一种基于Storm的流数据正则匹配方法与流程
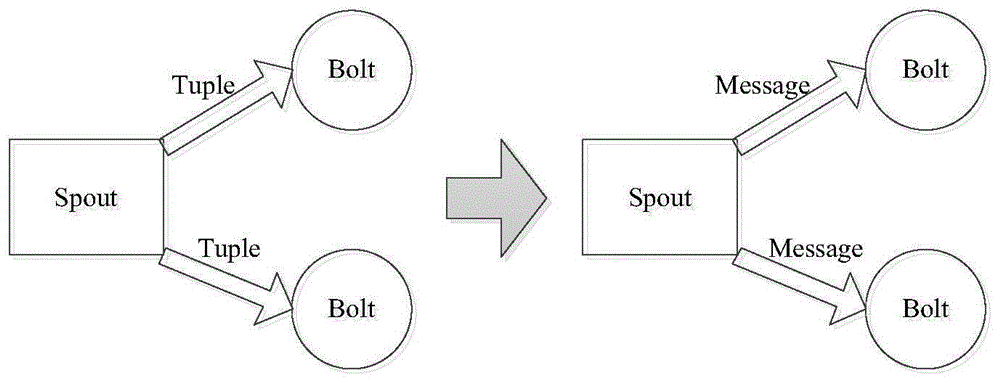
本发明属于计算机
技术领域:
,涉及互联网的数据处理,具体涉及一种基于storm的面向流数据的实时处理的正则匹配技术。
背景技术:
:随着互联网的快速发展,网络信息呈指数级增长,使待检测数据量以及正则表达式的规则数据剧增。同时,在大量网络数据的处理业务中经常需要对如报文等数据进行实时处理,这对正则表达式的匹配技术的实时匹配性能提出了巨大的挑战。目前正则表达式匹配技术的研究主要集中在将其转化为自动机进行匹配时的匹配效率和空间存储两方面,而正则表达式在流数据实时处理中仅能支持简单的模糊匹配筛选,无法满足复杂匹配场景的业务需求。因此,亟待提出一种实时性强的能够支持多种正则匹配规则的技术。storm是twitter开源的分布式实时大数据处理框架,被业界称为实时版hadoop。随着越来越多的场景对hadoop的mapreduce高延迟无法容忍,大数据实时处理解决方案(流计算)的应用日趋广泛,而storm是流计算技术中的佼佼者和主流。storm实现了一个数据流(dataflow)的模型,在这个模型中数据持续不断地流经一个由很多转换实体构成的网络。一个数据流抽象叫做流(stream),流是无限的元组(tuple)序列。元组就像一个可以表示标准数据类型(例如int,float和byte数组)和用户自定义类型的数据结构。每个流由一个唯一的id来标示的,这个id可以用来构建拓扑中各个组件的数据源。技术实现要素:本发明为了提高流数据正则匹配的效率和解决流数据处理中只支持简单正则匹配的问题,提供了一种基于storm的流数据正则匹配方法。一种基于storm的流数据正则匹配技术方法,实现包括如下步骤:步骤1,搭建实时处理集群,实时处理集群中包括kafka集群和storm集群,并部署schemaregisterserver服务;实时处理集群中,kafka作为storm实时处理引擎的数据源,将kafka中topic所对应的数据格式的描述schema注册到schemaregisterserver服务中;实时处理集群按照schema描述的数据格式将原始数据进行序列化,将序列化后的数据进行批量打包到一个message中,将message数据加载到kafka消息队列中;步骤2,利用kafkaspout订阅kafka中某个topic的数据,获取的message数据按序填入storm的单元tuple中,直接将tuple发送给storm的计算算子bolt;步骤3,计算算子bolt从schemaregisterserver中获取kafka中每一个topic对应的数据格式的描述schema,将获取的topic与schema的对应关系放到一个map结构的缓存中;步骤4,计算算子bolt在数据初始化时,对输入的正则匹配表达式生成相应的模式匹配模板;步骤5,计算算子bolt对获得的tuple数据拆包,得到message数据,解包message数据;根据message的数据头,获取该message数据所对应的topic,再获取相应的schema,将message中的数据进行反序列化;计算算子bolt将反序列化后的数据中的有效载荷划分成多个固定长度的块,逐个对每一块根据相应的正则匹配模板进行模式匹配。本发明的优点与积极效果在于:本发明改变了storm集群中数据传输转换方式,采用序列化好的数据进行传输,减少了传输数据量,解决了kafkaspout生成tuple的速度瓶颈,使得整个集群的处理速度得到有效的提升;在各个bolt上进行反序列化,bolt为分布式多点布置并对数据块进行并行处理,提高了反序列化的效率;在数据流进行正则匹配时将数据分块,提高了短而有效数据的正则匹配效率。附图说明图1是本发明对storm的数据处理过程进行改进的示意图;图2是本发明对数据进行正则匹配过程进行改进的示意图;图3是本发明实施例提供的一个实时处理集群的整体系统架构图;图4是本发明实施例中schema初始化的流程图;图5是本发明实施例中进行数据正则匹配处理的流程图。具体实施方式下面将结合附图和实施例对本发明作进一步的详细说明。本发明将storm流处理技术与正则匹配技术相结合,根据storm中tuple处理结构和正则匹配数据包载荷有效结合,可以提高整个流处理集群的处理速度,提升正则表达式匹配的效率。本发明在数据缓存模块中采用kafka消息队列进行缓存数据的存储。storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流,而是时而多时而少。对于这种情况下进行批处理是不合适的,因此引入了kafka作为消息队列,与storm完美配合,这样可以实现稳定的流式计算。kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费大规模的网站中的所有动作流数据,每条发布到kafka集群的消息都有一个类别,这个类别被称为topic。本发明中kafka作为storm实时处理引擎的数据源。本发明将kafka中topic所对应的数据类型的描述schema注册到一个单独的schemaregisterserver服务中。schemaregisterserver代表架构注册服务,提供了对topic对应schema的注册和获取的功能,是数据序列化和反序列化操作的依据。本发明在数据的实时处理中采用storm流数据实时处理引擎,整个storm集群由spout(数据源)和bolt(数据处理)两类算子组成,spout负责数据的输入,bolt负责数据的处理以及输出到指定的数据存储中。使用kafkaspout从kafka集群中消费message(kafka中数据存储的格式)数据,生成tuple(storm中一次消息传递的基本单元)结构数据,然后把tuple数据传递给对应的bolt。在storm集群数据传递的过程中,数据以tuple的形式在各个算子之间传递。在原始的storm处理流程中,kafkaspout中一个tuple对应kafka中的一条message,kafkaspout消费到kafka中的message后,需要对该message按照对应的schema进行反序列化。然后,按照tuple的生成规则,将相应的数据生成一个tuple,并发送给对应的bolt算子。此时,kafkaspout处理kafkamessage生成tuple是一对一的关系。该方式在大规模数据流传输过程中,效率较低。本发明对storm的数据处理过程进行了改进,如图1所示,对数据的传输转换过程进行了优化。kafkaspout消费kafka中的message后并不进行反序列化操作,而是把message批量打包发送给bolt,在bolt中把每一条message按照schema进行反序列化,转换生成tuple结构的数据,然后按照bolt的逻辑处理规则对数据进行处理。在传递过程中的message相比较原生的tuple来说,实现了数据的快速批量处理。这一解决了kafkaspout生成tuple的速度瓶颈,使得整个集群的处理速度得到有效的提升。kafkaspout用来实现strom从kafka中读取数据,本质是实现一个storm中的spout,来读取kafka中的数据,这个spout称为kafkaspout。本发明在数据进行正则匹配时对正则匹配过程进行了改进,如图2所示。图2中,将数据流分块,每块l个字符,并行对一个处理窗口内的每个块依次与一个正则匹配模板进行匹配。计算算子bolt在解析出message中的数据并根据相应的schema进行反序列化后,把数据包的有效载荷划分成多个固定长度的块,逐个地对每一块执行模式匹配。对于每块仅需要较少数量的比较。相对于全量的网络报文数据流,有效的数据量较少,而且需要进行用户行为分析的大部分正则匹配模板都很短。对多个模板的并行匹配,加快了处理速度,减少了指令间的相关性。对于非固定长度的正则表达式模板,通过一个哈希表来尽可能避免对大部分数据包的进一步检查匹配。如此,需要少量的内存来存储经常使用的数据,这些数据存储在高速缓存(cache)中,因此cpu绝大部分时间并不需要访问主内存。内存访问延迟的时间通常是数百倍于cpu时钟周期,由于需要很少的内存访问,从而加快了模式匹配的速度。窗口为storm抽象出来的数据处理的概念,方便做一些统计计算。支持每隔一段时间(slidinginterval)集中处理落在相同窗口下的所有tuples,一个窗口为一个批。窗口长度(windowlength)可以是时间段也可以tuple数量。目前有两种窗口抽象:tumblingwindow:slidinginterval=windowlength这就使得一个tuple只属于一个窗口;slidingwindow:slidinginterval<>windowlength这就使得一个tuple可能属于多个窗口。本发明支持正则表达式中常见的元字符,如下表所示:表1正则表达式中常见的元字符元字符意义及说明^匹配输入字符串开始的位置$匹配输入字符串结尾的位置.匹配除换行符之外的任何单个字符?零次或一次匹配前面的字符或子表达式*零次或多次匹配前面的字符或子表达式+一次或多次匹配前面的字符或子表达式{n}正好匹配n次(n是非负整数){n,}至少匹配n次(n是非负整数){n,m}匹配至少n次,至多m次(n,m是非负整数)\d匹配数字\s匹配任何空白字符\w匹配字母或数字或下划线或汉字a|b或关系,匹配a和b中的任一项即可[abc]字符集合,匹配其中任意一个字符,相当于a|b|c[^abc]反向字符集合,匹配除a、b、c之外的任意一个字符[a-z]字符范围,匹配指定范围内的任何字符[^a-z]反向字符范围,匹配不在指定范围内的任何字符\转义符号(正则表达式)使用()可以对表达式进行分组本发明支持对数据块进行将元字符灵活组合实现的功能有:任意数字匹配,字符串开始或结束匹配,单词的开始或结束匹配,重复匹配,字符集匹配,或逻辑运算匹配,反义匹配,对分组的向后引用、零宽断言、负向零宽断言匹配等。下面说明本发明实施例实现的一种基于storm的流数据正则匹配方法,具体如步骤一至步骤五所示。步骤一、实时处理集群的搭建。集群搭建如图3所示的本发明所依赖的整体分布式架构,包括zookeeper,kafka集群和storm集群,并部署schemaregisterserver服务。zookeeper是一个主要负责分布式系统的协调服务。在系统启动后将kafka中topic与数据描述schema注册到schemaregisterserver服务中,根据schemaregisterserver服务中的schema进行数据的加载。消息可以通过各种方式进入到kafka消息中间件,比如可以通过使用日志收集系统flume作为数据的生产者(consumer)来收集网络或日志数据,然后在kafka中路由暂存。按照schema描述的数据格式将原始数据进行序列化,将序列化后的数据进行批量打包,打包到一个message中,将message数据加载到kafka消息队列中。步骤二、利用kafkaspout订阅kafka中某个topic的数据,获取的message数据按序填入tuple基本单元中,将message直接组成tuple中的值列表valuelist,直接发送给storm集群中的计算算子bolt。步骤三、schema初始化,如图4所示,该步骤在整个系统初始化时进行。计算算子bolt从schemaregisterserver中获取kafka中每一个topic对应的数据格式的描述schema,将获取的topic与schema的对应关系放到一个map结构的缓存中,已供后续数据处理过程中进行数据的反序列化。步骤四、在storm数据实时处理的算子bolt中,在数据初始化时对输入的正则匹配表达式进行分析,并生成相应的模式匹配模板,以待后续进行正则模式匹配应用。步骤四在整个系统初始化时进行。步骤五、进行数据正则匹配处理,如图5所示,计算算子bolt拿到message组成的valuelist的tuple数据,将数据拆包拿到message数据。解包message数据,获取该message中的数据和数据头。根据message数据的数据头,获取该message数据所对应的topic。再根据该topic获取相应的schema,将message中获取的数据进行反序列化。将反序列化后的数据根据信息的有效性进行分块,每一块根据相应的正则匹配模板进行正则匹配的处理。该步骤会在storm实时处理集群中的bolt算子中进行分布式的实时处理。对反序列化后的数据进行分块,块的大小可以根据时间和字节长度两个条件来进行设置。本发明提供的一个实例为,块大小的时间间隔设置为500ms,字节长度设置为1024个字节,当时间间隔为500ms或字节长度达到1024个字节时则划分为一个块。显然,所描述的实施例也仅仅是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员能够对上述详细描述的本发明做出各种修改和改进,在不脱离权利要求所要求的本发明的精神和范围的情况下,都属于本发明保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1