一种双流RGB-DFasterR-CNN识别哺乳母猪姿态的方法与流程
本发明涉及计算机视觉中多模态的目标检测和识别技术领域,特别涉及一种基于fasterr-cnn目标检测算法,利用rgb-d数据,采用双流cnn提取rgb-d特征后在特征提取阶段融合的端对端的哺乳母猪姿态识别方法。
背景技术:
养猪场中猪的行为是其福利和健康状态的重要表现形式,直接影响到养猪场的经济效益。在动物行为的监测技术中,与传统的人工监测和传感器技术相比,使用计算机视觉进行自动识别是一种低成本、高效的、非接触式的方式,能持续提供有价值的行为信息。
近年来,使用计算机视觉对猪进行行为识别受到了广泛的研究。例如:2018年华南农业大学薛月菊等人公开号为cn108830144a的专利利用深度图像数据,引入残差结构和centerloss改进fasterr-cnn算法来自动识别自由栏中哺乳母猪的五种姿态。该团队2017年公开号为cn201710890676的专利利用深度图像,首先采用dpm算法检测母猪,在对检测框使用cnn网络识别母猪姿态,公开号为cn107527351a的专利则利用rgb图像和fcn算法自动分割场景中的母猪。2018年华南农业大学肖德琴等人公开号为cn108717523a的专利公开了一种基于机器视觉的母猪发情行为检测方法,该方法首先进行爬跨行为判断,然后根据发情母猪的位移运动信息,公猪的接近程度和爬跨频次等信息训练神经网络模型实现行为检测。2016年中国农业大学劳凤丹等人公开号为cn104881636a的专利公开了一种识别猪躺卧行为的方法及装置,该方法获取猪的深度图像和二值图像,对二值图像进行椭圆拟合,并计算深度图像特定点到地面的高度,最后通过阈值比较识别猪的躺卧行为。2017年江苏大学朱伟兴等人公开号为cn108090426a的专利公开了一种基于机器视觉的群养猪身份识别方法,通过采集群养猪的俯视视频,频域中提取猪个体的多尺度和多方向的特征,空间域提取猪个体微小细节特征,对特征降维后训练分类器,实现识别判段,此外该团队公开号为cn107679463a的专利公开了一种采用机器视觉技术识别群养猪攻击行为的分析方法,公开号为cn107437069a的专利公开了基于轮廓的猪只饮水识别方法等等。
目前基于计算机视觉的猪的行为识别研究中,大多研究仅使用rgb图像或深度图像数据进行研究,这导致在真实场景中难以获得鲁棒的特征表示,容易达到识别精度的瓶颈。摄像机将3维世界映射为2维空间的rgb图像会不可避免地导致信息丢失,使用深度图像来作为补偿这部分信息是可行的。此外,深度图像因缺少rgb图像的纹理、色彩等信息而缺失目标物体的细节信息特征,当目标物体形状高度相似时难以做精准的识别。特别地,在俯视拍摄的母猪姿态识别任务中,一方面,目标的高度是判断不同姿态的重要信息,这在rgb图像中是无法体现的,另一方面,母猪的部分姿态的高度和形状又是相近的(例如俯卧与腹卧),仅利用深度信息难以精准区分。
因此,提供一种高精度的双流rgb-dfasterr-cnn识别哺乳母猪姿态的方法是本领域技术人员亟待解决的技术问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种双流rgb-dfasterr-cnn识别哺乳母猪姿态的方法,对自由栏中的哺乳母猪实现自动、更高精度和实时的姿态识别。为实现上述目的其具体方案如下:
本发明公开了一种双流rgb-dfasterr-cnn识别哺乳母猪姿态的方法,包括如下步骤:
s1、采集哺乳母猪的rgb-d视频图像,包括rgb图像和深度图像,并建立母猪姿态识别rgb-d视频图像库;
s2、通过相机标定方法计算获得rgb图像与深度图像之间的映射关系;
s3、基于fasterr-cnn算法,使用两个cnn网络分别卷积rgb图像和深度图像,得到rgb图像特征图和深度图像特征图;
s4、仅使用一个rpn网络,以深度图像特征图为基础生成感兴趣区域d-roi,通过rgb图像与深度图像之间的映射关系,对每一个d-roi一一对应生成rgb图像特征图的感兴趣区域rgb-roi;
s5、对每一个d-roi和rgb-roi分别使用roipooling层池化为固定大小,对池化后的每一组d-roi和rgb-roi特征图使用拼接融合方法,融合两者特征;
s6、对融合后的特征图使用noc结构的fastr-cnn进一步提取融合特征,在经过全局平均池化层之后交由分类器和回归器处理,得到双流rgb-dfasterr-cnn母猪姿态识别模型,并输出识别结果;
s7、从母猪姿态识别rgb-d视频图像库获取训练集和测试集,使用训练集训练双流rgb-dfasterr-cnn母猪姿态识别模型,使用测试集测试模型性能,最终筛选最佳性能模型。
优选的,所述步骤s1的具体过程如下:
s11、将rgb-d传感器固定俯视拍摄采集猪栏rgb-d视频图像;rgb-d传感器不仅能捕获客观世界的色彩信息还能捕获目标的深度信息,其拍摄的rgb图像包含了色彩、形状和纹理等信息,而深度图像包含了清晰的边缘信息和对光线鲁棒的深度信息;
s12、从获取的rgb-d视频图像数据中采样获取训练集和测试集,其中训练数据集占70%,测试集占30%以测试模型性能;
s13、在训练集和测试集中,对深度图像进行预处理,包括滤波去噪和图像增强,然后对预处理后的深度图像进行目标标注,即标注目标外包围框和姿态类别,rgb图像则无需处理;再对处理后的训练集数据进行旋转和镜像扩增用于训练模型。
优选的,所述步骤s2的具体过程如下:
s21、使用相机标定方法获得rgb图像的内参矩阵为krgb,深度图像的内参矩阵kd,针对相机标定使用的同一幅棋盘格图像获得rgb图像外参矩阵rrgb和trgb,以及深度图像的外参矩阵rd和td;令rgb图像的非齐次像素坐标为prgb=[urgb,vrgb,1]t,深度图像的非齐次像素坐标为pd=[ud,vd,1]t;则深度图像坐标映射到rgb图像坐标的旋转矩阵r,平移矩阵t分别为:
s22、深度图像的像素坐标与rgb图像的像素坐标的映射关系为:
prgb=(r*zd*pd+t)/zrgb
由上式,可以通过获取深度图像的坐标值pd和其像素值zd,以及拍摄距离zrgb得到该点映射对应的rgb图像的坐标值prgb。
优选的,所述步骤s3的具体过程如下:
在fasterr-cnn的共享卷积层部分,使用两个相同的cnn网络分别以深度图像和rgb图像作为输入,以深度图像作为输入的cnn网络为conv-d,以rgb图像作为输入的cnn网络为conv-rgb。
优选的,所述步骤s4的具体过程如下:
s41、在fasterr-cnn算法的rpn阶段,仅用一个rpn网络以conv-d输出的深度图像特征图作为输入生成深度图像的感兴趣区域d-roi;
s42、利用rgb图像与深度图像之间的映射关系,对每一个d-roi一一对应生成conv-rgb输出的rgb图像特征图的rgb图像感兴趣区域rgb-roi。
优选的,所述步骤s5的具体过程如下:
s51、对每一组d-roi与rgb-roi使用roipooling层池化为固定大小;
s52、对池化后的d-roi与rgb-roi的特征图进行串联堆叠融合,即对相同的空间位置i,j(1≤i≤h,1≤j≤w)在通道上d(1≤d≤d)堆叠,对于两个通道数量为d的特征图,堆叠后输出特征图通道数量为2d:
其中,
优选的,所述步骤s6的具体过程如下:
s61、对融合后的特征图继续使用由若干层卷积层组合而成的noc结构卷积进一步提取融合特征;
s62、再使用全局平均池化层池化后输入给fastr-cnn的分类器与回归器。
优选的,所述步骤s11的rgb-d传感器为kinect2.0传感器。
优选的,所述步骤s31的conv-d与conv-rgb为相同的卷积结构且均为zf结构。
优选的,所述步骤s51的采用空间金字塔池化层方式,将特征图分为6*6的网格,并对每一个网格采用最大值池化的方式生成固定大小6*6、通道数为256的特征图。
与现有技术相比,本发明技术方案的有益效果是:
(1)本发明提出双流rgb-dfasterr-cnn算法,融合了rgb图像与深度图像各自的优越性,大大提高了识别精度,而不增加太多时间成本。
(2)本发明通过全卷积的结构设计大大压缩了模型大小同时保证了实时性。
(3)本发明建立了哺乳母猪rgb-d视频图像数据库,为后续基于rgb-d视频图像的算法设计和模型训练提供数据源。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
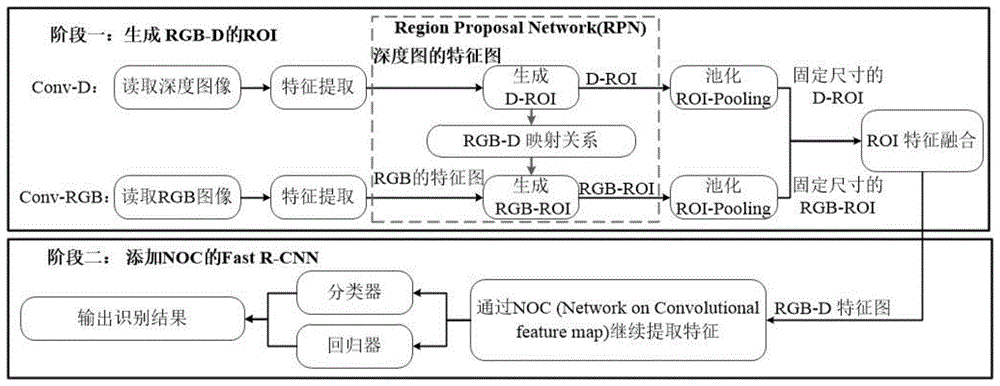
图1为本发明双流rgb-dfasterr-cnn识别哺乳母猪姿态的方法的流程图;
图2附图为本发明双流rgb-dfasterr-cnn的母猪姿态识别模型结构图;
图3附图为本发明识别结果示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
深度学习融合不同的图像特征能获得更好的图像特征表示,在目标识别任务中,融合rgb-d特征可以提取rgb图像和深度图像特征之间的互补性,将有助于提高特征学习的鲁棒性,有助于获得具有目标辨识力的特征。本发明提出一种端对端的rgb-d特征提取阶段的融合策略,即首先分别使用两个cnn网络提取两种数据的差异性特征,再对两者特征融合后继续使用cnn网络提取两种数据特征之间的内在的互补性特征信息。最终基于fasterr-cnn算法,提出一种能充分利用rgb-d数据信息的双流rgb-dfasterr-cnn算法用于高精度的识别哺乳母猪姿态。
图1附图所示的阶段一为生成rgb-d视频图像的感兴趣区域roi,首先分别使用深度图像流的cnn网络conv-d以深度图像做输入提取深度图像特征,rgb图像流的cnn网络conv-rgb以rgb图像做输入提取rgb图像特征。然后使用rpn网络以深度图像特征图作为输入生成感兴趣区域d-roi,再利用rgb图像与深度图像之间的映射关系,即rgb-d映射关系,一一对应生成rgb-roi,d-roi与rgb-roi的特征图分别使用roi-pooling层池化为固定大小尺寸,然后使用拼接融合两者的特征图。阶段二为fastr-cnn对roi进行分类识别的阶段,融合后的特征继续使用noc结构进行卷积,以进一步融合rgb图像与深度图像特征,提取鲁棒的rgb-d特征,最后交由分类器和回归器处理,输出识别结果。
深度学习融合不同的图像特征能获得更好的图像特征表示,在目标识别任务中,融合rgb-d特征可以提取rgb图像和深度图像特征之间的互补性,将有助于提高特征学习的鲁棒性,有助于获得具有目标辨识力的特征。本发明提出一种端对端的rgb-d特征提取阶段的融合策略,即首先分别使用两个cnn网络提取两种数据的差异性特征,再对两者特征融合后继续使用cnn网络提取两种数据特征之间的内在的互补性特征信息。最终基于fasterr-cnn算法,提出一种能充分利用rgb-d数据信息的双流rgb-dfasterr-cnn算法用于高精度的识别哺乳母猪姿态。该方法基于nvidiagtx980ti型号的gpu硬件平台,在ubuntu14.04操作系统搭建caffe深度学习框架,使用python作为编程语言,进行母猪姿态识别模型的训练和测试。
具体实现为:
步骤一、采集哺乳母猪的rgb-d视频图像,包括rgb图像和深度图像,并建立母猪姿态识别rgb-d视频图像库;
步骤二、通过相机标定计算获得rgb图像与深度图像之间的映射关系;
步骤三、基于fasterr-cnn算法,使用两个cnn网络分别卷积rgb图像和深度图像;
步骤四、仅使用一个rpn网络,以深度图像特征图为基础生成感兴趣区域d-roi,通过rgb图像与深度图像之间的映射关系,对每一个d-roi一一对应生成rgb图像特征图的感兴趣区域rgb-roi;
步骤五、对每一个d-roi和rgb-roi使用roipooling层池化为固定大小,对池化后的每一组d-roi和rgb-roi特征使用拼接融合方法,融合两者特征;
步骤六、对融合后的特征图继续使用由若干层卷积层组合而成的noc结构卷积进一步提取融合特征,即rgb-d特征,在经过全局平均池化层之后交由分类器和回归器处理,得到双流rgb-dfasterr-cnn母猪姿态识别模型,并输出识别结果;
步骤七、使用母猪姿态识别rgb-d视频图像库中的训练集训练双流rgb-dfasterr-cnn母猪姿态识别模型,使用测试集测试模型性能,最终筛选最佳性能模型。
步骤一的数据库建立方法具体包括:
1)对28栏猪进行数据采集,采集猪舍为自由栏,大小约为3.8m×2.0m,每栏内包含一只哺乳母猪和8-10头仔猪。使用微软的kinectv2.0传感器,距离猪舍地面190cm~270cm的高度,自上而下俯视拍摄,以每秒5帧的速度获取rgb-d数据。其中获取的rgb图像像素为1080*1920,为了在后续的算法使用过程中节省显存(gpumemory)和加快对rgb图像处理的计算速度,将rgb图像缩放到540*960的分辨率大小。获取的深度图像像素为424*512的分辨率,深度图像的像素值反映了物体到传感器之间的距离。
2)从拍摄的前三次共计21栏数据中,对连续的视频图像随机隔10~40帧选取一组,共随机采样5类姿态的rgb-d图像组,站立2522组,坐立2568组,俯卧2505组,腹卧2497组,侧卧2508组图片,总计12600组rgb-d图像作为原始训练集。从第四次拍摄的7栏数据中随机采样站立1127组,坐立1033组,俯卧1151组,腹卧1076组,侧卧1146组图片,总计5533组rgb-d图像作为测试集,用于测试模型性能。其中每一组rgb-d图像包括一张rgb图像和其对应的深度图像。在总的数据集中,训练集约占70%,测试集约占30%。
3)首先对采样后获取的深度图像进行中值滤波和自适应直方图均衡化处理,以提高对比度,rgb图像则不做预处理。在人工标注阶段,对每一组rgb-d视频图像的数据,我们对深度图像进行人工标注,即对数据集中的每一张深度图像标注母猪的外边界框,获取母猪在图中的坐标位置信息。为了增强后续模型训练的泛化能力和鲁棒性,实验中对原始训练集数据进行数据扩增处理,即进行90度,180度,270度的顺时针旋转以及水平镜像和垂直镜像处理。处理后的rgb-d数据达到75600组,作为训练数据集,用于训练模型。
表1哺乳母猪5类姿态介绍
步骤二的使用相机标定方法获得rgb-d映射关系的方法具体包括:
使用相机标定方法获得rgb图像的内参矩阵为krgb,深度图像的内参矩阵kd,针对同一幅棋盘格图像获得rgb外参矩阵rrgb和trgb,以及深度图像的外参矩阵rd和td,这里棋盘格图像为相机标定所使用的在实验中打印出来的棋盘格图像。令rgb图像的非齐次像素坐标为prgb=[urgb,vrgb,1]t,深度图像的非齐次像素坐标为pd=[ud,vd,1]t。则深度图像坐标映射到rgb图像坐标的旋转矩阵r,平移矩阵t分别为:
故深度图像的像素坐标与rgb图像的像素坐标的映射关系为:
prgb=(r*zd*pd+t)/zrgb
由上式,我们可以通过获取深度图像的坐标值pd和其像素值zd,以及拍摄距离zrgb得到该点映射对应的rgb图像的坐标值prgb。
步骤三的基于fasterr-cnn算法,使用两个cnn网络分别卷积rgb图像和深度图像的方法具体包括:
1)基于fasterr-cnn算法以zf网络为例,网络结构首先使用zf网络结构的一系列的卷积层和maxpooling层来独立地处理这两种数据,提取两种图像数据的特征。其中conv1~conv5以及pool1和pool2组成conv-d,用于提取深度图像特征,conv1_1~conv5_1以及pool1_1和pool2_1组成conv-rgb,用于提取rgb图像特征。conv-d输入为512*424*1的深度图像,输出为33*28大小,通道为256的特征图,conv-rgb输入为960*540*3的rgb图像,输出为61*35大小,通道为256的特征图,输出的特征图如图2所示。
步骤四的仅使用一个rpn网络rgb-d数据特征的roi的方法具体包括:
1)在rpn阶段,双流输出的特征图共享一个rpn网络,即以深度图特征图为基础生成d-roi,并通过rgb-d映射关系,对rgb图像特征图生成rgb-roi。其中对于rpn网络,在每个滑动窗口位置,分别取3种面积尺度{96,192,384}及3种长宽比{1:1,1:3,3:1}的9个锚点。
步骤五的对每一组d-roi和rgb-roi池化为固定大小后进行特征融合的方法具体包括:
1)分别使用两个roi-pooling层(空间金字塔池化层)对生成的不同尺寸的d-roi和rgb-roi以h*w(h,w设置为6)的网格,并采用最大值池化方式,生成固定大小的特征图,即每一个roi特征图均池化为大小为6*6,通道数为256的特征图。
2)在特征融合阶段。定义roi融合层的融合函数f:
拼接融合公式为ycat=fcat(xrgb,xd)。即串联堆叠两个特征图。对相同的空间位置i,j(1≤i≤h,1≤j≤w)在通道上d(1≤d≤d)堆叠,对于两个通道数量为d的特征图,堆叠后输出特征图通道数量为2d:
其中,
步骤六的对融合后的特征使用noc结构的fastr-cnn的方法具体包括:
对融合后的特征在fastr-cnn阶段使用四个卷积层conv6、conv7、conv8与conv9组成的noc结构继续卷积融合后的特征图,以促进融合特征通道间信息的流通,从而进一步抽象出rgb-d数据的特征,再经过全局平均池化层后,最后连接fastr-cnn的分类器和回归器。如图2所示。
步骤七的使用训练集训练双流rgb-dfasterr-cnn模型,测试集测试模型性能,最终筛选最佳性能模型方法具体包括:
使用准备的rgb-d数据库中的训练集进行模型训练,设置图像输入的minibatch为1,冲量为0.9,权值衰减系数为5-4,最大迭代次数为14*105,基础学习率为10-4,衰减步长step为6*105,衰减系数gamma为0.1。在8*105次迭代后,每隔1*105次迭代保存一个模型,选取测试集精度最高的模型作为比较。以最佳的模型作为最终模型。
下面详细说明本发明的实验结果:
本发明采用业界公认的3个评价指标对测试集的母猪姿态识别结果进行统计,并将本文提出的方法与仅使用深度图像的方法(depthimage)、仅使用rgb图像的方法(rgbimage)、将rgb-d简单拼接作为四通道图像输入的前融合方法(rgb-dearlyfusion)以及采用了两个cnn、两个rpn和两个fastr-cnn在对输出结果融合的后融合的方法(rgb-dlaterfusion)比较,其中前融合与后融合中将深度图像分辨率缩放到540*960后与rgb图像配准作为输入,结果如下:
本发明采用ap(averageprecision,平均准确率)、map(meanaverageprecision,平均准确率均值)、识别速度和模型大小进行评价。如下表2所示:
表2模型的识别性能对比
本发明提出的方法在融合了rgb数据和深度图像数据后,对站立、坐立、俯卧、腹卧和侧卧五类姿态的ap(averageprecision,平均准确率)分别达到99.74%、96.49%、90.77%、90.91%和99.45%,五类姿态的map(meanaverageprecision,平均准确率均值)达到95.47%,超过仅使用rgb图像的方法7.11%,超过仅使用深度图像的方法5.36%,超过前融合方法1.55%,超过后融合的方法0.15%。在识别速度达则到12.3fps,能够满足实时性的识别需求。模型大小仅为70.1mb远远小于其他方法,展现出极大的优越性。综上所述,本发明的方法在识别精度和模型大小的性能优越,同时还保持了实时的识别性能。
以上对本发明所提供的一种双流rgb-dfasterr-cnn识别哺乳母猪姿态的方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
- 还没有人留言评论。精彩留言会获得点赞!