一种基于深度学习模型的OCR识别方法及终端与流程
本发明涉及一种基于深度学习模型的ocr识别方法及终端,属于数据处理领域。
背景技术:
ocr识别是指电子设备,例如扫描仪或数码相机,获取影像,然后用字符识别方法检测影像上的字符区域并将其翻译成计算机文字的过程。字符识别领域中,字符的描述特征很大程度上决定了ocr识别的精度和速度。
常用的ocr识别方法有如下几种:
第一种,传统的ocr识别方法,先将字符片段图像分割成单字符图像,再利用二值图像识别方法或灰度图像识别方法分别对各个单字符图像进行识别。基于二值图像的ocr识别方法受前期预处理的影响较大,适合字符清晰无干扰的字符影像,但是对于打印票据或其他印刷品常常出现墨渍不均匀、字不清晰的情况,二值化方法受干扰影响较大,识别准确度较低。基于灰度图像的识别方法,常采用不同的特征算子,例如hog和gabor,对图像进行卷积运算,然后将抽取的图像像素点作为字符的描述特征,但是拍摄的光照变化,文档的印章、底纹、线条、污渍等干扰会改变字符图像的灰度信息,在存在干扰的情况下,识别准确度较低。
第二种,基于深度学习模型的ocr识别方法。现有的基于深度学习模型的ocr识别方法,直接将整个字符片段图像输入到深度学习模型进行识别,由于整个字符片段图像所包含的干扰因素较多,当干扰程度较重时,会影响深度学习模型识别的准确性。
技术实现要素:
本发明所要解决的技术问题是:如何提高ocr识别字符的抗干扰能力。
为了解决上述技术问题,本发明采用的技术方案为:
本发明提供一种基于深度学习模型的ocr识别方法,包括:
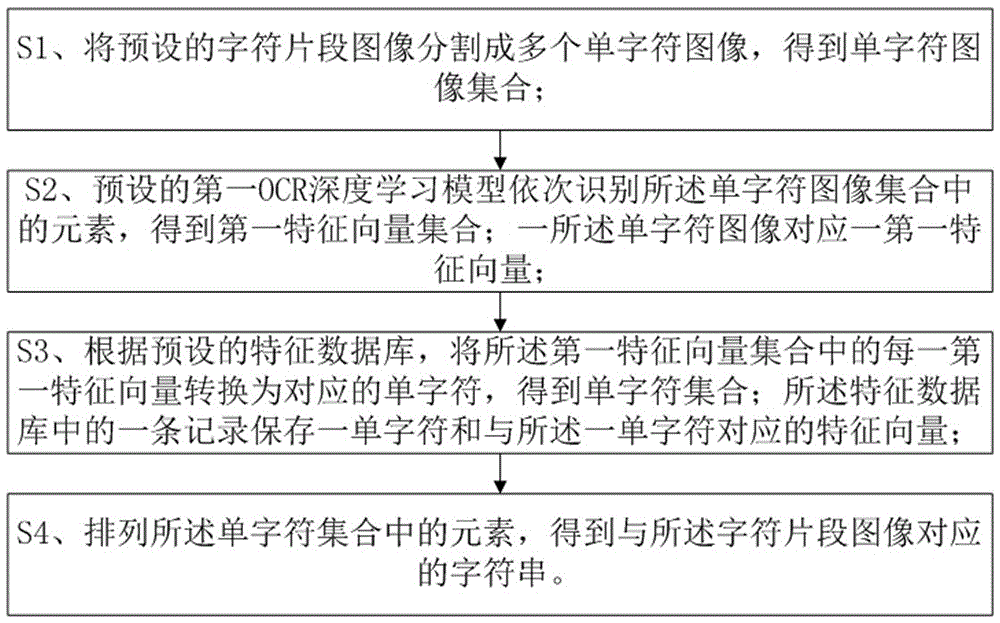
s1、将预设的字符片段图像分割成多个单字符图像,得到单字符图像集合;
s2、预设的第一ocr深度学习模型依次识别所述单字符图像集合中的元素,得到第一特征向量集合;一所述单字符图像对应一第一特征向量;
s3、根据预设的特征数据库,将所述第一特征向量集合中的每一第一特征向量转换为对应的单字符,得到单字符集合;所述特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量;
s4、排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
进一步地,所述s2之前,还包括:
s51、从所述单字符图像集合中获取一单字符图像,得到第一单字符图像;
s52、获取所述第一单字符图像的长宽比例;
s53、将所述第一单字符图像的最长边缩放至预设的像素,并根据所述长宽比例缩放所述第一单字符图像中除所述最长边之外的其它边,得到第二单字符图像;
s54、当所述第二单字符图像中存在边长小于所述预设的像素的边时,使用所述第一单字符图像的背景图像填充所述第二单字符图像,得到第三单字符图像;所述第三单字符图像的长和宽均为所述预设的像素;
s55、重复执行s51至s54,直至所述单字符图像集合被遍历。
进一步地,所述s2之前,还包括:
s61、从预设的第一训练样本集中获取一样本;
s62、预设的第二ocr深度学习模型识别所述一样本,得到第二特征向量;
s63、根据预设的损失函数计算所述第二特征向量的损失值;
s64、根据所述损失值调整所述第二ocr深度学习模型的参数;
s65、重复执行s61至s64,直至所述第一训练样本集被遍历,得到所述第一ocr深度学习模型;
所述预设的损失函数,具体为:
其中,
进一步地,所述s3之前,还包括:
获取与第四单字符对应的预设数量样本,得到第二训练样本集;
所述第一ocr深度学习模型识别所述第二训练样本集,得到第三特征向量集合;
获取与所述第三特征向量集合对应的平均特征向量;
添加所述第四单字符和所述平均特征向量至所述特征数据库。
进一步地,所述s4具体为:
获取所述单字符图像集合中每一所述单字符图像在所述字符片段图像中的坐标,得到坐标信息;
根据所述坐标信息排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
本发明还提供一种基于深度学习模型的ocr识别终端,包括一个或多个处理器及存储器,所述存储器存储有程序,并且被配置成由所述一个或多个处理器执行以下步骤:
s1、将预设的字符片段图像分割成多个单字符图像,得到单字符图像集合;
s2、预设的第一ocr深度学习模型依次识别所述单字符图像集合中的元素,得到第一特征向量集合;一所述单字符图像对应一第一特征向量;
s3、根据预设的特征数据库,将所述第一特征向量集合中的每一第一特征向量转换为对应的单字符,得到单字符集合;所述特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量;
s4、排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
进一步地,所述s2之前,还包括:
s51、从所述单字符图像集合中获取一单字符图像,得到第一单字符图像;
s52、获取所述第一单字符图像的长宽比例;
s53、将所述第一单字符图像的最长边缩放至预设的像素,并根据所述长宽比例缩放所述第一单字符图像中除所述最长边之外的其它边,得到第二单字符图像;
s54、当所述第二单字符图像中存在边长小于所述预设的像素的边时,使用所述第一单字符图像的背景图像填充所述第二单字符图像,得到第三单字符图像;所述第三单字符图像的长和宽均为所述预设的像素;
s55、重复执行s51至s54,直至所述单字符图像集合被遍历。
进一步地,所述s2之前,还包括:
s61、从预设的第一训练样本集中获取一样本;
s62、预设的第二ocr深度学习模型识别所述一样本,得到第二特征向量;
s63、根据预设的损失函数计算所述第二特征向量的损失值;
s64、根据所述损失值调整所述第二ocr深度学习模型的参数;
s65、重复执行s61至s64,直至所述第一训练样本集被遍历,得到所述第一ocr深度学习模型;
所述预设的损失函数,具体为:
其中,
进一步地,所述s3之前,还包括:
获取与第四单字符对应的预设数量样本,得到第二训练样本集;
所述第一ocr深度学习模型识别所述第二训练样本集,得到第三特征向量集合;
获取与所述第三特征向量集合对应的平均特征向量;
添加所述第四单字符和所述平均特征向量至所述特征数据库。
进一步地,所述s4具体为:
获取所述单字符图像集合中每一所述单字符图像在所述字符片段图像中的坐标,得到坐标信息;
根据所述坐标信息排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
本发明具有如下有益效果:
1、本发明提供一种基于深度学习模型的ocr识别方法,先将字符片段图像分割成多个单字符图像,从而实现将字符片段图像中的印章、线条、光照、图像模糊等干扰因素碎片化,降低干扰因素对字符识别准确度的影响。再使用本发明提供的第一ocr深度学习模型依次识别每个单字符图像,得到与每个单字符图像对应的识别结果。由于本发明提供的第一ocr深度学习模型是通过大量存在不同类型、不同程度干扰的单字符图像样本训练得到的,具有较好的抗干扰能力,较高的识别准确度。区别于现有技术1使用深度学习模型直接识别整个字符片段图像,本发明的深度学习模型一次只识别一个单字符图像,其待识别单字符图像本身携带的干扰因素较之整个字符片段图像中的干扰因素相比较小,且本发明的深度学习模型是使用单字符图像训练样本训练得到的,较之使用整个字符片段图像样本训练得到的深度学习模型,具有更高的识别准确度。区别于现有技术2将字符片段图像分割成单字符图像后,直接使用二值化或灰度图像识别方法识别单字符图像,由于二值化和灰度图像识别方法均不适用于具有干扰因素的应用场景,本发明提供的基于深度学习模型的ocr识别方法能够更准确地识别出带干扰因素的字符片段图像对应的字符串。综上所述,本发明提供的基于深度学习模型的ocr识别方法及终端具有较强的抗干扰能力和较高的识别准确度,尤其适用于合同、表格、票据等纸质文档在电子数据化过程中,印章底纹、拍摄光照、图像模糊等外部环境变化较大的应用场景。
2、进一步地,本发明在将单字符图像送入深度学习模型之前,先将所有待识别的单字符图像尺寸进行归一化处理,使得待识别的单字符图像与训练样本的单字符图像尺寸相同,有利于减小尺寸因素对识别准确度的干扰。在尺寸归一化的过程中,本发明保持原单字符图像的长宽比例不变,使用背景图像填充不足部分,有效保证了待识别的单字符图像保持原来的特征,避免单字符图像扭曲变形带来的干扰。同时,使用背景图像填充不足之处,有利于避免单字符图像的空白部分被误识别成有意义的像素,减少背景对ocr字符识别的干扰,提高ocr字符识别的准确度。
3、进一步地,本发明摒弃使用ocr字符识别领域常用的损失函数softmax,softmax只在欧式空间里学习特征,只考虑样本是否能正确分类,而不考虑类内和类间的距离,即不能优化特征使得同一字符对应的不同形式样本得到高相似度,不同字符之间的样本得到低相似度。本发明提供的损失函数直接关注特征的角度可分性,认为设置分类间隔以缩小类内间距,拉大类间距离,使得同一字符对应的不同形式样本相似度高,不同字符之间的样本相似度低,使得训练第一深度学习模型过程中可以更加精准地调整模型参数,增强第一深度学习模型的拟合性,提高第一深度学习模型的准确度。
4、进一步地,由于每一个单字符的字体、字号、光照、背景等干扰因素不同,使用同一深度学习模型识别同一单字符对应的不同形式样本得到的特征向量有略微差别。本发明为了提高深度学习模型识别单字符图像的准确度,使用由同一个单字符对应的不同形式样本的平均特征向量作为该单字符的特征模板,特征模板描述该单字符的典型特征,并使用各单字符的特征模板与深度学习模型实时识别到的特征向量进行比较,从而挑选出相似度最高的单字符,极大程度上降低了不同字体、字号、光照、背景等因素对深度学习模型识别准确度的影响。
5、进一步地,根据各个单字符图像在同一字符片段图像中的相对坐标排列深度学习模型识别到的单字符,能够得到与字符片段图像相同的字符串。
附图说明
图1为本发明提供的一种基于深度学习模型的ocr识别方法的具体实施方式的流程框图;
图2为单字符图像示意图;
图3为另一单字符图像示意图;
图4为本发明提供的一种基于深度学习模型的ocr识别终端的具体实施方式的结构框图;
标号说明:
1、处理器;2、存储器。
具体实施方式
下面结合附图和具体实施例来对本发明进行详细的说明。
请参照图1至图4,
本发明的实施例一为:
如图1所示,本实施例提供一种基于深度学习模型的ocr识别方法,包括:
s1、将预设的字符片段图像分割成多个单字符图像,得到单字符图像集合。
其中,本实施例采用开源的深度学习目标检测模型rfcn训练检测票据图像的单字符位置,得到票据图像上每个字符外接矩形框的左上角和右下角坐标。根据每个字符对应的坐标信息,从原票据图像中剪切得到多个单字符图像。
例如,一个字符片段图像中包含字符片段“增值税发票”,通过目标检测模型识别到每一个字符的坐标,并根据每一个字符的坐标分割该字符片段图像,得到“增”、“值”、“税”、“发”和“票”五个单字符图像。
s2、归一化所述单字符图像集合中每一单字符图像的尺寸。具体为:
s21、从所述单字符图像集合中获取一单字符图像,得到第一单字符图像;
s22、获取所述第一单字符图像的长宽比例;
s23、将所述第一单字符图像的最长边缩放至预设的像素,并根据所述长宽比例缩放所述第一单字符图像中除所述最长边之外的其它边,得到第二单字符图像;
s24、当所述第二单字符图像中存在边长小于所述预设的像素的边时,使用所述第一单字符图像的背景图像填充所述第二单字符图像,得到第三单字符图像;所述第三单字符图像的长和宽均为所述预设的像素;
s25、重复执行s21至s24,直至所述单字符图像集合被遍历。
其中,所述预设的像素为64。经大量实验,当单字符图像尺寸太小时保留图像信息不足,识别字符的准确度较差。当单字符图像尺寸太大时,提取特征速度慢。本实施例将单字符图像的尺寸归一化为64像素*64像素,不仅能够满足识别字符所需的特征信息,而且能够加快特征提取的速度,节约显存空间。尺寸归一化后的多个单字符图像如图2所示。图2中的方框边长为64像素,若方框中存在空白区域,直接使用单字符图像的背景填充方框。
本实施例在将单字符图像送入深度学习模型之前,先将所有待识别的单字符图像尺寸进行归一化处理,使得待识别的单字符图像与训练样本的单字符图像尺寸相同,有利于减小尺寸因素对识别准确度的干扰。在尺寸归一化的过程中,本发明保持原单字符图像的长宽比例不变,使用背景图像填充不足部分,有效保证了待识别的单字符图像保持原来的特征,避免单字符图像扭曲变形带来的干扰。同时,使用背景图像填充不足之处,有利于避免单字符图像的空白部分被误识别成有意义的像素,减少背景对ocr字符识别的干扰,提高ocr字符识别的准确度。
s3、获取第一ocr深度学习模型。具体为:
s31、从预设的第一训练样本集中获取一样本;
s32、预设的第二ocr深度学习模型识别所述一样本,得到第二特征向量;
s33、根据预设的损失函数计算所述第二特征向量的损失值;
s34、根据所述损失值调整所述第二ocr深度学习模型的参数;
s35、重复执行s31至s34,直至所述第一训练样本集被遍历,得到所述第一ocr深度学习模型;
所述预设的损失函数,具体为:
其中,
s,m,n,n为固定值,w为深度学习的权重参数,初始赋予随机数或预训练模型参数。x为当前样本的特征向量,yi为当前样本的实际类别,对于输入的特征向量x,预测为正确类别的概率值为cosθyi,预测为其他类别的概率值为(cosθj),当预测的值越接近真实类别时,cosθyi越大,代入公式,则loss的值越接近于0;反之,loss越大,即代表当前样本与预测的类别差距越大。
本实施例,引入惩罚系数,即类别间距m,来使类内距离变小,类外距离变大,以提升识别单字的准确率。
其中,本实施例的第二ocr深度学习模型为用于中英文字符识别的arcface深度学习模型。arcface深度学习模型的网络主干采用34层残差卷积网络(resnet34),输出为512维的特征向量;然后接入1*class_number的全连接层,class_number表示字符的类别数。将尺寸归一化后的单字符图像送入训练好的第一深度学习模型,经过卷积运算,提取单字符特征,最后输出高维的特征向量,该特征向量就是描述输入的单字符图像的一种数学表达方式。
本实施例收集涵盖国标gb2312一二级字库的字符样本,主要是票据文档,送入s1和s2,得到的单字符图像样本按8:2的比例分成训练集和测试集,用第二ocr深度学习模型进行训练,得到能正确表达单字类别特征的第一ocr深度学习模型。测试样本集测试准确率为99.9%。
损失函数是一种用于衡量损失和错误的函数。损失函数的计算结果表示深度学习网络识别一单字符图像得到的字符与该单字符图像真实表示的字符之间的差异值。
本实施例摒弃使用ocr字符识别领域常用的损失函数softmax,softmax只在欧式空间里学习特征,只考虑样本是否能正确分类,而不考虑类内和类间的距离,即不能优化特征使得同一字符对应的不同形式样本得到高相似度,不同字符之间的样本得到低相似度。本发明提供的损失函数直接关注特征的角度可分性,认为设置分类间隔以缩小类内间距,拉大类间距离,使得同一字符对应的不同形式样本相似度高,不同字符之间的样本相似度低,使得训练第一深度学习模型过程中可以更加精准地调整模型参数,增强第一深度学习模型的拟合性,提高第一深度学习模型的准确度。
s4、创建特征数据库;所述特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量。具体为:
s41、获取与第四单字符对应的预设数量样本,得到第二训练样本集。
s42、所述第一ocr深度学习模型识别所述第二训练样本集,得到第三特征向量集合。
s43、获取与所述第三特征向量集合对应的平均特征向量。
s44、添加所述第四单字符和所述平均特征向量至所述特征数据库。
s45、重复执行s41至s42,直至所有的预设第四单字符集合被遍历。
其中,所述预设数量不少于10。
由于每一个单字符的字体、字号、光照、背景等干扰因素不同,使用同一深度学习模型识别同一单字符对应的不同形式样本得到的特征向量有略微差别。本实施例为了提高深度学习模型识别单字符图像的准确度,使用由同一个单字符对应的不同形式样本的平均特征向量作为该单字符的特征模板,特征模板描述该单字符的典型特征,并使用各单字符的特征模板与深度学习模型实时识别到的特征向量进行比较,从而挑选出相似度最高的单字符,极大程度上降低了不同字体、字号、光照、背景等因素对深度学习模型识别准确度的影响。
例如,第四单字符“利”对应的第二训练样本集中包括不同字体的“利”字图像、不同字号的“利”字图像、不同光照强度下拍摄或扫描的“利”字图像、印在不同背景图像上的“利”字图像等。由于各样本之间存在差异,第一ocr深度学习模型对不同的“利”样本进行识别,得到的第三特征向量有略微的差别。将所有“利”对应的第三特征向量进行平均化,得到平均特征向量。平均特征向量能够去除不同样本“利”之间的差异特征,保留“利”的典型特征。即使第一ocr深度学习模型当前所要识别的“利”字图像存在的干扰情况在之前的训练样本中未出现过,也能够通过具有“利”字典型特征的平均特征向量准确匹配。
s5、预设的第一ocr深度学习模型依次识别所述单字符图像集合中的元素,得到第一特征向量集合;一所述单字符图像对应一第一特征向量。
其中,第一ocr深度学习模型识别一单字符图像所得到的第一特征向量能够反映出该单字符图像的特征。
例如,图3所示的单字符图像对应的特征向量是一个512维的浮点型向量[0.152485,0.846521,0.745145,…………,0.547854,0.879466,0.914724,0.007963]。
s6、根据预设的特征数据库,将所述第一特征向量集合中的每一第一特征向量转换为对应的单字符,得到单字符集合。
其中,特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量。将当前第一ocr深度学习模型识别得到的第一特征向量与特征数据库中的每一特征向量计算相似度,具有最高相似度的特征向量对应的单字符即为第一ocr深度学习模型识别一单字符图像的识别结果。可选地,采用余弦距离作为两个特征向量之间的相似度。
s4、排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。具体为:
获取所述单字符图像集合中每一所述单字符图像在所述字符片段图像中的坐标,得到坐标信息;
根据所述坐标信息排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
例如,一个字符片段图像中包含“增值税发票”,分别获取能包含每一个字的最小方框的左上角坐标,根据每一单字符图像的左上角坐标排列字符“增”、“值”、“税”、“发”和“票”。根据各个单字符图像在同一字符片段图像中的相对坐标排列深度学习模型识别到的单字符,能够得到与字符片段图像相同的字符串。
通过本实施例提供的基于深度学习模型的ocr识别方法获取单字特征,相较于传统ocr识别方法获取的单字特征,具有更优秀的表达能力和鲁棒性,能够适应文字的底纹印章、线条、污渍、光照、墨渍不均等干扰。实验取10000个票据图像的单字样本,这些样本较多由于墨渍不均出现模糊、断线、印章、线条干扰等问题,分别使用现有的识别方法abbyy和本实施例提供的方法进行识别,其中abbyy识别准确率为97.8%,本实施例提供的方法的准确率为99.2%。本实施例提供的ocr识别方法具有较强的抗干扰能力和较高的识别准确度。
本实施例提供一种基于深度学习模型的ocr识别方法,先将字符片段图像分割成多个单字符图像,从而实现将字符片段图像中的印章、线条、光照、图像模糊等干扰因素碎片化,降低干扰因素对字符识别准确度的影响。再使用本发明提供的第一ocr深度学习模型依次识别每个单字符图像,得到与每个单字符图像对应的识别结果。由于本发明提供的第一ocr深度学习模型是通过大量存在不同类型、不同程度干扰的单字符图像样本训练得到的,具有较好的抗干扰能力,较高的识别准确度。区别于现有技术1使用深度学习模型直接识别整个字符片段图像,本实施例的深度学习模型一次只识别一个单字符图像,其待识别单字符图像本身携带的干扰因素较之整个字符片段图像中的干扰因素相比较小,且本实施例的深度学习模型是使用单字符图像训练样本训练得到的,较之使用整个字符片段图像样本训练得到的深度学习模型,具有更高的识别准确度。区别于现有技术2将字符片段图像分割成单字符图像后,直接使用二值化或灰度图像识别方法识别单字符图像,由于二值化和灰度图像识别方法均不适用于具有干扰因素的应用场景,本实施例提供的基于深度学习模型的ocr识别方法能够更准确地识别出带干扰因素的字符片段图像对应的字符串。综上所述,本实施例提供的基于深度学习模型的ocr识别方法具有较强的抗干扰能力和较高的识别准确度,尤其适用于合同、表格、票据等纸质文档在电子数据化过程中,印章底纹、拍摄光照、图像模糊等外部环境变化较大的应用场景。
本发明的实施例二为:
如图4所示,本实施例还提供一种基于深度学习模型的ocr识别终端,包括一个或多个处理器1及存储器2,所述存储器2存储有程序,并且被配置成由所述一个或多个处理器1执行以下步骤:
s1、将预设的字符片段图像分割成多个单字符图像,得到单字符图像集合。
其中,本实施例采用开源的深度学习目标检测模型rfcn训练检测票据图像的单字符位置,得到票据图像上每个字符外接矩形框的左上角和右下角坐标。根据每个字符对应的坐标信息,从原票据图像中剪切得到多个单字符图像。
例如,一个字符片段图像中包含字符片段“增值税发票”,通过目标检测模型识别到每一个字符的坐标,并根据每一个字符的坐标分割该字符片段图像,得到“增”、“值”、“税”、“发”和“票”五个单字符图像。
s2、归一化所述单字符图像集合中每一单字符图像的尺寸。具体为:
s21、从所述单字符图像集合中获取一单字符图像,得到第一单字符图像;
s22、获取所述第一单字符图像的长宽比例;
s23、将所述第一单字符图像的最长边缩放至预设的像素,并根据所述长宽比例缩放所述第一单字符图像中除所述最长边之外的其它边,得到第二单字符图像;
s24、当所述第二单字符图像中存在边长小于所述预设的像素的边时,使用所述第一单字符图像的背景图像填充所述第二单字符图像,得到第三单字符图像;所述第三单字符图像的长和宽均为所述预设的像素;
s25、重复执行s21至s24,直至所述单字符图像集合被遍历。
其中,所述预设的像素为64。经大量实验,当单字符图像尺寸太小时保留图像信息不足,识别字符的准确度较差。当单字符图像尺寸太大时,提取特征速度慢。本实施例将单字符图像的尺寸归一化为64像素*64像素,不仅能够满足识别字符所需的特征信息,而且能够加快特征提取的速度,节约显存空间。尺寸归一化后的多个单字符图像如图2所示。图2中的方框边长为64像素,若方框中存在空白区域,直接使用单字符图像的背景填充方框。
本实施例在将单字符图像送入深度学习模型之前,先将所有待识别的单字符图像尺寸进行归一化处理,使得待识别的单字符图像与训练样本的单字符图像尺寸相同,有利于减小尺寸因素对识别准确度的干扰。在尺寸归一化的过程中,本发明保持原单字符图像的长宽比例不变,使用背景图像填充不足部分,有效保证了待识别的单字符图像保持原来的特征,避免单字符图像扭曲变形带来的干扰。同时,使用背景图像填充不足之处,有利于避免单字符图像的空白部分被误识别成有意义的像素,减少背景对ocr字符识别的干扰,提高ocr字符识别的准确度。
s3、获取第一ocr深度学习模型。具体为:
s31、从预设的第一训练样本集中获取一样本;
s32、预设的第二ocr深度学习模型识别所述一样本,得到第二特征向量;
s33、根据预设的损失函数计算所述第二特征向量的损失值;
s34、根据所述损失值调整所述第二ocr深度学习模型的参数;
s35、重复执行s31至s34,直至所述第一训练样本集被遍历,得到所述第一ocr深度学习模型;
所述预设的损失函数,具体为:
其中,
s,m,n,n为固定值,w为深度学习的权重参数,初始赋予随机数或预训练模型参数。x为当前样本的特征向量,yi为当前样本的实际类别,对于输入的特征向量x,预测为正确类别的概率值为cosθyi,预测为其他类别的概率值为(cosθj),当预测的值越接近真实类别时,cosθyi越大,代入公式,则loss的值越接近于0;反之,loss越大,即代表当前样本与预测的类别差距越大。
本实施例,引入惩罚系数,即类别间距m,来使类内距离变小,类外距离变大,以提升识别单字的准确率。
其中,本实施例的第二ocr深度学习模型为用于中英文字符识别的arcface深度学习模型。arcface深度学习模型的网络主干采用34层残差卷积网络(resnet34),输出为512维的特征向量;然后接入1*class_number的全连接层,class_number表示字符的类别数。将尺寸归一化后的单字符图像送入训练好的第一深度学习模型,经过卷积运算,提取单字符特征,最后输出高维的特征向量,该特征向量就是描述输入的单字符图像的一种数学表达方式。
本实施例收集涵盖国标gb2312一二级字库的字符样本,主要是票据文档,送入s1和s2,得到的单字符图像样本按8:2的比例分成训练集和测试集,用第二ocr深度学习模型进行训练,得到能正确表达单字类别特征的第一ocr深度学习模型。测试样本集测试准确率为99.9%。
损失函数是一种用于衡量损失和错误的函数。损失函数的计算结果表示深度学习网络识别一单字符图像得到的字符与该单字符图像真实表示的字符之间的差异值。
本实施例摒弃使用ocr字符识别领域常用的损失函数softmax,softmax只在欧式空间里学习特征,只考虑样本是否能正确分类,而不考虑类内和类间的距离,即不能优化特征使得同一字符对应的不同形式样本得到高相似度,不同字符之间的样本得到低相似度。本发明提供的损失函数直接关注特征的角度可分性,认为设置分类间隔以缩小类内间距,拉大类间距离,使得同一字符对应的不同形式样本相似度高,不同字符之间的样本相似度低,使得训练第一深度学习模型过程中可以更加精准地调整模型参数,增强第一深度学习模型的拟合性,提高第一深度学习模型的准确度。
s4、创建特征数据库;所述特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量。具体为:
s41、获取与第四单字符对应的预设数量样本,得到第二训练样本集。
s42、所述第一ocr深度学习模型识别所述第二训练样本集,得到第三特征向量集合。
s43、获取与所述第三特征向量集合对应的平均特征向量。
s44、添加所述第四单字符和所述平均特征向量至所述特征数据库。
s45、重复执行s41至s42,直至所有的预设第四单字符集合被遍历。
其中,所述预设数量不少于10。
由于每一个单字符的字体、字号、光照、背景等干扰因素不同,使用同一深度学习模型识别同一单字符对应的不同形式样本得到的特征向量有略微差别。本实施例为了提高深度学习模型识别单字符图像的准确度,使用由同一个单字符对应的不同形式样本的平均特征向量作为该单字符的特征模板,特征模板描述该单字符的典型特征,并使用各单字符的特征模板与深度学习模型实时识别到的特征向量进行比较,从而挑选出相似度最高的单字符,极大程度上降低了不同字体、字号、光照、背景等因素对深度学习模型识别准确度的影响。
例如,第四单字符“利”对应的第二训练样本集中包括不同字体的“利”字图像、不同字号的“利”字图像、不同光照强度下拍摄或扫描的“利”字图像、印在不同背景图像上的“利”字图像等。由于各样本之间存在差异,第一ocr深度学习模型对不同的“利”样本进行识别,得到的第三特征向量有略微的差别。将所有“利”对应的第三特征向量进行平均化,得到平均特征向量。平均特征向量能够去除不同样本“利”之间的差异特征,保留“利”的典型特征。即使第一ocr深度学习模型当前所要识别的“利”字图像存在的干扰情况在之前的训练样本中未出现过,也能够通过具有“利”字典型特征的平均特征向量准确匹配。
s5、预设的第一ocr深度学习模型依次识别所述单字符图像集合中的元素,得到第一特征向量集合;一所述单字符图像对应一第一特征向量。
其中,第一ocr深度学习模型识别一单字符图像所得到的第一特征向量能够反映出该单字符图像的特征。
例如,图3所示的单字符图像对应的特征向量是一个512维的浮点型向量[0.152485,0.846521,0.745145,…………,0.547854,0.879466,0.914724,0.007963]。
s6、根据预设的特征数据库,将所述第一特征向量集合中的每一第一特征向量转换为对应的单字符,得到单字符集合。
其中,特征数据库中的一条记录保存一单字符和与所述一单字符对应的特征向量。将当前第一ocr深度学习模型识别得到的第一特征向量与特征数据库中的每一特征向量计算相似度,具有最高相似度的特征向量对应的单字符即为第一ocr深度学习模型识别一单字符图像的识别结果。可选地,采用余弦距离作为两个特征向量之间的相似度。
s4、排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。具体为:
获取所述单字符图像集合中每一所述单字符图像在所述字符片段图像中的坐标,得到坐标信息;
根据所述坐标信息排列所述单字符集合中的元素,得到与所述字符片段图像对应的字符串。
例如,一个字符片段图像中包含“增值税发票”,分别获取能包含每一个字的最小方框的左上角坐标,根据每一单字符图像的左上角坐标排列字符“增”、“值”、“税”、“发”和“票”。根据各个单字符图像在同一字符片段图像中的相对坐标排列深度学习模型识别到的单字符,能够得到与字符片段图像相同的字符串。
通过本实施例提供的基于深度学习模型的ocr识别终端获取单字特征,相较于传统ocr识别终端获取的单字特征,具有更优秀的表达能力和鲁棒性,能够适应文字的底纹印章、线条、污渍、光照、墨渍不均等干扰。实验取10000个票据图像的单字样本,这些样本较多由于墨渍不均出现模糊、断线、印章、线条干扰等问题,分别使用现有的识别终端abbyy和本实施例提供的终端进行识别,其中abbyy识别准确率为97.8%,本实施例提供的终端的准确率为99.2%。本实施例提供的ocr识别终端具有较强的抗干扰能力和较高的识别准确度。
本实施例提供一种基于深度学习模型的ocr识别终端,先将字符片段图像分割成多个单字符图像,从而实现将字符片段图像中的印章、线条、光照、图像模糊等干扰因素碎片化,降低干扰因素对字符识别准确度的影响。再使用本发明提供的第一ocr深度学习模型依次识别每个单字符图像,得到与每个单字符图像对应的识别结果。由于本发明提供的第一ocr深度学习模型是通过大量存在不同类型、不同程度干扰的单字符图像样本训练得到的,具有较好的抗干扰能力,较高的识别准确度。区别于现有技术1使用深度学习模型直接识别整个字符片段图像,本实施例的深度学习模型一次只识别一个单字符图像,其待识别单字符图像本身携带的干扰因素较之整个字符片段图像中的干扰因素相比较小,且本实施例的深度学习模型是使用单字符图像训练样本训练得到的,较之使用整个字符片段图像样本训练得到的深度学习模型,具有更高的识别准确度。区别于现有技术2将字符片段图像分割成单字符图像后,直接使用二值化或灰度图像识别方法识别单字符图像,由于二值化和灰度图像识别方法均不适用于具有干扰因素的应用场景,本实施例提供的基于深度学习模型的ocr识别终端能够更准确地识别出带干扰因素的字符片段图像对应的字符串。综上所述,本实施例提供的基于深度学习模型的ocr识别终端具有较强的抗干扰能力和较高的识别准确度,尤其适用于合同、表格、票据等纸质文档在电子数据化过程中,印章底纹、拍摄光照、图像模糊等外部环境变化较大的应用场景。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!