于存储指示不同种类的错误的发生的多个错误标志,下一个寄存器,其用于存储用于选择将被复制到多个通用寄存器的多个影子寄存器的内容的掩码,以及服务质量寄存器,其用于存储对与处理器相关联的存储器的控制。
在示例32中,示例30的主题可以进一步提供:加速器电路还包括多个电路条,多个电路条中的每一个包括多个过滤器电路、以及被分配给多个过滤器电路的内部存储器的片段。
在示例33中,示例30的主题可以进一步提供:所述过滤器电路块还包括八个相同的电路条,其中,所述八个相同的电路条中的电路条包括四个三乘三卷积神经网络(cnn)过滤器电路、以及分配给四个三乘三cnn过滤器电路的内部存储器的片段。
在示例34中,示例33的主题可以进一步提供:八个相同的电路条中的所述电路条包括四个三乘三cnn过滤器电路,所述四个三乘三cnn过滤器电路共享第一多个寄存器,以存储所述四个三乘三cnn过滤器电路的权重参数。
在示例35中,示例29的主题可以进一步提供:所述第一指令包括输入指令,所述输入指令包括类型值、模式值和大小值,以及其中,为了执行所述输入指令,所述输入处理器:连接输入处理器的第一本地寄存器和第二本地寄存器以形成第一存储器地址;基于第一存储器地址,读取与处理器相关联的存储器来以由类型值确定的格式获取数据值,其中,大小值确定从存储器中获取的数据值的字节数;以及以由模式值确定的模式写入内部存储器。
在示例36中,示例29的主题可以进一步提供:所述第二指令包括过滤器指令,所述过滤器指令包括和值和模式值,以及其中,为了执行所述过滤器指令,所述过滤器处理器:基于存储在过滤器处理器的第一本地寄存器中的第一存储器地址,从内部存储器读取数据值;对于每一个电路条:将数据值加载到与该电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果;基于所述和值,计算来自每个电路条的相应过滤器结果的和值;基于所述模式值,确定所述过滤器电路块是处于片段模式还是处于全局模式;响应于确定过滤器电路块处于片段模式,以存储在第二本地寄存器中的偏移量将所述和值写入每个片段;以及响应于确定过滤器电路块处于全局模式,在存储在第二本地寄存器中的存储器地址处将所述和值写入内部存储器。
在示例37中,示例29的主题可以进一步提供:所述第三指令包括后处理指令,所述后处理指令包括所述控制寄存器的标识符、列值、行值和种类值,其中,为了执行所述后处理指令,所述后处理处理器:响应于确定所述种类值指示压缩模式,基于存储在第一本地寄存器中的第一存储器地址从内部存储器读取一定数量的数据值,其中,列值指定所述组的数量;基于所述列值,将数据值分为多个组;基于所述种类值,将多个组中的每一个压缩为该组的最大值或该组的第一个元素中之一;确定压缩值和存储在阶段寄存器中的值中的最大值;将最大值存储在状态寄存器中;将激活函数应用于所述最大值,其中,激活函数是恒等函数、阶跃函数、s型函数或双曲正切函数中之一;以及基于存储在第二本地寄存器中的第二存储器地址,将激活函数的结果写入内部存储器;以及响应于确定种类值指示top-n模式,基于存储在第三本地寄存器中的第三存储器地址,读取数据值阵列;确定所述阵列中的top-n个值及其相应位置,其中n为大于1的整数;响应于确定控制值指示存储器写入,在存储在第四本地寄存器中的第四存储器地址处将top-n个值及其相应位置写入内部存储器中;以及响应于确定控制值指示寄存器写入,将top-n个值及其相应位置写入与所述后处理处理器相关联的状态寄存器中。
在示例38中,示例29的主题可以进一步提供:所述第四指令包括输出指令,所述输出指令包括类型值、模式值和大小值,以及其中,为了执行所述输出指令,所述输出处理器:基于存储在输出处理器的第一本地寄存器中的第一存储器地址从内部存储器读取多个数据值,其中大小值指定多个数据值的数量;连接输出处理器的第二本地寄存器和第三本地寄存器以形成第二存储器地址;以及基于第二存储器地址,以由所述类型值确定的格式将多个数据值写入与处理器相关联的存储器。
示例39是一种系统,该系统包括存储器、加速器电路和处理器,该加速器电路包括输入电路块、过滤器电路块、后处理电路块和输出电路块,处理器通信地耦合至存储器和加速器电路,以初始化加速器电路,确定要由输入电路块、过滤器电路块、后处理电路块或输出电路块中的至少一个执行的神经网络应用的任务,确定将由输入电路块、过滤器电路块、后处理电路块或输出电路块中的至少一个执行的神经网络应用的任务,指示加速器电路执行任务,并基于从完成任务执行的加速器电路接收到的结果,来执行神经网络应用。
在示例40中,示例39的主题可以进一步提供:加速器电路还包括用于存储从存储器接收的数据的内部存储器、用于存储指示至少一个任务开始执行的第一标志位的多个通用寄存器、用于存储响应于复制事件而将被复制到多个通用寄存器中的内容的多个影子寄存器、以及接口电路,该接口电路包括用于存储至处理器的多个中断的控制寄存器、用于存储指示不同种类的错误的发生的多个错误标志的错误寄存器、用于存储用于选择将被复制到多个通用寄存器的多个影子寄存器的内容的掩码的下一个寄存器、以及用于存储对与处理器相关联的存储器的控制的服务质量寄存器。
在示例41中,示例40的主题可以进一步提供:输入电路块还包括输入处理器、第一指令存储器、第一数据存储器和第一程序计数器(pc),其中,第一指令存储器用于存储根据输入处理器的第一指令集体系结构(isa)指定的第一任务的第一指令,其中第一pc用于存储要由第一处理器执行的当前第一指令的地址,以及其中输入处理器用于使用存储在第一数据存储器中的第一数据来执行第一指令以执行第一任务,过滤器电路块包括过滤器处理器、第二指令存储器、第二数据存储器和第二pc,其中,第二指令存储器用于存储根据过滤器处理器的第二isa指定的第二任务的第二指令,其中第二pc用于存储要由第二处理器执行的当前第二指令的地址,以及其中过滤器处理器用于使用存储在第二数据存储器中的第二数据来执行第二指令以执行第二任务,后处理电路块包括后处理处理器、第三指令存储器、第三数据存储器、第三pc,其中,第三指令存储器用于存储根据后处理处理器的第三isa指定的第三任务的第三指令,其中第三pc用于存储要由第三处理器执行的当前第三指令的地址,以及其中后处理处理器用于使用存储在第三数据存储器中的第三数据来执行第三指令以执行第三任务,并且输出电路块包括输出处理器、第四指令存储器、第四数据存储器,第四pc,其中,第四指令存储器用于存储根据输出处理器的第四isa指定的第四任务的第四指令,其中第四pc用于存储要由第四处理器执行的当前第四指令的地址,以及其中输出处理器用于使用存储在第四数据存储器中的第四数据来执行第四指令以执行第四任务。
在示例42中,示例41的主题可以进一步提供多个电路条,多个电路条中的每一个电路条包括多个过滤器电路,和分配给多个过滤器电路的内部存储器的片段。
在示例43中,示例41的主题可以进一步提供:过滤器电路块还包括八个相同的电路条,其中,八个相同的电路条中的电路条包括四个三乘三卷积神经网络(cnn)过滤器电路,和分配给四个三乘三cnn过滤器电路的内部存储器的片段。
在示例44中,示例41的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块中的至少两个同时操作。
在示例45中,示例41的主题可以进一步提供:第一指令包括输入指令,该输入指令包括类型值、模式值和大小值,以及其中,为了执行输入指令,输入处理器连接输入处理器的第一本地寄存器和第二本地寄存器以形成第一存储器地址,基于第一存储器地址,读取与处理器相关联的存储器来以由类型值确定的格式获取数据值,其中,大小值确定与从存储器中获取的数据值相关联的字节数,并以由模式值确定的模式将数据值写入本地存储器。
在示例46中,示例45的主题可以进一步提供:响应于确定模式值指示第一模式,输入处理器基于存储在第三本地寄存器中的第二存储器地址,写入本地存储器,并且响应于确定模式值指示第二模式,输入处理器以存储在第三本地寄存器中的偏移量写入多个电路条中的每一个的片段中。
在示例47中,示例41的主题还可以提供:所述第二指令包括过滤器指令,所述过滤器指令包括和值和模式值,以及其中,为了执行过滤器指令,所述过滤器处理器:基于存储在过滤器处理器的第一本地寄存器中的第一存储器地址从内部存储器中读取数据值;对于每一个电路条:将数据值加载到与该电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果;基于和值,计算来自每个电路条的相应过滤器结果的和值;基于所述模式值,确定所述过滤器电路块是处于片段模式还是处于全局模式;响应于确定过滤器电路块处于片段模式,以存储在第二本地寄存器中的偏移量将和值写入每个片段;以及响应于确定过滤器电路块处于全局模式,在存储在所述第二本地寄存器中的存储器地址处将所述和值写入内部存储器。
在示例48中,示例41的主题可以进一步提供:所述第三指令包括后处理指令,所述后处理指令包括控制寄存器的标识符、列值、行值、以及种类值,其中,为了执行所述后处理指令,所述后处理处理器:响应于确定种类值指示压缩模式,基于存储在第一本地寄存器中的第一存储器地址,从内部存储器读取一定数量的数据值,其中,列值指定组的数量;基于所述列值,将数据值分为多个组;基于种类值,将多个组中的每一组压缩为该组的最大值或该组的第一个元素中之一;确定压缩值和存储在阶段寄存器中的值中的最大值;将最大值存储在状态寄存器中;将激活函数应用于最大值,其中,激活函数是恒等函数、阶跃函数、s型函数或双曲正切函数中之一;以及基于存储在第二本地寄存器中的第二存储器地址,将激活函数的结果写入内部存储器;以及响应于确定种类值指示top-n模式,基于存储在第三本地寄存器中的第三存储器地址,读取数据值阵列;确定中的top-n个值及其相应位置,其中n为大于1的整数;响应于确定控制值指示存储器写入,在存储在第四本地寄存器中的第四存储器地址处将top-n个值及其相应位置写入内部存储器中;以及响应于确定控制值指示寄存器写入,将top-n个值及其相应位置写入与所述后处理处理器相关联的状态寄存器中。
在示例49中,示例41的主题可以进一步提供:所述第四指令包括输出指令,所述输出指令包括类型值、模式值和大小值,以及其中,为了执行所述输出指令,所述输出处理器:基于存储在输出处理器的第一本地寄存器中的第一存储器地址从内部存储器读取多个数据值,其中大小值指定多个数据值的数量;连接输出处理器的第二本地寄存器和第三本地寄存器以形成第二存储器地址;以及基于第二存储器地址,以由所述类型值确定的格式将多个数据值写入与处理器关联的存储器。
在示例50中,示例41的主题可以进一步提供:为了初始化加速器电路,处理器在控制寄存器中置位复位标志。
在示例51中,示例41的主题可以进一步提供:为了确定神经网络应用的任务,处理器将神经网络应用划分为将由输入处理器、过滤器处理器、后处理处理器或输出处理器中之一执行的代码段。
在示例52中,示例39的主题可以进一步提供:为将每个任务分配给输入电路块、过滤器电路块、后处理电路块或输出电路块中的相应一个,处理器将任务的指令放置在相应的第一指令存储器、第二指令存储器、第三指令存储器、或第四指令存储器中。
示例53是一种方法,包括由处理器初始化加速器电路,该加速器电路包括输入电路块、过滤器电路块、后处理电路块和输出电路块,确定将由输入电路块、过滤器电路块、后处理电路块或输出电路块中的至少一个执行的神经网络应用的任务,将每个任务分配给输入电路块、过滤器电路块、后处理电路块、或输出电路块中的相应的一个,指示加速器电路执行任务,并基于从完成任务执行的加速器电路接收到的结果,来执行神经网络应用。
示例54是一个加速器电路,包括:用于存储从与处理器相关联的存储器接收到的数据的内部存储器,以及包括多个电路条的过滤器电路块,每个电路条包括过滤器处理器、多个过滤器电路、以及分配给多个过滤器电路的内部存储器的片段,其中过滤器处理器用于执行过滤器指令,基于第一存储器地址从内部存储器读取数据值,对于多个电路条中的每一个:将数据值加载到与电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中以生成多个过滤器结果,并在第二存储器地址处将使用多个过滤器电路生成的结果写入内部存储器中。
在示例55中,示例54的主题可以进一步包括输入电路块,该输入电路块还包括输入处理器、第一指令存储器、第一数据存储器、和第一程序计数器(pc),其中,第一指令存储器用于存储根据输入处理器的第一指令集体系结构(isa)指定的第一任务的第一指令,其中第一pc用于存储将由第一处理器执行的当前第一指令的地址,以及其中输入处理器用于使用存储在第一数据存储器中的第一数据来执行第一指令以执行第一任务,过滤器电路块包括第二指令存储器、第二数据存储器、和第二pc,其中,第二指令存储器用于存储根据过滤器处理器的第二isa指定的第二任务的第二指令,其中第二pc用于存储将由第二处理器执行的当前第二指令的地址,以及其中过滤器处理器用于使用存储在第二数据存储器中的第二数据来执行第二指令以执行第二任务,后处理电路块包括后处理处理器、第三指令存储器、第三数据存储器、第三pc,其中,第三指令存储器用于存储根据后处理处理器的第三isa指定的第三任务的第三指令,其中第三pc用于存储将由第三处理器执行的当前第三指令的地址,以及其中后处理处理器用于使用存储在第三数据存储器中的第三数据来执行第三指令以执行第三任务,并且输出电路块包括输出处理器、第四指令存储器、第四数据存储器,第四pc,其中,第四指令存储器用于存储根据输出处理器的第四isa指定的第四任务的第四指令,其中第四pc用于存储将由第四处理器执行的当前第四指令的地址,以及其中输出处理器用于使用存储在第四数据存储器中的第四数据来执行第四指令以执行第四任务。
在示例56中,示例55的主题可以进一步包括用于存储指示至少一个任务开始执行的第一标志位的多个通用寄存器、用于存储响应于复制事件而将被复制到多个通用寄存器中的内容的多个影子寄存器、以及接口电路,该接口电路包括用于存储至处理器的多个中断的控制寄存器、用于存储指示不同种类的错误的发生的多个错误标志的错误寄存器、用于存储用于选择将被复制到多个通用寄存器的多个影子寄存器的内容的掩码的下一个寄存器、以及用于存储对与处理器相关联的存储器的控制的服务质量寄存器。
在示例57中,示例56的主题可以进一步提供:过滤器电路块包括八个相同的电路条,其中,八个相同的电路条中的电路条包括四个三乘三的卷积神经网络(cnn)过滤器电路、以及分配给四个三乘三cnn过滤器电路的内部存储器的片段。
在示例58中,示例57的主题可以进一步提供:八个相同的电路条中的电路条包括四个三乘三cnn过滤器电路,它们共享第一多个寄存器来存储四个三乘三cnn过滤器电路的共有的权重参数。
在示例59中,示例57的主题可以进一步提供:四个三乘三cnn过滤器电路中之一包括用于存储权重参数的第一多个寄存器、用于存储输入值的第二多个寄存器、包括多个乘法电路以计算权重参数中相应的一个与输入值中相应的一个之间的乘积的归约树、以及用于将来自多个乘法电路的结果与来自三乘三cnn过滤器电路中的另一个的进位结果相加的求和电路。
在示例60中,示例59的主题可以进一步提供:八个相同的电路条各自输出由其中的四个三乘三cnn过滤器电路生成的四个结果,以及其中,过滤器电路块包括四个加法电路,四个加法电路的每一个对来自八个过滤器电路的四个结果中的相应的一个求和。
在示例61中,示例59的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块形成执行流水线,以及其中所述输入电路块的所述输入处理器用于从与处理器相关联的存储器中读取,并将由所述输入电路块生成的第一结果写入内部存储器,过滤器处理器用于从内部存储器中读取第一结果,并将由过滤器电路块生成的第二结果写入内部存储器,后处理处理器用于从内部存储器读取第二结果,并将由后处理电路块生成的第三结果写入内部存储器,以及输出处理器用于从内部存储器读取第三结果,并将由输出电路块生成的第四结果写入与处理器相关联的存储器。
在示例62中,示例59的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块中的至少两个同时操作。
在示例63中,示例59的主题可以进一步提供:所述后处理电路块执行压缩函数、激活函数或top-n函数中的至少一个。
在示例64中,示例59的主题可以进一步提供:所述第一指令包括输入指令,所述输入指令包括类型值、模式值和大小值,以及其中,为了执行所述输入指令,所述输入处理器连接输入处理器的第一本地寄存器和第二本地寄存器以形成第一存储器地址;基于所述第一存储器地址,读取与处理器关联的存储器,以由类型值确定的格式获取数据值,其中,大小值确定与从存储器中获取的数据值相关联的字节数;以及以由模式值确定的模式将数据值写入内部存储器。
在示例65中,示例59的主题可以进一步提供:所述第二指令包括过滤器指令,所述过滤器指令包括和值和模式值,以及其中,为了执行过滤器指令,所述过滤器处理器:基于存储在过滤器处理器的第一本地寄存器中的第一存储器地址从内部存储器中读取数据值;对于每一个电路条:将数据值加载到与该电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果;基于和值,计算来自每个电路条的相应过滤器结果的和值;基于所述模式值,确定所述过滤器电路块是处于片段模式还是处于全局模式;响应于确定过滤器电路块处于片段模式,以存储在第二本地寄存器中的偏移量将和值写入每个片段;以及响应于确定过滤器电路块处于全局模式,在存储在所述第二本地寄存器中的存储器地址处将所述和值写入内部存储器。
在示例66中,示例59的主题可以进一步提供:所述第三指令包括后处理指令,所述后处理指令包括控制寄存器的标识符、列值、行值、以及种类值,其中,为了执行所述后处理指令,所述后处理处理器:响应于确定种类值指示压缩模式,基于存储在第一本地寄存器中的第一存储器地址,从内部存储器读取一定数量的数据值,其中,列值指定组的数量;基于所述列值,将数据值分为多个组;基于种类值,将多个组中的每一个压缩为该组的最大值或该组的第一个元素中之一;确定压缩值和存储在阶段寄存器中的值中的最大值;将最大值存储在状态寄存器中;将激活函数应用于最大值,其中,激活函数是恒等函数、阶跃函数、s型函数或双曲正切函数中之一;以及基于存储在第二本地寄存器中的第二存储器地址,将激活函数的结果写入内部存储器;以及响应于确定种类值指示top-n模式,基于存储在第三本地寄存器中的第三存储器地址,读取数据值阵列;确定阵列中的top-n个值及其相应位置,其中n为大于1的整数;响应于确定控制值指示存储器写入,在存储在第四本地寄存器中的第四存储器地址处将top-n个值及其相应位置写入内部存储器中;以及响应于确定控制值指示寄存器写入,将top-n值及其相应位置写入与所述后处理处理器相关联的状态寄存器中。
在示例67中,示例59的主题可以进一步提供:所述第四指令包括输出指令,所述输出指令包括类型值、模式值和大小值,以及其中,为了执行所述输出指令,所述输出处理器:基于存储在输出处理器的第一本地寄存器中的第一存储器地址从内部存储器读取多个数据值,其中大小值指定多个数据值的数量;连接输出处理器的第二本地寄存器和第三本地寄存器以形成第二存储器地址;以及基于第二存储器地址,以由所述类型值确定的格式将多个数据值写入与处理器关联的存储器。
示例68是一个系统,该系统包括:用于存储数据的存储器;可通信地耦合到该存储器以执行神经网络应用的处理器,该神经网络应用包括使用该数据的过滤器操作;以及加速器电路,包括:内部存储器;包括多个电路条的过滤器电路块,每个电路条包括过滤器处理器、多个过滤器电路以及分配给多个过滤器电路的内部存储器的片段,其中过滤器处理器执行过滤器指令,以基于第一存储器地址读取来自内部存储器的数据值,对于每一个电路条:将数据值加载到与电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果,并在第二存储器地址处将使用多个过滤器电路生成的结果写入内部存储器中。
示例69是一种方法,包括由加速器电路从处理器接收包含过滤器指令的任务,其中加速器电路包括具有多个电路条的过滤器电路块,每个电路条包括过滤器引擎、多个过滤器电路、和分配给多个过滤器电路的内部存储器的片段,从第一存储器地址开始从加速器电路的内部存储器中读取数据值,对于多个电路条的每一个,将该数据值加载到与多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果,并在第二存储地址处将使用多个过滤器电路生成的结果写入内部存储器中。
示例70是一个系统,该系统包括:用于存储数据的存储器、可通信地耦合到该存储器以执行神经网络应用的处理器、以及加速器电路,该加速器电路包括:输入电路块,其包括输入处理器以执行神经网络应用的第一任务;过滤器电路块,其包括过滤器处理器以执行神经网络应用的第二任务;以及通信地耦合到输入电路块、过滤器电路块、后处理电路块和输出电路块的多个通用过滤器,其中输入电路块和过滤器电路块形成执行流水线的阶段,其中生产者阶段将数据值提供给消费者阶段,以及其中消费者阶段的操作一直停止直到存储在多个通用寄存器的第一通用寄存器中的开始标志被生产者置位。
在示例71中,示例68的主题可以进一步提供:加速器电路还包括:后处理电路块,其包括后处理处理器以执行神经网络应用的第三任务;以及输出电路块,其包括输出处理器以执行神经网络的第四任务,其中输入电路块、过滤器电路块形成执行流水线的阶段,后处理电路块、和输出电路块形成执行流水线。
在示例73中,示例71的主题可以进一步提供:生产者阶段是输入电路块,以及消费者阶段是过滤器电路块、后处理电路块、或输出电路块之一,其中生产者阶段是输入电路块或过滤器电路块之一,以及消费者阶段是后处理电路块或输出电路块之一,以及其中生产者阶段是输入电路块、过滤器电路块、或后处理阶段之一,并且消费者阶段是输出电路块。
在示例73中,示例70的主题可以进一步提供:所述输入电路块还包括第一指令存储器、第一数据存储器和第一程序计数器(pc),其中,所述第一指令存储器用于存储根据输入处理器的第一指令集体系结构(isa)指定的第一任务的第一指令,其中第一pc用于存储将由第一处理器执行的当前第一指令的地址,以及其中输入处理器用于使用存储在第一数据存储器中的第一数据执行第一指令以执行第一任务;过滤器电路块还包括第二指令存储器、第二数据存储器、和第二pc,其中第二指令存储器用于存储根据过滤器处理器的第二isa指定的第二任务的第二指令,其中第二pc用于存储将由第二处理器执行的当前第二指令的地址,以及其中过滤器处理器用于使用存储在第二数据存储器中的第二数据执行第二指令以执行第二任务;后处理电路块还包括第三指令存储器、第三数据存储器、和第三pc,其中第三指令存储器用于存储根据后处理处理器的第三isa指定的第三任务的第三指令,其中第三pc用于存储将由第三处理器执行的当前第三指令的地址,以及其中后处理处理器用于使用存储在第三数据存储器中的第三数据执行第三指令以执行第三任务;以及输出电路块还包括第四指令存储器、第四数据存储器、和第四pc,其中第四指令存储器用于存储根据输出处理器的第四isa指定的第四任务的第四指令,其中第四pc用于存储将由第四处理器执行的当前第四指令的地址,以及其中所述输出处理器用于使用存储在第四数据存储器中的第四数据执行第四指令以执行第四任务。
在示例74中,示例73的主题可以进一步提供:加速器电路还包括:多个影子寄存器,其用于存储响应于复制事件将被复制到多个通用寄存器中的内容;以及接口电路,包括:控制寄存器,其用于存储至处理器的多个中断,错误寄存器,其用于存储指示不同种类的错误的发生的多个错误标志,下一个寄存器,其用于存储用于选择将被复制到多个通用寄存器的多个影子寄存器的内容的掩码,以及服务质量寄存器,其用于存储对与处理器相关联的存储器的控制。
在示例75中,示例73的主题可以进一步提供:所述输入电路块的所述输入处理器用于从与处理器相关联的存储器中读取,并将由所述输入电路块生成的第一结果写入内部存储器,过滤器处理器用于从内部存储器中读取第一结果,并将由过滤器电路块生成的第二结果写入内部存储器,后处理处理器用于从内部存储器读取第二结果,并将由后处理电路块生成的第三结果写入内部存储器,以及输出处理器用于从内部存储器读取第三结果,并将由输出电路块生成的第四结果写入与处理器相关联的存储器。
在示例76中,示例73的主题可以进一步提供:输入电路块、过滤器电路块、后处理电路块和输出电路块中的至少两个同时操作。
在示例77中,示例73的主题可以进一步提供:所述第一指令包括输入指令,所述输入指令包括类型值、模式值和大小值,以及其中,为了执行所述输入指令,所述输入处理器连接输入处理器的第一本地寄存器和第二本地寄存器以形成第一存储器地址;基于所述第一存储器地址,读取与处理器关联的存储器,以由类型值确定的格式获取数据值,其中,大小值确定与从存储器中获取的数据值相关联的字节数;以及以由模式值确定的模式将数据值写入内部存储器。
在示例78中,示例77的主题可以进一步提供:响应于确定所述模式值指示第一模式,输入处理器基于存储在第三本地寄存器中的第二存储器地址,写入所述内部存储器;以及响应于确定所述模式值指示第二模式,输入处理器以存储在第三本地寄存器中的偏移量写入多个电路条中的每一个的片段中。
在示例79中,示例73的主题可以进一步提供:所述第二指令包括过滤器指令,所述过滤器指令包括和值和模式值,以及其中,为了执行过滤器指令,所述过滤器处理器:基于存储在过滤器处理器的第一本地寄存器中的第一存储器地址从内部存储器中读取数据值;对于每一个电路条:将数据值加载到与该电路条的多个过滤器电路相关联的权重寄存器和输入寄存器中,以生成多个过滤器结果;基于和值,计算来自每个电路条的相应过滤器结果的和值;基于所述模式值,确定所述过滤器电路块是处于片段模式还是处于全局模式;响应于确定过滤器电路块处于片段模式,以存储在第二本地寄存器中的偏移量将和值写入每个片段;以及响应于确定过滤器电路块处于全局模式,在存储在所述第二本地寄存器中的存储器地址处将所述和值写入内部存储器。
在示例80中,示例73的主题可以进一步提供:所述第三指令包括后处理指令,所述后处理指令包括控制寄存器的标识符、列值、行值、以及种类值,其中,为了执行所述后处理指令,所述后处理处理器:响应于确定种类值指示压缩模式,基于存储在第一本地寄存器中的第一存储器地址,从内部存储器读取一定数量的数据值,其中,列值指定组的数量;基于所述列值,将数据值分为多个组;基于种类值,将多个组中的每一个压缩为该组的最大值或该组的第一个元素中之一;确定压缩值和存储在阶段寄存器中的值中的最大值;将最大值存储在状态寄存器中;将激活函数应用于最大值,其中,激活函数是恒等函数、阶跃函数、s型函数或双曲正切函数中之一;以及响应于确定种类值指示top-n模式,基于存储在第三本地寄存器中的第三存储器地址,读取数据值阵列;确定阵列中的top-n个值及其相应位置,其中n为大于1的整数;响应于确定控制值指示存储器写入,在存储在第四本地寄存器中的第四存储器地址处将top-n值及其相应位置写入内部存储器中;以及响应于确定控制值指示寄存器写入,将top-n个值及其相应位置写入与所述后处理处理器相关联的状态寄存器中。
在示例81中,示例73的主题可以进一步提供:所述第四指令包括输出指令,所述输出指令包括类型值、模式值和大小值,以及其中,为了执行所述输出指令,所述输出处理器:基于存储在输出处理器的第一本地寄存器中的第一存储器地址从内部存储器读取多个数据值,其中大小值指定多个数据值的数量;连接输出处理器的第二本地寄存器和第三本地寄存器以形成第二存储器地址;以及基于第二存储器地址,以由所述类型值确定的格式将多个数据值写入与处理器相关联的存储器。
尽管已经针对有限数量的实施例描述了本公开,但是本领域技术人员将理解从其进行的许多修改和变化。所附权利要求书旨在涵盖落入本公开的真实精神和范围内的所有这种修改和变化。
设计可以经历从创建到仿真再到制造的各个阶段。表示设计的数据可以多种方式表示设计。首先,如在仿真中有用的,可以使用硬件描述语言或另一种功能描述语言来表示硬件。另外,可以在设计过程的某些阶段产生具有逻辑和/或晶体管门的电路级模型。此外,大多数设计在某个阶段达到了表示硬件模型中各种装置的物理布置的数据级别。在使用传统的半导体制造技术的情况下,表示硬件模型的数据可以是指定用于制造集成电路的掩模的不同掩模层上各种特征的存在或不存在的数据。在设计的任何表示中,数据可以以任何形式的机器可读介质存储。存储器或诸如磁盘的磁或光存储装置可以是机器可读介质,用于存储经由光波或电波传输的信息,该光波或电波经调制或以其他方式生成以传输这种信息。当传输指示或承载代码或设计的电载波时,以执行复制、缓冲或重新传输电信号的程度,进行了新的复制。因此,通信提供商或网络提供商可以至少暂时地在有形的机器可读介质上存储体现本公开的实施例的技术的物品,诸如编码为载波的信息。
如本文所使用的模块是指硬件、软件和/或固件的任何组合。作为示例,模块包括与非暂时性介质相关联的诸如微控制器的硬件,以存储适于由微控制器执行的代码。因此,在一个实施例中,对模块的引用指的是专门配置为识别和/或执行保存在非暂时性介质上的代码的硬件。此外,在另一个实施例中,模块的使用是指包括代码的非暂时性介质,该代码特别适于由微控制器执行以执行预定的操作。并且可以推断,在又一个实施例中,术语模块(在该示例中)可以指微控制器和非暂时性介质的组合。通常,被示为单独的模块边界通常会发生变化并且可能重叠。例如,第一和第二模块可以共享硬件、软件、固件或其组合,同时可能保留一些独立的硬件、软件或固件。在一个实施例中,术语逻辑的使用包括诸如晶体管、寄存器的硬件、或诸如可编程逻辑器件的其他硬件的硬件。
在一个实施例中,短语“配置为”的使用是指布置、组合、制造、提供销售、进口和/或设计用于执行指定或确定的任务的设备、硬件、逻辑、或元件。在该示例中,如果没有正在操作的设备或其元件被设计、耦合和/或互连以执行所述指定任务,其仍“配置为”执行指定任务。仅作为说明性示例,逻辑门可以在操作期间提供0或1。但逻辑门“配置为”提供使能信号给时钟不包括可以提供1或0的每一个可能的逻辑门。相反,逻辑门是以某种方式耦合的,使得在操作期间1或0的输出用于启用时钟。再次注意,使用术语“配置为”不需要操作,而是专注于设备、硬件和/或元素的潜在状态,其中在潜在状态下,设备、硬件和/或元件被设计为当设备、硬件和/或元件运行时,执行特定任务。
此外,在一个实施例中,使用短语“用于”、“能够”和或“可操作以”指的是一些设备、逻辑、硬件、和/或元件以这样的方式设计,以使得可以以指定的方式对设备、逻辑、硬件和/或元件进行使用。注意如上所述,在一个实施例中,使用用于、能够、或可操作以是指设备、逻辑、硬件和/或元件的潜在状态,其中该设备、逻辑、硬件和/或元件不是正在运行,而是以可以以指定方式使用设备的方式被设计的。
本文所使用的值包括数字、状态、逻辑状态或二进制逻辑状态的任何已知表示。通常,逻辑电平、逻辑值或逻辑值的使用也被称为1和0,这简单地表示二进制逻辑状态。例如,1指高逻辑电平,0指低逻辑电平。在一个实施例中,诸如晶体管或闪存单元的存储单元可能能够保存单个逻辑值或多个逻辑值。然而,已经使用了计算机系统中的值的其他表示形式。例如,十进制数十也可以表示为二进制值910和十六进制字母a。因此,值包括能够保存在计算机系统中的信息的任何表示形式。
此外,状态可以由值或值的一部分表示。作为示例,第一值,例如逻辑1,可以表示默认或初始状态,而第二值,例如逻辑0,可以表示非默认状态。另外,在一个实施例中,术语复位和置位分别指默认和更新后的值或状态。例如,默认值可能包括高逻辑值,即复位,而更新值可能包括低逻辑值,即置位。注意,值的任何组合可以用于表示任何数量的状态。
上述方法、硬件、软件、固件或代码集的实施例可以经由存储在机器可访问、机器可读、计算机可访问或计算机可读介质上的可以由处理元件执行的指令或代码来实现。非暂时性机器可访问/可读介质包括以诸如计算机或电子系统的机器可读的形式提供(即,存储和/或发送)信息的任何机制。例如,非暂时性机器可访问介质包括随机存取存储器(ram),例如静态ram(sram)或动态ram(dram);rom;磁或光存储介质;闪存装置;蓄电装置;光学存储装置;声学存储装置;其他形式的存储装置,用于保存从瞬态(传播)信号(例如,载波、红外信号、数字信号)接收的信息;等等,这将与可以从中接收信息的非暂时性介质区分开。
用于对逻辑进行编程以执行本公开的实施例的指令可以被存储在系统的存储器内,诸如dram、高速缓存、闪存或其他存储装置。此外,指令可以经由网络或通过其他计算机可读介质来分发。因此,机器可读介质可以包括用于以机器(例如,计算机)可读的形式存储或传输信息的任何机制,但不限于,软盘、光盘、压缩盘、只读存储器(cd-rom)和磁光盘、只读存储器(rom)、随机存取存储器(ram)、可擦可编程只读存储器(eprom)、电可擦可编程只读存储器(eeprom)、磁或光卡、闪存或经由电、光、声或其他形式的传播信号(例如,载波、红外信号、数字信号等)通过互联网传输信息使用的有形的机器可读存储装置。因此,计算机可读介质包括适合于以机器(例如,计算机)可读形式存储或传输电子指令或信息的任何类型的有形机器可读介质。
在整个说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性包括在本公开的至少一个实施例中。因此,在整个说明书中各处出现的短语“在一个实施例中”或“在实施例中”不一定都指的是同一实施例。此外,在一个或多个实施例中,可以以任何合适的方式组合特定的特征、结构或特性。
在前述说明书中,已经参考特定示例性实施例给出了详细描述。然而,将显而易见的是,在不脱离所附权利要求书中所阐述的本发明的更广泛精神和范围的情况下,可以对其进行各种修改和改变。因此,说明书和附图应被认为是说明性而不是限制性的。此外,实施例和其他示例性语言的前述使用不一定指代相同的实施例或相同的示例,而是可以指代不同和有区别的实施例以及潜在地相同的实施例。
- 还没有人留言评论。精彩留言会获得点赞!