基于元学习的视频摘要方法与流程
本发明属于计算机视觉
技术领域:
,也是机器学习和模式识别的关键问题之一。本发明对视频进行摘要,提取出其中的关键帧,可缩减人们浏览视频的时间,并能应用到视频检索、视频管理等方面。
背景技术:
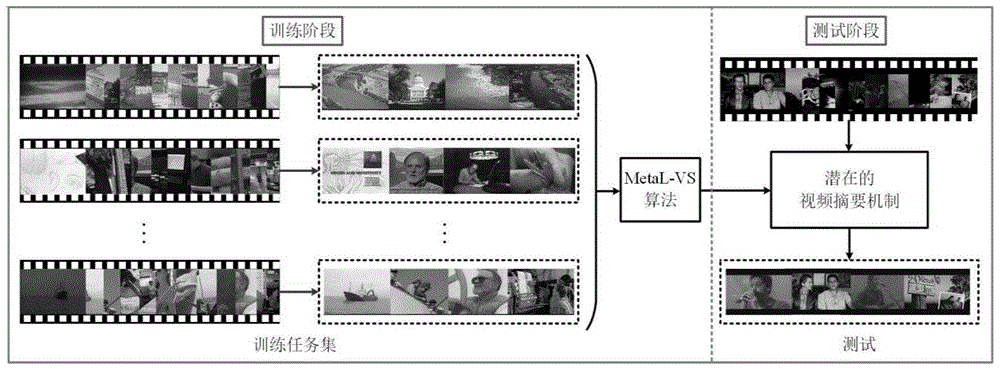
:随着手机、移动相机等可拍摄设备的广泛普及,涌现出海量的视频数据,并且每天都有大量的视频数据产生和传播。一方面,这些数据为人们提供了丰富的信息,另一方面,浏览、检索这些视频数据消耗的时间也非常可观。在此背景下,视频摘要作为一种视频浓缩技术得到了计算机视觉领域研究人员的广泛关注。视频摘要是指通过半自动或自动的方式,分析视频结构和内容存在的时空冗余,去除原始视频中的冗余片段(帧),并提取出其中有意义的片段(帧)。它不但可以提高人们浏览视频的效率,还可以为后续视频分析和处理奠定基础,广泛应用于视频检索、视频管理等方面。自其产生至今,一直备受关注,涌现出很多具有代表性的方法。但因不同人在浏览视频时关注点不同,到目前为止,还没有一个普适的或者能够完全满足人们需要的视频摘要方法,因此,视频摘要算法的研究还有广阔的探索空间。因视频数据固有的结构、序列化特性以及长短期记忆神经网络(longshorttermmemoryneuralnetwork,lstm)优异的序列建模性能,最近的方法大多使用lstm作为基本模型。如zhang等人在文献k.zhang,w.l.chao,f.sha,andk.grauman,“videosummarizationwithlongshorttermmemory,”inproc.eur.conf.comput.vis.,pp.766-782,2016.中提出的视频摘要长短期记忆网络(videosummarizationlstm,vslstm)和行列式点过程长短期记忆网络(determinantalpointprocesslstm,dpplstm)是近些年基于基本lstm模型改进的两个典型视频摘要网络模型,可很好地对视频中不同长度的时间依赖关系建模;zhou和qiao在文献k.zhouandy.qiao,“deepreinforcementlearningforunsupervisedvideosummarizationwithdiversityrepresentativenessreward,”arxiv:18.01.00054,2017.中提出的多种无监督和监督版本深度摘要网络(deepsummarizationnetwork,dsn)将深度强化学习的思想融入lstm网络的学习过程中,以更好的捕捉视频数据的结构化特性;ji等人在文献z.ji,k.xiong,y.pang,andx.li,“videosummarizationwithattention-basedencoder-decodernetworks,”arxiv:1708.09545,2017.中提出的基于注意力机制的编码解码器视频摘要网络结构(attentionencoder-decodernetworksforvideosummarization,avs)将以lstm为基本模型的编码器和基于注意力机制的解码器结合实现对视频关键帧的提取。存在的问题:1)更多的关注于视频数据的结构或序列化特性,而非视频摘要任务本身;2)未明确地要求模型探索视频摘要的机制,模型泛化能力不够好。技术实现要素:要解决的技术问题针对上述现有方法的不足,,本发明提供一种基于元学习的视频摘要方法。该方法基于元学习的思想,将对每个视频的摘要问题视为一个独立的视频摘要任务,模型的学习在视频摘要任务空间进行,以使其更多的关注于视频摘要任务本身;通过在视频摘要任务空间的学习,本方法显示地要求模型探索一种视频摘要机制,以提高模型的泛化性能。技术方案一种基于元学习的视频摘要方法,其特征在于步骤如下:步骤1:准备数据集使用开源视频摘要数据集summe、tvsum、youtube以及ovp:当以summe为测试集时,youtube和ovp作为训练集,tvsum作为验证集;当以tvsum为测试集时,youtube和ovp作为训练集,summe作为验证集;步骤2:提取视频帧特征将视频帧输入到googlelenet网络,并以网络倒数第二层的输出作为其深度特征;使用颜色直方图、gist、hog以及densesift作为传统特征,其中颜色直方图提取自视频帧的rgb形式,其他传统特征提取自视频帧对应的灰度图;步骤3:训练视频摘要模型采用基于元学习思想的两阶段网络训练算法以进行学习者模型vslstm网络fθ参数θ的学习,训练前将模型参数θ随机初始化为θ0,其第i次迭代将模型参数由θi-1更新为θi,训练中每次迭代由两阶段的随机梯度下降过程组成:第一阶段将参数由θi-1更新为从训练集中随机选出一个任务计算学习者在当前参数θi-1状态下在该任务上的表现以及损失函数求对θi-1的导数并更新学习者参数θi-1至然后可再次计算学习者模型在该任务上的表现并更新其参数此参数更新可进行n次,其中n为正整数,如下式所示:其中,α表示学习率,和是学习者模型和在任务上的l1损失函数,其中学习者模型的参数分别为θi-1和l1损失函数的定义为:其中y表示模型的输出向量,x表示groundtruth向量,n表示向量中元素的个数;第二阶段将参数由更新为θi:从训练集中随机选出一个任务计算学习者在参数状态下在该任务上的表现以及损失函数求对θi-1的导数并更新学习者参数至θi,如式(3)所示:其中β表示元学习率,在本发明方法中作为超参数;是学习者模型在任务上的l1损失函数,其中学习者模型的参数是此两阶段训练算法作为元学习者模型指导学习者模型vslstm的训练以进行视频摘要机制的探索,通过最大化学习者模型在测试集上的泛化能力,即最小化学习者模型在测试集上的期望泛化误差,可在多次迭代中求得学习者模型的参数θ;步骤4:将步骤2中的视频帧特征输入到步骤3训练好的学习者模型vslstm网络中,可得到每帧被选入视频摘要的概率。步骤4的具体步骤如下:首先根据vslstm输出的概率或得分,将视频分成时序上不相交的片段;然后将每个片段内视频帧分数的平均值作为该视频片段的得分,并根据视频片段的分数,对视频片段进行降序排序;从最大概率的视频片段开始按序保留,为避免选取的摘要结果过长,当保留的视频片段总长度达到原视频长度的15%时停止,此时选取的视频片段作为原始视频的摘要结果。有益效果本发明提出的一种基于元学习的视频摘要方法,有益效果如下:1)首次应用元学习的思想解决视频摘要问题;2)提出了简单有效的视频摘要模型训练方法,使模型更多的关注于视频摘要任务本身;3)旨在提高模型的泛化能力,明确要求视频摘要模型对视频摘要机制进行探索;4)通过定性和定量实验对比证明本发明算法具有先进性、有效性等特点,有很高的实际应用价值。附图说明图1是本发明概念上整体的流程图图2是本发明提出训练方法的一次迭代过程示意图图3是本发明在不同超参数下的性能示意图图4是本发明的可视化结果图具体实施方式现结合实施例、附图对本发明作进一步描述:实现本发明的技术方案包括以下步骤:1)准备数据集本方法使用开源视频摘要数据集summe(m.gygli,h.grabner,h.riemenschneider,andl.vangool,“creatingsummariesfromuservideos,”inproc.eur.conf.comput.vis.,pp.505-520,2014)、tvsum(y.song,j.vallmitjana,a.stent,anda.jaimes,“tvsum:summarizingwebvideosusingtitles,”inproc.ieeeconf.comput.vis.patternrecognit.,pp.5179-5187,2015)、youtube(s.e.f.deavila,a.p.b.lopes,a.daluzjr,anda.dealbuquerquearaujo,“vssum:amechanismdesignedtoproducestaticvideosummariziesandanovelevaluationmethod,”patternrecognit.lett.,vol.32,no.1,pp.56-68,2011)和ovp(openvideoproject,http://www.open-video.org/.)。为探索模型的泛化性能,先后使用summe或tvsum作为测试集,另外三个作为训练和验证集。当以summe为测试集时,tvsum、youtube以及ovp作为训练和验证集;当以summe为测试集时,youtube和ovp作为训练集,tvsum作为验证集;当以tvsum为测试集时,youtube和ovp作为训练集,summe作为验证集。2)提取视频帧特征本发明方法分别使用深度和传统两种类型的特征以验证模型的有效性。将视频帧输入到googlelenet(c.szegedy,w.liu,y.jia,p.sermanet,s.reed,d.angueloy,d.erhan,v.vanhoucke,a.rabinovichetal,“goingdeeperwithconvolutions,”inporc.ieeeconf.comput.vis.patternrecognit.,2015)网络模型中的倒数第二层输出作为其深度特征,传统特征使用颜色直方图、gist、hog(histogramoforientedgradient)以及densesift(scaleinvariantfeaturetransform),其中颜色直方图提取自视频帧的rgb形式,其他传统特征提取自视频帧对应的灰度图。3)训练视频摘要模型本方法提出基于元学习思想的两阶段网络训练算法metal-vs,训练中每次迭代由两阶段的随机梯度下降算法组成,此两阶段训练算法作为元学习者模型指导学习者模型的训练,vslstm作为学习者模型进行视频摘要机制的探索。如图1所示,本方法基于元学习的思想,将对每个视频的摘要问题视为一个独立的视频摘要任务,模型在视频摘要任务空间进行学习,最后,通过将测试视频的摘要问题视为新任务,模型可得到该视频对应的摘要。具体地,本方法提出了基于元学习思想的两阶段网络训练算法以进行学习者模型(本方法实现时使用vslstm网络作为学习者模型)fθ参数θ的学习。如图2所示,设第i次迭代可将模型参数由θi-1更新为θi(训练前将模型参数随机初始化为θ0),训练中每次迭代由两阶段的随机梯度下降过程组成。第一阶段将参数由θi-1更新为(图示情况中n=2):从训练集中随机选出一个任务计算学习者在当前参数θi-1状态下在该任务上的表现以及损失函数求对θi-1的导数并更新学习者参数θi-1至然后可再次计算学习者模型在该任务上的表现并更新其参数理论上此参数更新可进行n(n为正整数)次,如式(1)所示:其中α表示学习率,在本发明方法中将其作为超参数;和是学习者模型和在任务上的l1损失函数,其中学习者模型的参数分别为θi-1和l1损失函数的定义为:其中y表示模型的输出向量,x表示groundtruth向量,n表示向量中元素的个数。第二阶段将参数由更新为θi:从训练集中随机选出一个任务计算学习者在参数状态下在该任务上的表现以及损失函数求对θi-1的导数并更新学习者参数至θi,如式(3)所示:其中β表示元学习率,在本发明方法中作为超参数;是学习者模型在任务上的l1损失函数,其中学习者模型的参数是此两阶段训练算法作为元学习者模型指导学习者模型(vslstm)的训练以进行视频摘要机制的探索。通过最大化学习者模型在测试集上的泛化能力(最小化学习者模型在测试集上的期望泛化误差),可在多次迭代中求得学习者模型的参数θ。4)输出视频摘要本视频摘要模型的输入是视频帧特征(深度或传统特征),输出是视频中每帧被选入摘要的概率(输出是一个向量,向量中每个元素大于等于0小于等于1,向量的长度等于帧数,即向量中每个原素表示相应视频帧被选入视频摘要的概率,也可以理解为是该帧的重要性得分。)。按照文献k.zhang,w.l.chao,f.sha,andk.grauman,“videosummarizationwithlongshorttermmemory,”inproc.eur.conf.comput.vis.,pp.766-782,2016.中的方法,可将本方法的结果转化为摘要结果。将测试视频各帧的特征输入到训练好的学习者模型,经过处理即可得到视频摘要结果。具体步骤:首先根据vslstm输出的概率或得分,用kerneltemporalsegmentation(kts)(按照文献k.zhang,w.l.chao,f.sha,andk.grauman,“videosummarizationwithlongshorttermmemory,”inproc.eur.conf.comput.vis.,pp.766-782,2016.)方法将视频分成时序上不相交的片段;然后将每个片段内视频帧分数的平均值作为该视频片段的得分,并根据视频片段的分数,对视频片段进行降序排序;从最大概率的视频片段开始按序保留(按视频片段得分由高到低的顺序),为避免选取的摘要结果过长,当保留的视频片段总长度达到原视频长度的15%时停止,此时选取的视频片段作为原始视频的摘要结果。1)仿真条件本发明是在中央处理器为i5-34703.2ghzgpu、内存16g、centos操作系统上,运用anaconda软件进行python程序的仿真。实验中使用的数据集是从公开的数据库中获得:summedataset(http://classif.ai/dataset/ethz-cvl-video-summe)tvsumdataset(https://github.com/yalesong/tvsum)youtubedataset(http://www.npdi.dcc.ufmg.br/vsumm)ovpdataset(http://www.open-video.org)其中summe数据集包含25个标注视频,tvsum、youtube以及ovp中各有50个标注视频。在训练学习者模型时,训练集包含groundtruth,测试集的groundtruth被隐藏。当以summe为测试集时,从tvsum中随机选取10个视频作为验证集,tvsum中其余视频与youtube、ovp中的视频共同组成训练集;当以tvsum作为测试集时,从tvsum中随机选出25个视频作为测试集,其中剩余的视频作为验证集,另外三个数据集组成训练集。在我们的实验中,使用测试集来验证我们方法的有效性。性能评价指标是f-scoref:其中p表示精度(precision),r表示召回率(recall):其中a表示模型生成的摘要结果,b表示groundtruth。2)仿真内容(1)为展示探索使本发明方法性能更好的超参数(学习率learningrate,lr、元学习率metalearningrate,mlr以及第一阶段参数更新次数n)的过程,在一个实验里,我们进行了不同超参数下模型性能的测评实验。图3展示了不同超参数下模型性能的表现。从图中可以看出,当lr取0.0001,mlr取0.001时,模型在两个数据集上的表现最好。表1展示了超参数n取不同值时模型在两个数据集上的f-score,加粗数字是最好的指标。因实验使用显卡的显存限制,n值最大是2,当n值大于2时会出现内存不足的错误。从表中可以看出,当超参数n的值为1时,模型在两个数据集上的表现最好。表1.超参数n取不同值时模型在两个数据集上的性能(f-score)n12summe44.1%42.5%tvsum58.2%58.1%(2)为证明本算法的有效性,在实验2中,我们将本文的算法与近几年的典型方法进行了对比。第一种对比方法是gyglietal.在2015年提出的,详细介绍参考论文:m.gygli,h.grabner,andl.vangool,“videosummarizationbylearningsubmodularmixturesofobjectives,”inproc.ieeeconf.comput.vis.patternrecognit.,2015,pp.3090-3098.第二种对比方法是vslstm,详细介绍参考论文:k.zhang,w.l.chao,f.sha,andk.grauman,“videosummarizationwithlongshorttermmemory,”inproc.eur.conf.comput.vis.,2016,pp.766-782.第三种对比方法是zhangetal.在2016年提出的,详细介绍参考论文:k.zhang,w.l.chao,f.sha,andk.grauman,“summarytransfer:exemplar-basedsubsetselectionforvideosummarization,”inproc.ieeeconf.comput.vis.patternrecognit.,2016,pp.1059-1067.第四种对比方法是sum-gansup,详细介绍参考论文:b.mahasseni,m.lam,ands.todorovic,“unsupervisedvideosummarizationwithadversariallstmnetworks,”inproc.ieeeconf.comput.vis.patternrecognit.,2017.第五种对比方法是dr-dsnsup,详细介绍参考论文:k.zhouandy.qiao,“deepreinforcementlearningforunsupervisedvideosummarizationwithdiversityrepresentativenessreward,”arxiv:1801.00054,2017.第六种对比方法是lietal在2017年提出的,详细介绍参考论文:x.li,b.zhao,andx.lu,“ageneralframeworkforeditedvideoandrawvideosummarization,”ieeetrans.imageprocess.,vol.26,no.8,pp.3652-3664,2017.表2是量化指标f-score的对比,加粗数字是最好的指标。从表中可以看出,本文提出的方法metal-vs在对比中表现最好。因此,通过与此领域近些年具有代表性的方法的对比,进一步证明了本发明的先进性。图4是metal-vs的可视化结果图,其中air_force_one和car_over_camera视频来自summe数据集;awmhb44_ouw和qqr6aexwxoq视频来自tvsum数据集。直方图的蓝色部分是groundtruth,即人工标注的各帧是摘要帧的概率,红色部分是metal-vs的结果,直方图下边的图片是metal-vs摘要结果中的部分示例图片。从图中可以看出,虽然有一些偏差,但metal-vs可以从原始视频中选出重要度高的帧,忽略不足够重要的帧。从可视化图中可看出本发明的有效性。表2.7种方法视频摘要结果指标f-score对比方法summetvsumgyglietal.39.7%-vslstm40.7%56.9%zhangetal.40.9%-sum-gansup41.7%56.3%dr-dsnsup42.1%58.1%lietal.43.1%52.7%metal-vs(本发明)44.1%58.2%(3)为测试本发明方法metal-vs对传统特征的鲁棒性,我们与两个近两年具有代表性的方法进行了传统特征上视频摘要性能的对比实验。第一个对比方法是sum-gansup,详细介绍参考论文:b.mahasseni,m.lam,ands.todorovic,“unsupervisedvideosummarizationwithadversariallstmnetworks,”inproc.ieeeconf.comput.vis.patternrecognit.,2017.第二个对比方法是dpplstm,详细介绍参考文献:k.zhang,w.l.chao,f.sha,andk.grauman,“videosummarizationwithlongshorttermmemory,”inproc.eur.conf.comput.vis.,2016,pp.766-782.表3是量化指标f-score的对比,加粗数字表示最好的指标。从表中能看出,metal-vs取得了可与近两年经典方法比肩的性能,并且在summe数据集上还分别超过两个对比方法4和2.8个百分点。由metal-vs在传统特征上的表现可知,本发明对传统特征有一定的鲁棒性和泛化能力。表3.使用传统特征时f-score性能对比方法summetvsumsum-gansup39.5%59.5%dpplstm40.7%57.9%metal-vs(本发明)43.5%57.9%本发明方法是第一个探索元学习在视频摘要领域应用的方法。基于元学习的思想,视频摘要模型在视频摘要任务空间进行学习,这种方式有利于模型更多的关注于视频摘要任务本身,而不仅仅是结构化、序列化的视频数据,同时更有利于模型对视频摘要机制的探索,有利于提高模型的泛化能力。通过定性和定量实验对比,证明本发明算法具有先进性、有效性等特点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1