一种基于SiameseFC框架和PFP神经网络的目标跟踪方法与流程
本发明属于计算机视觉技术领域,具体涉及一种基于siamesefc框架和pfp神经网络的目标跟踪方法。
背景技术:
目标跟踪由于其在行为分析、车辆导航、人机交互、医学成像、视频监控等众多领域都有着广阔的应用,从而成为计算机视觉技术最活跃的研究之一。目标跟踪是指在给定视频第1帧中的目标位置,对之后的每一帧进行目标定位。目标跟踪的核心问题紧跟随着时间不断变化的目标。尽管近年来在国内外学者的不断研究下,目标跟踪算法得到了迅速发展,但在光照变化剧烈、目标快速运动、部分遮挡等情况下仍然无法取得很好效果。
近年来,国内外学者提出了多种跟踪算法,主要可以分成两类:一类是基于对于目标本身进行描述和刻画的生成式模型;另一类旨在将目标和背景分离开的判别式模型。生成式模型重点在于建立目标外观模型的表征,虽然构建有效的外观模型以处理跟踪中的各种具有挑战性的情况至关重要,但是与此同时,也会增加很大的计算复杂度,并且还会丢弃了可用于更好地将对象与背景分离的目标区域周围的有用信息;判别式模型将跟踪问题转换为目标和背景的二分类问题,即把跟踪的目标作为前景,利用在线学习或离线训练的判断器来区分前景目标和背景,从而得到前景目标的位置。在进行判断前往往会进行特征提取,以作为判断依据提高判断的精确度,但是这也会导致有大量的候选样本需要进行特征提取,使得难以达到实时性。
相关滤波是一种传统的信号处理方法,其描述了两个样本之间的相似程度。2015年kcf算法采用多通道hog特征,生成循环样本集训练出滤波器并通过傅里叶域的快速运算实现了高速的目标跟踪。但是kcf算法在卷积求解中使用的固定大小的模板,从而导致模型没有尺度自适应的功能,dsst算法在原本的位置滤波器基础上增加了一个尺度滤波器,fdsst算法在dsst算法的基础上进行改进增加其跟踪速度,samf算法通过多尺度采样获取候选样本来使得模型具有尺度适应性。由于使用循环位移构造样本增加正负样本数量,图像像素会跨越边界,这样就产生的错误样本,使得分类器判别力降低,即所谓的边界效应。2015年提出的srdcf算法通过引入成一种符合空间约束的正则化权重系数从而极大地减小了边界效应,提高了跟踪精度。基于相关滤波的跟踪算法属于判别式跟踪算法,其在进行判断前往往会进行特征提取,以作为判断依据提高判断的精确度,特征的表征能力在很大程度上决定了跟踪效果。自从2012年hinton利用alexnet深度卷积神经网络在imagenet图像分类比赛中一举获得第一后,深度卷积神经网络开始兴起,其在许多任务中也展现了其令人惊叹的性能,特别是其所具有的强大的特征提取能力。2015年提出deepsrdcf算法将vgg深度卷积神经网络应用于srdcf算法中,使得精度得到进一步的提高。2016年提出的siamesefc使用全卷积孪生神经网络分别得到模板图像和搜索区域的特征图,直接将模板图像的特征图作为滤波器得到搜索区域中的目标,siamesefc实现了端到端的训练,使神经网络提取的特征更适用于目标跟踪,同时也解决了边界效应的问题,但是其只能使用单层神经网络所输出的特征图,没有很好的融合上下文信息和不同感受野的信息,这一局限限制了其区分目标与背景和对目标精确定位的能力。
针对目前跟踪算法只使用神经网络最后一层输出的特征,不能很好的融合上下文信息和不同感受野的信息,需要设计一种跟踪算法,使其能很好地融合上下文信息和不同感受野的信息,从而更好的预测目标的位置,使得跟踪精度得到提高。
技术实现要素:
为解决背景技术中存在的问题,本发明的目的在于提供一种基于siamesefc框架和pfp神经网络的目标跟踪方法。
基于上述目的,本发明采用如下技术方案:
一种基于siamesefc框架和pfp神经网络的目标跟踪方法,其特征在于,包括以下步骤:
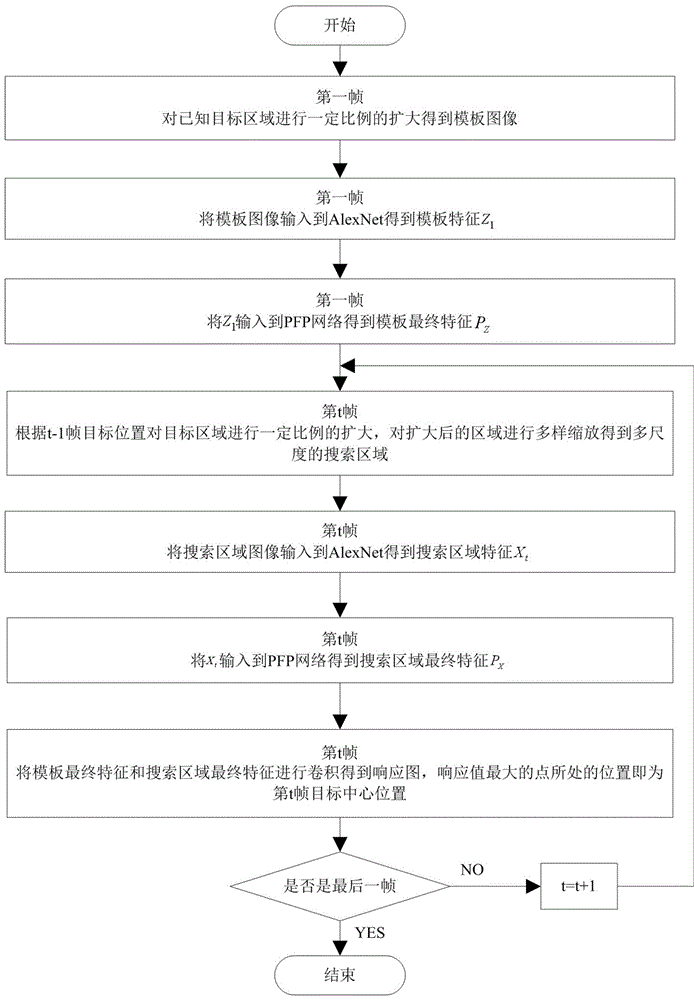
(1)基于siamesefc框架,对视频第1帧中跟踪目标的中心位置所在的目标区域进行扩大,得到模板图像;将模板图像输入到alexnet中,得到模板特征;将模板特征输入到pfp神经网络中,得到模板最终特征pz;
(2)基于siamesefc框架,对t-1帧中跟踪目标的中心位置所在的目标区域进行处理得到搜索区域;将搜索区域输入到alexnet中,得到搜索区域特征;将搜索区域特征输入到pfp神经网络中得到搜索区域最终特征px,其中,t为大于等于2的整数;
(3)将步骤(1)得到的模板最终特征pz作为卷积核,在步骤(2)得到的搜索区域最终特征px上进行卷积,得到pz和px的相关响应图,响应图中响应值最大点所在位置即为第t帧中跟踪目标的中心位置(xt,yt),并确定目标区域(lt,ht);
(4)重复步骤(2)步骤(3)至视频结束,完成对跟踪目标的中心位置以及目标区域的跟踪。
进一步地,所述步骤(1)中获得模板最终特征pz过程具体为:
①.对视频第1帧中跟踪目标的中心位置所在的目标区域进行扩大,得到模板图像,具体过程为:确定第1帧中跟踪目标的中心位置(x1,y1)以及目标区域(l1,h1),对目标区域进行扩大,得到模板图像z1(lp,1,hp,1);即
z1(lp,1,hp,1)=α(l1,h1)
其中,x1为第1帧中跟踪目标的中心位置的横坐标;y1为第1帧中跟踪目标的中心位置的纵坐标;l1为目标区域的长度;h1为目标区域的宽度;α为扩大比例;lp,1为扩大后目标区域的长度;hp,1为扩大后目标区域的宽度;
②.将模板图像输入到alexnet中,得到模板特征,具体过程为:以alexnet作为基础神经网络,将模板图像输入到基础神经网络中后得到模板特征
③.将模板特征z1输入到pfp神经网络中,得到模板最终特征。
进一步地,步骤③中将模板特征z1输入到pfp神经网络的具体过程为:
a.将模板特征z1输入到pfp神经网络中,对z1进行上采样得到特征
b.将
c.将特征z1、
进一步地,步骤(2)中获得搜索区域最终特征px过程具体为:
i.基于siamesefc框架,对t-1帧中跟踪目标的中心位置所在的目标区域进行处理得到搜索区域,具体过程为:根据t-1帧中跟踪目标的中心位置(xt-1,yt-1)以及目标区域(lt-1,ht-1),对目标区域进行扩大,得到扩大后的目标区域(lp,t,hp,t),即(lp,t,hp,t)=γ(lt-1,ht-1),对扩大后的目标区域进行多尺度缩放,得到多种搜索区域图像xt{(lt,ht)},即xt{(lt,ht)}={β(lp,t,hp,t)},再将多种搜索区域图像xt{(lt,ht)}通过插值进行变换为固定大小的搜索区域xt(lt,ht),其中xt-1为第t-1帧跟踪目标的中心位置的横坐标;yt-1为第t-1帧跟踪目标的中心位置的纵坐标;lt-1为第t-1帧目标区域的长度;ht-1为第t-1帧目标区域的宽度;lp,t为扩大后目标区域的长度;hp,t为扩大后目标区域的宽度;γ为扩大比例;lt为第t帧搜索区域的长度;ht为第t帧搜索区域的宽度;β为缩放比例;
ii.将搜索区域输入到alexnet中,得到搜索区域特征,具体过程为:以alexnet作为基础神经网络,将搜索区域输入到基础神经网络中后得到搜索区域特征
iii.将搜索区域特征xt输入到pfp神经网络中得到搜索区域最终特征px。
进一步地,步骤iii中将搜索区域特征xt输入到pfp神经网络的具体过程为:
a.将搜索区域特征xt输入到pfp神经网络中,对xt进行上采样得到特征
b.将
c.将特征xt、
与现有技术相比,本发明的有益效果为:
本发明基于siamesefc框架,结合pfp神经网络,实现对目标的跟踪,能够对同一深度、不同尺度和不同感受野的特征进行融合,避免了各特征抽象级别不同,也实现了上下文信息和不同感受野信息的融合,从而提高目标跟踪精度;此外,本发明提供的一种基于siamesefc框架和pfp神经网络的目标跟踪方法是一种实时鲁棒性的跟踪算法,在不同的跟踪场景中取得了良好的效果。
附图说明
图1为本发明的方法流程图;
图2为本发明的神经网络框架图。
具体实施方式
如图1和图2所示,一种基于siamesefc框架和pfp神经网络的目标跟踪方法,具体步骤为:
1)对于跟踪任务给予的视频中第1帧跟踪目标的中心位置(x1,y1)以及目标区域(l1,h1)信息,对目标区域进行扩大,得到模板图像z1(lp,1,hp,1);即
z1(lp,1,hp,1)=α(l1,h1)
其中,x1为第1帧中跟踪目标的中心位置的横坐标;y1为第1帧中跟踪目标的中心位置的纵坐标;l1为目标区域的长度;h1为目标区域的宽度;α为扩大比例;lp,1为扩大后目标区域的长度;hp,1为扩大后目标区域的宽度;目标区域是一个紧紧包围跟踪目标的示意框,跟踪目标的大小、形状决定了目标区域的大小,不同跟踪目标对应的目标区域不尽相同,在本实施例中,所得的模板图像的大小为127*127*3,由于模板图像的实际大小为127*127,而每一张彩色照片的通道数均为3,故在模板图像的大小采用(实际大小*通道数)进行表示;
2)以alexnet作为基础神经网络,将模板图像输入到基础神经网络中后得到模板特征
3)将模板特征z1输入到pfp神经网络中,对z1进行上采样得到特征
4)将
5)将特征z1、
6)基于siamesefc框架,对t-1帧中跟踪目标的中心位置所在的目标区域进行处理得到搜索区域,具体过程为:根据t-1帧中跟踪目标的中心位置(xt-1,yt-1)以及目标区域(lt-1,ht-1),对目标区域进行扩大,得到扩大后的目标区域(lp,t,hp,t),即(lp,t,hp,t)=γ(lt-1,ht-1),对扩大后的目标区域进行多尺度缩放,得到多种搜索区域图像xt{(lt,ht)},即xt{(lt,ht)}={β(lp,t,hp,t)},再将多种搜索区域图像xt{(lt,ht)}通过插值进行变换为固定大小的搜索区域xt(lt,ht),变换后所得的搜索区域的大小为255*255*3,其中,t为大于等于2的整数,β为缩放尺度,β={0.985,0.99,1,1.005,1.01,1.015};xt-1为第t-1帧跟踪目标的中心位置的横坐标;yt-1为第t-1帧跟踪目标的中心位置的纵坐标;lt-1为第t-1帧目标区域的长度;ht-1为第t-1帧目标区域的宽度;lp,t为扩大后目标区域的长度;hp,t为扩大后目标区域的宽度;γ为扩大比例;lt为第t帧搜索区域的长度;ht为第t帧搜索区域的宽度;
7)以alexnet作为基础神经网络,将搜索区域xt(lt,ht)输入到基础神经网络中后得到搜索区域特征
8)将搜索区域特征xt输入到pfp神经网络中,对xt进行上采样得到特征
9)将
10)将特征xt、
11)经上述步骤得到的模板最终特征pz作为卷积核,在上述步骤得到的搜索区域最终特征px上进行卷积,得到pz和px的相关响应图,响应图中响应值最大点所在位置即为第t帧中跟踪目标的中心位置(xt,yt),并确定目标区域(lt,ht);
12)重复步骤6)至步骤11),至视频结束,完成对跟踪目标的中心位置以及目标区域的跟踪。
- 还没有人留言评论。精彩留言会获得点赞!