一种联邦型分布式RDF数据库上的多查询优化方法与流程
本发明属于联邦型分布式rdf数据查询优化技术领域,主要涉及一种在联邦型rdf数据库上基于查询重写和连接(join)优化的多查询优化方法。
背景技术:
rdf(resourcedescriptionframework)是由w3c提出的一种描述资源概念模型的框架,数据形式用三元组来表示。一个rdf数据文件包含多个资源描述,而一个资源描述由多个三元组语句构成。rdf数据中的三元组通常用<主语(subject),属性(property),客体(object)>来表示,一个rdf数据集可以被视为一系列三元组的集合。rdf的特性是即使底层模式不同也可以促进数据合并;能够扩展网络的链接结构;使用统一资源标识符(uri,uniformresourceidentifier)命名事物之间的关系以及链接的两端。使用rdf模型,我们可以在不同应用程序之间混合、公开和共享结构化和半结构化数据。
sparql(simpleprotocolandrdfquerylanguage)是w3c设计的一种结构化rdf查询语言,用于查询和管理rdf数据。sparql最初由w3c在2008年发行,目前的最新版是2013年公开的sparql1.1。
联邦型rdf数据库(federatedrdfsystem)是一种分布式数据库系统,它集成多个rdf资源为一个系统并提供对这些资源的访问和管理。具体而言,是将rdf数据储存在若干不同机器中“自治”的rdf数据源上,即这些机器中的子系统按其本地rdf管理系统对数据进行管理;同时,提供一个共同的接口给用户处理sparql查询。这些sparql查询接口都从属于“自治”的系统,即能够各自独立地接受sparql查询并得到匹配sparql查询的结果。其中,rdf数据源是指包含一定rdf数据集合和sparql查询接口的机器。
针对联邦型rdf数据库中这些“自治”的rdf数据源,如何有效地利用它们进行sparql查询处理拥有很大的实际应用需求。对于联邦型rdf数据库上的sparql查询处理而言,其中,最关键的问题就是在于如何处理那些无法通过一个rdf数据源上的单独处理来得到匹配的sparql查询。在执行无法由单个rdf数据源处理的sparql查询时,首先需要将查询进行分解,然后分别发送到各个机器上,通过各个机器上的本地sparql接口找到子查询的局部匹配,最终将全部局部结果连接后得到的最终匹配结果。而实际中,用户可能同时发送多个sparql查询到能够处理跨多个“自治”rdf数据源的联邦型rdf数据库系统上,这些查询之间存在一定相似性,而且,这些查询都无法仅通过一个rdf数据源处理上的计算得到匹配。如果只是依次对这些并发的sparql查询进行处理,由于没有利用多个sparql查询之间的相似性,系统处理查询的效率会比较低、吞吐量有限。
现有的联邦型rdf数据库上的sparql查询处理方法在查询分解与数据源选择时都以每个三元组模式为基本单元。即分别求出每个三元组模式所涉及的rdf数据源。对于多sparql查询,现有技术只考虑了逐个对单个查询进行处理而忽略了多个三元组模式间的相似性,这使得一个三元组模式所涉及rdf数据源的数量会被高估而产生过多无效的开销,查询效率低。
技术实现要素:
本发明提出了一种基于查询重写和连接优化的多sparql查询优化技术,用于对联邦型分布式rdf数据库上的多sparql查询进行有效的处理。
本发明克服了现有技术的不足,能够有效地处理多sparql查询。本发明结合利用公共子结构和union、filter这两种操作符对每个rdf数据源上所涉及的查询进行重写,从而降低了查询执行过程中的远程调用次数。同时,本发明进一步利用了values操作符在连接阶段对重写查询进行优化以限制子查询的查找范围、减少子查询的本地查询匹配。
一种联邦型分布式rdf数据库上的多查询优化方法,包括如下步骤:
1.将接收到的每个sparql查询进行分解;
用户发送一组sparql查询,q1,q2,...,qn,其中n为sparql查询总数。一个sparql查询可以被视为一个基础图模型q,q表示为{v(q),e(q),l},
在查询分解阶段,将用户输入的查询q分解成若干子查询{q1,q2,...,qm},其中m为sparql查询中的三元组模式总数。
2.为分解后的每个三元组模式选择数据源,利用基于sparql查询图结构与联邦型rdf数据库中数据源的拓扑关系的方法对数据源进行剪枝;
在数据源选择阶段,根据sparql查询图结构与联邦型rdf数据库中数据源的拓扑关系对每个子查询所涉及的rdf数据源进行剪枝,排除那些无关联的数据源。将每个子查询qi(0<i≤m)与它的相关rdf数据源集合s(qi)结合起来表示成qi@s(qi),称之为qi在s(qi)上的本地查询。根据数据源拓扑关系图,如果一个sparql查询所属的全部数据源之间不连通,那么,这个sparql查询的结果为空;如果一个sparql查询包含的全部数据源中,存在一个数据源与其他相互关联的数据源之间不存在一条或一条以上的连通边,则可以将这个数据源剪枝。
3.将属于相同rdf数据源并且拥有相同子结构的三元组模式重写成相应的sparql查询;
属于一系列相同rdf数据源并且拥有至少一个相似子结构的三元组模式可以被分为同一组,每组三元组模式合并重写为相应的一个sparql查询,同一组中的三元组模式可能来自不同的sparql查询。
4.将重写查询发送到相应rdf数据源的sparql查询接口,得到部分本地查询匹配;
5.利用本地查询匹配进一步优化重写查询,发送优化后的查询到相应rdf数据源的sparql查询接口并得到查询结果;
利用sparql查询和重写查询之间的存在变量的对应关系,本发明提供了一种新的连接优化方法,即基于重写的连接方法。此方法主要分为两个部分:基于values操作符优化重写查询、公共子查询匹配。
通过优先发送选择性低的重写查询至rdf数据源的查询接口,返回的部分本地查询匹配用于结合values操作符来优化后面与其相关的选择性高的查询。
6.将重写查询的部分相同计算整合在一起,共享这些相同匹配的局部结果;
通过扩展现有的频繁子结构挖掘算法,不断找出不同的重写查询中的公共子查询部分。这些公共子查询通常来自于相同的sparql查询,将这些公共子查询的本地查询匹配进行局部匹配以减少全部结果匹配数量。
7.返回每个sparql查询的本地查询匹配进行连接后的最终结果。
将本地查询匹配返回到各个sparql查询,对每个sparql查询的查询匹配进行连接,依次返回每个sparql查询的最终查询结果。
有益效果
本发明提供的一种联邦型分布式rdf数据库上的多查询优化方法,能够有效地处理联邦型分布式rdf数据库上的多sparql查询的请求。本发明针对联邦型分布式rdf数据库上的多sparql查询,利用查询重写、连接优化等策略解决了关键问题。首先,通过优化查询分解和数据源的选择来对数据源进行剪枝,从而避免了对无效查询和数据源的处理开销。其次,利用多种优化策略来重写查询,从而提高查询重写的效率、减少执行过程中的远程调用数。另外,选择性高且缺少查询常量的查询的直接执行容易导致查询的整体执行效率降低,本发明提出的利用values操作符来优化连接操作可以有效地解决此问题。最后,本发明利用查询之间的相似性将部分相同计算整合在一起,共享这些相同匹配的局部结果以减少最终匹配次数。因此,本发明实行的方法提高了系统性能和整体查询效率,在应用过程中非常高效。
附图说明
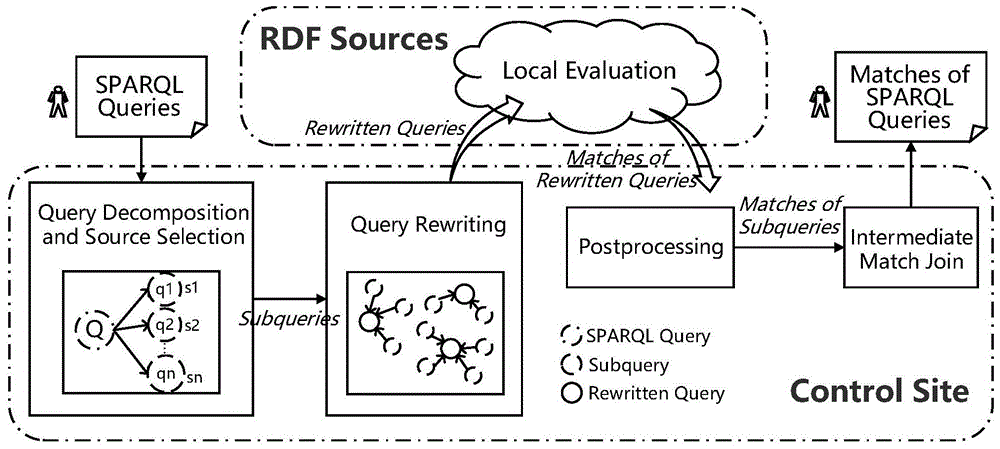
图1为本发明提供的一种联邦型分布式rdf数据库上的多查询优化的方法的整体框架流程示意图;
图2为本发明提供的实施例中的部分sparql查询及一个联邦型分布式rdf数据库系统展示图;
图3为本发明提供的实施例中图2所示查询的查询分解和数据源选择的方法示意图;
图4为本发明提供的实施例中使用union操作符处理的查询重写的示意图;
图5为本发明提供的实施例中使用filter操作符处理的查询重写的示意图;
图6为本发明提供的实施例中结合union操作符和filter操作符处理的查询重写的示意图;
图7为本发明提供的实施例中结合本地查询匹配和values操作符的连接优化的过程示例。
具体实施方式
下面结合实施例对本发明做进一步的说明。
本发明提供的一种基于查询重写和连接优化的多sparql查询优化技术,能够根据sparql查询的特性来进行优化,从而在联邦型分布式rdf数据库上对多sparql查询进行有效的处理。如图1至图7所示,本发明实施的具体方法可分为四个步骤:查询分解与数据源选择、查询重写、本地查询处理与查询后处理、局部解连接。
步骤1:查询分解与数据源选择
本发明提供一种基于数据源拓扑关系图的剪枝策略来找出每个sparql查询的相关数据源,并对每个本地查询相关的rdf数据源进行剪枝。对于用户发送的一组sparql查询,首先将这些查询分解为多个三元组模式,其次,将rdf数据源拓扑关系图上的每个rdf数据源标注在这个rdf数据源相关的本地查询上,并把属于一组相同的数据源的子查询分为同一组。如图3所示,q1、q2和q3分别被分解成了多组子查询,每组子查询都被标记了所属的数据源。从图3中可以看出,一个联邦型的sparql中通常包含多组子查询,这些子查询由一个或多个三元组模式构成,并且属于一组不同的数据源。根据数据源拓扑关系图,如果sparql查询所属的数据源中包含一个不连通的数据源,将剪枝这个数据源。
步骤2:查询重写
本发明的查询重写优化策略的主要思路在于将每个rdf数据源所接收到的需要处理的本地查询重写成更有效的一个或多个重写查询,从而降低系统整体的远程调用次数与查询响应时间。本发明提供多种重写规则,结合sparql查询语义中的union、filter这两种操作符来重写查询,同时,在本地查询匹配的连接优化过程中利用values操作符以进一步改良重写的查询。如图4所示,图中左边的两个查询拥有一个公共的三元组部分?lg:name"canada",则可以通过union操作符改写为右边的查询。如图5所示,图中左边的两个查询除了一个查询常量不同外其他部分完全相同,则可以通过filter操作符改写为右边的一个查询。结合union、filter这两种操作符可以处理更复杂的查询情况。在图6中,同属于geonames数据源的3个子查询q1、q2和q3,通过union、filter这两种操作符被改写为一个sparql查询来表示,从而可以减少了两次远程调用。
步骤3:本地查询处理与查询后处理
在查询重写阶段完成后,一个rdf数据源s需要通过相关的sparql查询接口处理这些重写后的sparql查询,并得到本地查询结果集合,表示为
具体来说,本发明利用一个基于集合交集运算的方法来计算每个本地查询的匹配。对于
步骤4:局部解连接
本发明提供了一种基于重写的连接方法,此方法包括基于values操作符优化重写查询和公共子查询匹配这两部分。对于一组重写的sparql查询,通常既包含选择性高的查询,也包含选择性低的查询。选择性高的查询相较于选择性低的查询而言,由于包含的三元组模式更少,所以缺少限定查询范围的常量的可能性更大,也就是缺少查询中特定的值。如图3中(a)q1所示,查询q1被分解成3个子查询
在全部重写查询执行结束后,通过扩展现有的频繁子结构挖掘算法来不断找出不同的各个重写查询中的公共子查询部分。这些公共子查询通常来自于相同的sparql查询,预先将这些公共子查询的本地查询匹配进行局部匹配以减少全部结果匹配数量,即不断找出不同连接图之间的公共子图中可以合并的连接操作。最后,将本地查询匹配结果返回到各个sparql查询,对每个sparql查询的本地查询匹配结果进行连接匹配,依次返回每个sparql查询的最终查询结果。
综上所述,针对大规模的rdf数据和联邦型rdf数据库上多sparql查询的特性,本发明提供一种联邦型rdf数据库上有效地进行多查询优化的方法,设计了查询分解与资源选择、查询重写、查询模式优化、本地查询匹配的连接方法优化等过程。通过所述方法,能够高效率地在联邦型rdf数据库系统上进行多查询处理。
需要强调的是,上述实例仅仅是本发明的一个具体实施方式,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方案,不脱离本发明宗旨和范围的简单修改、替换等也均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!