接口数据获取方法及系统与流程
本发明涉及接口数据获取技术领域,特别是涉及一种接口数据获取方法及系统。
背景技术:
现有企业间的接口数据传递,多数是提供各类业务的web系统。供应商的工作人员,定时/不定时的登录系统,进入功能,手输过滤条件进行数据查询,并下载数据到excel文件或其他格式的文件上。下载下来的文件,再通过人工的认识进行数据整理和转换。这种方式,往往需要企业配备固定的工作人员,耗费大量的人力成本和时间成本。
技术实现要素:
本发明针对现有技术存在的问题和不足,提供一种接口数据获取方法及系统。
本发明是通过下述技术方案来解决上述技术问题的:
本发明提供一种接口数据获取方法,其特点在于,其包括以下步骤:
s1、配置接口web系统的登陆账号和登陆密码,通过自动模拟人工的方式进行接口web系统的登陆;
s2、通过图片识别技术对登陆验证码进行识别;
s3、对配置的登陆账号和登陆密码以及识别出的登陆验证码进行验证,在验证成功时,进入步骤s4;
s4、根据预设的查询策略通过网络爬虫技术对接口web系统的数据进行获取;
s5、通过数据纠错和数据补全机制对获取到的接口数据进行处理;
s6、存储处理后的接口数据。
较佳地,在步骤s4中,通过网络爬虫技术进行excel、cvs、html等文件或者内容获取。
较佳地,在步骤s6中,通过mysql文件数据库进行接口数据的存储。
本发明还提供一种接口数据获取系统,其特点在于,其包括配置登陆模块、识别模块、验证模块、数据获取模块、数据处理模块和数据存储模块;
所述配置登陆模块用于配置接口web系统的登陆账号和登陆密码,通过自动模拟人工的方式进行接口web系统的登陆;
所述识别模块用于通过图片识别技术对登陆验证码进行识别;
所述验证模块用于对配置的登陆账号和登陆密码以及识别出的登陆验证码进行验证,在验证成功时调用数据获取模块;
所述数据获取模块用于根据预设的查询策略通过网络爬虫技术对接口web系统的数据进行获取;
所述数据处理模块用于通过数据纠错和数据补全机制对获取到的接口数据进行处理;
所述数据存储模块用于存储处理后的接口数据。
较佳地,所述数据获取模块用于通过网络爬虫技术进行excel、cvs、html等文件或者内容获取。
较佳地,所述数据存储模块用于通过mysql文件数据库进行接口数据的存储。
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
本发明的积极进步效果在于:
本发明通过人工模拟技术、图片识别技术、网络数据获取技术的组合使用,让接口数据获取工作变得简单高效,节省了大量的人力和时间。而且,本发明通过数据纠错和数据补全机制,保证数据正确性,代替人工日常重复性操作,提高效率90%以上。
附图说明
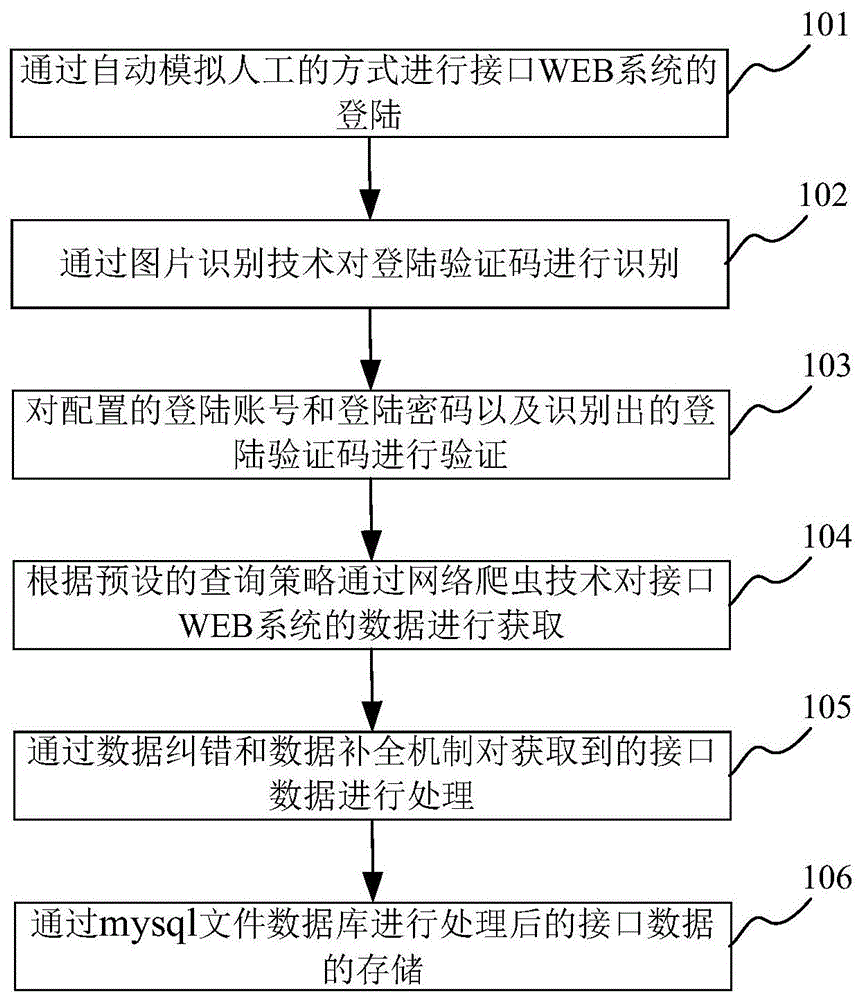
图1为本发明较佳实施例的接口数据获取方法的流程图。
图2为本发明较佳实施例的接口数据获取方法的结构框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本实施例提供一种接口数据获取方法,其包括以下步骤:
步骤101、配置接口web系统的登陆账号和登陆密码,通过自动模拟人工的方式进行接口web系统的登陆。
首先将登陆账号和登陆密码配置在接口web系统上,根据预设的定时时间自动登陆登陆账号和登陆密码,而不需要人工手动输入登陆账号和登陆密码,节省了人力成本。
步骤102、通过图片识别技术对登陆验证码进行识别。
通过图片识别技术识别登陆验证码,而不需要人工手动输入登陆验证码,节省了人力成本。
步骤103、对配置的登陆账号和登陆密码以及识别出的登陆验证码进行验证,即自动输入的登陆账号和登陆密码和自动识别出的登陆验证码与预先存储的登陆账号、登陆密码和登陆验证码进行一一匹配验证,在一一匹配时表明身份验证成功。
步骤104、根据预设的查询策略通过网络爬虫技术对接口web系统的数据进行获取,如通过网络爬虫技术进行excel、cvs、html等文件或者内容获取。
步骤105、通过数据纠错和数据补全机制对获取到的接口数据进行处理,以保证获取的接口数据的正确性。
步骤106、通过mysql文件数据库进行处理后的接口数据的存储。
如图2所示,本实施例还提供一种接口数据获取系统,其包括配置登陆模块1、识别模块2、验证模块3、数据获取模块4、数据处理模块5和数据存储模块6。
所述配置登陆模块1用于配置接口web系统的登陆账号和登陆密码,通过自动模拟人工的方式进行接口web系统的登陆。
所述识别模块2用于通过图片识别技术对登陆验证码进行识别。
所述验证模块3用于对配置的登陆账号和登陆密码以及识别出的登陆验证码进行验证,在验证成功时调用数据获取模块4。
所述数据获取模块4用于根据预设的查询策略通过网络爬虫技术对接口web系统的数据(excel、cvs、html等文件或者内容)进行获取。
所述数据处理模块5用于通过数据纠错和数据补全机制对获取到的接口数据进行处理。
所述数据存储模块6用于通过mysql文件数据库进行处理后的接口数据的存储。
本发明在互联网上,根据设置好的指定网络地址,通过类似搜索引擎的技术方式和预设好的查询策略,对企业间接口系统的web网页内容进行数据获取,经过一定的自动分析和过滤,对数据进行下载存储。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
技术特征:
技术总结
本发明公开了一种接口数据获取方法及系统,包括:S1、配置接口WEB系统的登陆账号和登陆密码,通过自动模拟人工的方式进行接口WEB系统的登陆;S2、通过图片识别技术对登陆验证码进行识别;S3、对配置的登陆账号和登陆密码以及识别出的登陆验证码进行验证,在验证成功时,进入S4;S4、根据预设的查询策略通过网络爬虫技术对接口WEB系统的数据进行获取;S5、通过数据纠错和数据补全机制对获取到的接口数据进行处理;S6、存储处理后的接口数据。本发明通过人工模拟技术、图片识别技术、网络数据获取技术的组合使用,让接口数据获取工作变得简单高效,节省了大量的人力和时间。
技术研发人员:王郁
受保护的技术使用者:上海因致信息科技有限公司
技术研发日:2019.01.08
技术公布日:2019.05.21
- 还没有人留言评论。精彩留言会获得点赞!