化身呈现方法及电子设备与流程
本公开涉及人工智能领域,更具体地,涉及一种化身呈现方法及电子设备。
背景技术:
随着人工智能技术的发展,人工智能聊天机器人已经广泛应用在各个行业中。在实际应用中,用户通过语音输入的方式向智能机器人发布指令,智能机器人通过语音识别技术接收并识别语音指令来为用户提供各种服务或做出相应的响应。为了使得用户和人工智能聊天机器人的交互变得更加准确,需要对用户与智能机器人的交互方式进行开发。
技术实现要素:
提供本公开的实施例内容是为了以精简的方式介绍将在以下详细描述中进一步描述的一些概念。本公开内容并不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要保护主题的范围。
本公开的基于通过使用经过训练的神经网络模型对用户与化身的互动时的相关信息的分析结果来呈现化身的技术方案,通过将用户的表情、用户的姿势、用户所处的环境以及用户与化身的聊天信息、互动时长等应用于呈现化身的方案之中,使得化身能够根据结合多种分析结果更精确地对用户的需求进行响应。
上述说明仅是本公开技术方案的概述,为了能够更清楚了解本公开的技术手段,而可依照说明书的内容予以实施,并且为了让本公开的上述和其他目的、特征和优点能够更明显易懂,以下特举本公开的具体实施方式。
附图说明
图1为本公开的实施例的化身呈现的技术方案的示意图;
图2为本公开的实施例的化身呈现方法的流程图;
图3为本公开的实施例的根据用户的表情呈现更新后的化身的示例性场景的示意图;
图4为本公开的实施例的神经网络模型的示意图;
图5为本公开的实施例的根据环境信息呈现化身的示例性场景的示意图;
图6为根据本公开的实施例的根据环境信息调整化身的背景的示例性场景的示意图;
图7为本公开的实施例的在更新后的化身的背景中呈现用户与更新后的化身的组合图像的示例性场景图的示意图;
图8为本公开的实施例的根据用户的姿势呈现更新后的化身的示例性场景的示意图;
图9为根据本公开的实施例的化身根据聊天信息控制外部设备的示例性场景的示意图;
图10为本公开的实施例的根据互动时长的变化呈现化身的示意图;以及
图11为本公开的实施例的电子设备的框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解的是,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
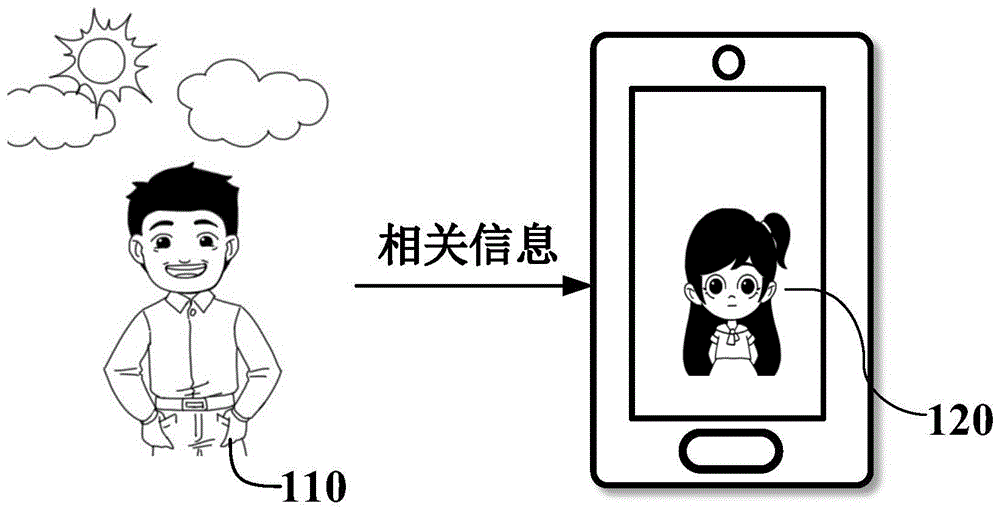
图1为本公开的实施例的化身呈现的技术方案的示意图。应当理解的是,图1中所示出的示意图仅仅是示例性的,而不应当构成对本公开所描述的实现的功能和范围的任何限制。如图1所示,电子设备向用户110提供用户所需要的服务,例如可以获取包括指示用户所选服务的服务模式信息,并且根据获取到的指示用户所选服务的服务模式信息为用户110呈现与所选服务相对应的化身120,并且根据与用户110之间进行互动时的相关信息对化身120进行更新,并且呈现更新后的化身。
需要注意的是,本公开中的化身可以是在电子设备的屏幕中呈现的虚拟人物形象,也可以是通过vr技术所呈现出来的虚拟人物形象,或者可以是实体机器人,在本公开中对化身的具体实现方式不作任何限定。
下面将进一步结合附图对本公开的实施例的化身呈现的技术方案进行详细说明。
图2为本公开的实施例的化身呈现方法的流程图。参考图2,本公开的实施例的化身呈现方法具体包括以下步骤:
步骤s210,呈现与服务模式相关的化身。
在步骤s210中,用户通过语音输入、文本输入、触摸输入、悬停输入等方式选择所需要的服务模式,电子设备接收用户的包含指示所选服务模式的指令并根据用户所选服务模式向用户呈现与用户所选服务模式相对应的化身。
其中,所述服务模式可以包括电子设备通过化身呈现的聊天应用服务、音乐应用服务、新闻应用服务等。
在一个实施例中,用户通过语音指令的方式选择聊天服务模式,电子设备根据用户所选聊天服务模式向用户呈现与聊天服务相关的化身,例如以化身方式呈现的聊天应用等。
步骤s220:在用户与化身互动时获取相关信息。
在步骤s220中,在电子设备向用户呈现与用户所选服务模式相关的化身之后,电子设备还可以在用户与化身进行互动时获取相关信息。其中该相关信息可以指的是用户在化身互动过程中的用户的图像(用户的静止图像或运动图像)、用户与化身互动时的聊天信息、用户与化身互动的互动时长。
用户的图像可以反映出用户的表情、用户的姿势以及用户的环境信息。
用户的表情例如可以是用户在与化身进行互动时的中性、微笑、咧嘴、悲伤、惊讶、厌恶、愤怒、蔑视、恐惧、大笑和痛苦等能够表示用户的情绪的表情。
用户的姿势例如可以是用户在与化身进行互动时的头部姿势(例如,点头或摇头等)、手部姿势(例如,挥手等)以及人体姿势(例如,拥抱等)。
环境信息例如可以是用户所处的环境的信息,例如,室内环境(例如卧室等)或室外环境(例如公园等)。此外,环境信息还可以包括用户所处的环境中可以指示天气的信息(例如,用户所处的环境中出现的太阳、雪花、雨点等)。
步骤s230:获取利用经过训练的神经网络模型对相关信息进行分析得到的分析结果。
在步骤s230,在向用户提供了与用户所选服务模式相对应的化身之后,还可以使用神经网络模型对获取到的相关信息进行分析,预测用户的行为、态度、情感和意图等,以便根据分析结果做出响应。
具体地,经过训练的神经网络模型可存储于电子设备本地,也可存储于云端服务器中。当经过训练的神经网络模型可存储于电子设备本地时,将相关信息输入本地经过训练的神经网络模型进行分析识别,从而得到分析结果。当经过训练的神经网络模型可存储于云端的服务器时,终端设备向云端服务器发送分析请求,该分析请求中包括相关信息,云端服务器响应于该分析请求,将相关信息输入经过训练的神经网络模型进行分析识别,从而得到分析结果,并将分析结果作为分析请求的反馈信息返回至该电子设备。
步骤s240:根据分析结果更新化身,并呈现更新后的化身。
在步骤s240,电子设备根据分析结果,例如分析出用户的表情是开心的还是不开心的、所处的环境是室内还是室外、用户的动作所表达的含义等来对用户进行响应,对化身进行更新,并向用户呈现更新后的化身。
上述呈现化身的方法由于可以通过对相关信息进行分析,综合用户的行为、态度、情感和意图等多方面的因素来对化身进行更新,因此能够更准确和智能地对用户进行响应,提高了用户与化身互动的浸入感。
以上通过结合图2的化身呈现方法的流程图介绍了本公开的实施例的具体流程,下面进一步结合图3至图10对呈现更新后的化身的技术方案分别进行详细说明。
图3为本公开的实施例的根据用户的表情呈现更新后的化身的示例性场景的示意图。
在图3的示例性应用场景中,化身320是例如可以显示在电子设备330内的一个女孩的形象。在用户310与化身320进行互动的过程中,可以通过电子设备330的相机获取用户310的图像,并通过经过训练的神经网络模型对获取到的用户310的图像进行分析,识别出用户的表情。例如,如果用户310在与化身320进行互动时呈现的是微笑的表情,则电子设备330的相机可以拍摄用户的微笑的照片或者视频,使用设置在电子设备内或者来自云端服务器的经过训练的神经网络模型对拍摄的照片或视频进行分析,识别出照片或视频中的用户的表情为“微笑”,根据识别出的表情“微笑”从设置在电子设备内或者来自云端服务器的表情数据库中检索与该“微笑”的表情相对应的表情模式,将化身的表情更新为“微笑”或者与“微笑”的表情相对应的表情,并且向用户呈现具有与用户的“微笑”表情相对应的表情的化身,例如向用户310呈现如图3中示出的具有微笑的表情的化身。
进一步地,在用户与化身的聊天互动中,电子设备可以实时地获取用户的图像,并根据对图像的实时的分析对化身所呈现的表情进行调整。例如,当根据用户愤怒的图像预测出用户“愤怒”的表情时,可以从设置在电子设备内或者来自外部服务器的表情数据库中获取与该“愤怒”的表情相对应的表情模式,将化身的表情更新为与用户的“愤怒”的表情相对应的表情,并且向用户呈现该对应的表情,例如,化身可以呈现与“愤怒”相对应的“恐惧”的表情。
进一步地,在一个实施例中,还可以从电子设备内或者来自云端服务器的动作数据库中获取与“恐惧”的表情相对应的动作模式(颤抖),从而根据与“愤怒”的表情相对应的表情模式(恐惧)和动作模式(颤抖)更新化身的表情以及动作,并向用户呈现更新后的化身,例如更新后的化身不仅具有“恐惧”的表情,还可以具有表示“恐惧”含义的“颤抖”的动作。
进一步地,在一个实施例中,在识别用户的表情时,具体可以使用卷积神经网络(cnn)模型来识别用户的表情。图4为本公开的实施例的神经网络模型的示意图。
如图4所示,该卷积神经网络模型包括一个输入层、多个卷积层(例如卷积层420或440)、最大池化层430、多个全连接层(例如,全连接层450和460)。首先,预先从表情数据库中提取人脸的面部表情图像,对提取出的人脸表情图像进行预处理,例如,对人脸的面部表情图像进行归一化处理从而获得具有人脸关键特征点的图像样本,将所获得的图像样本作为训练样本输入到cnn的卷积层通过对神经网络模型的权重的调整完成表情识别的cnn模型的训练。当电子设备的相机拍摄到用户的表情照片之后,将该表情照片输入到该训练好的cnn模型中进行预测,如果识别拍摄的用户的照片(例如,用户微笑的照片)中的表情为“微笑”的预测值大于某阈值,则确定该用户的表情为“微笑”。
在识别出用户的表情后,电子设备可以从电子设备内或者来自云端服务器的表情数据库中提取出与该用户的表情相对应的表情模式并通过化身呈现该表情。
进一步地,电子设备具体呈现表情的方式可以包括:提供与人类的面部表情相对应的基本面部元素,例如可以提供不同大小和形状的眉毛、鼻子、眼睛、上嘴唇、下嘴唇、牙齿、脸颊轮廓、鼻子下方等基本面部元素。当从表情数据库中获取到与用户的表情相对应的表情模式时,可以根据获取到的对应的表情对上述的全部或一些基本面部元素进行组合,从而呈现该表情模式。例如,化身的面部可以由上述基本面部元素构成,当识别出用户的“微笑”的表情时,可以通过仅调整上嘴唇和下嘴唇这两个的面部基本元素来呈现化身的微笑的表情。可选地,电子设备还可以根据识别到的用户的表情实时地绘制化身的表情,并将实时绘制的表情呈现给用户。
进一步地,电子设备还可以根据用户的图像呈现与用户的形象相关联的化身。例如,电子设备可以生成与用户的形象相似的形象。可选地,本公开的实施例还可以根据用户的偏好生成用户喜爱的形象,从而使得用户觉得更新后的化身更亲切和真实,从而提高了用户体验。
进一步地,电子设备还可以分析出相关信息中的环境信息,并呈现该环境信息对应的化身,以下结合图5详细描述根据环境信息呈现更新的技术方案。
图5为本公开的实施例的呈现与环境信息对应的化身的示例性场景的示意图。
参考图5,用户510所处的环境为一个室外的下雪的环境,因此用户510具有“羽绒服”540这一特征,并且用户的所处的环境具有“雪花”530这一环境信息。化身是例如可以显示在电子设备的显示器内的一个女孩的动画形象。在该实施例中,通过电子设备的相机拍摄用户的图像,并使用经过训练的神经网络模型分析所拍摄的用户的图像,识别出例如“雪花”530或与其对应的“下雪”这样的环境信息,并根据“雪花”530或与其对应的“下雪”这样的环境信息确定用户510所处的是一个寒冷的室外环境,从而为化身520添加与该寒冷的环境相对应的环境特征,例如为化身添加如图5中所示的环境特征“围巾”550等。此外,本公开的实施例还可以结合所识别出的用户的“羽绒服”540这一环境特征来为化身添加环境特征“围巾”550,并向用户510呈现更新后的具有“围巾”550的化身520。
进一步的,如果电子设备识别出用户所处的环境为一个室外的下雨的环境,则可以为化身添加与“雨点”或其对应的“下雨”的环境信息相对应的环境特征“雨伞”。
具体地,在电子设备识别用户所处的环境时,具体可以通过神经网络模型对用户所处的环境进行识别。例如可以通过参考例如图4中的表情识别的cnn模型训练一个对象检测的cnn模型。通过向cnn模型提供训练数据,并通过反向传播调整神经网络模型的权重来提高对象检测的准确性。例如,在使用电子设备的相机获取到用户的图像后,可以提取出“雪花”530这个对象,获取对象“雪花”530的特征(例如,纹理、形状等颜色),并将提取出的特征输入到训练好的对象检测的cnn模型中,如果预测的结果超过预测阈值,则可以确认所识别出的对象为“雪花”,并从电子设备或者来自云端服务器的图像数据库中提取与对象“雪花”530相关联的图片或者实时生成与“雪花”相关联的图片,并呈现更新后的背景中具有“雪花”530这一环境特征或与“雪花”相关联的环境特征的化身。
需要注意的是,在本公开的技术方案中,还可以基于不同的训练数据分别训练多个神经网络模型来分别对用户的姿势、与用户的姿势相关联的对象等进行识别,具体可以参考图4的识别表情的神经网络模型的结构进行训练,为了避免重复,省略了对使用不同的神经网络模型对用户的姿势以及与用户的姿势相关联的对象的识别的过程的描述。
进一步地,电子设备还可以分析出相关信息中的环境信息,并根据识别出的环境信息对化身的环境进行调整,以下结合图6详细描述根据用户的环境信息调整化身的背景的技术方案。
图6为根据本公开的实施例的根据环境信息调整化身的背景的示例性场景的示意图。
参考图6,用户610所处的环境是一个室外的太阳630下的环境,而化身620的背景是一个室内的卧室的环境,化身620的背景中包括例如床、窗户、相框等卧室场景中常见的对象。
在用户610与化身620的互动过程中,通过电子设备的相机拍摄用户610的图像,通过经过训练的神经网络模型从拍摄到的用户610的图像中识别出用户610的环境信息,例如从用户610的图像中识别出环境信息“太阳”630,则确定化身620的背景也具有环境信息“太阳”630,并且将该环境信息“太阳”630对应的图像640添加到化身620的背景中,例如将“太阳”630对应的图像640添加到图6的化身620的卧室背景的窗外,从而使得用户与化身的环境保持一致。
进一步地,在一个实施例中,如果电子设备从上述图5的用户的图像中识别出环境信息“下雪”或“下雨”时,可以确定用户所处环境的天气为“雨/雪天”时,则电子设备可以将“雪花”和“雨点”这些表示“雨/雪天”的环境信息添加的化身的背景中,例如将“雪花”和“雨点”添加到图6的化身的卧室背景中的窗外。
在本公开的实施例中,根据用户的环境信息对化身以及化身的背景进行调整,可以使化身以及化身的背景与用户的环境保持一致,使得化身及其背景与用户关联性更高,互动性更好,从而提升了用户体验。
进一步地,本公开的实施例还可以在更新后的化身的背景中呈现用户与更新后的化身的组合图像。以下将结合图7详细描述该方案。
图7为本公开的实施例的在更新后的化身的背景中呈现用户与更新后的化身的组合图像的示例性场景图的示意图。
参考图7,在电子设备获得用户710的图像后,可以生成用户710与化身720的合影,并且将该合影添加到化身720的卧室背景的相框730中,使得用户与化身的互动更加的真实,使得用户可以有身临其境的感觉。
进一步地,在电子设备获取到用户的图像后,还可以使用经过训练的神经网络模型,分析用户的图像以识别出用户的姿态,并根据用户的姿势,更新化身的姿势,并呈现更新后的化身的姿势,并且还可以识别出与用户的姿势相关联的对象,根据用户的姿势以及与用户的姿势相关联的对象更新化身,并呈现更新后的化身的姿势以及相关联的对象,以下将结合图8详细描述该技术方案。
图8为本公开的实施例的根据用户的姿势呈现更新后的化身的示例性场景的示意图。在图8所示的场景中,用户810手中托着一份“礼物”,当用户810靠近电子设备的显示器830并做出将手中的“礼物”靠近显示器830的动作时,电子设备使用经过训练的神经网络模型识别出用户810“靠近显示器并将手伸向显示器”的动作以及与用户810的动作相关联的对象“礼物”840,并且可以结合用户的语音信息“生日快乐”,分析出用户810的意图是“送一份生日礼物”,电子设备根据分析出的用户的意图从电子设备中的或来自外部服务器的视频数据库获取与“送一份生日礼物”这一意图相对应的动作,并根据获取到的动作更新化身,并向用户呈现更新后的化身,例如,电子设备可以呈现出接收了用户的“礼物”850的动作的化身并同时生成语音信息“谢谢”,并播放该语音信息。本公开的该实施例通过根据用户的姿势以及与姿势相对应的对象呈现更新后的化身,可以使得用户和化身之间的互动更加的真实,增强了用户与化身互动的浸入感。
在一个实施例中,当电子设备识别出用户的手势(例如,挥手的手势)时,可以呈现出化身做出与该挥手的手势相对应的响应动作。例如,根据用户和化身互动的上下文情景的不同,当识别出用户的挥手的手势(例如,该挥手的手势表示用户与化身打招呼或告别)时,可以呈现通过挥手的方式向用户打招呼或者告别的化身或者以语音输入的方式回复用户“您好”或者“再见”的信息。
在一个实施例中,如果电子设备识别出用户的“拥抱”的动作时,化身也可以呈现相对应的“拥抱”的动作,并且在识别出“拥抱”的动作的同时,还可以识别出用户的表情(例如,微笑的表情),并且在响应用户的“拥抱”的动作的同时,向用户呈现“微笑”的表情。
在一个实施例中,电子设备还可以从用户的手势中检测出该手势所代表的含义。例如,当用户与化身进行互动的过程中涉及到与数字相关的表达时,除了通过语音输入或者文本输入的方式表达时,还可以使用手势表达该数字。例如,当用户向化身展示“五指张开”的手势时,电子设备识别出该手势表示数字“五”;当用户向化身展示“张开拇指和食指并且闭合小拇指、无名指以及中指”的手势时,识别出该手势表示数字“八”,当用户向化身展示“握紧拳头”的手势时,识别出该手势表示数字“十”。在识别出用户的表达中文数字的手势后,通过结合用户的聊天信息,可以对用户与化身的互动进行补充,能够更准确地理解用户的意图,使得向用户呈现出的化身更加的准确和智能。
在一个实施例中,在用户与化身进行互动的过程中,用户可以与化身进行游戏互动,并且可以通过识别用户的手势与用户进行游戏。例如,在传统的“剪刀、石头、布”的游戏中,电子设备可以识别游戏“剪刀、石头、布”中“剪刀”、“石头”、“布”分别对应的三种手势,并根据用户的手势进行响应。
在一个实施例中,当使用经过训练的神经网络模型识别出用户的头部姿势时(例如,点头或摇头的姿势,其中点头对应用户表示的积极的态度,而摇头对应用户表示的消极的态度),可以呈现的化身做出与该用户的头部姿势相对应的响应。例如,当需要根据用户的态度来对用户进行响应时,由于用户所处环境的噪音的影响或者化身获得的数据不充分和不准确而导致化身对用户的响应不准确时,可以通过电子设备的相机等来检测用户的头部姿势,如果检测到用户的头部姿势是用户点头的姿势时,则表示用户的态度是积极的态度,如果检测到的是用户的摇头的姿势时,则表示用户的态度是消极的态度。根据用户与化身互动的上下文的聊天信息并且结合用户的头部姿势所表达的态度,可以更精确地了解用户的意图,从而可以呈现更精确以及更智能化的化身。
进一步地,相关信息还可以包括聊天信息,呈现化身的方法还可以包括获取利用神经网络模型对聊天信息进行分析得到的化身的意图,并控制外部设备执行与该意图相应的操作。以下将结合图9详细描述化身根据聊天信息控制外部的技术方案。
图9为根据本公开的实施例的根据聊天信息呈现化身的示例性场景的示意图。
在上述图8的示例性场景中,当电子设备呈现出化身接收到用户的“礼物”的情形后,为了对用户表示感谢,在聊天信息中提及“送用户一张感谢卡片”,通过经过训练的神经网络模型分析该聊天信息并从该聊天信息中提取出化身“送用户一张感谢卡片”的意图,根据化身的意图执行与“送用户一张感谢卡片”相对应的操作,例如控制外部设备(例如图9中的打印机920)通过网络向用户提供“感谢卡片”930。可选地,本公开的实施例还可以在化身900的背景中显示卡片910。
在一个实施例中,在智能家居系统的环境下,电子设备还可以使用经过训练的神经网络模型分析用户与化身互动时的聊天信息,提取出化身控制各种家用电器的意图,并生成控制家用电子的控制指令,并根据控制指令来控制智能家居系统中的家用电器,例如、空调、电视、灯泡等。
进一步地,本公开的技术方案还可以根据分析结果以及用户与化身的互动时长,更新并呈现更新后的化身,该更新后的化身具有与互动时长对应的年龄特征。以下将结合图10详细描述根据互动时长呈现更新后的化身的技术方案。
图10为本公开的实施例的根据互动时长的变化呈现化身的示意图。
在一个实施例中,电子设备可以记录用户与化身互动的互动时长,并且根据互动时长的变化为化身配置不同的年龄特征,其中该年龄特征可以反映化身外观上的成长。在本实施例中,可以设置以下互动时长与化身年龄的映射,例如设置为:
互动时长0.5小时对应于2岁的化身;
互动时长1小时对应于3岁的化身;
……
……
活动时长10小时对应于17岁的化身;
……
并且为各个年龄的化身分别配置不同的年龄特征,例如,如图10所示,左图中的化身1010为互动时长为1小时的3岁的化身,右图中的化身1020为互动时长为10小时的17岁的化身,其中化身1010可以配置有与3岁的儿童相应对的反映年龄的外观特征,例如短发、豁牙、比较矮小的身高以及其所穿着的较为幼稚的服装等外观特征;而化身1020可以配置有与17岁的少年相对应的反映年龄的外观特征,例如长发、已经长出了新牙、较高的身高以及所穿着的较为成熟的服装等外观特征。
进一步地,在本公开的实施例中电子设备还可以调用与年龄特征相对应的聊天模型来呈现更新后的化身的聊天信息,从而使得化身的思想也随着互动时长的变化而成长。
参考图10,例如,用户在为具有不同的互动时长的化身配置相应的年龄的外观特征的同时,可以继续配置与该外观特征对应的思想特征。也就是说,可以建立一个互动时长、化身年龄、年龄对应的外形特征以及年龄对应的思想特征的映射。例如,可以预先配置为:互动时长为1小时对应化身的年龄为3岁的儿童,与3岁的年龄对应的形象特征为图10中左图中的化身1010,其对应的思想特征为一个初级语言库,该初级语言库可以包括普通的3岁的儿童的常用字、词汇以及句子,其中由于3岁的儿童的学习能力的局限性,其常用的句子可能会出现一些语法错误。或者在本公开的实施例中,可以在该初级语言库中预先配置包括语法错误的表述,以使得化身1010的语言表述更符合3岁的儿童的身份。例如,当用户向化身询问年龄时,图10中的化身1010回答的“3岁了,我,今年”的表述基本清楚但存在着明显的语法错误。
在本公开的实施例中还可以预先配置:用户与化身的互动时长为10小时对应的化身的年龄为17岁的少年,与17岁的年龄对应的形象特征为图10中右图中的化身1020,其对应的思想特征为一个高级语言库,该高级语言库可以包括普通的17岁的少年的常用的字、词汇以及常用的完整的句子。例如,当用户询问化身的年龄时,图10中的化身1020的回答为与化身1010的表达相比表述更加清楚并且没有任何语法错误的表示“我今年17岁”。
应该注意的是,虽然在本公开的实施例中使用的都是女孩形象的化身,但是在本公开的实施例中并不对化身的性别进行任何限制,并且本公开的实施例也不对互动时长与化身的年龄特征的映射并不作任何限制,可以根据实际需要通过互动时长的变化来呈现的具有不同年龄特征的化身。
通过根据互动时长的变化为对化身的外形和思想进行调整,可以使得化身表现的更加自然和逼真,使得用户可以感觉到化身在伴随着用户的成长而成长,从而提高了用户与化身互动的浸入感。
图11为本公开的实施例的电子设备1100的框图,该电子设备包括存储器1110和处理器1120。其中,存储器1110用于执行上述操作的程序,还可以配置为存储其他数据以支持在电子设备1100上的操作,这些数据的示例包括在电子设备1100上操作的任何应用程序或方法的指令、联系人数据、消息、图片、视频等。
存储器1110可以是易失性存储器(例如寄存器、高速缓存、随机访问存储器(ram))、非易失性存储器(例如,只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、闪存)或其某种组合。存储器可以包括一个或多个程序模块,这些程序模块被配置为执行本文所描述的各种实现的功能。计算机模块可以由处理单元访问和运行,以实现相应的功能。存储设备可以是可拆卸或不可拆卸的介质,并且可以包括机器可读介质,其能够用于存储信息和/或数据并且可以在电子设备内被访问。
处理器1120可以是实际或虚拟处理器,并且能够根据存储器中存储的程序来执行各种处理。处理单元也可以被称为中央处理单元(cpu)、微处理器、控制器、微控制器。
存储器1110耦合至处理器1120并且存储有指令,该指令在由处理器1120执行时使得电子设备1100:呈现与服务模式相关的化身;在用户与化身互动时获取相关信息;获取利用经过训练的神经网络模型对相关信息进行分析得到的分析结果;以及根据分析结果更新化身,并呈现更新后的化身。
其中,该相关信息可以为用户的图像以及聊天信息以及用户与化身的互动时长。
在一个实施例中,电子设备获取利用神经网络模型对用户的图像进行分析得到的用户的表情;根据用户的表情更新化身。
在一个实施例中,电子设备获取利用神经网络模型对用户的图像进行分析得到的环境信息,根据环境信息更新化身。
在一个实施例中,电子设备使化身的背景对应于环境信息。
在一个实施例中,电子设备获取利用神经网络模型对用户的图像进行分析得到的用户的姿势,根据用户的姿势,更新化身。
在一个实施例中,电子设备还获取利用神经网络模型对用户的图像进行分析得到的与用户的姿势相关联的对象,并呈现该对象。
在一个实施例中,电子设备获取利用神经网络模型对聊天信息进行分析得到的化身的意图,并控制外部设备执行与意图相应的操作。
在一个实施例中,电子设备根据分析结果以及用户与化身的互动时长,更新化身,更新后的化身具有与互动时长对应的年龄特征。
在一个实施例中,电子设备调用与年龄特征相对应的聊天模型来呈现更新后的化身的聊天信息。
在一个实施例中,电子设备生成用户与更新后的化身的组合图像,并在更新后的化身的背景中呈现组合图像。
对于上述的处理操作,在前面的方法实施例以及具体应用场景的实施例中已经进行了详细说明,对于上述的处理操作的详细内容同样也适用于电子设备1100中,即可以将前面描述的实施例中的提到的具体处理操作以程序的方式写入在处理器中1110中,并通过处理器1120来进行执行。
进一步地,在一些实施例中,该电子设备被实现为各种用户终端或服务终端。服务终端可以是各种服务方提供的服务器、大型电子设备。用户终端诸如是任何类型的移动终端、固定终端或便携式终端,包括移动手机、多媒体计算机、多媒体平板、互联网节点、通信器、台式计算机、膝上型计算机、笔记本计算机、上网本计算机、平板计算机、个人通信系统(pcs)设备、个人导航设备、个人数字处理(pda)、音频/视频播放器、数码相机/摄像机、定位设备、电视接收器、无线电广播接收器、电子书设备、游戏设备或其任意组合,包括这些设备的配件和外设或者其任意组合。此外,电子设备能够支持任何类型的针对用户的接口(诸如,可穿戴设备)。
进一步地,在一些实施例中,如图11所示,电子设备1110还可以包括通信模块1130、电源模块1140、音频模块1150、显示器1160、总线1170、相机模块1180等其他组件。应当注意的是,图11仅示意性地给出部分组件,并不意味着电子设备1100只包括图11所示的组件。
通信模块1130被配置为便于电子设备1100和其他设备之间有线或无线方式的通信。电子设备1100可以接入基于通信标准的无线网络,例如wifi、lte以及5g等或它们的组合。在一个示例性实施例中,通信模块1130经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,通信模块1130还包括近场通信(nfc)模块以进行短程通信。例如,在nfc模块可基于射频识别(rfid)技术、红外数据协会(irda)技术、超宽带(uwb)技术、蓝牙(bt)技术和其他技术来实现。
电源模块1140,为电子设备1100的各种组件提供电力。电源模块1140可以包括电源管理系统、一个或多个电源以及他与为电子设备生成、管理和分配电力相关联的组件(例如,以无线或有线方式为电子设备供电的充电器)。
音频模块1150被配置为输出和/或输入音频信号。例如,音频模块1150包括一个麦克风(mic),当电子设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收来自用户的音频信号。所接收的音频信号可以被进一步存储在存储器1110或经由通信模块1130发送。在一些实施例中,音频模块1150还包括一个扬声器,用于输出用户与化身互动时的音频信号。
显示器1160包括屏幕,该屏幕可以配置为呈现化身,该屏幕可以包括液晶显示器(lcd)和触摸面板。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与触摸或滑动操作相关的持续时间和压力。
相机模块1180其被配置为向化身提供用户的图像。
上述的存储器1110、处理器1120、通信模块1130、电源模块1140、音频模块1150、显示器1160以及相机模块1180可以与总线1170连接。总线1170可以提供处理器1120与电子设备1100中的其余组件之间的接口。此外,总线1170还可以提供电子设备1100中的各个组件对存储器1110的访问接口以及各个组件间相互访问的通讯接口。
本文中以上描述的功能可以至少部分地由一个或多个硬件逻辑部件来执行。例如,非限制性地,可以使用的示范类型的硬件逻辑部件包括:现场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、片上系统(soc)、复杂可编程逻辑设备(cpld)等等。
示例性条款
一种化身呈现方法,包括:
呈现与服务模式相关的化身;
在用户与所述化身互动时获取相关信息;
获取利用经过训练的神经网络模型对所述相关信息进行分析得到的分析结果;以及
根据所述分析结果更新所述化身,并呈现更新后的化身。
在一个实施例中,所述相关信息包括用户的图像;获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的所述用户的表情;更新所述化身包括:根据所述用户的表情更新所述化身。在一个实施例中,所述相关信息包括用户的图像;获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的环境信息;更新所述化身包括:根据所述环境信息更新所述化身。
在一个实施例中,呈现更新后的化身包括:使所述化身的背景对应于所述环境信息。
在一个实施例中,所述相关信息包括用户的图像;获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的所述用户的姿势;更新所述化身包括:根据所述用户的姿势,更新所述化身。在一个实施例中,还获取利用所述神经网络模型对所述用户的图像进行分析得到的与所述用户的姿势相关联的对象;呈现更新后的化身包括:呈现所述对象。
在一个实施例中,所述相关信息包括聊天信息;获取所述分析结果包括:获取利用所述神经网络模型对所述聊天信息进行分析得到的所述化身的意图;该方法还包括:控制外部设备执行与所述意图相应的操作。
在一个实施例中,根据所述分析结果更新所述化身包括:根据所述分析结果以及所述用户与所述化身的互动时长,更新所述化身,所述更新后的化身具有与所述互动时长对应的年龄特征。
在一个实施例中,该方法还包括:调用与所述年龄特征相对应的聊天模型来呈现所述更新后的化身的聊天信息。
在一个实施例中,该方法还包括:生成所述用户与所述更新后的化身的组合图像,并在所述更新后的化身的背景中呈现所述组合图像。
一种电子设备,包括:处理器;以及存储器,所述存储器耦合至所述处理器并且存储有指令,所述指令在由所述处理器执行时使所述电子设备:呈现与服务模式相关的化身;在用户与所述化身互动时获取相关信息;获取利用经过训练的神经网络模型对所述相关信息进行分析得到的分析结果;以及根据所述分析结果更新所述化身,并呈现更新后的化身。
在一个实施例中,所述相关信息包括用户的图像;获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的所述用户的表情;更新所述化身包括:根据所述用户的表情更新所述化身。
在一个实施例中,所述相关信息包括用户的图像;
获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的环境信息;更新所述化身包括:根据所述环境信息更新所述化身。
在一个实施例中,呈现更新后的化身包括:使所述化身的背景对应于所述环境信息。
在一个实施例中,所述相关信息包括用户的图像;获取所述分析结果包括:获取利用所述神经网络模型对所述用户的图像进行分析得到的所述用户的姿势;更新所述化身包括:根据所述用户的姿势,更新所述化身。
在一个实施例中,所述指令在由所述处理器执行时,使所述电子设备还获取利用所述神经网络模型对所述用户的图像进行分析得到的与所述用户的姿势相关联的对象;呈现更新后的化身包括:呈现所述对象。
在一个实施例中,所述相关信息包括聊天信息;获取所述分析结果包括:获取利用所述神经网络模型对所述聊天信息进行分析得到的所述化身的意图;所述指令在由所述处理器执行时使所述电子设备控制外部设备执行与所述意图相应的操作。
在一个实施例中,根据所述分析结果更新所述化身包括:根据所述分析结果以及所述用户与所述化身的互动时长,更新所述化身,所述更新后的化身具有与所述互动时长对应的年龄特征。
在一个实施例中,所述指令在由所述处理器执行时使所述电子设备:调用与所述年龄特征相对应的聊天模型来呈现所述更新后的化身的聊天信息。
在一个实施例中,所述指令在由所述处理器执行时使所述电子设备:生成所述用户与所述更新后的化身的组合图像,并在所述更新后的化身的背景中呈现所述组合图像。
用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
在本公开的实施例的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)、闪存、光纤、便捷式紧凑盘只读存储器(cd-rom)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
此外,虽然采用特定次序描绘了各操作,但是这应当理解为要求这样操作以所示出的特定次序或以顺序次序执行,或者要求所有图示的操作应被执行以取得期望的结果。在一定环境下,多任务和并行处理可能是有利的。同样地,虽然在上面论述中包含了若干具体实现细节,但是这些不应当被解释为对本公开的范围的限制。在单独的实现的上下文中描述的某些特征还可以组合地实现在单个实现中。相反地,在单个实现的上下文中描述的各种特征也可以单独地或以任何合适的子组合的方式实现在多个实现中。
尽管已经采用特定于结构特征和/或方法逻辑动作的语言描述了本主题,但是应当理解所附权利要求书中所限定的主题未必局限于上面描述的特定特征或动作。相反,上面所描述的特定特征和动作仅仅是实现权利要求书的示例形式。
本领域技术人员可以理解的是,可以替换、改变、组合或删除本发明的实施例中讨论的操作、方法、流程中的步骤、措施和技术方案。此外,还可以替换、改变、重新排列、组合或删除本发明中讨论的操作、方法、流程中的其他步骤、措施和技术方案。此外,还可以替换、改变、重新排列、组合和移除具有本发明中讨论的操作、方法、流程中的其他步骤、措施和技术方案的现有技术。
因此,尽管已经关于特定实施例描述了本公开,但是应当理解,本公开旨在覆盖所附权利要求范围内的所有修改和等同物。
- 还没有人留言评论。精彩留言会获得点赞!