基于多尺度残差密集网络夜间图像增强方法与流程
本发明涉及计算机视觉和深度学习领域。
背景技术:
伴随着摄影设备拍摄能力的不断提高,人们拍摄的相片、视频的质量都得到了明显的提高。但是,人们在夜间拍照时由于低信噪比与光照强度太低的影响,仍旧会存在很多让人不满意的情况,尤其是使用手机或者较差的设备,在光线极差的环境中拍摄照片时,设备的成像质量时常让我们感到失望。同时,监控设备在夜间经常难以表现出优良的性能,尤其是处于室外、光照环境极差的环境中时。目前大部分的解决方法都是在硬件上的改进,但是这类设备一般都价格比较昂贵并且携带极其不方便。因此,研究夜晚图像增强是十分有意义的,这可以大大降低许多监控设备的成本,提高设备的性能,尤其是提高手机的夜间成像能力。
目前,大部分的夜间图像增强都采用传统的方法,例如使用直方图均衡、帧间融合、retinex等方法。这些方法在许多方面都取得了不错的效果。但是仍然存在不足,例如:对于增强的图像会引入很多的噪点、对图像的还原不够真实、图像细节丢失严重等问题。
随着深度学习快速发展,越来越多的计算机视觉任务都得到很好的解决。但是在低光照下的夜间成像依旧是一个十分难以解决的难题。
技术实现要素:
本发明所要解决的技术问题是:如何解决在光照环境差或极差环境中,增强相机的成像能力,使其可以成像出逼真的图片。
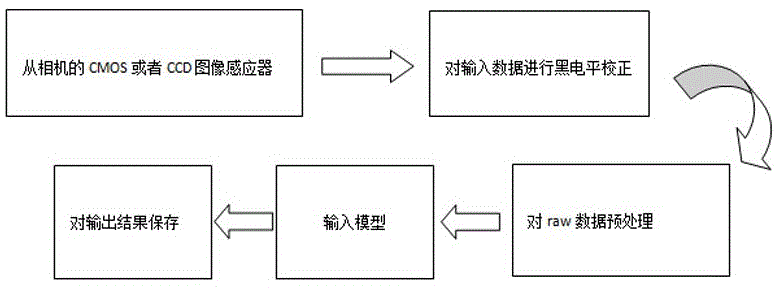
本发明所采用的技术方案是:基于多尺度残差密集网络夜间图像增强方法(multi-scaleresidualdensenetwork(mrdn)),按照如下的步骤进行步骤s1,从sony相机(或其它任意相机,本专利采用的为sony相机进行数据捕捉)的cmos或者ccd图像感应器捕捉到的光源信号转化为数字信号获得raw格式的原始数据,对采集到的原始数据进行黑电平校正,消除暗电流造成的成像干扰,并将像素值归一化到[0,1]之间;
步骤s2,将经过黑电平校正后的raw格式的数据进行预处理,raw格式数据中,奇数行为rgrg,偶数行为gbgb,将raw格式数据中的r,g,b像素分别取出,将数据格式转化为四通道的格式;
步骤s3,将经过预处理后数据输入mrdn模型;
步骤s4,将mrdn模型的输出结果经过处理后保存为图像进行输出。
作为一种优选方式:所述mrdn模型包括卷积下采样层、反卷积上采样层、多尺度残差密集卷积块;卷积下采样层使用五层卷积块(包含两层卷积层,具有相同大小的卷积核)和四层池化层,实现对信号特征的提取,降低信号纬度,减小网络计算量;反卷积上采样层使用四层反卷积,实现对降纬度后的数据恢复成原始纬度的信号;多尺度残差密集卷积块通过残差密集卷积网络使数据加上多尺度的信息,使得mrdn模型可以对输入的数据进行更加高效的利用;mrdn模型损失函数
本发明的有益效果是:本发明采用基于深度学习方法的mrdn模型(多尺度残差密集网络模型(multi-scaleresidual-densenetwork))深度学习方法,通过对拍摄图像的重建,使得相机的成像更加清晰明亮。可以将在夜间或者极端光照的条件下拍摄的照片,通过本专利算法重建为清晰明亮的照片。夜间成像一直以来都是一项难以解决的问题,由于低信噪比、复杂的图像内容、拍摄场景多样性等问题的影响,使得在夜间拍摄的图像会出现照片不清晰、图像过暗甚至完全看不清的问题。推动夜间成像技术的发展,具有极其重要的意义,不但可以提高监控设备在夜间拍摄质量、提升手机夜间成像能力,同时还能降低拍摄设备的成本。但是目前存在的技术都存在一定的缺陷,本文提出了一种全新的多尺度级联式残差密集神经网络,以便生成更加鲁棒的图像。
附图说明
图1为本发明实施例提供的流程图;
图2为数据预处理示意图;
图3为本发明实施例提供的整体结构图;
图4为本发明实施例提供的卷积下采样层的细节结构图;
图5为本发明实施例提供的多尺度残差密集网络的细节结构图;
图6为本发明实施例提供的残差密集网络的细节结构图。
具体实施方式
如附图1所示,基于多尺度残差密集网络夜间图像增强方法包括以下步骤:
步骤s1,从sony相机(或其它任意相机,本专利采用的为sony相机进行数据捕捉)的cmos或者ccd图像感应器捕捉到的光源信号转化为数字信号获得raw格式的原始数据,对采集到的原始数据进行黑电平校正,消除暗电流造成的成像干扰,并将像素值归一化到[0,1]之间;
步骤s2,将经过黑电平校正后的raw格式的数据进行预处理,raw格式数据中,奇数行为rgrg,偶数行为gbgb,将raw格式数据中的r,g,b像素分别取出,将数据格式转化为四通道的格式;
步骤s3,将经过预处理后数据输入mrdn模型;
黑电平校正包括以下步骤:
暗电流指传感器在没有入射光的情况下,存在一定的信号输出,这是由于半导体的热运动造成的,它的大小和传感器结构及温度有关,因此我们首先需要进行黑电平校正,同时将像素值归一化到[0,1]之间。进一步地,定义输入的低光照图片为iraw,也就是通过相机采集到的数据,这里对黑电平进行校正的公式如下:
raw=max(iraw-512)/(16383-512)
进一步地,本专利采用的是sony相机,不同的相机对数据的编码方式不同,因此对数据预处理和黑电平校正的方式会不同,需根据使用的相机具体操作。同时,黑电平校正已经是比较成熟的技术了,所以本专利不做重复说明。
如附图2所示,步骤s2对raw数据的预处理为:
raw数据的格式为:奇数行为rgrg,偶数行为gbgb,在训练模型时首先将数据进行变换,将raw数据的r,g,b像素分别取出,将数据格式转化为四通道的格式,此时数据的长为原来的1/2,宽为原来的1/2。如图2示例,输入的4×4的raw数据,数据的分布为图2所示,第一行为r(红色)、g(绿色)、r(红色)、g(绿色),第二、三、四行同理(其中rgb分别代表红色,绿色,蓝色),仅仅是数据不同,通道数为1,在进行转换时,首先将第一行与第三行的r全部取出,构成2×2的一个矩阵,矩阵的内容全部为r,这样构成新数据的第一个通道;将第二行与第四行的g数据全部取出,构成2×2的矩阵,构成新数据的第二个通道;将第一行与第三行的b数据全部取出,构成2×2的矩阵,构成新数据的第三个通道;将第一行与第三行的g数据全部取出,构成2×2的矩阵,构成新数据的第四个通道,将这四个通道构成一个2×2×4的新矩阵输入进模型中,也就是iraw数据。
如附图3所示,本专利的mrdn模型为:
mrdn模型,主要包括三部分,卷积下采样层(convolutionsamplingnet(csnet)),反卷积上采样层(deconvolutionup-samplingnet(dupnet)),多尺度残差密集卷积块(multiscaleresidualdenseconvolutionblock(mrdb))。
进一步地,如图4所示,本专利的csnet网络,网络的第一层接受输入的原始数据iraw,随后是一个池化层进行降维操作,作用是减少网络的计算量,紧随其后的卷积块和池化层的操作与作用和之前的相同。在这里,csnet网络使用的卷积层的大小均为3×3的,步长为1。
进一步地,本专利采用的dupnet网络的作用是将经过池化层降维后的数据还原为原来的大小,采用的方法是反卷积,一共有四层dupnet层,每一层于之前的池化层相对应,例如,原图的大小为1024×1024大小,经过一层池化层后,降为512×512,在经过一层后大小为256×256,以此类推,经过四层后的图像大小为64×64,所以在输出阶段,需要将图像大小恢复为1024×1024,如图示3所示,经过一次dupnet网络后,图像的大小扩大一倍,例如,输入为64×64,输出为128×128。
进一步地,如图5所示,本专利定义的多尺度残差密集卷积块((multiscaleresidualdenseconvolutionblocks(mrdb))的结构为,mrdb包含三个残差密集卷积网络(residualdenseconvolutionnetwork(rdn)),rdn1的结构为,输入为前一层dupnet的输出,在之后为一个卷积层,然后为多个残差密集卷积块(residualdenseconvolutionblocks(rdb))的结构如图6所示,在rdb的最后,对所有的rdb层进行concat操作。本专利中,rdn1使用的均为1×1的卷积,rdn2和rdn3采用的为3×3和5×5的结构,除了卷积的大小不同外,其余结构完全一致。
进一步地,如图6所示,残差密集卷积块(residualdenseconvolutionblocks(rdb))和传统卷积网络的不同在于,传统的卷积网络在每一个卷积层之后直接连接下一个卷积层,这一层获得的特征不能够实现跨层传递,这样难以对卷积特征充分的利用,而残差密集卷积块这样的结构,将任意的卷积网络都与后面的卷积网络相连接,这样可以使卷积网络获得的特征进行充分利用,大大提升网络性能。
进一步地,定义输入的低光照图片为iraw,增强后的图片为ig,增强后的图片即为模型最后的输出图片。第一个卷积层直接从raw数据中提取特征,这里定义hcsnet(·)定义为卷积下采样操作,ck为hcsnet(·)操作第k层操作的结果,如式2所示,c1为hcsnet(·)操作第一层(模型的第一个卷积层)得到的结果。
c1=hcsnet(iraw)(1)
ck=hcsnet(ck-1)(2)
进一步地,反卷积上采样的过程定义为hdupnet(·),hdupnet(·)第一层的操作如公式3,cend为hcsnet(·)最后一层的输出。第d层hdupnet(·)的输出结果为dd,d1为hdupnet(·)第一层操作得到的结果。gd-1代表hmrdb(·)第d-1层的输出,hmrdb(·)为多尺度残差密集块操作,计算过程如公式5所示。
d2=hdupnet(cend)(3)
dd=hdupnet(gd-1)(4)
gd=hmrdb(dd-1)(5)
进一步地,在整个模型的计算过程中,一共有d层hdupnet(·)和hmrdb(·)操作,整个网络的输出可以定义为公式6。
ig=hmrdb,d(hdupnet,d(hmrdb,d-1(...(hcsnet,1(iraw)))))(6)
进一步地,在损失函数上,本专利使用l1损失,目标为求出使损失最小的参数,如下所示:
这里θ为模型需要通过学习更新的参数,本专利的目标为,通过更新参数,使得l1损失最小,θ*表示更新后得到的最有参数。
为了验证本发明的效果,进行了多方位实验:
实验平台:gpu:nvidiadgx-1,8个teslap100gpu加速器,每颗gpu16gb内存;
编程软件:pycharm;
编程语言:python3.5。
- 还没有人留言评论。精彩留言会获得点赞!