一种基于深度强化学习的文本语义相似计算模型的制作方法
本发明涉及文本语义相似计算方法
技术领域:
,具体涉及一种基于深度强化学习的文本语义相似计算方法。
背景技术:
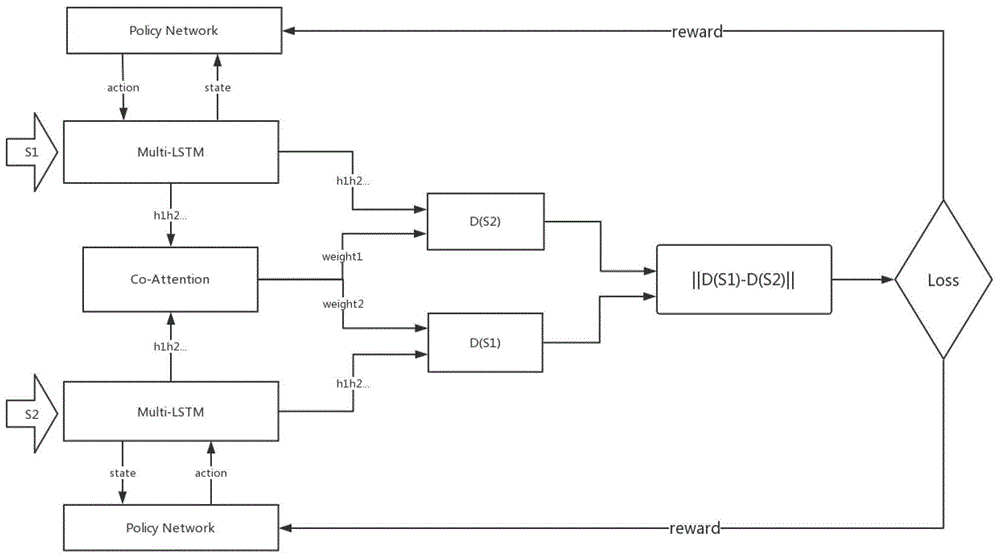
:随着人工智能技术的发展,深度学习在计算机视觉领域取得了很多突破进展,使得人们开始将这一技术慢慢应用于各个领域,自然语言处理领域是深度学习下一个攻克的对象,语义相似研究是自然语言处理领域的最基础的问题之一,也一直是一个难题。语义相似计算在很多的自然语言处理领域都有应用,比如在各种问答系统当中,用户在网上提出问题后,会有网友去回答这些问题,之后系统将问题和答案放入问答库当中,日后再有人提出问题,就可以根据提出的问题和问答库当中的问题进行语义的相似度计算,然后排序返回问题对应的答案给用户。再比如在新闻推荐领域同样会应用语义计算模型,用户点击新闻标题后,后台可以计算该新闻和新闻库当中新闻标题的相似性,以此推荐相关新闻给用户。随着互联网的发展,网上的信息呈井喷式的增长,在新闻网站或者社交平台等信息日益增多,在检索的过程中句子相似度计算可以提高检索效率。在信息抽取中,从文档中筛选实体过程也要用到语义相似计算。语义相似计算一直都是自然语言处理领域的一个最基本问题,它是机器进行语义理解的一种手段,机器可以通过相似类比从而能间接的理解语言,相比于传统的基于统计的语义相似计算模型,基于机器学习和深度学习的语义相似计算模型能更加细致的表达句子的语义特征和结构特征,比如词向量技术、lstm模型、cnn模型,然而随着技术不断的应用,这些语义特征模型存在很多问题被人诟病。比如长短时记忆模型虽然是专门用来处理时序模型的,但是它在处理比较长的句子过程中仍然会因为反向传播算法而带来的梯度消失问题,从而丧失很多语义信息,尤其是句子靠前部分的语义信息,因为在反向更新的过程中,梯度很难传到靠近前面词语的位置。而用cnn来卷积句子的时候,仍然难以表达句子中间隔较远的词之间的关系,需要多层的卷积或者更大的卷积核,这也增加了计算开销,此外池化层会使得在提取语义信息时语义丢失严重,这种现象同样存在于图像领域。因此探索一种更加好的方式来计算句子语义信息就更为重要。同时研究语义相似模型有助于自然语言处理各个领域场景的使用。专利201610986272.2“多粒度短文本语义相似度比较方法及系统”中,发明了一种多粒度短文本的语义相似比较方法,通过对文本的分词处理,然后基于分词后进行短文本的一些特征构建,比如对任意一个汉字分为词头、词中、词尾,单字状态,然后对短文本进行特征选择后,将选择出来的特征进行构建向量,然后计算向量距离来表示文本的相似性。该方法是一种基于传统的统计方法来处理文本相似性问题的,tf-idf方法和知网等传统方法一样,这种方法是一种粗粒度的统计,一般只能给一个词赋予权重,既不能很好的量化表达词语的意义,也会丢失句子的结构信息。专利201711309921.6“一种基于卷积神经网络的中文文档自动问答系统”是一种语义计算的深度学习模型,主要是采用长短时记忆模型来解决句子的长期依赖,然后使用卷积神经网络来进行语义特征提取,并且提出了新的注意力加权方式来对不同长度的上下文进行语义加权,在问答系统中获得很好的效果。然而这种方式仍然会存在着问题,如果先是通过长短时记忆模型来提取语义后,再用卷积网络来卷积,之后用加权模型来加权卷积后的特征,那么在使用长短时记忆模型处理比较长的句子的时候仍然可能遇到提取语义信息不充分的问题。技术实现要素:本发明的目的在于克服现有技术不足,提供一种基于深度强化学习的文本语义相似计算方法。这种基于深度强化学习的文本语义相似计算模型,包括句子蒸馏网络模型、句子划分网络模型和相互加权模型;整体结构是一个强化学习模型,组成有两部分:最外围的policynetwork网络是句子划分网络模型和句子蒸馏网络模块,该网络使用多层深度神经网络模型,是一个actor网络功能模块,功能是接受multi-lstm模型的内部状态,然后计算给出一个动作返回给multi-lstm模型;内层的整体架构是一个siameselstm模型,是一个critic网络模块,输入部分仍然是将词向量作为每个时刻的输入,该模型曼哈顿距离来衡量句子语义相似程度;使用相互加权模型来增强语义;multi-lstm使用了两层的长短时记忆模型叠加,将第二层输出的隐藏层语义向量输出到co-attention模型当中进行加权操作,生成每个时刻的加权重weight后,再与隐藏层的输出h进行运算生成最终的语义向量d(s);最终将提取的语义向量用曼哈顿的距离来表示相似度||d(s1)-d(s2)||;actor网络部分和critic网络部分分别训练,内部的环境模型通过backpropagation(bp)算法来更新,外部的policynetwork根据环境的损失值使用policygradient算法来更新。作为优选:所述句子蒸馏网络模型是由蒸馏网络模块和multi-lstm网络模块组成,multi-lstm用于句子的语义抽取;policynetwork模型就是actor网络,multi-lstm模型包含两层的长短时记忆模型;蒸馏网络,{w1,w2,w3...wt...we}表示每个时刻输入到长短时记忆模型的词向量,{s1,s2,s3...st...se}代表模型内每个时刻的状态,初始时刻将长短时记忆模型内节点初始化为0,{h1,h2,h3...ht...he}表示每个时刻长短时记忆模型的隐藏层输出,{a1,a2,at-1...an}表示每个时刻policynetwork的输出动作值,当词向量输入到lstm模型当中的时候,先将长短时记忆模型节点当前的状态和隐藏层的输出以及词向量合并成状态st:传入policy网络当中进行动作的输出记作at,语义提取总的结构有两层长短时记忆模型,生成状态st后,将状态传入句子蒸馏网络判断当前传入的词根据当前上下文是否应该被蒸馏出去,如果判断应该保留该词就将词向量传入第一层的长短时记忆模型当中进行语义的计算,如果模型判断不应该保留则跳过当前词;通过句子蒸馏网络可以将一个长句子当中的非关键词去除掉,从而保留了句子的核心的词语,使得长短时记忆模型对句子中的每个关键的词都能学习到;所述句子划分网络模型和句子蒸馏网络模型结构部分相同,区别是:policynetwork网络输出的动作是重置长短时记忆模型的状态;动作输出有两种状态分别表示是否重置长短时记忆模型的状态,当actor网络输出要重置状态时,在下个单词输入之前要将长短时记忆模型内部细胞状态重置;当输出动作不需要重置细胞状态时,就按照正常的模型来输出处理;当一段句子被截断后,该时间戳的句子最后一个时刻输出的隐藏层状态作为被截断句子的语义表达保存下来作为下一层模型的输入;当一个句子被划分成n段后,就会产生n个截断语句的输出,将这n个截断语句输出到下一层的lstm进行拼接,从而形成了句子整体的语义信息。作为优选:相互加权模型是一种软的加权方式;将第二层的{h1...ht...he}隐藏层输出状态传入加权模型当中进行加权;其中h1和h2表示lstm的长短时记忆模型第二层隐藏层输出拼接成的语义矩阵,ws是一个形状为l*l的二维加权矩阵,h1是一个l*n的二维矩阵,h2是一个l*m形状的二维矩阵,进行如下的矩阵操作运算:经过运算可以获得一个n*m的权重矩阵,然后将每行的参数相加和每列的参数相加,然后经过softmax函数进行归一化后,可以获得h1语义矩阵和h2语义矩阵的每个时刻分别对应的语义权重向量,最后将各自的权重向量和语义矩阵相乘可以获取最后的句子的语义向量;单个的加权矩阵往往会加权语句中的某一个方面,使用多个加权矩阵来对lstm每个时刻输出的语义进行加权,生成多个权重向量;在最终的函数当中会定义一个的正则项,正则项的推导如下所示:定义n个加权矩阵{ws1,ws2,ws3,...wsn},用这n个加权矩阵来对语义矩阵h1和h2进行语义加权,按照相互加权的矩阵运算公式:最终获得n个权重矩阵分别为:{wt1,wt2,wt3,...,wtn},对这n个权重矩阵进行加和求平均值记作:将看作是一个中心的权重矩阵,定义以下的正则项:通过最大化这个正则项保证每个权重矩阵尽可能的不相同,从而保证每个权重矩阵都能够抽取不同层次的语义信息。本发明的有益效果是:从实验结果上来看,句子划分后的模型对lstm模型有很好的提升,因为句子划分网络可以使得lstm每次进行句子语义提取的时候可以只计算句子中的一部分,从而在训练lstm的时序反向传播算法过程中梯度差只需要传播几个时序,从而可以很好的学习到每个词。这也是句子划分网络所能够带来的语义相似模型判断效果上提升的原因。附图说明图1基于强化学习的语义相似计算模型整体图;图2siameselstm模型图;图3相互加权的siameselstm模型图;图4句子蒸馏模型图;图5句子划分模型图;图6相互加权模型图;具体实施方式下面结合实施例对本发明做进一步描述。下述实施例的说明只是用于帮助理解本发明。应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。本发明的主要目的是通过使用强化学习的方法来进一步的改善长短时记忆模型卷积句子过程中可能会存在的重要的语义信息丢失现象。主要是在语义相似模型siamese上提出改进的模型。本发明提出的模型主要包括四个主要的功能模块:句子蒸馏网络模块,句子划分网络模块,句子语义抽取模块,注意力加权模块。模型的总体图如图1所示。模型的整体结构是一个强化学习的模型,基于强化学习中的ddpg算法模型的一种改编,模型的组成有两部分,最外围的policynetwork网络是句子划分的网络或者是句子蒸馏网络模块,该网络使用多层深度神经网络模型,是一个actor网络功能模块,主要功能是接受multi-lstm模型的内部状态,然后计算给出一个动作返回给multi-lstm模型。内层的整体架构是一个siameselstm模型,是一个critic网络模块,siameselstm模型如图2所示,该模型是一个传统的通用模型,输入部分仍然是将词向量作为每个时刻的输入,该模型曼哈顿距离来衡量句子语义相似程度。使用曼哈顿距离来代替出传统常用的欧式距离的原因是曼哈顿距离更加的稳定。同时本发明将使用相互加权模型来增强语义,相互加权后的模型如图3所示。multi-lstm使用了两层的长短时记忆模型叠加,将第二层输出的隐藏层语义向量输出到co-attention模型当中进行加权操作,生成每个时刻的加权重weight后,再与隐藏层的输出h进行运算生成最终的语义向量d(s)。最终将提取的语义向量用曼哈顿的距离来表示相似度||d(s1)-d(s2)||。actor网络部分和critic网络部分要分别训练,内部的环境模型通过backpropagation(bp)算法来更新,外部的policynetwork根据环境的损失值使用policygradient算法来更新。1.句子蒸馏网络模型句子蒸馏网络是由蒸馏网络模块和multi-lstm网络模块组成,multi-lstm用于句子的语义抽取。policynetwork模型就是actor网络,模型的详细表述如图4所示。图4中左边的模型是multi-lstm模型,包含两层的长短时记忆模型,右边的是蒸馏网络,其中{w1,w2,w3...wt...we}表示每个时刻输入到长短时记忆模型的词向量,{s1,s2,s3...st...se}代表模型内每个时刻的状态,初始时刻将长短时记忆模型内节点初始化为0,{h1,h2,h3...ht...he}表示每个时刻长短时记忆模型的隐藏层输出,{a1,a2,at-1...an}表示每个时刻policynetwork的输出动作值,当词向量输入到lstm模型当中的时候,都会先将长短时记忆模型节点当前的状态和隐藏层的输出以及词向量合并成状态st:传入policy网络当中进行动作的输出记作at,语义提取总的结构有两层长短时记忆模型,生成状态st后,将状态传入句子蒸馏网络判断当前传入的词根据当前上下文是否应该被蒸馏出去,如果判断应该保留该词就将词向量传入第一层的长短时记忆模型当中进行语义的计算,如果模型判断不应该保留则跳过当前词。通过句子蒸馏网络可以将一个长句子当中的非关键词去除掉,从而保留了句子的核心的词语,使得长短时记忆模型对句子中的每个关键的词都能很好的学习到。2.句子划分网络模型句子划分网络和句子蒸馏网络的原理基本相似,区别是policynetwork输出的动作不同以及内部multi-lstm模型接受动作后处理方式不同,policynetwork网络输出的动作是重置长短时记忆模型的状态,结构如图5所示。动作输出有两种状态分别表示是否重置长短时记忆模型的状态,当actor网络输出要重置状态时,在下个单词输入之前要将长短时记忆模型内部细胞状态重置,这样就可以使模型只记得之前一段句子,达到截断句子的效果,从而可以缓解lstm在处理很长句子的时候会因为时间戳过长而忘记之前的词。当输出动作不需要重置细胞状态时,就按照正常的模型来输出处理。当一段句子被截断后,该时间戳的句子最后一个时刻输出的隐藏层状态作为被截断句子的语义表达保存下来作为下一层模型的输入。当一个句子被划分成n段后,就会产生n个截断语句的输出,将这n个截断语句输出到下一层的lstm进行拼接,从而形成了句子整体的语义信息。3.相互加权模型相互加权模型是一种软的加权方式。我们将第二层的{h1...ht...he}隐藏层输出状态传入加权模型当中进行加权。具体的结构如图6所示,其中h1和h2表示lstm的长短时记忆模型第二层隐藏层输出拼接成的语义矩阵,ws是一个形状为l*l的二维加权矩阵,h1是一个l*n的二维矩阵,h2是一个l*m形状的二维矩阵,我们进行如下的矩阵操作运算:经过运算可以获得一个n*m的权重矩阵,然后将每行的参数相加和每列的参数相加,然后经过softmax函数进行归一化后,可以获得h1语义矩阵和h2语义矩阵的每个时刻分别对应的语义权重向量,最后将各自的权重向量和语义矩阵相乘可以获取最后的句子的语义向量。单个的加权矩阵往往会加权语句中的某一个方面,我们为了获取语句更丰富的语义信息,将使用多个加权矩阵来对lstm每个时刻输出的语义进行加权,生成多个权重向量。为了避免多个权重矩阵最终生成的权重矩阵相同从而失去丰富性,因此在最终的函数当中会定义一个的正则项,正则项的推导如下所示:假设我们定义了n个加权矩阵{ws1,ws2,ws3,...wsn},用这n个加权矩阵来对语义矩阵h1和h2进行语义加权,按照相互加权的矩阵运算公式:最终我们可以获得n个权重矩阵分别为:{wt1,wt2,wt3,...,wtn},为了使得这n个加权矩阵能够加权语义矩阵的不同方面的语义特征,为此我们希望这n个权重矩阵能够尽可能的不相同,因此我们对这n个权重矩阵进行加和求平均值我们记作:我们为了保证任意两个权重矩阵之间的距离尽可能的大,从而引用降维lda算法中的类间散度思想来对这个问题进行求解,将看做是一个中心的权重矩阵,则我们的原问题可以化为任意一个权重矩阵距离中心权重矩阵的距离尽可能的大,因此我们可以定义以下的正则项:通过最大化这个正则项,也就是最小化倒数来保证每个权重矩阵尽可能的不相同,从而可以保证每个权重矩阵都能够抽取不同层次的语义信息。模型的算法实现细节:本发明的模型是一个强化学习模型,在具体的算法设计上有online和target两个网络,网络的参数更新依据策略更新的方式,由于强化学习模型在训练过程中很不容易收敛,因此为了使得模型的训练过程更加的稳定,我们将采用off-policy的更新方式来更新网络。首先我们要定义两组相同的神经网络模型。我们称两组神经网络分别为online部分和target部分,两组神经网络的模型结构完全相同,区别是更新的时间不同。在每个轮回训练之前要将target网络的参数赋值给online网络,用online网络来实时更新参数作为训练网络来参与整体的训练,当一个轮回训练完毕后,要使用soft更新的方式将online网络当中的参数来更新到target网络上,即设置一个参数β,则最终更新到target网络上的参数为:targetθ=(1-β)targetθ+βonlineθ(公式6)最后在下个轮回训练开始之前,将target网络的参数再次赋值给online网络进行下一轮的训练,本发明在衡量句子之间的语义相似度的时候采用曼哈顿距离来表示,曼哈顿距离的公式为:d=exp(-||ha-hb||)∈[0,1](公式7)同时采用对比比损失值作为误差来训练模型,对比损失函数如下:在训练过程中还有很多的训练技巧,比如在训练过程中如果从初始开始训练模型则收敛过程会很慢,或者很可能不会收敛,因此一般会有一个预训练的过程,模型的预训练是强化学习模型的一个特殊模式,就是根据当前环境下要给网络一组合理的初始化参数,就像一个学生要想学习解方程必须要先学会加减乘除一样。本方法对于句子划分模型的初始化训练策略是随机的将句子按照3-6个词进行划分。对于句子蒸馏网络的预训练部分,由于本发明后续中文实验采用的数据的特殊性(句子的前几个词非常重要),一般将句子的前几个词组保留,后面的词组以一定的概率进行随机的蒸馏出去。并且在训练过程中对policynetwork网络部分不去训练,用预训练的方式先训练multi-lstm语义提取网络,当整体模型达到一定的准确率后再将两个部分网络共同训练。下面结合具体的实验来说明本发明的效果,本发明是一种用于计算语义相似综合性框架,具体的实验如下。1.实验平台本发明实验所采用的硬件平台:intel(r)core(tm)i7-5700hqcpu@2.70ghz,内存16gb,nvidiageforcegtx970m显存3gb。软件平台:windows10专业版、eclipse开发环境,pathon3.6、tensorflow(gpu版)深度学习框架2.实验数据本发明采取的实验数据有两个部分:句子划分语义相似计算模型的实验数据使用的是斯坦福的自然语言处理语料库,将单词少于15的句子对进行筛选出去,最终获得21万对左右的数据。我们将数据集分为训练集、测试集、验证集。句子蒸馏语义相似计算模型的数据是网络爬下来的数据共有两个部分,我们的数据库当中有一整套从网上爬来的汽车名称数据以及汽车的配件信息以及售后信息等,用户同样会提供他们收集的汽车信息的数据库,我们要依据用户数据库当中车的名称和我们的数据库中的车名称来匹配相同车型,从而对两个部分汽车数据进行整合。但是用户提供的汽车名称和我们数据库当中的汽车名称命名规则不同,如表1所示,该表是部分的我们标注好的数据,右边是我们数据的命名标准,左边的是用户的数据库。通过语义相似计算的方法来将用户提供的名称和数据库当中的车辆名称做一个相似性匹配,从而确定是我们数据库当中的哪个型号的车,然后将所有的数据进行整合。实验数据有6万多对已经标注的配对的数据。在生成训练数据过程中要1:2的随机生成负样本。表1数据库命名数据3.基于句子蒸馏模型的语义相似计算模型实验步骤(1)首先我们要训练本次实验需要的中文词向量。我们使用gensim工具来训练中文的分词向量,首先使用数据库当中的所有汽车名称作为语料库来训练词向量。使用jieba分词工具对汽车描述名称进行分词,然后使用gensim工具进行中文的词向量训练。(2)随机初始化online网络和target网络的参数(3)将target网络参数赋值给online网络并且读取一个batch的数据(4)该步骤要分情况,首先模型初始训练需要经历预训练步骤,所以如果该步骤是在预训练情况下,则会随机的将句子中的词蒸馏出去,如果是正式训练则要将样本句子中的词向量按照顺序输入到语义提取的模型当中,并且记录下每个时刻输入词向量后的长短时记忆模型的隐藏层输出以及自身状态,然后将隐藏层输出状态和细胞状态作为环境输入到句子蒸馏网络当中进行动作(保留)的判断,我们将输出的动作概率当作一个概率模型随机选择最终的动作。(5)循环执行(4)获取多个采样样本,并且在采样过程中保留一个非随机样本,非随机样本是根据输出动作概率大小唯一确定的。(6)我们使用这个非随机样本获取的loss来对模型的非句子蒸馏网络的online网络也就是语义相似判断部分的网络online进行参数更新。(7)根据随机样本和非随机样本来产生的loss来对句子蒸馏网络部分的online进行训练(8)循环(4)-(7)直到一个batch训练完,然后将online网络以soft更新的方式来对target网络进行更新。(9)将target网络的参数更新到online网络上,然后执行(3)(10)将训练好的模型保存下来,然后用测试数据来验证模型的效果。选取测试数据中用户数据库命名的数据作为原始数据,设置阈值为0.5,对于每个用户的汽车名称,和我们数据库的汽车名称作相似性计算,大于0.5的作为相同车名备选项,然后把相似值做排序后选出最相似的一个作为最终的相似车型名称。最终实验的结果如表2所示表2实验结果模型召回率准确率语义相似计算模型96%95.7%通常我们判断是不是同一辆车一般只需要车名和紧接着车名后面的车型号就能唯一的识别出来,因此蒸馏模型可以一定程度的将后面修饰的蒸馏出去。表3所示为句子蒸馏前后的效果,其中第一栏是原来的汽车名称,当中是经过分词工具分词后去除特殊符号后的模型输入数据,右边的是蒸馏后的效果。可以看到模型基本上会保留主要的汽车名称以及必要的汽车的统一型号名称。表3句子蒸馏效果4.基于句子划分模型的语义相似计算模型实验步骤(1)首先我们要训练本次实验需要的英文词向量。训练英文词向量的语料库使用维基百科的英文语料库大约有11g左右。在这里我们指定向量维度为200维分别训练词向量模型,阈值和窗口大小设置成默认值。(2)随机初始化online网络和target网络的参数(3)将target网络参数赋值给online网络并且读取一个batch的数据(4)该步骤需要分情况,如果是在预训练步骤当中进行训练,则本步需要将每个句子3-6个单词分一组,如果是正式训练则将样本句子中的词向量按照顺序输入到语义提取的模型当中,并且记录下每个时刻输入词向量后的长短时记忆模型的隐藏层输出以及自身状态,然后将隐藏层输出状态和细胞状态作为环境输入到句子划分网络当中进行动作(截断)的判断,我们将输出的动作概率当作一个概率模型随机选择最终的动作。这样做的目的主要是进行解空间的探索(5)循环执行(4)获取多个采样样本,并且在采样过程中保留一个非随机样本,非随机样本是根据输出动作概率大小唯一确定的。(6)我们使用这个非随机样本获取的loss来对模型的非句子划分网络的online网络也就是语义相似判断部分的网络online进行训练。(7)根据随机样本和非随机样本产生loss来对句子划分网络部分的online进行训练。(8)循环(4)-(7)直到一个batch训练完,然后将online网络以soft更新的方式来对target网络进行更新。(9)将target网络的参数更新到online网络上,然后执行(3)。(10)训练好模型以后我们用测试数据集来测试。实验最终所有的模型训练结果如表4所示,从实验结果上来看,句子划分后的模型对lstm模型有很好的提升,因为句子划分网络可以使得lstm每次进行句子语义提取的时候可以只计算句子中的一部分,从而在训练lstm的时序反向传播算法过程中梯度差只需要传播几个时序,从而可以很好的学习到每个词。这也是句子划分网络所能够带来的语义相似模型判断效果上提升的原因。表4实验结果对比表modelsacc(%)siamesebilstm0.8657自注意力加权模型0.8846句子划分语义相似计算模型0.9136基于句子划分语义相似模型的policynetwork部分的句子划分效果,如表5所示表5句子划分网络效果表当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1