一种用于深度学习的资源管理系统及方法与流程
本发明涉及深度学习技术领域,具体涉及一种用于深度学习的资源管理系统及方法。
背景技术:
tensorflow作为最新的、应用范围最为广泛的深度学习开源框架近年来受到了广泛的关注与重视,它不仅便携、高效、可扩展,具有灵活的移植性,编译速度快,还能在不同的计算机上运行:小到智能手机,大到计算机集群都可以。tensorflow现已广泛用于从个人到企业、从初创公司到大公司等不同群体,无论在工业、商业还是科学研究上都展现出巨大的应用价值,因而已成为时下最热门的深度学习框架。
然而,在tensorflow落地的过程中,也存在以下相应的一些问题:(1)资源无法隔离:训练时tensorflow各个任务之间可能因计算资源抢占而互相影响,由于gpu显卡由gpu计算单元和显存组成,如果多个任务共用一个gpu,如果显存不够用的话,会发生训练中断或者其他未知错误;(2)缺乏调度能力:需要用户手动配置和管理任务的计算资源,这些都得在代码中硬编码实现;(3)训练异常中断:当ps或者worker异常导致任务进程退出后,由于tensorflow没有自愈能力,需要人工介入才能恢复训练;(4)无生命周期管理:无法有效管理多个任务的执行过程、以及监控多个任务的状态等;(5)复杂的分布式部署:对于ai开发人员来说,每次发布一个训练任务,都要做一次分布式部署,这在一定程度上加重了程序员的心智负担,他们除了要实现训练任务逻辑外,还得操心有哪些机器资源可以用,如何让这个任务跑起来。
随着ai业务的不断发展,基于tensorflow的神经网络模型的训练时间要求越来越高,单机模式下将难以应付大规模的深度神经网络模型训练。分布式tensorflow集群训练方式虽然解决了单机算力不足的问题,但是本身并没有提供诸如任务调度、监控、失败重启等集群管理功能,这给ai开发人员大规模自动化的模型训练带来了不少的困难。
技术实现要素:
本发明所要解决的技术问题是针对现有技术中存在的上述不足,提供一种用于深度学习的资源管理系统及方法,以实现基于tensorflow的深度学习训练任务资源的统一调度与管理,监控训练过程,支持自动中断与重启,减轻ai开发人员的工作负担,提高任务训练效率。
为实现以上发明目的,采用的技术方案是:
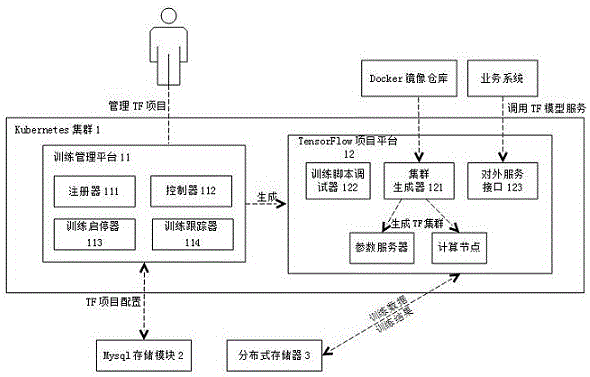
一种用于深度学习的资源管理系统,该系统包括:kubernetes集群、mysql存储模块和分布式存储器;所述kubernetes集群包括训练管理平台和tensorflow项目平台,所述训练管理平台包括注册器和控制器,所述tensorflow项目平台由集群生成器构成;
所述注册器用于注册tensorflow项目,配置项目信息;所述控制器用于解析项目配置文件和创建tensorflow项目;所述集群生成器为训练任务创建tensorflow集群,并进行集群管理;所述tensorflow集群包含参数服务器和计算节点;所述mysql存储模块用于存储tensorflow项目配置信息;所述分布式存储器用于存储训练数据和训练结果。
进一步的,所述训练管理平台还包括训练启停器,所述训练启停器用于启动或停止训练任务。
进一步的,所述训练管理平台还包括训练跟踪器,所述训练跟踪器用于跟踪训练过程的事件、参数,并用图表显示。
进一步的,所述tensorflow项目平台还包括训练脚本调试器,所述训练脚本调试器用于编辑和运行tensorflow代码,及查看运行结果。
进一步的,所述tensorflow项目平台还包括对外服务接口,所述对外服务接口用于向外提供模型服务能力,输出tensorflow网络模型的计算结果。
一种用于深度学习的资源管理方法,包括以下步骤:
步骤s100:创建包含tensorflow训练脚本的docker镜像,并将镜像推送到镜像仓库;
步骤s200:注册tensorflow项目,配置项目信息;
步骤s300:创建tensorflow项目平台,生成tensorflow集群;
步骤s400:启动任务训练,定时保存训练文件;
步骤s500:任务训练结束,生成结果模型。
进一步的,所述步骤s100之后、步骤s200之前还包括:
步骤s101:创建包含tensorflow-web服务的docker镜像,并将镜像推送到镜像仓库。
进一步的,所述步骤s400之后、步骤s500之前还包括:
步骤s401:中断任务训练;
步骤s402:中断后,重启任务训练。
进一步的,所述中断包括:定时中断、人为手动中断和程序异常自动中断三种方式。
进一步的,还包括:
步骤s600:部署产品,对外提供api接口服务。
本发明的一种用于深度学习的资源管理系统及方法,具有以下有益效果:
(1)本发明一种用于深度学习的资源管理系统及方法,通过kubernetes可为每个tensorflow训练任务创建独立的namespace,为每个任务做资源分配与隔离,避免了资源争抢与浪费;通过训练管理平台可跟踪管理各个训练任务,展示训练结果,极大方便了测试人员实时掌握训练情况。通过本发明的资源管理系统及方法,能够提供自动化的tensorflow集群部署,开发人员只需要配置集群的大小、使用的资源类型、训练任务对应的专用镜像等,即可完成tensorflow的集群部署,为开发人员分担了很多繁琐重复的工作,减轻了劳动强度,并可在训练过程中调整训练参数,以此来优化模型或者加快训练速度。
(2)本发明的用于深度学习的资源管理系统及方法,支持训练中断,并具备自愈能力,因而无需开发人员值守,对需要运行数天的训练任务提供了极大的便利;可通过加载已保存的checkpoint文件,使中断的训练不必从头开始,有效提高了训练效率、节约训练资源与成本。
(3)本发明的用于深度学习的资源管理系统及方法,可自动转化训练成果,不需要手动部署,即可向外输出api服务,极大提升了运行效率和节约了人工成本。
附图说明
图1是本发明用于深度学习的资源管理系统结构示意图;
图2是本发明用于深度学习的资源管理方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明的目的在于提供一种用于深度学习的资源管理系统及方法,以实现基于tensorflow的深度学习训练任务资源的统一调度与管理,监控训练过程,支持自动中断与重启,减轻ai开发人员的工作负担,提高任务训练效率。以下将详细阐述本发明的一种用于深度学习的资源管理系统及方法的原理及实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的技术内容。
图1是本发明用于深度学习的资源管理系统结构示意图。如图1所示,本发明一种用于深度学习的资源管理系统,包括:kubernetes集群1、mysql存储模块2和分布式存储器3;kubernetes集群1包括训练管理平台11和tensorflow项目平台12;训练管理平台11包括注册器111、控制器112、训练启停器113和训练跟踪器114;tensorflow项目平台12由集群生成器121、训练脚本调试器122和对外服务接口123构成。以下详细阐明各部分工作内容及原理:
注册器用于注册tensorflow项目(简称tf项目)、配置项目信息。具体的,注册tensorflow项目时,输入项目基础信息,包括:项目名称、项目训练时间计划、训练结果的存储位置等;需配置的项目信息主要包括以下三个方面:(1)训练参数配置:迭代次数、批次大小、初始化学习率、学习率衰减因子、图形增强选择参数、卷积核大小、卷积步长、填充、卷积核数量等;(2)计算资源配置:cpu/gpu的数量、使用的内存大小等;(3)tensorflow集群配置:定义tensorflow集群的运行模式为分布式运行,具体定义参数服务器和计算节点的数量,指定包含训练脚本的docker镜像以及各个容器的启动脚本,该集群配置信息以yaml文件格式保存;(4)对外服务接口配置:包括结果模型的存储路径、web服务的docker镜像以及启动参数等,此配置信息同样以yaml文件格式保存。
控制器主要用于解析项目配置文件和创建tensorflow项目。具体的,控制器提供了kubernetes的一个客户端实现,它解析项目配置中的yaml文件,调用kubernetes的api接口,创建相应的pod进行tensorflow项目组建。另外,它还根据yaml文件,生成serving-pod,加载包含业务逻辑的docker镜像和tensorflow结果模型,对外提供api接口服务。
集群生成器主要为训练任务创建tensorflow集群(tf集群)和进行集群管理。具体的,根据项目的yaml配置文件,生成tensorflow集群,tensorflow集群由kubernetes-pods组成,运行在kubernetes之上;更为具体的,tensorflow集群包含参数服务器和计算节点。
训练启停器用于启动或停止训练任务。具体的,训练启停器为一定时任务模块,可根据训练的时间计划,去启动或停止训练任务。通过定义tensorflow项目的启动时间,可以即时启动,也可以预设一个固定的启动时间及结束时间,将训练任务放到固定的时间段内运行,比如设置在凌晨零点启动训练至凌晨六点结束训练,这样可以充分利用计算资源。
训练跟踪器主要用于跟踪训练过程的事件、参数,并用图表直观显示。具体的,训练跟踪器对训练过程中的异常事件、准确率及图片参数等进行搜集分析,并通过ui图表的形式直观地表现出来,以利于测试人员实时掌握训练情况,为后续任务训练的优化调整做参考。
训练脚本调试器主要用于编辑和运行tensorflow代码,及查看运行结果。具体的,训练脚本调试器为一个支持多开发语言的交互式笔记本,可以在上面直接编辑和快速运行tensorflow代码,并及时查看运行结果,方便研发人员进行代码调试。
对外服务接口主要用于向外提供模型服务能力,业务系统可通过直接调用该服务接口,输出tensorflow网络模型的计算结果。深度学习训练任务完成后,最后生成一个结果模型,具体的,对外服务接口整合了web服务和tensorflow的结果模型,通过web服务对外提供api接口,接入用户图形数据或者文本数据,经过加载结果模型进行计算分析后,得出如图像分类结果、文本分析结果、语音识别结果等,并将结果返回给客户端。更为具体的,web服务的具体业务实现逻辑由训练管理平台业务yaml参数中指定的docker镜像决定。
mysql存储模块主要用于存储tensorflow项目配置信息,当tensorflow项目完成注册和项目信息配置后,相关项目信息通过mysql数据库进行存储,当项目运行时,则通过mysql存储模块进行调用相关信息。
分布式存储器主要用于存储训练数据和训练结果。具体的,分布式存储器可以为ceph或glusterfs分布式存储中的一种,通过接入分布式存储器存储tensorflow定期保存的checkpoint文件,pod失败后能实现自动重启功能,可以自动恢复因异常退出的任务,pod重启的时候重新加载分布式存储器中保存的文件,训练任务不必重头开始,大大提高了训练效率。更为具体的,分布式存储器通过kubernetes的pv资源对象为参数服务器pod、工作节点pod以及对外服务接口pod等提供分布式存储。
图2是本发明用于深度学习的资源管理方法流程图。以下结合图1和图2详细说明本发明用于深度学习的资源管理方法步骤:
步骤s100:创建包含tensorflow训练脚本的docker镜像,并将镜像推送到镜像仓库。开发人员编写完成tensorflow训练脚本后,使用dockerbuild命令创建镜像,并用dockerpush命令将镜像推送到镜像仓库;
进一步的,如需考虑对外提供模型服务,该服务加载tensorflow模型来完成业务处理,通过api接口对外提供服务,还包括步骤s101:
步骤s101:创建包含tensorflow-web服务的docker镜像,并将镜像推送到镜像仓库。开发人员完成编写tensorflow-web服务代码,然后使用dockerbuild命令创建镜像,并用dockerpush命令将镜像推送到镜像仓库。
步骤s200:注册tensorflow项目,配置项目信息。用户登陆训练管理平台,注册一个新的tensorflow项目,填写项目基础信息、配置项目信息等。项目基础信息,包括:项目名称、项目训练时间计划、训练结果的存储位置等;配置项目信息主要包括:(1)训练参数配置信息:迭代次数、批次大小、初始化学习率、学习率衰减因子、图形增强选择参数、卷积核大小、卷积步长、填充、卷积核数量等;(2)计算资源配置信息:cpu/gpu的数量、使用的内存大小等;(3)tensorflow集群配置信息:定义tensorflow集群的运行模式为分布式运行,具体定义参数服务器和计算节点的数量,指定包含训练脚本的docker镜像以及各个容器的启动脚本;(4)对外服务接口配置信息:包括结果模型的存储路径、web服务的docker镜像以及启动参数等。上述(3)和(4)项配置信息均以yaml文件格式保存。
步骤s300:创建tensorflow项目平台,生成tensorflow集群。具体的,训练管理平台根据tensorflow项目配置,自动创建一个tensorflow项目平台,包含有训练脚本调试器、集群生成器和对外服务接口,再由集群生成器自动创建tensorflow集群,tensorflow集群包含有参数服务器和计算节点。更为具体的,通过训练管理平台控制器提供kubernetes的一个客户端实现,它解析项目配置中的yaml文件,调用kubernetes的api接口,创建相应的pod进行tensorflow项目组建;并根据yaml文件,生成serving-pod,加载包含业务逻辑的docker镜像和tensorflow结果模型,对外提供api接口服务。
步骤s400:启动任务训练,定时保存训练文件。tensorflow集群创建成功后,项目平台自动启动训练任务,在训练过程中,按预设的间隔时间自动保存tensorflow的checkpoint文件到分布式存储器中,例如设置每间隔半小时保存一次。
如果训练任务过重、时间过长,可设置定时中断,使训练在指定的时间点进行中断或重启,以充分合理利用资源。进一步的,还包括步骤s401和步骤s402:
步骤s401:中断任务训练。具体的,中断的方式有以下三种:定时中断、人为手动中断和程序异常自动中断;定时中断为预先设定中断时间点,比如将中断时间设定在服务器忙碌的时间段,在服务器空闲时间段重启训练任务;人为手动中断,通常是在需要对有关参数进行调整的情况下执行,比如需要调整可用的gpu、cpu资源或是需要更新代码;程序异常自动中断为发生异常或错误导致运行中断的情况。
步骤s402:中断后,重启任务训练。定时中断或程序异常自动中断后,项目平台可以通过重新加载已保存的checkpoint文件,从保存的最后位置开始继续进行训练,而不必从头开始训练,从而有效提高训练效率,节约训练资源与成本。人为手动中断如需更改代码,则需从头开始训练。
步骤s500:任务训练结束,生成结果模型。任务训练结束后,tensorflow生成结果模型文件,tensorflow项目平台自动将该模型文件转存到分布式存储器的共享目录,供下一步部署服务时使用。
步骤s600:部署产品,对外提供api接口服务。根据步骤s101创建的docker镜像和步骤s500生成的结果模型,组合构成产品,tensorflow项目平台自动部署和运行该产品,对外提供api接口服务。
本发明一种用于深度学习的资源管理系统及方法通过kubernetes可为每个tensorflow训练任务创建独立的namespace,为每个任务做资源分配与隔离,避免了资源争抢与浪费;通过训练管理平台可跟踪管理各个训练任务,展示训练结果,极大方便了测试人员实时掌握训练情况。通过本发明的资源管理系统及方法,能够提供自动化的tensorflow集群部署,开发人员只需要配置集群的大小、使用的资源类型、训练任务对应的专用镜像等,即可完成tensorflow的集群部署,为开发人员分担了很多繁琐重复的工作,减轻了劳动强度,使他们可以将更多的精力放在对训练逻辑的优化调整上,并可在训练过程中调整训练参数,以此来优化模型或者加快训练速度。
本发明的用于深度学习的资源管理系统及方法,支持训练中断,并具备自愈能力,因而无需开发人员值守,对需要运行数天的训练任务提供了极大的便利;可通过加载已保存的checkpoint文件,使中断的训练不必从头开始,有效提高了训练效率、节约训练资源与成本。
本发明的用于深度学习的资源管理系统及方法,可自动转化训练成果,不需要手动部署,即可向外输出api服务,极大提升了运行效率和节约了人工成本。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。凡在本发明的精神和原则之内,所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!