一种基于α叉索引树的多关键词密文排序检索方法与流程
本发明属于云计算安全领域,具体涉及一种基于α叉索引树的多关键词密文排序检索方法。
背景技术:
在大数据的环境下,如何从海量数据中高速有效的检索出用户需要的信息,成为当下迫切需要解决的问题。云计算技术凭借其高质量计算、存储、应用能力成为了it行业中的一种主流模式。在云环境下,用户把资源数据服务外包给云服务端来最小化支出成本,而保护用户隐私,防止数据被泄露,保证从云服务端获取数据的高效性和有效性也成为了人们关心的焦点。
传统的解决数据泄露的方法是对原始数据进行数据加密,但这会使数据利用面临严重的挑战。基于明文的搜索方案或许可以保证数据的安全性,但是具有较高的时间复杂度和空间复杂度,不适用于大数据检索。为了解决这一问题,人们在密码学的理论基础上提出了一系列的可搜索加密方法,这些加密方法或者不具有高精确度的检索结果,或者在时间、空间的开销上花费巨大。因此,有必要提出一种高效且有效的索引方法,来提高检索的效率。
多关键字检索方法使得用户可以输入多个查询关键字来获取最相关文档。针对检索结果又可以分为可排序检索以及不可排序检索。在不可排序检索中,常见检索方案有连接关键词搜索方案,即返回所有包含检索关键词的文档;析取关键词搜索方案,即返回所有包含关键字子集的文档;以及支持以上两种方案的谓语搜索方案。很明显,不可排序检索不适用于精确top-k查找。对于可排序检索,目前较为成熟的方案是利用向量空间模型将明文文档抽象成高维空间中的“点”,再通过安全内积的方法对检索文档和检索关键词进行加密,利用安全内积的值来进一步描述检索文档与检索关键词之间的相关度得分,通过比较相关度得分获取我们所需要的top-k最相关文档。为了提高检索的效率,安全高效的索引构建方式显得尤为重要。目前,较为典型的索引结构有线性索引、平衡二叉树索引、多维b树索引、关键词平衡二叉树索引、层次聚类树索引等。这些方案或许能够较为准确的返回排序文档,但随着文档基数的增加,其索引树空间开销较大,且检索算法的剪枝效果也会降低,从而导致检索效率降低,因此有必要提出一种安全高效且有效的多关键词密文排序检索方法。
技术实现要素:
发明目的:本发明提供一种基于α叉索引树的高效多关键词密文排序检索方法,可使数据拥有者以更低的索引开销来构建安全的多叉索引树,并上传到云服务器;同时,数据使用者能够获得更高的检索效率,实现精确检索。
技术方案:本发明所述的是一种基于α叉索引树的多关键词密文排序检索方法,包括以下步骤:
(1)数据拥有者生成密钥k={key,s,m1,m2},其中key为加密密钥,s为随机向量,m1和m2为随机可逆矩阵;对明文文档集合进行预处理,通过向量空间模型对明文文档进行向量化;
(2)通过二分k-means聚类方法对明文文档集进行二分聚类处理,构建二分聚类树,最后遍历该二分聚类树叶子节点获取聚类文档序列;
(3)基于聚类文档序列,自底向上构建明文α叉索引树;
(4)通过密钥key对明文文档进行加密,通过s、m1和m2对α叉索引树进行加密,将加密后的文档以及加密索引树发送至云服务器,同时与授权用户共享密钥;
(5)授权用户根据检索需求生成检索向量,通过s、m1和m2对检索向量进行加密处理,生成检索陷门;
(6)授权用户将检索陷门和检索需返回的文档数量k发送至云服务器,然后等待接收检索结果;
(7)云服务器接收到检索陷门后,采用贪婪深度优先遍历搜索算法对步骤(4)中索引树进行检索,获取加密文档向量与检索陷门内积计算结果最大的k个加密文档,并作为检索结果返回给授权用户;
(8)授权用户接收到云服务器返回的加密文档后,通过密钥key对加密文档进行解密,进而获得明文检索结果。
所述步骤(2)包括以下步骤:
(21)将明文文档集合ds看成一个原始簇,并作为二分聚类树的根节点,利用二分k-means聚类方法进行自顶向下的二分处理;
(22)每执行一次二分k-means聚类,原始簇划分成两个子簇,将这两个子簇作为原始簇的两个孩子节点构建二分聚类树;不断递归,直到划分生成的子簇只包含一个文档为止;
(23)遍历二分聚类树中的叶子节点,获取聚类文档序列
所述步骤(3)包括以下步骤:
(31)数据拥有者基于步骤(23)中生成的聚类文档序列
(32)从子层节点序列中依次取α个节点构造父节点,并将父节点加入到父层节点序列中;若子层节点序列中剩余节点数不足α,则将剩余节点直接移入父层节点序列;
(33)将父层节点序列中的节点依次移入子层节点序列,重复步骤(32),不断向上构建索引树,当父层节点序列只含有一个节点时,α叉索引树构造完成,该节点即为α叉索引树的根节点。
所述步骤(4)包括以下步骤:
(41)利用密钥key对文档集合ds中的每个文档di进行加密处理生成密文
(42)为明文文档集合ds中的任意文档di生成其对应的明文文档向量di,如果关键词wj∈di则di[j]存储wj对应的tf值,否则di[j]为0;
(43)利用密钥s对文档向量di根据如下公式拆分成d′i和d″i,再利用可逆矩阵m1,m2进行加密得到索引向量
所述步骤(5)包括以下步骤:
(51)根据检索关键词集wq构建检索向量q,如果wi∈wq,q[i]中存储wi的idf值,否则q[i]的值为0;
(52)利用密钥s,根据如下公式将q拆分成两个向量q′和q″,
(53)利用m1和m2进行加密得到检索陷门
所述步骤(6)包括以下步骤:
(61)云服务器收到授权用户上传的检索陷门后,采用贪婪深度优先遍历搜索算法对步骤(4)中索引树进行检索;
(62)若检索节点为中间节点,计算过滤向量和检索陷门的内积值,如果计算结果大于第k个最相关文档与检索陷门的内积值,则继续向下搜索,否则直接剪枝以该中间节点为根的子树;
(63)如果检索节点为叶子节点,计算叶子节点文档向量与检索陷门的内积值,获取与检索陷门内积值最大的k个文档作为返回结果。
有益效果:与现有技术相比,本发明的有益效果:1、通过采用二分k-means对原文档数据进行聚类处理生成聚类树,而后自底向上构建索引树,检索效率更高,剪枝效果更好,构造的α叉索引树具有较少的中间节点以及较低的索引空间开销,其检索过程中过滤向量与检索陷门进行内积计算与比较的次数更少,检索效率更佳;2、本发明α叉索引树节点采用的是存放过滤向量的方式,在文档检索的时候,所有得分高于返回结果列表中最小相关度得分的节点必然被检索出来,从而与检索陷门相关度更高的文档也必然会被遍历出来并更新在返回结果列表中,能够实现精确检索;3、本发明采用与α叉索引树的构造方式,每一个中间节点包含1~α个孩子节点,与基于线性的索引以及基于平衡二叉树的索引方式相比,α叉索引树的高度以及总节点个数必然更小,从而大大降低索引空间开销。
附图说明
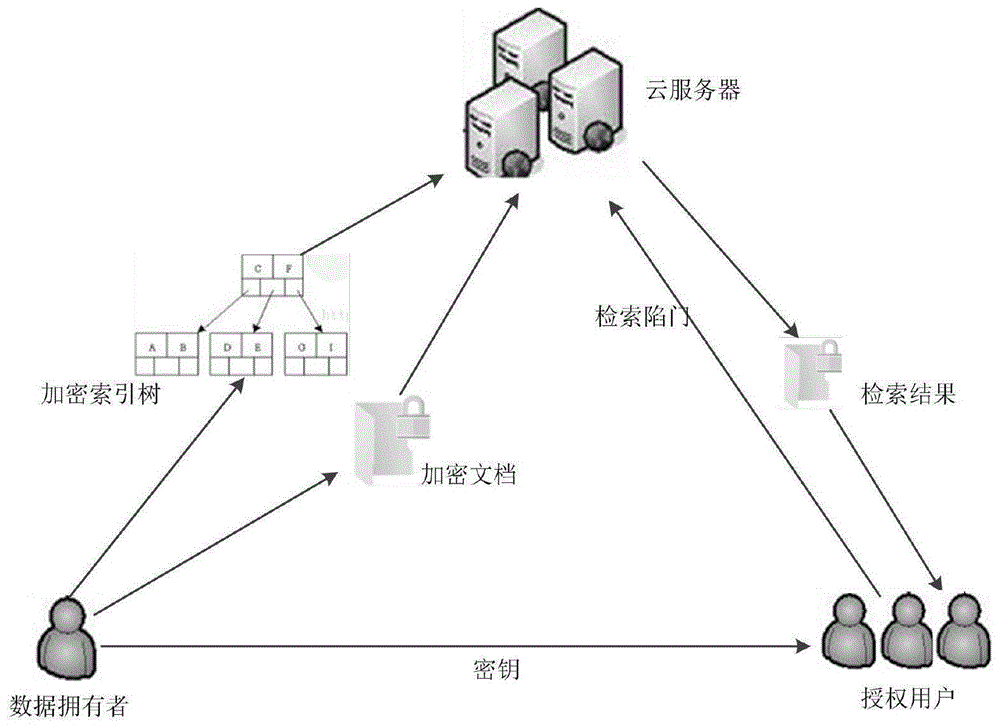
图1为本发明的系统架构图;
图2为本发明数据处理流程图;
图3为本发明排序检索流程图;
图4为τ=3时二分聚类树生成过程;
图5为α=3时α叉索引树的生成过程。
具体实施方式
下面结合附图,对本发明作进一步详细说明。
为了方便描述,现对相关符号作如下定义:
n表示文档的个数,m表示关键词字典的长度。密钥k={key,s,m1,m2},其中key为文档加密密钥,s为m维的随机向量,m1,m2为m×m的可逆矩阵。文档集合ds={d1,d2,…,dn},加密后的密文集合
如图1所示为本发明的系统框架图,描述了数据拥有者、云服务器和授权用户之间进行数据交换及处理的逻辑。数据拥有者负责把外包数据集ds进行数据加密,并与加密索引树一起上传到云服务器,同时对授权用户共享密钥。授权用户可以通过检索指令q生成检索陷门指令td,并对云服务器发出检索请求,获取检索结果。云服务器存储加密的数据集
本发明包括两个阶段:数据处理阶段以及排序检索阶段。
如图2所示,数据处理阶段包括以下步骤:
(1)数据拥有者生成密钥k={key,s,m1,m2},其中key为加密密钥,s为随机向量,m1和m2为m×m的随机可逆矩阵;
(2)数据拥有者对明文文档集进行预处理,通过向量空间模型对明文文档进行向量化。具体实现方法如下:数据拥有者为明文文档集合ds中的任意文档di生成其对应的明文文档向量di,如果关键词wj在文档di中,则di[j]存储wj在di中的tf值;否则di[j]为0。
(3)数据拥有者通过二分k-means聚类方法对明文文档集进行二分聚类处理,构建二分聚类树,最后遍历该二分聚类树叶子节点获取聚类文档序列。具体实现方法如下:
①如图4所示,将明文文档集合ds={d1,d2,…,d6}看成一个原始簇,并作为二分聚类树的根节点,利用二分k-means聚类方法进行自顶向下的二分处理。
②每执行一次二分k-means聚类,原始簇划分成两个子簇,将这两个子簇作为原始簇的两个孩子节点构建二分聚类树;不断递归,直到划分生成的子簇只包含一个文档为止,此时,二分聚类树的构造完成。
③遍历二分聚类树叶子节点获取聚类文档序列
(4)数据拥有者基于聚类文档序列
①如图5所示,数据拥有者基于聚类文档序列
②从子层节点序列中依次取α个节点构造父节点,并将父节点加入到父层节点序列中;若子层节点序列中剩余节点数不足α,则将剩余节点直接移入父层节点序列。
③将父层节点序列中的节点依次移入子层节点序列,重复②步骤,不断向上构建索引树。当父层节点序列只含有一个节点时,α叉索引树构造完成,该节点即为α叉索引树的根节点。
(5)数据拥有者通过密钥key对明文文档进行加密,通过s、m1和m2对明文索引进行加密,并将加密后的文档以及索引树发送至云服务器,同时对授权用户共享密钥。具体加密方法如下:
①利用密钥key对文档集合ds中的每个文档di进行加密处理生成密文
②利用密钥s对文档向量di根据如下公式拆分成d′i和d″i,再利用可逆矩阵m1,m2进行加密得到索引向量
如图3所示,排序检索阶段包括以下步骤:
(1)授权用户根据检索需求生成检索向量,通过s、m1和m2对检索向量进行加密处理,生成检索陷门。具体处理过程如下:
①根据检索关键词集wq构建检索向量q,如果wi∈wq,q[i]中存储wi的idf值,否则q[i]的值为0。
②利用密钥s,根据如下公式将q拆分成两个向量q′和q″,
③利用m1和m2进行加密得到检索陷门
(2)授权用户将检索陷门和检索需返回的文档数量k发送至云服务器,然后等待接收检索结果。
(3)云服务器接收到授权用户发来的检索陷门后,采用深度优先遍历搜索算法对α叉索引树进行检索。具体处理过程如下:
①云服务器收到授权用户上传的检索陷门后,采用贪婪深度优先遍历搜索算法对索引树进行检索。
②若检索节点为中间节点,计算过滤向量和检索陷门的内积值,如果计算结果大于第k个最相关文档与检索陷门的内积值,则继续向下搜索,否则直接剪枝以该中间节点为根的子树。
③如果检索节点为叶子节点,计算叶子节点文档向量与检索陷门的内积值,获取与检索陷门内积值最大的k个文档作为返回结果。
(4)授权用户接收到云服务器返回的加密文档后,通过密钥key对加密文档进行解密,进而获得明文检索结果。
- 还没有人留言评论。精彩留言会获得点赞!