一种基于多判别器生成对抗网络的人脸图像修复方法与流程
本发明涉及计算机视觉与模式识别领域,特别涉及一种基于多判别器生成对抗网络的人脸图像修复方法。
背景技术:
随着科学技术的发展,手机、平板电脑及数码相机等电子设备得到了广泛普及。使用电子设备拍照成为了人们日常生活的普遍行为。同时伴随着移动互联网的发展,人们热衷于人脸照片相关的娱乐分享社交活动,而且对拍照得到的人脸图像的审美要求越来越高。现有的电子设备提供一系列的拍照功能,可以对人脸图像进行自动美化,拥有包括美白、祛痘、自动美妆等功能,但是缺乏人脸图像修复的相关功能。当针对一些存在脸部缺陷的用户,针对拍出来的人脸图像,无法有效地去除人脸图像的缺陷。同时,在探案侦查、考古和艺术等领域已损坏人脸图像也需要进行修复,成熟的人脸修复技术具有非常重要的意义与应用价值。
传统的人脸图像修复技术修复出来的图像纹理简单,并且需要缺陷部分的形状特定,这局限了人脸图像修复的应用场景。随着计算设备运算能力的提升和算法模型的发展,深度学习和生成模型在许多领域取得了丰厚的成果。虽然生成式对抗网络能对一些人脸图像进行修复,但是现有的技术很难稳定提供一个更加逼真、更加真实的人脸修复图像。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于多判别器生成对抗网络的人脸图像修复方法。
本发明的目的通过以下的技术方案实现:
一种基于多判别器生成对抗网络的人脸图像修复方法,包括以下步骤
步骤a:将公开的人脸图像数据库中的图像进行预处理,并输入到生成器中得到生成图像;
步骤b:真实图像和生成图像输入到判别器中得到反馈值;
步骤c:将判别器的反馈值作为对抗损失,同时结合感知损失和重建损失对生成对抗网络中的生成器和判别器进行对抗训练;
步骤d:将缺失的人脸图像输入到训练好的生成器中得到修复的人脸图像。
步骤a中,所述将公开的人脸图像数据库中的图像进行预处理,具体包括:
步骤a1:将人脸图像x裁剪成大小为n*n,n为正整数,然后使用dlib人脸特征点检测算法检测人脸图像中左眼、右眼、鼻子和嘴巴这4个区域的特征点,并计算均值得到4个区域的中心特征点位置,以4个区域中每个区域的中心特征点为中心截取4个大小为p*p的图像块,p为正整数;
步骤a2:随机生成大小为m*m的二进制掩码,m为正整数,m的值包括0和1,其中0表示图像中待修补区域,1表示图像中需要保留的区域,将二进制掩码与人脸图像相乘得到模型训练数据;
步骤a3:根据二进制掩码的位置信息将原图中缺失矩形图像块截取出来,然后把该图像块均分成k个大小为(m/k)*(m/k)的小图像块,其中k为正整数。
所述生成器采用类u-net网络结构,由编码网络与解码网络组成,构成一个u型结构。
所述编码网络由8个编码模块级联组成,其中每个编码模块由1个卷积层、1个批处理层和1个relu激活层按顺序级联而成。
所述解码网络由8个解码模块级联组成,其中每个解码模块由1个上采样层、1个拼接层、1个卷积层、1个批处理层、1个relu激活层按顺序级联而成。
所述判别器有d个,d为正整数,d=4+1+1+k,其中4个判别器作为人脸图像中左眼、右眼、鼻子和嘴巴这4个区域图像块的输入,确保人脸特定区域所生成出来的细节以及清晰度;1个判别器作为整张图像的输入,确保整体图像语义的一致性;1个判别器作为缺失矩形图像块的输入,确保缺失区域图像的语义一致性;k个判别器作为缺失矩形小图像块的输入,确保缺失区域生成出来的细节以及训练的稳定性。
所述判别器由5个卷积模块级联构成,其中每个卷积模块均由一个卷积核大小t×t的卷积层、1个批处理层和1个系数为0.2的leakyrelu激活层按顺序级联而成,t为正整数。
步骤c中,所述对抗损失的经验风险最小化项为
其中,
步骤c中,所述对抗网络使用的是wgan-gp算法,所述对抗损失的梯度惩罚项为
其中,
所述判别器的最小化目标函数为
其中,l(di)表示第i个判别器的最小化目标函数。
步骤c中,所述重建损失为
其中x为真实图像,
步骤c中,所述感知损失为
其中,x为真实图像,
所述深度学习网络模型为用imagenet数据集预训练的vgg16模型。
所述生成器的最小化目标函数为
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明提出一种基于多判别器生成对抗网络的人脸图像修复方法,使用了多个判别器,使网络在训练阶段收敛更加稳定,同时很好地约束生成模型对人脸图像细节的生成,使修复的人脸图像在人脸中眼镜、鼻子和嘴巴等特定区域上生成出更真实的细节和更协调的图像语义。
2、本发明引入多判别器的方法,使用模型时减小了整体网络模型的参数量和计算量,使该方法可以应用在更多的使用场景中。
3、本发明的方法采用程序化、步骤化的方式进行,加工成相关功能模块可以进行更为直接的利用和推广
附图说明
图1为本发明所述一种基于多判别器生成对抗网络的人脸图像修复方法的流程图。
图2是生成器网络结构图。
图3是生成器网络结构细节图。
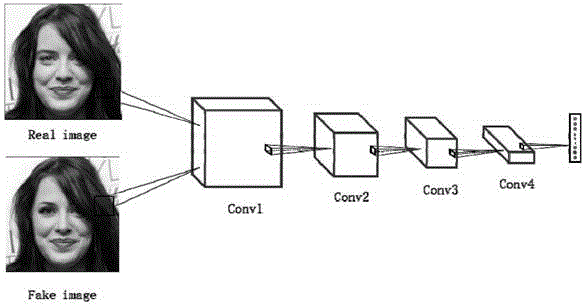
图4是判别器网络结构图。
图5是原始人脸图像、待修复图像和修复处理后的人脸图像的对比图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
如图1-5,一种基于多判别器生成对抗网络的人脸图像修复方法,包括步骤如下
步骤(a):将公开的人脸图像数据库中的图像进行预处理,并输入到生成器中得到生成图像;
步骤(b):真实图像和生成图像输入到多个判别器中得到反馈值;
步骤(c):将多个判别器的反馈值作为对抗损失,同时结合感知损失和重建损失对生成对抗网络中的生成器和判别器进行对抗训练;
步骤d:将缺失的人脸图像输入到训练好的生成器中得到修复的人脸图像。
上述步骤(a)中图像预处理步骤包括:
步骤(a1):将人脸图像x裁剪成大小为256*256,然后使用dlib人脸特征点检测算法检测人脸图像中左眼、右眼、鼻子和嘴巴这4个区域的特征点,并计算均值得到4个区域的中心特征点位置,以4个区域中每个区域的中心特征点为中心截取4个大小为32*32的图像块;
步骤(a2):随机生成大小为128*128的二进制掩码,值包括0和1,其中0表示图像中待修补区域,1表示图像中需要保留的区域,将二进制掩码与人脸图像相乘得到模型训练数据;
步骤(a3):根据二进制掩码的位置信息将原图中缺失矩形图像块截取出来,然后把该图像块均分成4个大小为32*32的小图像块,其中k为正整数。
步骤(a)中所述生成器为类u-net网络结构,由编码网络与解码网络组成,构成一个u型结构。其中编码网络8个编码模块级联组成,其中每个编码模块由1个卷积层、1个批处理层和1个relu激活层构成。解码网络8个解码模块级联组成,其中每个解码模块由1个上采样层、1个拼接层、1个卷积层、1个批处理层还有1个relu激活层构成。
步骤(b)中所述判别器有10个,其中4个判别器作为人脸图像中左眼、右眼、鼻子和嘴巴这4个区域图像块的输入,确保人脸特定区域所生成出来的细节以及清晰度;1个判别器作为整张图像的输入,确保整体图像语义的一致性;1个判别器作为缺失矩形图像块的输入,确保缺失区域图像的语义一致性;4个判别器作为缺失矩形小图像块的输入,确保缺失区域生成出来的细节以及训练的稳定性。
上述判别器由5个卷积模块级联构成,其中所有卷积模块由一个卷积核大小4*4的卷积层、1个批处理层和1个系数为0.2的leakyrelu激活层构成。
步骤c中对抗损失的经验风险最小化项为
其中,
步骤c所述对抗网络训练使用的是wgan-gp算法,对抗损失中梯度惩罚项为
其中,
步骤c中,判别器的最小化目标函数为
其中,l(di)表示第i个判别器的最小化目标函数。
步骤c中所述重建损失为,
其中x为真实图像,
步骤c中感知损失为
其中,x为真实图像,
结合以上,则上述步骤c中,生成器的最小化目标函数为
上述深度学习网络模型为用imagenet数据集预训练的vgg16模型。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!