一种无资料地区场次洪水径流过程反演的方法与流程
本发明涉及水文资料整理技术领域,尤其涉及一种无资料地区场次洪水径流过程反演的方法。
背景技术:
研究水库调度、水资源管理、水文预报等问题,获取无资料地区场次洪水径流过程是必不可少的步骤之一。
目前,广泛使用的无资料地区水文获取的方法包括水文拟法、径流系数法以及水文模型法。水文比拟法将气候地理等条件类似的参证流域水文资料移用至设计流域,方法简便易行,但是只能计算径流总量。径流等值线法利用水文参数等值线图或流域分区图求得水文变量值或特征值,这种方法操作上也比较简便,但是也只能计算径流总量。水文模型法能够计算出径流过程,但是其中水文模型参数率定利用参证站的降雨径流数据,然后根据无资料地区与参证流域的气候下垫面条件等异同调整参数,没有对无资料地区进行降雨径流模拟验证。
然而,流域产汇流规律极其复杂,单纯依靠参证流域与无资料地区的在气候条件和下垫面条件的异同,而通过简单的调整参证流域的产汇流参数,并将其作为无资料地区的参数进行计算,会出现较大的误差。
技术实现要素:
本发明的目的在于提供一种无资料地区场次洪水径流过程反演的方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
一种无资料地区场次洪水径流过程反演的方法,包括如下步骤:
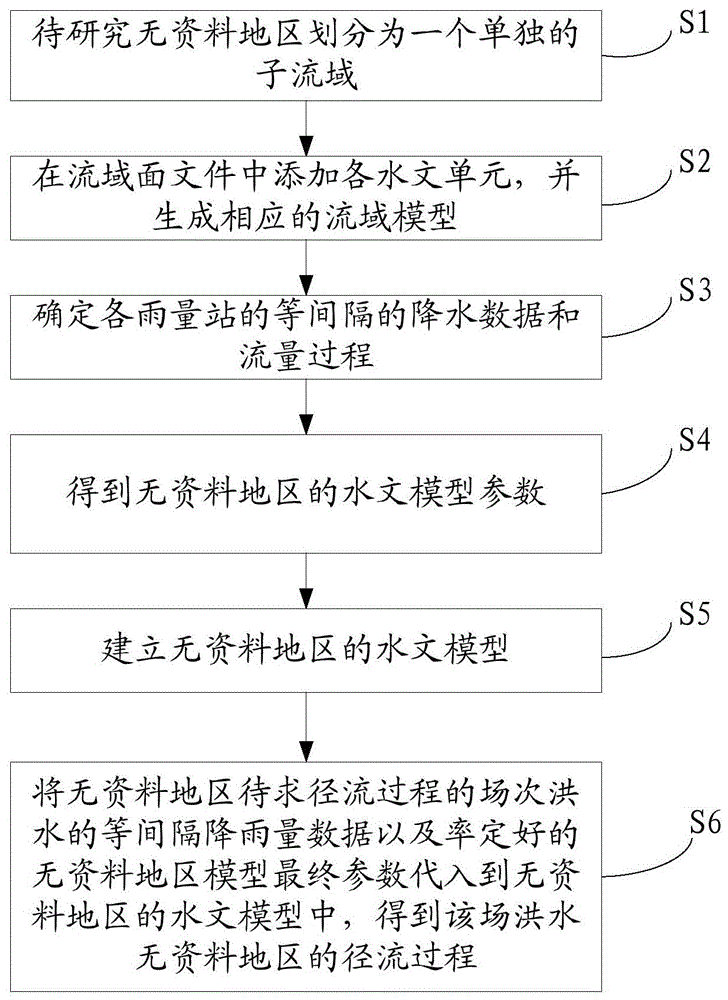
s1,在gis图层中,将待研究无资料地区划分为一个单独的子流域;
获取水文站点以上流域各雨量站场次洪水的降水过程以及流域出口断面相应场次洪水的流量过程,并把降水过程和流量过程由不等间隔时间序列转化为等间隔时间序列;
s2,在流域面文件中添加各水文单元,并生成相应的流域模型,确定对应的计算方法;
s3,根据s1中得到的各雨量站的等间隔的降水数据,采用空间插值方法确定子流域的降雨过程,将s1中得到的等间隔的流量过程作为场次洪水的流量过程;
s4,根据s3中得到的流域的降雨过程以及场次洪水的流量过程,估算出无资料地区下游水文站以上流域的水文模型参数,并根据该参数得到无资料地区的水文模型参数;
s5,根据无资料地区水文模型的参数建立无资料地区的水文模型;
s6,将无资料地区待求径流过程的场次洪水的等间隔降雨量数据以及率定好的无资料地区模型最终参数代入到无资料地区的水文模型中,得到该场洪水无资料地区的径流过程。
优选地,s1中,所述在gis图层中,将待研究无资料地区划分为一个单独的子流域,具体为:获取待研究无资料地区下游水文站点,以及该水文站点的经纬度信息、水文站点以上流域内雨量站点的经纬度信息,并将这些点位信息通过gis软件点绘在图层中将其制成面文件;收集水文站点以上流域范围的dem图,并将该文件类型转化为栅格文件类型,在gis软件中加载geohms工具条,将该栅格文件通过geohms工具进行水文分析,得到目标流域的按照自然流域划分的流域面文件,其中,待研究无资料地区划分为一个单独的子流域。
优选地,s1中,所述水文分析包括:填洼、生成流向、计算累积流、定义河流、河流分段、集水区划分、集水区多边形处理、排水线处理、流域聚合、提取目标流域。
优选地,s1中,所述等间隔时间序列的时段长度根据降雨径流特性确定,湿润半湿润地区,时段长度为1小时。
优选地,s2中,所述在流域面文件中添加的水文单元包括水源、河段、汇流点、水库,对于水源单元确定的计算方法包括:产流计算的方法、汇流计算的方法;对于河段单元确定的计算方法为洪水演进的方法;对于水库单元确定的计算方法为水库的蓄泄关系;对于汇流点确定的计算方法为其上下相连接的水文单元。
优选地,s3中,所述空间插值方法包括泰森多边形法、距离倒数平方法。
优选地,s4具体为:
s401,根据参数的物理意义及经验确定一个参数的初始值;
s402,确定定量描述模型计算结果与实测流量拟合优度的目标函数;
s403,通过优化方法确定目标函数的最小值,通过优化计算得出水文站点以上流域的水文模型参数,找出在该水文模型中作为子流域单元的无资料地区的产汇流计算方案以及方案的参数,该参数即为无资料地区的水文模型的参数。
优选地,s402中,所述目标函数选择峰值加权均方根误差函数、残差平方和函数、残差绝对值函数或峰值流量百分比误差函数,s403中,优化方法选择遗传算法或粒子群算法。
本发明的有益效果是:本发明提供的无资料地区场次洪水径流过程反演的方法,通过自然流域分割的方法,将无资料地区划分为一个单独的子流域,通过对无资料地区下游水文站以上流域降雨径流过程的模拟率定,获得无资料地区的水文模型参数,构建了无资料地区的水文模型,并通过将无资料地区待求径流过程的场次洪水的等间隔降雨量数据以及率定好的无资料地区模型最终参数代入到无资料地区的水文模型中,得到该场洪水无资料地区的径流过程。所以,采用本发明提供的方法,在掌握资料较少的情况下通过简单操作就可以得到较高精度的场次洪水的径流过程。
附图说明
图1是本发明实施例提供的无资料地区场次洪水径流过程反演的方法流程示意图;
图2是无资料地区流域示意图;
图3是无资料地区在其下游水文站以上流域所占位置示意图;
图4是无资料地区下游站点a站以上流域1989年5月6号20时至1989年5月21日8时时间步长为1小时的降雨径流过程示意图;
图5是无资料地区概化流域模型图;
图6是无资料地区的场次洪水径流过程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明提供了一种无资料地区场次洪水径流过程反演的方法,包括如下步骤:
步骤一,资料收集与处理
寻找该无资料地区下游水文站点,搜集该水文站点的经纬度信息及其以上流域dem图,以及流域内雨量站点的经纬度信息,并将这些点位信息通过gis软件点绘在图层中将其制成面文件,文件名记为gagestation.shap;收集水文站点以上流域范围的dem图,并将该文件类型转化为栅格文件类型,在gis软件中加载geohms工具条,将该栅格文件通过geohms工具进行水文分析,经过填洼、生成流向、计算累积流、定义河流、河流分段、集水区划分、集水区多边形处理、排水线处理、流域聚合、提取目标流域等操作,得到目标流域的按照自然流域划分的流域图面文件,通过流域分割的方法将无资料区划分为一个单独的子流域,流域面文件记为model.shape。
收集水文站点以上流域各雨量站场次洪水的降水过程以及流域出口断面相应场次洪水的流量过程,并把降水过程和流量过程由不等间隔时间序列转化为等间隔时间序列,时段长度根据降雨径流特性而定,一般湿润半湿润地区,时段长度取1小时。
步骤二,生成流域模型
在流域面文件中添加水源、河段、汇流点、水库等水文单元,生成流域模型,并且为不同的水文单元选择不同的计算方法。如对于子流域水源单元需要确定产流计算的方法、汇流计算的方法;对于河段单元需要确定洪水演进的方法;对于水库单元需要确定水库的蓄泄关系;对于汇流点需要确定其上下相连接的水文单元。
步骤三,确定子流域的降雨过程以及流域出口断面的流量过程
各子流域的降雨过程需根据s1中得到的各雨量站的等间隔的降水数据选择一定的空间插值方法确定,比如泰森多边形法、距离倒数平方法等。场次洪水的流量过程取s1中等到的等间隔的流量过程。
步骤四,无资料地区水文模型参数估算方法
参数估算时首先估算出无资料地区下游水文站以上流域的水文模型参数,进而得到无资料地区的水文模型参数从而建立无资料地区的水文模型。具体做法是:在确定无资料地区下游水文站以上流域水文模型参数时,首先根据参数的物理意义及经验确定一个参数的初始值,然后确定定量描述模型计算结果与实测流量拟合优度的目标函数,可以选择峰值加权均方根误差函数、残差平方和函数、残差绝对值函数、峰值流量百分比误差函数等,然后通过遗传算法或粒子群算法等优化方法确定目标函数的最小值,通过优化计算得出水文站点以上流域的水文模型参数找出在该水文模型中作为子流域单元的无资料地区的产汇流计算方案以及方案的参数,该参数即为无资料地区的水文模型的参数,从而建立无资料地区的水文模型。
步骤五,无资料地区径流过程反演
将无资料地区待求径流过程的场次洪水的等间隔降雨量数据以及率定好的无资料地区模型最终参数代入到无资料地区的水文模型中,推求该场洪水无资料地区的径流过程。
具体实施例
本实施例以湖北澴河流域花园水文站以上无资料地区w160场次洪水降雨径流过程为实例,以表现本发明达到的效果。
澴河流域位于湖北省长江以北,大别山南麓,江汉平原北部的孝感市地区,流域界于东经113°72'~114°33',北纬30°86'~31°89'之间。干流全长8km,流域面积2590.88km2。流域地势东北高西南低,溶蚀低山与切割丘陵互为穿插。地貌以丘陵山地为主,东北部为低山区,海拔500~1000米,相对高度在100~300米,西南部低矮缓丘,海拔在100~500米。流域有7个雨量站记为a站、b站、c站、d站、e站、f站、和g站;流域出口断面所在的水文站为a站。无资料地区为其子流域w160,其流域面积为193.04平方公里。实施例以起止时间为1989年5月6日20时至1989年5月21日8时,时间步长为1小时的a水文站以上流域雨量站a、b、c、d、e、f、g降雨量系列和a水文站的流量系列作为基础降雨径流数据,计算无资料地区w160径流过程。本实施例中,可以按照如下步骤实施无资料地区径流过程反演:
步骤一:收集无资料地区下游水文站(a站)经纬度信息,以及该站以上流域雨量站(b、c、d、e、f、g雨量站)的经纬度信息,并将这些点通过gis软件点绘在图层中将其制成面文件,文件名记为gagestation.shap;收集a站以上流域的dem图,并将该文件类型转化为栅格文件类型,在gis软件中通过水文分析工具经过填洼、生成流向、计算累积流、定义河流、河流分段、集水区划分、集水区多边形处理、排水线处理、流域聚合、提取目标流域等操作,得到a站以上流域的按照自然流域划分的流域图面文件,通过流域分割的方法将无资料区划分为一个单独的子流域w160,无资料地区流域图见图2,w160在其下游水文站以上流域所占位置见图3。
收集a站以上流域各雨量站1989年5月6日20时至1989年5月21日8时的降水过程以及流域出口断面相应场次洪水的流量过程,并把降水过程和流量过程由不等间隔时间序列转化为时间步长为1小时的降水过程和流量过程,见图4。
步骤二:在a站以上流域面文件中添加水源、河段、汇流点、水库等水文单元,生成流域模型,确定子流域单元的产流计算方法为初始常速率法、汇流计算的方法为斯奈德单位线法;河段单元洪水演进的方法为马斯京根法。
步骤三:通过泰森多边形法计算各子流域的降雨过程。
步骤四:参数估算时先根据参数的物理意义及经验确定参数的初始值,选择残差平方和函数作为优化函数,通过经典遗传算法确定目标函数的最小值,通过多场洪水的降雨径流数据做基础数据对a站以上流域的水文模型进行参数率定,通过优化计算得出水文站点以上流域的水文模型综合最优参数,找出在该水文模型中作为子流域单元的无资料地区的产汇流计算方案以及方案的参数,该参数即为无资料地区的水文模型的参数,从而建立无资料地区的水文模型。本例中无资料地区概化的流域模型见图5,无资料地区的产汇流方案分别为产流计算方法为初始常速率法、汇流计算的方法为斯奈德单位线法。
步骤五:无资料地区w160径流过程反演
将1989年5月6日20时至1989年5月21日8时的降水过程输入到在步骤四中得到的无资料地区的水文模型中,得到无资料地区w160流域出口断面的径流过程见图6。
从图6可以看出:通过上述方法,可以详尽地得出该无资料地区19890506号洪水的完整径流过程。
所以,采用本发明提供的方法,在掌握资料较少的情况下通过简单操作就可以得到较高精度的场次洪水的径流过程。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:本发明提供的无资料地区场次洪水径流过程反演的方法,通过自然流域分割的方法,将无资料地区划分为一个单独的子流域,通过对无资料地区下游水文站以上流域降雨径流过程的模拟率定,获得无资料地区的水文模型参数,构建了无资料地区的水文模型,并通过将无资料地区待求径流过程的场次洪水的等间隔降雨量数据以及率定好的无资料地区模型最终参数代入到无资料地区的水文模型中,得到该场洪水无资料地区的径流过程。所以,采用本发明提供的方法,在掌握资料较少的情况下通过简单操作就可以得到较高精度的场次洪水的径流过程。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!