一种基于大数据的短视频活跃用户预测方法与流程
本发明属于深度学习、大数据处理技术领域,尤其基于余弦退火快照的lstm模型短视频活跃用户预测。
背景技术:
近年来,传播形态走向立体化,短视频日益受重视。短视频作为一种依托社交平台传播、能够拉近线上与线下空间、内容愈发垂直细分的传播形态,无疑受到了互联网巨头以及各家媒体的关注。2013年,instagram短视频功能上线,上线首日视频上传量达到500万条。早在2014年前后,facebook已将视频作为信息流中优先展示的内容。2015年,公司首席执行官马克·扎克伯格表示其用于日均观看视频数量已达30亿个用户。该公司运营主管尼古拉·门德尔松曾在2016年公开表示,“讲故事的最好方式其实是视频,这种内容形式为我们提供了大量的信息。”2017年至今,国内已经涌现大量优秀的短视频app,累计用户量以达5亿,日活跃用户数超过6000万,用户日均使用时长超过50分钟,为此我们可获得大量有价值的数据。
短视频平台竞争激烈,盈利模式有待发掘。随着平台对短视频创作者的补贴逐渐收拢,依靠平台红利支撑短视频的内容运营并非长久之计。二更视频创始人丁丰曾公开表示,未来定制化短视频广告的市场可达千亿级别,但定制化广告内容需要制作团队本身有过硬的技术与传播影响力。头部视频创作者之外,更多的短视频生产者仍旧需要探寻稳定长久的盈利模式,持续生产“爆款”、靠引人眼球吸引流量,或通过个人化标签将视频平台打造成ip的模式,并非适用于所有类型的视频制作团队。
随着人工智能和大数据等技术不断渗透,依靠短视频app主动收集、分析、整理各类用户数据,为短视频app细分这部分活跃人群提供更为精准的个性化推送服务,成为解决短视频app寻找潜在用户问题的有效途径。简言之,如何区别活跃用户,成为短视频app领域提供更为精准的个性化推送服务的关键。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种旨在对当月注册用户在未来一周是否会使用该短视频app进行预测,进而为短视频领域寻找活跃用户提供更为精准的个性化推送服务,解决短视频app寻找潜在用户问题的方法。本发明的技术方案如下:
一种基于大数据的短视频活跃用户预测方法,其包括以下步骤:
101、对用户的历史行为数据进行包括“僵尸”用户处理步骤、用户注册设备处理步骤在内的预处理操作;
102、根据注册时间将用户划分成训练集候选用户和测试集候选用户;
103、将训练集候选用户和测试集候选用户的历史行为转化为时序序列,再将时序序列根据时间划窗划分为训练集和测试集;
104、对作为训练集的时序序列进行打标;
105、通过时序序列建立many-to-many多输入对多输出结构的lstm长短期记忆网络模型;many-to-many多输入对多输出结构即每个输入都对应输出之后7天是否活跃;
106、根据用户历史行为时间序列,采用lstm长短期记忆网络模型对当月注册用户在未来一周是否会使用相应短视频app进行预测。
进一步的,所述步骤101对用户的历史行为数据预处理操作具体步骤为:
1011.“僵尸”用户处理步骤:针对数据中存在的“僵尸”注册用户,也就是在历史数据中除了注册当天出现过,未来再也没有出现过的用户,采取将其从活跃用户候选集中过滤掉,不参与训练以及预测,直接将这些用户标作非活跃用户的策略;
1012.用户注册设备处理步骤:对用户注册设备采用平均值编码方法进行编码,在贝叶斯的架构下,利用所要预测的应变量,有监督地确定最适合这个定性特征的编码方式。
进一步的,所述平均值编码方法具体包括:将用户注册设备处理中的每一个设备类别k,都表示为它所对应的目标y值的先验概率与后验概率的一个凸组合,引入先验概率的权重λ来计算编码所用概率
其中n为一个设备类型出现的次数,k为设备类型,prior为用户使用该短视频app的概率即先验概率、posterior为用户注册账号所使用的设备类型为k时,使用该短视频app的概率即后验概率,device_type为用户注册时所使用的设备类型、y表示用户未来7天是否使用该短视频app,1表示使用,0表示未使用。
进一步的,所述步骤102根据注册时间将用户划分成训练集候选用户和测试集候选用户具体步骤为:
采取滑窗法划分训练集候选用户和测试集候选用户,基于30天的用户行为数据,将数据中前23天的注册用户作为训练集候选用户,将数据中后7天作为训练集的标签区间,判断数据前23天注册用户是否活跃区间,将数据30天所有的注册用户作为测试集候选用户。
进一步的,所述步骤103将训练集候选用户和测试集候选用户根据历史行为转化为时序序列,作为训练集和测试集的具体步骤为:
根据对用户历史行为数据的分析,以天为单位对训练集候选用户和测试集候选用户进行特征工程构建,所述对特征工程进行构建是指对用户历史行为数据构建register相关特征、launch相关特征、video相关特征、activity特征、date特征、device_type特征,从而将训练集候选用户和测试集候选用户的历史行为转换成以天为单位的时序序列;
1031.register相关特征:当天是否为第一天注册
1032.launch相关特征:当天是否登录;
1033.video相关特征:当天创建短视频的次数;
1034.activity特征:当天播放、关注、点赞、转发、举报、减少此类短视频的行为次数,当天在关注页、个人主页、发现页、同城页、其他页的行为次数,当天观看短视频总数,当天观看除自己所短拍摄之外的短视频总数,当天观看自己短视频的次数;
1035.date特征:是否为周末,是否为三天小长假,是否为七天长假;
1036.device_type特征:device_type的平均编码值。
进一步的,考虑到训练集和测试集的序列长度一致性,取序列长度为23才能保证时序序列长度一致性,训练集的时序序列是基于数据中第1天到第23天每天的用户行为产生的,测试集的时序序列是基于数据中第8天到第30天每天的用户行为产生的。
进一步的,所述步骤104对处理好的时序序列进行打标,具体步骤为:
对时间序列的每一天进行打标:考虑lstm模型的many-to-many结构,即每个输入都对应一个输出——之后7天是否对该短视频app进行交互,若交互,则打标为1,反之,打标为0;考虑到训练集和测试集的序列输出一致性,由于测试集中第24天到第29天,所对应的之后7天是否对该短视频app进行交互的信息,都包含了31到37天的标签信息,即24天到第29天的输出是不完整的,而数据集中第30天的输出即用户在31到37天对该app的交互情况是要预测的结果,因此测试集不考虑24天到30天时序序列所对应的输出,同样将训练集中第17天至第22天的时序序列中每天所对应的输出设置为空值。
进一步的,所述步骤105通过时序序列建立many-to-many结构的lstm模型,具体步骤为:
1051.输入序列:对各类行为序列直接输入;
1052.intercept截距拼接:在输出层直接做一个intercept拼接,将日期、device_type、register_type进行one-hot后输入;
1053.batch数据块选择:随机采样一定样本作为一个batch数据块;
1054.循环三角退火快照:通过循环调整网络学习率使网络依次收敛到不同的局部最优解处,将网络学习率η设置为随模型迭代轮数t改变的函数,即:
其中,η0为初始学习率,t为模型迭代轮数,t为模型中的批处理训练次数,m为学习率“循环退火”次数,其对应了模型将收敛到的局部最优解个数,公式(2)利用余弦函数的循环性来循环更新网络学习率,将学习率从0.1随t的增长逐渐减缓到0,之后将学习率重新放大从而跳出该局部最优解,自此开始下一循环的训练,此循环结束后可收敛到新的局部最优解处,如此循环往复,直到10个循环结束,因为公式(2)中利用正弦函数和余弦函数循环更新网络参数,所以这一过程被称为“循环三角退火”过程;
1055.权值临界集成:采用权值临界集成策略,权值临界集成的工作原理分为两个步骤:
(1)首先,给最终集成模型的权值赋值7个模型“快照”的权值的平均值:
其中ωi为第i个模型“快照”的权值,即在权重空间而不是模型空间对这些点进行平均;
(2)在每个学习率周期的末尾,使用当前模型“快照”的权值将用来更新最终集成模型的权值,更新公式如下式所示:
其中nmodels为模型“快照”的序数,ωi为第i个模型“快照”的权值。
进一步的,所述步骤106根据当月用户历史行为时间序列,对用户在未来一周是否会使用相应短视频app进行预测,具体步骤为:
根据lstm模型,构建的框架主要实现基于循环余弦退火快照的集成框架,其核心思想为:(1)学习率采用循环三角学习率退火使得lstm模型产生多个模型“快照”;(2)通过不同阶段的模型所产生的模型“快照”采用权值临界集成策略进行集成,最终得到的用户活跃概率:
其中t为时间序列长度,x(t)为模型的第t次输入,h为隐层单元,而u,v,w,p为权值空间ωswa中的权值,prob为最终得到的用户活跃概率,当prob大于0.56的时候,说明该条测试数据对应的用户很大可能是活跃用户,会在规定时间内使用该短视频app。
本发明的优点及有益效果如下:
本发明创新点:
1、将平均值编码在预测短视频活跃用户这个一应用中进行改进,先验概率和后验概率的系数改进,由于预测短视频活跃用户这个一应用会出现大量的新的设备,所以我将系数与前段时间所出现的设备种类数与系数增添了关系,使得编码结果与新设备出现的频率有关,在神经网络中是一个十分强的特征,大大提高最终结果的效果。
2、根据预测短视频活跃用户这个一应用,将lstm(长短期记忆网络)改进为many-to-many(多输入对多输出)结构,也就是多个时间序列的输入对应一个输出,many-to-one(多输入对单输出)的结构为了充分利用数据,需要对训练数据做大量的滑窗,以实现数据增广,计算成本高。另外,每个序列只有一个标签,梯度难以传导,导致训练困难,相反的,我们可以考虑many-to-many(多输入对多输出)结构,即每个输入都对应输出之后7天是否活跃,充分利用监督信息,减轻梯度传到负担,使训练更加容易。
3、1054中新颖的循环三角退火快照:常规的退火快照的学习率都是采用的余弦函数,但是对于此应用来说,余弦函数的周期太小,导致优化方法每次还没达到最小值时就跳出最优值附近了,所以采用了正弦函数和余弦函数的结合,提高学习率函数的周期,从而提高了函数本身的优化的稳定性,使更快的收敛到最优值。
4、1055的(2)中,常规的随机加权集成公式为
本专利中采用的
区别在于对于最终结果在不同的快照模型中,离中心值更近,还是离边缘值更近,由于本专利采用的是循环三角退火快照,每一个快照模型本身就接近于最优值,使得最终结果收敛于更为边缘的结果,会使得模型获得更为宽泛的优化。
附图说明
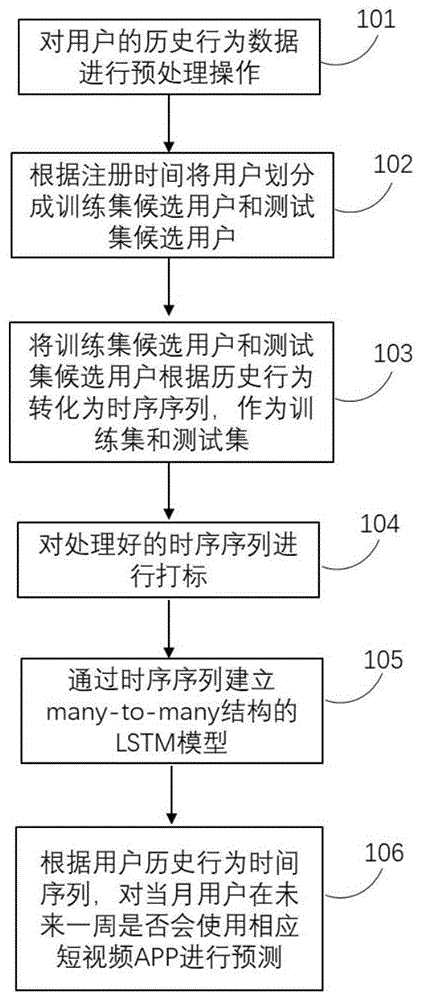
图1是本发明提供优选实施例一种基于大数据的短视频活跃用户预测方法的流程图。
图2为本发明实施例提供的一种基于大数据的短视频活跃用户预测方法中注册用户数量和注册时间的关系变化图。
图3为本发明实施例提供的一种基于大数据的短视频活跃用户预测方法中平均值编码的时间划分图。
图4为本发明实施例提供的一种基于大数据的短视频活跃用户预测方法中lstm中的时间序列的一种结构:many-to-many。
图5为本发明实施例提供的一种基于大数据的短视频活跃用户预测方法中模型lstm的整体框架。
图6为本发明实施例提供的一种基于大数据的短视频活跃用户预测方法中优化算法的学习率变化图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
参考图1,图1为本发明实施例一提供一种基于大数据的短视频活跃用户预测方法的流程图,具体包括:
101.对用户的历史行为数据预处理操作,具体如下:1011.“僵尸”用户处理:数据中存在着许多僵尸用户,数据集中第24天的注册用户尤为突出(见图2),针对数据中存在的“僵尸”注册用户采取将其从活跃用户候选集中过滤掉,不参与训练以及预测,直接将这些用户标作非活跃用户的策略;1012.用户注册设备处理:我们对设备进行平均数编码,即将用户注册设备处理中的每一个设备类别k,都表示为它所对应的目标y值概率,最终编码所使用的概率估算,应当是先验概率与后验概率的一个凸组合,如公式(1)所示,由于平均数编码涉及到标签信息,为了避免数据穿越,所以我们需要对数据集进行划分,才能得以实现平均值编码,划分方式如图3所示。
102.根据注册时间将用户划分成训练集候选用户和测试集候选用户,具体如下:采取滑窗法划分训练集候选用户和测试集候选用户,其中,将数据中第1天至第23天的注册用户作为训练集候选用户,将数据中第1天至第30天的注册用户作为测试集候选用户。
103.根据对用户历史行为数据的分析,以天为单位对训练集候选用户和测试集候选用户进行特征工程构建,所述对特征工程进行构建是指对用户历史行为数据构建launch相关特征、video相关特征、activity特征、date特征、device_type特征,如下:
1031.register相关特征:当天是否为第一天注册
1032.launch相关特征:当天是否登录;
1033.video相关特征:当天创建短视频的次数;
1034.activity特征:当天播放、关注、点赞、转发、举报、减少此类短视频的行为次数,当天在关注页、个人主页、发现页、同城页、其他页的行为次数,当天观看短视频总数(去重),当天观看除自己所短拍摄之外的短视频总数(去重),当天观看自己短视频的次数;
1035.date特征:是否为周末,是否为三天小长假;是否为七天小长假;
1036.device_type特征:device_type的平均编码值。
104.对处理好的时序序列进行打标,具体如下:我们使用lstm模型中的many-to-many结构(见图4),即每个输入都对应一个输出——之后7天是否对该短视频app进行交互,若交互,则打标为1,反之,打标为0。
105.通过时序序列建立many-to-many结构的lstm模型,具体如下:
1051.输入序列:lstm无需对输入序列做过多处理,对各类行为序列直接输入即可。
1052.intercept:另外,在输出层直接做一个intercept拼接,将日期、device_type、register_type进行one-hot后输入。(lstm模型的具体框架如图5所示)
1053.batch选择:随机采样一定样本作为一个batch,能将数据充分打散,使得模型泛化能力更强,下降方向更加准确。
1054.循环三角退火快照:网络“快照”集成法利用了网络解空间中的这些局部最优解来对单个网络做模型集成。通过循环调整网络学习率可使网络依次收敛到不同的局部最优解处,具体而言,公式(2)是将网络学习率η设置为随模型迭代轮数t改变的函数,学习率的变化趋势如图6所示,可以从图中看出利用正弦函数和余弦函数的循环性来循环更新网络学习率,将学习率从0.1随t的增长逐渐减缓到0,之后将学习率重新放大从而跳出该局部最优解,自此开始下一循环的训练,此循环结束后可收敛到新的局部最优解处,如此循环往复,直到10个循环结束。测试阶段在做模型集成时,由于深度网络模型在初始训练阶段未必拥有较优性能,因此挑选最后7个模型“快照”用于集成。
1055.权值临界集成策略:上述模型“快照”的集成策略我们采用随权值临界集成策略。权值临界集成的工作原理分为两个步骤:
(1)给最终集成模型的权值赋值7个模型快照权值的平均值,即在权重空间而不是模型空间对这些点进行平均,赋值方式为公式(3)。
(2)在每个学习率周期的末尾,使用当前模型“快照”的权值将用来更新最终集成模型的权值,更新公式为公式(4)。
106.根据当月用户历史行为时间序列,对用户在未来一周是否会使用相应短视频app进行预测,具体如下:
构建的框架主要实现基于循环三角退火快照的lstm集成框架,其核心思想为:(1)学习率采用循环三角学习率退火使得lstm模型产生多个模型“快照”。(2)通过不同阶段的模型所产生的模型“快照”采用临界权值平均策略进行集成。最终得到的用户活跃概率prob,概率prob的计算公式(5)所示。当prob大于一定值(0.56)的时候,说明该条测试数据对应的用户很大可能是活跃用户,会在规定时间内使用该短视频app,为短视频app细分这部分活跃人群提供更为精准的个性化推送服务,成为解决短视频app潜在用户问题的有效途径。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!