面向传感信息处理的GPU集群深度学习边缘计算系统的制作方法
本发明涉及一种计算机技术,特别涉及一种面向传感信息处理的gpu集群深度学习边缘计算系统。
背景技术:
随着物联网技术和人工智能技术的飞速发展,相应的复合应用已经在各个领域展开,特别是基于视频的实时分析技术应用已经成为热点。例如,大规模视频监控用于公交系统拥挤度实时分析、居家养老用于大社区范围的养老照护、工业自动化分拣应用等。对于这些基于视频传感的大规模应用面临诸多问题需要解决:1)传感信息的实时处理对前端传感设备的成本提出了挑战;2)视频数据的实时传输对通讯网络产生了压力;3)视频数据的存储和传输对隐私保护问题带来了应用难点(如居家养老照护隐私问题)。这些都为边缘计算技术的应用带来了机会。其关键是构建高性能价格比的边缘计算架构、模型和应用支撑模式。以小型gpu集群为中心的边缘计算模式可以有效解决局部大规模传感的汇集、传输、计算和存储的综合高性价比系统。
技术实现要素:
本发明是针对大规模物联网传感信息对物联网络和服务器系统压力日益增大的问题,提出了一种面向传感信息处理的gpu集群深度学习边缘计算系统,通过弹性协同机制,利用前端智能传感设备的预处理和初始特征提取,把数千个传感数据特征传输到gpu集群边缘计算中心按照spmd(单程序多数据并行)模式统一并行实时处理。
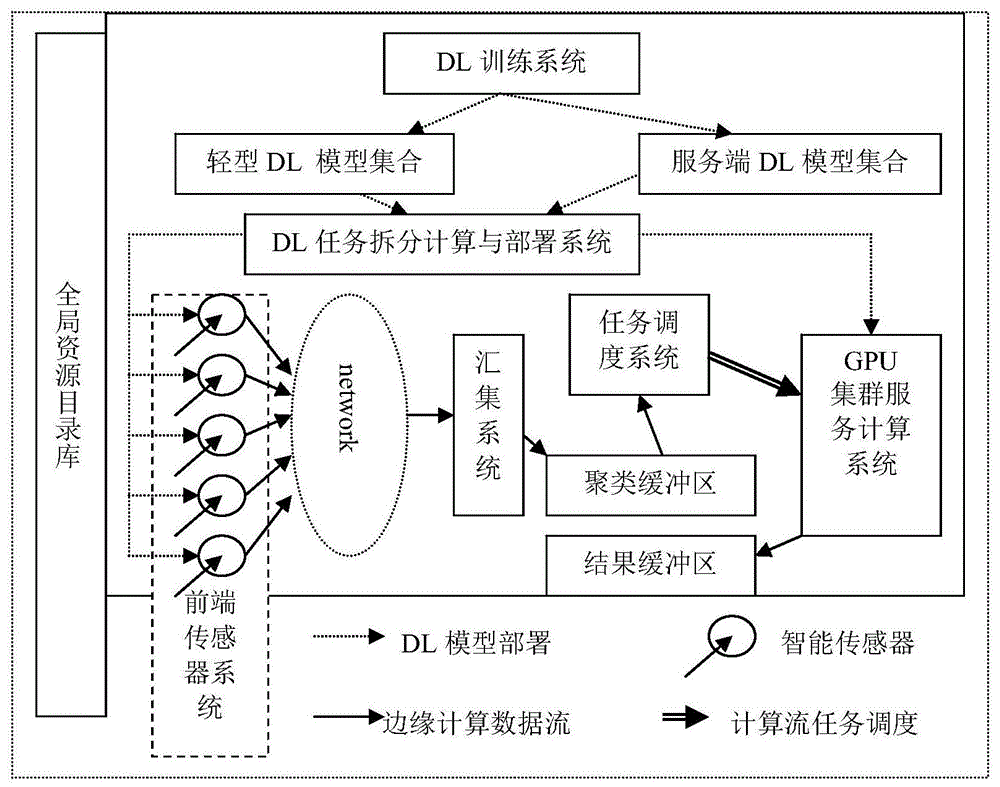
本发明的技术方案为:一种面向传感信息处理的gpu集群深度学习边缘计算系统,对前端智能传感系统中传感数据进行实时处理,包括dl训练系统、dl任务拆分计算与部署系统、前端智能传感系统、汇集系统、任务调度系统、聚类缓冲区、gpu集群服务计算系统、结果缓冲区和全局资源目录库;各个应用领域对应的样本数据集送入dl训练系统进行模型训练,每个应用领域对应训练输出运行在移动设备的轻量dl模型和运行在服务端设备上的服务器端dl模型,dl训练系统生成所有模型送全局资源目录库和dl任务拆分计算与部署系统;dl任务拆分计算与部署系统从全局资源目录库读取前端智能传感系统传感数据,部署在前端智能传感系统中,并根据智能传感设备的计算能力和通信能力约束条件计算得到所适用的轻量dl模型和服务器端dl模型处理工作比例,智能传感设备周期地对传感数据完成轻量dl模型相应比例的预处理工作,把得到的处理中间结果传输至汇集系统,汇集系统将前端智能传感系统处理的中间结果以及dl任务拆分工作的服务器工作比例送聚类缓冲区,任务调度系统根据聚类缓冲区的中间结果进行聚类,任务调度系统按照该聚类计算批任务所需要的计算资源,寻找适当的gpu集群服务计算系统,并发送该聚类批任务到选定的gpu集群服务计算系统,gpu集群服务计算系统配置相应的服务器端dl模型,完成前端智能传感系统的传感数据剩余比例处理任务,gpu集群服务计算系统把完成的最终结果送入结果缓冲区。
所述dl任务拆分计算与部署系统根据每个智能传感器is的计算能力cpower、计算周期间隔tcap、通信能力bnet为约束,计算出每个智能传感器is的功能所对应的轻量dl模型能够完成处理的计算工作的百分比α,然后对百分比b=1-α的计算工作部分安排相应的gpu集群服务计算系统进行执行。
所述面向传感信息处理的gpu集群协同深度学习边缘计算系统运行数据结构包括智能传感器任务部署表、聚类任务表和gpu集群服务计算系统动态任务分配表;
1)智能传感器任务部署表定义为复合对象ista,ista由isid,num,ldlmt构成定义,其中isid为is的标识符id,num为该ista上可以运行的轻量dl模型的数目;ldlmt为子表,ldlmt由no,ldlm,du,dt,α,tcap构成定义,该子表的每一行记载一个轻量dl模型,ldlmt的no为该轻量dl模型的序号,ldlm为轻量dl模型,du为该模型的输入数据单元,dt计算du所需要的计算资源量,α为该模型对du执行ldlm计算任务量的百分比,tcap为du出现的周期,is需要在tcap时间内完成du的ldlm任务的百分之α计算工作;
2)聚类任务表定义为gct,gct由gcid,gcdata,sdlm,b,tcap构成定义,其中gcid该聚类任务标识符,gcdata为该聚类任务数据集,sdlm为服务器端dl模型,b为该任务对gcdata执行sdlm计算任务量的百分比,tcap为gcdata出现的周期,需要在tcap时间内完成gcdata的sdlm任务的百分之b计算工作;
3)gpu集群服务计算系统动态任务分配表定义为gputa,gputa由sno,stime,gpusid,gcid,gcdata,sdlm,b,tcap构成定义,其中表的每一行为一个gpu计算任务,sno为该任务的序号,stime为任务起始执行时刻,gpusid为被分配gpu服务器的标识符,gcid为本次任务绑定所执行的聚类任务标识符,gcdata为本次任务绑定所执行的聚类任务数据集,sdlm为服务器端dl模型,b为该模型对gcdata执行sdlm计算任务量的百分比,tcap为gcdata出现的周期,gpu集群服务计算系统需要在tcap时间内完成gcdata的sdlm任务的百分之b计算工作。
本发明的有益效果在于:本发明面向传感信息处理的gpu集群深度学习边缘计算系统,1)运用前端智能传感设备的弱小的计算能力对传感信息进行预特征提取,可以根据前端智能传感设备的计算能力动态地量力而行地分配计算任务,减轻了前端传感设备的成本压力以及硬件版本一致要求的成本压力(不同时期的不同计算能力的前端设备可以一同使用,延长设备的寿命,降低了陈本,可以大规模普及应用);2)通过前端智能传感设备的预处理使得原始传感数据(如图像)的信息量大大压缩(仅仅获取传感数据的核心特征),降低了边缘计算网络(往往是无线网络、窄带物联网)的通信压力,使得构建边缘计算的网络成本大大降低;3)过前端智能传感设备的预处理使得原始传感数据的敏感部分被模糊淡化(图像的原始面貌发生了特征变换),使得边缘计算网络中传输的数据和存储的数据聚焦数据核心特征,更容易被隐私敏感的用户接受应用,拓展了物联网应用普及的范围;4)汇集到gpu集群的大规模传感数据特征集合通过聚类划分来驱动gpu的spmd计算机制,使得边缘计算的并行计算效率得到了提高,同时gpu集群的大规模并行计算能力以及低成本高可靠性的优势得以有效发挥。
附图说明
图1为本发明面向传感信息处理的gpu集群深度学习边缘计算系统结构示意图。
具体实施方式
一、面向传感信息处理的gpu集群协同深度学习(deeplearning-dl)边缘计算系统结构组成:
1、如图1所示gpu集群协同深度学习边缘计算系统结构示意图,面向大规模物联信息智能处理的gpu集群协同dl边缘计算系统(dlecg)包括:dl训练系统、轻型dl模型集合、服务端dl模型集合、dl任务拆分计算与部署系统、前端智能传感系统、汇集系统、任务调度系统、聚类缓冲区、gpu集群服务计算系统、结果缓冲区、全局资源目录库。
2、dl训练系统(dlts)由若干个dl训练模型dltm构成,dlts有自己的标识符id。每个dltm可以定义为一个四元组dltm,包括dlms,dlmssd,ldlm和sdlm;其中dlms为dltm所采用的dl开发工具(例如tensorflow,keras等);dlmssd为应用领域对应的训练数据集;ldlm为基于dlms(如tensorflow的轻量化版本tensorflowlite),利用dlmssd训练出的dlts所对应的领域应用轻量dl模型,此轻量dl模型是可以运行在移动设备芯片(如arm)上的应用模型(例如应用tensorflowlite训练的人脸识别、公交车乘客拥堵检测、基于视频的道路拥堵分析等);sdlm为基于dlms,利用dlmssd训练出的dlts所对应的领域应用服务器端dl模型,此服务端dl模型是可以运行在服务器芯片(如多核cpu、gpu集群等)上的应用模型(例如应用tensorflow训练的人脸识别、公交车乘客拥堵检测、基于视频的道路拥堵分析等)。
3、轻型dl模型集合由dl训练系统(dlts)生成的所有轻量dl模型构成,可以表示为ldlm1,ldlm2,……,ldlmn,n为领域应用个数。
4、服务端dl模型集合由dl训练系统(dlts)生成的所有服务端dl模型构成,可以表示为sdlm1,sdlm2,……,sdlmn,n为领域应用个数。为了简述,ldlmi和sdlmi(1≤i≤n)为一个应用模型对,即他们分别对应第i个领域应用的运行在移动设备和服务端设备上的dl模型。
5、前端智能传感系统由若干个智能传感器is构成,每个智能传感器is由id,cpower,func,bnet,dinput,dt,tcap构成定义,其中id为is的标识符,cpower为is的计算能力,func为is的功能描述,bnet为is的通信能力,dinput为is采集数据,dt为执行func来计算dinput所需要的总计算能力(总计算工作量),tcap为is的传感数据的计算周期间隔。
6、gpu集群服务计算系统由若干个gpu服务器构成,称为gpus,gpus由id,cowper,func,rpower,kernel,tcap构成定义,其中id为gpus的标识符,cpower为其计算能力,func为其功能描述,bpower为其聚类数据处理能力,dinput为其聚类数据集合,tcap为其聚类数据计算周期间隔。
7、dl任务拆分计算与部署系统根据智能传感器is的计算能力cpower、计算周期间隔tcap、通信能力bnet为约束,计算出is的func所对应的轻量dl模型ldlm能够完成处理dinput的计算工作的百分比α,然后对百分比b=1-α的dinput部分安排相应的gpus服务器进行执行,数对(α,b)为dl任务拆分计算与部署系统对is的ldlm模型计算量进行了划分。在实际工作中,如深度学习模型中,α可以为is完成的神经网络分层数,b为gpus完成的神经网络分层数,也就是说is和gpus共同完成对dinput的α+b层神经网络计算。
8、全局资源目录库用于存放系统的传感器资源、dl模型资源、gpus计算资源、任务拆分与部署信息、聚类数据信息等。
9、汇集系统通过物联网通信网络(如wifi、4g、zigbee、lora等)汇集来自前端智能传感器系统并发传来的轻型dl模型所计算的中间结果(仅仅完成is计算,也就是dt的百分之α);并按照轻型dl模型集合ldlm1,ldlm2,……,ldlmn进行聚类,即使用了同一领域应用轻型dl模型ldlm且前端计算百分比相同的中间结果聚为一类,放置到聚类缓冲区。
10、任务调度系统根据聚类缓冲区的中间结果得到聚类数据gc,按照gc完成后续dl模型计算任务所需要的计算资源,寻找适当的gpus并配置相应的sdlm,驱动它们完成gc的后百分之b的计算工作。gpu集群服务计算系统把完成的最终结果送入结果缓冲区。
二、系统运行数据结构
1、智能传感器任务部署表
智能传感器任务部署表可以定义为复合对象ista,ista由isid,num,ldlmt构成定义,其中isid为is的标识符id,num为该ista上可以运行的ldlm模型的数目;ldlmt为子表,ldlmt由no,ldlm,du,dt,a,tcap构成定义,该子表的每一行记载一个ldlm,ldlmt的no为该ldlm的序号,ldlm为模型,du为该模型的输入数据单元,dt计算du所需要的计算资源量,α为该模型对du执行ldlm计算任务量的百分比,tcap为du出现的周期(is需要在tcap时间内完成du的ldlm任务的百分之α计算工作)。
2、聚类任务表
聚类任务表可以定义为gct,gct由gcid,gcdata,sdlm,b,tcap构成定义,其中gcid该聚类任务标识符,gcdata为该聚类任务数据集,sdlm为模型,b为该任务对gcdata执行sdlm计算任务量的百分比,tcap为gcdata出现的周期(需要在tcap时间内完成gcdata的sdlm任务的百分之b计算工作)
3、gpus动态任务分配表
gpus动态任务分配表可以定义为gputa,gputa由sno,stime,gpusid,gcid,gcdata,sdlm,b,tcap构成定义,其中表的每一行为一个gpu计算任务,sno为该任务的序号,stime为任务起始执行时刻,gpusid为被分配gpu服务器的标识符,gcid为本次任务绑定所执行的聚类任务标识符,gcdata为本次任务绑定所执行的聚类任务数据集,sdlm为模型,b为该模型对gcdata执行sdlm计算任务量的百分比,tcap为gcdata出现的周期(gpus需要在tcap时间内完成gcdata的sdlm任务的百分之b计算工作)
三、算法
1、dl训练系统工作过程:
设有p个应用领域,分别为d1,d2,….,dp,它们对应的样本数据集为dlmssd1,dlmssd2,…..,dlmssdp,它们实施的dl计算任务分别为dt1,dt2,….,dtp。每个dti(1≤i≤p)有多个子任务构成,例如在深度学习网络中可以定义为卷积、池化等一系列子任务。
对每个应用领域di(1≤i≤p)进行模型训练,dl训练系统做如下工作:
{
为di确定一个dl开发工具dlms(例如tensorflow,keras等)
对于一个训练任务dti,利用某一dl开发工具dlms,对样本数据集dlmssdi进行计算训练(训练过程可参考具体的工具手册),得到一个训练模型dltmi(idi,dlmsi,dlmssdi,ldlmi,sdlmi,dti,dui);
};
完成所有训练任务,输出p个训练模型dltm1,dltm2,……,dltmp和sltm1,sltm2,……,sltmp到全局资源目录库。这里我们对每个应用领域di(1<=i<=p)对应都得到2个模型,一个可以运行在智能传感器上的轻型dl模型ldlmi,另一个是运行在gpu服务器上的服务端dl模型sdlmi。
2、dl任务拆分计算与部署系统过程如下:
读取全局资源目录库,获取前端传感器系统内的q个智能传感器isj(id,cpower,func,bnet,dinput,dt,tcap)(1≤j≤q);获取p个应用领域的训练模型dltm1,dltm2,……,dltmp;
对每个智能传感器isj(1≤j≤q),做如下工作:
{为isj生成一个标识符isid,置计数器num=1;
在智能传感器任务部署表ista中增加一个行复合对象otmp(isid,num,ldlmt(null)),其中null表示子表为空;
对isj对应的每个应用领域训练模型dltmi(1≤i≤p),做如下工作:
{获取模型dltmi的处理数据单元规范dui和isj单位计算任务量dtj;
设对dui执行任务dtj的百分之α后产生的中间结果为mm;采用如下约束来确定比例α的值:(1)α*dtj≤isj.cpower;(2)mm的数据规模≤isj.bnet;(3)α*dtj的运行时间+传输mm通讯时间≤dltmi.tcap,从约束条件计算出拆分任务dtj中isj传感器计算工作量为α*dtj;其中*为乘法运算;
把行复合对象otmp(isid,num,ldlmt())增加一个字表行ldlmt(dltmi.tdi,dltmi.ldlm,dui,dtj,α,dltmi.tcap),并且num++;
}
用num值更新行复合对象otmp(isid,num,ldlmt())的num属性;
}
3、前端传感器系统工作过程如下:
对前端传感器系统中的每个智能传感器isj(1≤j≤q),并发地如下工作:
{获取工作任务标志tflag;(选择当前传感器的领域应用模型)
读取全局资源目录库,获取智能传感器isj的智能传感器任务部署行复合对象otmp(isj.isid,num,ldlmt()),根据tflag查询子表ldlmt(),得到isj的当前工作配置状态isconfig(id,cpower,func,bnet,dinput,dltmi.ldlm,dtj,α,tcap);
装载isconfig.func功能函数库;根据α*dt的值拆分功能函数库func为subfunc;
智能传感器isj周而复始地做如下工作:
{启动计时器tt=0且tt<tcap时,做:
{从传感器端口读取传感数据dinput;
对dinput执行dltmi.ldlm的subfunc过程并输出中间结果mm;
传输通讯数据包tp(isj.isid,tflag,mm)到汇集系统;
}
}//传感器isj工作
}//q个传感器并发工作。
4、汇集系统工作过程如下:
周而复始地做如下工作:
{读取网络数据接受端口,并发地获取来自前端传感器系统的通讯数据包tp(isj,tflag,mm)(1≤j≤q);
读取全局资源目录库,获取智能传感器isj的智能传感器任务部署行复合对象otmp(isj.isid,num,ldlmt()),根据tflag查询子表ldlmt(),得到isj的当前工作配置状态isconfig(id,cpower,func,bnet,dinput,ldlm,dtj,α,tcap);根据ldlm获取对应的sdlm;计算服务器端计算任务后百分比b=1-α;
查询聚类缓冲区,根据func、sdlm、b、tcap计算通讯数据包tp归属的类别gcid,并把tp存入gct(gcid,gcdata,sdlm,b,tcap)的gcdata;
}
5、任务调度系统过程:
周而复始地做如下工作:
{查询聚类缓冲区,如果有一个准备好的聚类任务gct(gcid,gcdata,sdlm,b,tcap)则做如下工作:
{totaltask=0;
扫描聚类任务gct的gcdata,对gcdata的每个数据包tp(isj,tflag,mm),做如下工作:
{读取全局资源目录库,获取智能传感器isj的智能传感器任务部署行复合对象otmp(isj.isid,num,ldlmt()),根据tflag查询子表ldlmt(),得到isj的当前工作配置状态isconfig(id,cpower,func,bnet,dinput,ldlm,dtj,α,tcap);
totaltask=totaltask+(dt*1-α));
}
向gpu集群服务计算系统提交资源申请向量(totaltask,b,tcap),要求其在tcap的时间内完成sdlm模型的func功能的dt*b计算工作量;
在得到gpu集群服务计算系统确认恢复后,把聚类任务gct(gcid,gcdata,sdlm,b,tcap)和资源申请向量(totaltask,b,tcap)提交给gpu集群服务计算系统并行执行该聚类任务;
}
6、gpu集群服务计算系统过程如下:
从任务调度系统获取聚类任务gct(gcid,gcdata,sdlm,b,tcap)和资源申请向量(totaltask,b,tcap);
读取每个gpu服务器gpus(id,cowper,func,rpower,kernel,tcap)的状态信息,确定能够在tcap时间内完成totaltask任务的服务器子集合subcpus={gpus1,gpus2,….,gpusr};
把聚类任务gct的gcdata中的所有中间结果数据mm变换为spmd计算模式数据(具体参见gpu编程模型cuda),并驱动subcpus所有服务器完成执行具有func功能的kenerlspmd计算;subcpus把计算最终结果存入结果缓冲区。
- 还没有人留言评论。精彩留言会获得点赞!