一种基于信息熵的二维软件可靠性增长模型的制作方法
本发明属于软件可靠性增长模型技术领域,具体涉及一种基于信息熵的二维软件可靠性增长模型。
背景技术:
在现代社会中,计算机已经被广泛应用在各行各业。例如,交通、通讯、银行和国家军事防御系统等。而且随着计算机性能的增强,在计算机中的应用软件程序也变的复杂和编码程序规模也越来越大。例如,现在广泛研究的云计算和大数据应用软件。一旦软件发生故障,将会对现代社会造成重大损失。因此,软件可靠性成为人们关注的热点。软件可靠性也是评估计算机中软件安全运行重要指标。
软件可靠性被定义为在规定的时间和规定的条件下,不发生软件运行故障的概率[1]。在过去的四十年里,许多一维软件可靠性模型被开发出来。例如,jelinski和moranda模型[2],geol和okumoto模型[3],delays-shaped模型[4]和inflections-shaped模型[5]等。
一维软件可靠性增长模型仅仅依赖一个因素,例如,日历时间(测试时间资源)或者执行时间(测试工作量资源)。而且,musa[1]认为一维软件可靠性模型的性能主要依赖于执行时间,即,处理器执行程序指令所花费的时间[1]。例如,cpu小时要优于日常记录时间,即,日历时间因素(天,周和月等)。但是,一维软件可靠性模型依赖执行时间因素在实际的软件测试和可靠性评估中有一个限制,那就是执行时间在软件测试中,不方便使用和记录。对于软件开发者来说,只有把执行时间转化为日历时间才能方便地使用进行软件可靠性测试。为了解决这个问题,musa等人[1]在日历时间和执行时间之间建立一种关系或者公式表示,并且通过转化执行时间到日历时间来建立日历时间模型。但是,musa等人[1]建立的日历时间的确很少被用在实际的软件可靠性评测当中。这是因为他们建立的日历时间模型是一个理论和直觉模型,只能用在特殊的测试环境下。
针对上面提到关于怎样在一维软件可靠性增长模型中使用测试执行时间资源问题,yamada等人[6,7]提出一个基于非齐次泊松过程(nhpp)的软件测试工作量模型,假设累积执行时间是测试日历时间的函数。因此,在一维的软件可靠性增长模型使用上,人们可以方便地使用测试工作量资源,例如,测试日历时间和执行时间资源。但是,当测试时间是无限的,测试工作量函数值在测试工作量模型中将会小于1。故障检测概率明显是有缺陷的[8]。因此,具有两种资源的测试工作量模型在实际的软件测试过程中并不能完全使用测试资源。
为了完全使用测试资源,文献中已建立的一般二维软件可靠性增长模型(srgm)是一个数学模型[9-12],在软件测试过程中,用来评估软件的可靠性。文献[9,10]中,inoue和yamada使用cobb-douglas产品函数去合并测试日历时间和测试执行时间。通过扩展一维weibull类软件可靠性增长模型来建立二维软件可靠性增长模型。相似的,kapur等人[11,12]提出一个二维和多发布软件可靠性模型,使用cobb-douglas产品函数去整合测试日历时间和测试执行时间。虽然使用简单的cobb-douglas产品函数去整合两种测试时间资源是一个好的方法去建立二维软件可靠性增长模型,但是它不能完全有效地和精准地评估软件可靠性。因为他们仅仅是一个理论研究来建立二维软件可靠性模型,通过cobb-douglas产品函数简单地合并测试日历时间和测试执行时间资源方法不能准确地拟合和预测在实际测试过程中故障的数量。因此,现在建立的二维软件可靠性模型还不能被应用到实际软件可靠性评估和质量管理。
技术实现要素:
本发明针对背景技术中的问题,提供一种基于信息熵的二维软件可靠性增长模型。
本发明的技术方案为:
一种基于信息熵的二维软件可靠性增长模型,其特征是包括以下步骤:
(1)根据cobb-douglas产品函数整合测试日历时间和测试执行时间资源建立简单的二维软件可靠性增长模型如下:
y=alνk1-ν(1)
其中y是总产品函数,a是总的要素生产率,l是劳动输入,v是劳动弹性系数,是一个常量,k是资本输入;
(2)在步骤(1)的公式(1)的基础上,合并测试日历时间和测试执行时间两个时间变量被后得到公式(2):
τ=sαu1-α(2);
(3)在步骤(2)的公式(2)的基础上,将信息熵作为不确定度量的随机变量得到公式(4):
其中τ是测试资源,k是一个比例参数,s是测试日历时间,α是软件可靠性增长过程的影响程度,u是测试执行时间,β是软件可靠性增长过程的影响度,pij是测量概率,n是自然数;
其中,累计测试时间指的是测试日历时间,n1表示累计测试时间点;
(4)在步骤(3)中公式(4)的基础上,假设①故障去除现象服从非齐次泊松过程;②在软件运行过程中,软件失效是由软件中剩余故障造成的,并且失效率受到软件中剩余故障影响;③在软件测试过程中,检测出的故障立即被去除,没有引进新的故障;得到下述公式二维随机微分方程:
其中,m(τ)表示期望检测出故障数量,a表示最初期望检查出故障的数量,b(τ)表示二维故障检测率函数,b表示故障检测率,
(5)当b(x)=b,那么基于信息熵的二维软件可靠性增长模型可表示如下:
m(τ)=a[1-exp(-bτ)]
当
m(τ)=a[1-(1+bτ)exp(-bτ)]
当
本发明针对背景技术中二维软件可靠性模型存在的问题,提出一个改善的基于信息熵的二维软件可靠性增长模型框架,并且开发出三个基于信息熵的二维软件可靠性增长模型,在信息理论中,熵是一个随机变量期望值的度量。熵的概念起源于物理概念,并且用来计算不确定性程度。但是在现实信息世界,熵越高,越多的信息被传递;熵越低,很少的信息被传递。在本发明提出的模型中,加入信息熵到cobb-douglas产品函数,不但可以提取有用测试信息从已有的测试资源,还能够有效地改善已建立的二维软件可靠性模型的拟合和预测性能。本发明用两个故障数据集去验证提出的二维软件可靠性模型,通过比较一维、二维和weibull类模型,实验结果表明我们提出的简单基于信息熵的二维软件可靠性模型能更准确地拟合和预测故障发生行为。在实际的软件测试过程中,能够有效地改善二维软件可靠性增长模型的性能。总之,本发明首次提出基于信息熵的二维软件可靠性增长模型,并且能够有效地改善和增强在软件测试过程中软件可靠性增长模型的性能。
为了充分验证提出的二维软件可靠性模型的性能,本发明把提出的模型和一维、二维和其它模型进行了相应的比较。表1详细列出提出的模型和其它模型。在表1中,存在四种类型的模型。第一类是传统的经典模型,例如,goel-okumoto模型(g-o),delayeds-shaped模型(dss)和inflections-shaped模型(iss)。第二类是一般的二维软件可靠性模型,例如,一般的二维goel-okumoto模型(gtdt-o),一般的二维delayeds-shaped模型(gtddss)和一般的二维inflects-shaped模型(gtdiss)。第三类是weibull类模型,例如,基于logistictesting-effort的软件可靠性增长模型(srgm-ltef),基于logistictesting-effort函数的delayeds-shaped模型(dss-ltef)和yamadarayleigh模型(ya)。
表1.多种软件可靠性增长模型总结
参数估计
为了让实验产生无偏结果,我们既用最大似然估计,还用最小二乘法方法来估计我们提出基于信息熵的二维软件可靠性增长模型的参数。
参数的最大似然估计法
假设n(si,ui)和yi(i=1,2,…,n)表示计数过程和累计检测出故障的数量。给出n个故障数据点(si,ui,yi)(i=1,2,…,n),我们可以估计模型的参数θ,其中θ={a,b,c},那么自然函数可以表示为:
公式(9)两边取对数,
公式(10)两边取导数,
参数的最小二乘法
假设m(si,ui;θ)和yi分别表示为模型的均值函数和累计检测出故障的数量。θ表示为模型估计的参数,其中,θ={a,b,c}。那么最小二乘法可以表示为,
m(θ)=(m(si,ui;θ)-yi)2,i=1,2,…,n(11)
公式(11)两边取导数,
模型性能比较
为了完全和有效地充分比较提出的模型和一维、二维和其它模型的性能,我们用两个实际测试故障测试数据集和五个评估软件可靠性模型性能的比较标准。这五个模型比较标准分别是,均值平方误差(mse)、bias、variance、基本均值平方预测误差(rmspe)和theilstatistic(ts)。文章提到的所有软件可靠性模型都进行拟合和预测性能的比较。
附图说明
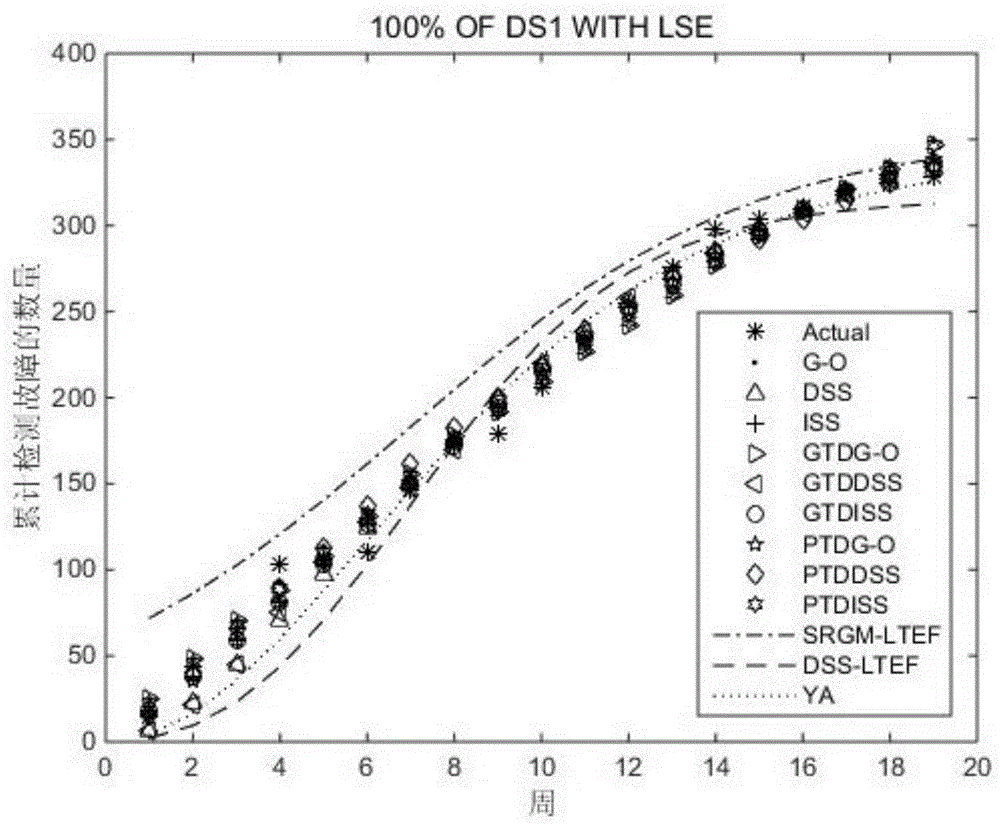
图1是本发明实施例中所有模型用100%故障数据集和最小二乘法(lse)以及最大似然估计(mse)方法进行拟合的比较结果;其中,(a)表示文中所有模型用100%的故障数据集1(ds1)和最小二乘法(lse)方法估计的累计检测出故障的数量,(b)表示文中所有模型用100%的故障数据集1(ds1)和最大似然估计(mle)方法估计的累计检测出故障的数量,(c)表示文中所有模型用100%的故障数据集2(ds2)和最小二乘法(lse)方法估计的累计检测出故障的数量,(d)表示文中所有模型用100%的故障数据集2(ds2)和最大似然估计(mle)方法估计的累计检测出故障的数量;
图2是本发明实施例中模型用60%故障数据集和最小二乘法(lse)以及最大似然估计(mse)方法进行预测的比较结果,其中,(a)表示文中所有模型用60%的故障数据集1(ds1)和最小二乘法(lse)方法预测累计检测出故障的数量,(b)表示文中所有模型用60%的故障数据集1(ds1)和最大似然估计(mle)方法预测累计检测出故障的数量,(c)表示文中所有模型用60%的故障数据集2(ds2)和最小二乘法(lse)方法预测累计检测出故障的数量,(d)表示文中所有模型用60%的故障数据集2(ds2)和最大似然估计(mle)方法预测累计检测出故障的数量;
图3是本发明提出的基于信息熵的二维软件可靠性增长模型使用故障数据集1(ds1)的95%置信区间图;
图4是本发明提出的基于信息熵的二维软件可靠性增长模型使用故障数据集2(ds2)的95%置信区间图;
具体实施方式
实施例1
一种基于信息熵的二维软件可靠性增长模型,包括以下步骤:
一种基于信息熵的二维软件可靠性增长模型,其特征是包括以下步骤:
(1)根据cobb-douglas产品函数整合测试日历时间和测试执行时间资源建立简单的二维软件可靠性增长模型如下:
y=alνk1-ν(1)
其中y是总产品函数,a是总的要素生产率,l是劳动输入,v是劳动弹性系数,是一个常量,k是资本输入;
(2)在步骤(1)的公式(1)的基础上,合并测试日历时间和测试执行时间两个时间变量被后得到公式(2):
τ=sαu1-α(2);
(3)在步骤(2)的公式(2)的基础上,将信息熵作为不确定度量的随机变量得到公式(4):
其中τ是测试资源,k是一个比例参数,s是测试日历时间,α是软件可靠性增长过程的影响程度,u是测试执行时间,β是软件可靠性增长过程的影响度,pij是测量概率,n是自然数;
其中,累计测试时间指的是测试日历时间,n1表示累计测试时间点;
(4)在步骤(3)中公式(4)的基础上,假设①故障去除现象服从非齐次泊松过程;②在软件运行过程中,软件失效是由软件中剩余故障造成的,并且失效率受到软件中剩余故障影响;③在软件测试过程中,检测出的故障立即被去除,没有引进新的故障;得到下述公式二维随机微分方程:
其中,m(τ)表示期望检测出故障数量,a表示最初期望检查出故障的数量,b(τ)表示二维故障检测率函数,b表示故障检测率,
(5)当b(x)=b,那么基于信息熵的二维软件可靠性增长模型可表示如下:
m(τ)=a[1-exp(-bτ)]
当
m(τ)=a[1-(1+bτ)exp(-bτ)]
当
为了验证提出模型的性能,我们选择两个实际软件项目测试得到的故障数据集进行相应的实验。第一个故障数据集是来自文章ohbam.softwarereliabilityanalysismodels.ibmjournalofresearchanddevelopment.1984,28,(4):428-443,它是一个pl/i数据基本应用软件系统,有近似1317000行代码。在19周软件执行时间里,用47.65个cpu小时,329个故障被检测出来。表2给出故障数据集(ds1)。第二个故障数据集(ds2)是wood收集和整理的,它是tandem计算机公司发布的四个软件应用系统之一wooda.predictingsoftwarereliability.ieeecomputer.1996,11:69–77。因为保密的原因,故障数量被标准化为0到100%。这篇文章仅用发布的软件1进行说明。在20周的时间里,10000cpu小时被花费,并且100个软件故障被检测出和去除掉。表3列出故障数据集(ds2)情况。
此外,模型参数估计是分别用故障数据集1(ds1)的前11周和故障数据集2(ds2)的前12周的数据完成的。即,用故障数据集1的1到11周来拟合故障发生行为,用12到19周来预测故障发生的数量。对故障数据集2(ds2),是用1到12周来拟合软件测试过程中故障发生的数量,用13到20周来预测故障发生的数量。它们相当于用故障数据集(ds1和ds2)的60%进行故障的拟合和估计模型的参数。用故障数据集(ds1和ds2)的40%进行故障的数量的预测。
模型比较标准
为了验证软件可靠性模型的有效性,五个模型比较标准被给出。模型比较标准表示为,
1)均值平方误差是表示实际观察到故障数据和预测故障数量的差值的平方和,被定义为,
模型有更小的mse值表明有更好的拟合或预测性能。
2)bias是实际观察到故障的数量和估计的故障数量的差值和的平均值,被定为,
模型有越小的bias值,则有更好的模型性能。
3)variance被定为,
更小的variance值,模型有更好的性能。
4)基本均值平方预测误差(rmspe)是实际观察值和估计的值偏差程度。它被定义为,
越小的rmspe值,模型有越好的性能。
5)theilstatistic(ts)被定义为,
ts越接近零,模型的性能越好。
模型性能比较和分析
软件可靠性模型的性能验证需要从二方面,一是验证模型的拟合性能(goodness-of-fit),即,拟合历史故障数据的能力;二是验证模型的预测性能,即,预测软件测试过程中检测出故障的数量。以下,我们将讨论和分析模型的拟合和预测方面的性能。
模型拟合性能比较(goodness-of-fittest)
ds1):从表4,我们能看到提出的基于信息熵的二维软件可靠性模型,无论是用最小二乘法(lse),还是最大似然估计(mle)方法,它的拟合性能都好于一般的二维软件可靠性模型和一维的软件可靠性模型。例如,提出的二维ptdg-o模型拟合性能好于gtdg-o和一维g-o模型,提出的二维ptddss模型性能好于gtddss和一维dss模型,提出的二维ptdiss要好于gtdiss和一维iss模型。而且,提出的二维ptdiss模型用最小二乘法进行参数估计时,有最低的mse值(81.3),bias(6.2),variance(11.2),ts(4.0)和rmspe(12.9);当用最大似然估计方法进行参数估计时,有最低的mse值(95.9),bias(7.3),variance(11.9),ts(4.4)和rmspe(14.1)。从图1(a)和(b),可以清楚地看到本文中所有模型用100%的故障数据集和最小二乘法(lse)以及最大似然估计方法(mle)估计模型参数进行故障失效行为拟合的情况。很明显,提出的基于信息熵的二维软件可靠性模型的拟合性能要好于其他相对应的模型。
信息熵的二维软件可靠性模型在用最小二乘法(lse)和最大似然估计(mle)方法进行模型参数估计时,提出的模型的拟合性能要好于一般的二维软件可靠性模型和一维的软件可靠性模型。例如,提出的二维ptdg-o模型要好于gtdg-o和一维g-o模型,提出的二维ptddss模型要好于gtddss和一维dss模型,并且提出的二维ptdiss模型好于gtdiss和一维iss模型。而且,二维ptdg-o模型在用最小二乘法(lse)进行参数估计时,有最低的mse(5.0),bias(1.8),variance(3.0),ts(3.0)和rmspe(3.5)。在用最大似然估计法进行参数估计时,ptdg-o模型有最低的mse(8.6),bias(2.3),variance(3.5),ts(3.9)和rmspe(4.2)。在图1(c)和(d)中,能够看到本文中所有模型在用100%故障数据和最小二乘法以及最大似然估计方法进行参数估计后,拟合历史故障数据的情况。图1(c)和(d)清晰地显示出提出二维软件可靠性模型的拟合性能好于其他模型。
模型预测性能比较
ds1):从表6,能够看到提出的基于信息熵的二维软件可靠性模型,无论是用最小二乘法(lse),还是最大似然估计(mle)方法,它的预测性能都好于一般二维软件可靠性模型和一维软件可靠性模型。总的来说,提出的二维ptdg-o模型预测性能要优于二维gtdg-o模型和一维g-o模型,提出的二维ptddss模型优于二维gtddss模型和一维dss模型,提出的二维ptdiss模型要优于gtdiss模型和一维iss模型。而且,提出的二维ptdiss在用最小二乘法估计模型参数时,有最小的mse(43.5),bias(5.7),variance(14.6),ts(2.2)和rmspe(12.9);提出的二维ptdg-o模型在用最大似然估计方法估计参数时,有最小的mse(201.6),bias(12.4),variance(19.0),ts(4.7)和rmspe(23.3)。图2(a)和(b)给出本文中所有模型的预测故障发生情况。在图2中,没有画出故障拟合的情况。从图2(a)和(b),可以清晰看到提出的模型的预测性能优于其它模型。图3给出提出模型的95%的置信区间。而且,能够看到提出的模型预测故障检测出故障数量和实际故障发生数量比较情况。从图3,能够明显地看到提出的模型用故障数据集1进行仿真实验时,无论用最小二乘法,还是最大似然估计方法,都能很好地预测故障发生的数量。
ds2):相似的,在表7中,提出的模型预测性能要优于其它模型,无论是一般的二维软件可靠性模型,还是一维软件可靠性模型。其中,提出的二维ptdg-o模型同二维gtdg-o模型和一维g-o模型相比较时,有更好的预测性能。提出的二维ptddss模型同二维gtddss模型和一维dss模型相比较时,有更好的性能。提出的二维ptdiss模型的预测性能要优于二维gtdiss模型和一维iss模型。而且,提出的二维ptdg-o模型在最小二乘法估计参数情况下有最低的mse(2.0),bias(1.1),variance(1.0),ts(1.5)和rmspe(1.5)。提出的二维ptddss在用最大似然估计方法估计参数情况下有最小的mse(1.8),bias(1.0),variance(1.3),ts(1.4)和rmspe(1.6)。从图2(c)和(d),可以清晰地看到提出的二维软件可靠性模型的预测性能要好于其它模型。图4显示提出的二维模型的95%置信区间情况。从图4,可以看到提出的二维软件可靠性模型很好的预测了故障发生的数量,而且估计的故障发生数量很好地落在了95%的置信区间之内。
提出的模型性能优于其它模型的机理分析
从上面分析,可以得出提出的基于信息熵的二维软件可靠性模型的拟合和预测性能优于一般的二维软件可靠性模型、一维软件可靠性模型和包含测试工作量的软件可靠性模型。它的原因有,
一是提出的基于信息熵的二维软件可靠性模型充分利用了测试过程中的时间资源和历史故障数据。通过用信息熵来充分和彻底地挖掘和捕获测试资源关于发生故障的信息。
二是用信息熵来整合测试日历时间和测试执行时间资源,最大程度的利用测试时间资源。
三是由于测试环境和软件的复杂性,因此,估计测试过程中故障发生的数量更是一个不确定性的随机变化问题。而信息熵可以表示信息的价值,用信息熵可以最大程度来描绘复杂测试资源的变化情况。
四是由于提出的基于信息熵的二维软件可靠性模型能够充分和彻底地利用测试中的有限资源的有用信息,因此,提出的模型同其它模型相比,有更好的拟合和预测性能。
总之,本发明利用信息熵来整合测试资源,并提出基于信息熵二维软件可靠性增长模型,而且分别用最小二乘法(lse)和最大似然估计(mle)方法来估计模型的参数。实验结果指出在同其它软件可靠性模型相比时,提出的基于信息熵的二维软件可靠性增长模型有最好的拟合和预测性能,能够准确地拟合和预测在软件测试过程中的故障发生的数量,并且能够有效地改善一般二维软件可靠性增长模型的性能。
表2.故障数据集1(ds1)
表3.故障数据集2(ds2)
- 还没有人留言评论。精彩留言会获得点赞!