一种基于多示例主动学习的代表性图像选取方法与流程
本发明涉及机器学习领域,具体涉及一种基于多示例主动学习的代表性图像选取方法。
背景技术:
随着互联网技术的快速发展,借助各种互联网工具,人们可以从互联网快速获取大量数据,然而从互联网获取的数据也通常伴随着较多的噪声及大量的内容冗余。在机器学习算法的训练过程中,如果不对原始数据进行清洗而直接标注,不仅将造成大量人力资源浪费,而且由于噪声的影响算法难以达到期望的训练效果。利用弱监督学习强大的分析能力,可以先对获取的原始数据集进行筛选。
根据训练数据标注的程度,可将机器学习分为强监督学习、弱监督学习、无监督学习三种。强监督学习中每个训练样本都有唯一与其对应的正确的标签,应用有检测、分类等;无监督学习只有训练样本,没有标签,应用有聚类、降维;弱监督学习介于两者之间,并非所有样本都有正确的标签,应用有主动学习、多示例学习等。
1997年dietterich等人在研究药物分子活性检测时提出了多示例学习模型(dietterich,thomasg.;lathrop,richardh.;lozano-pérez,tomás,solvingthemultipleinstanceproblemwithaxis-parallelrectangles,artificialintelligence,1997,89(1–2):31–71)。对于传统监督学习,所有训练数据都有唯一的与其对应的标签。在药分子活性预测问题中,科学家只能确认具有活性的药分子,而不能具体确定是哪种结构使其有效。因此在传统监督学习的条件下,需要将适于制药的药分子作为正样本,不适于制药的药分子作为负样本,此时学习模型认为正样本中所有结构都是有效的。然而正样本实际包含有大量无效的分子结构,大量的假正例导致正样本中包含大量噪声,从而导致学习失败。为解决该问题,dietterich等人提出多示例学习模型,在多示例学习中,每个药分子被抽象成一个包,而药分子的多种结构抽象成多个示例。多示例学习中,只有包有与其对应的标签,包中的实例没有。在dietterich等人的定义中,只要包中至少包含一个正样本的示例,则将该包标记为正包,否则标记为负包。
主动学习的目的是在不降低分类器精度的情况下降低人工标注的成本。数据集中不同的样本对于分类器分类精度的贡献不同,如svm中靠近决策边界的样本点对于分类器的贡献大,而远离决策边界的样本点对分类器的贡献小。主动学习方法正是寻找这些对分类器精度贡献较大的样本,并且在此过程中滤除一部分噪声样本,因此主动学习不仅能有效地降低人工标注的成本,还可以提升分类器的分类精度。在主动学习过程中,初始化时需要有一部分有标签数据,使用这部分有标签数据训练分类器,然后使用分类器对未标注数据进行预测,根据预测结果和未标注数据的采样策略,从未标注数据中选择对分类器分类精度影响最大的样本进行人工标注,最后将新标注的样本放入训练数据集中进行迭代,直到分类器的分类精度不再变化。
多示例学习通过学习已知包的分布,对未知包标签进行预测。利用主动学习方法分析使包变成正包的关键示例,从而从这些关键示例中选择代表性图像。目前公开的专利中代表性图像选取方法主要集中在聚类方法的优化,有些方法仍需要手动参与标注。申请号为cn201310300591的专利公开了一种基于聚类和投票机制的主动学习初始样本选择方法。该方法通过聚类将原始图像集合划分为多个簇,对聚类簇进行高斯混合模型建模,利用高斯混合模型中的高斯混合分量对每个簇划分多个代表性区域;然后根据样本与代表性区域的关系为代表性区域投票,最终选择投票最多的代表性区域中的样本作为初始训练样本。申请号为cn105469118a的专利公开了一种基于核函数的融合主动学习和非参半监督聚类的稀有类别检测方法。该方法通过学习数据集的距离度量函数,得到核矩阵;再结合核矩阵对原始数据集进行非参层次聚类,然后根据多个聚类评价标准对得到的聚类结果进行筛选得到潜在聚类类别,将这些类别的聚类中心提交给专家进行标注;迭代后直到所有潜在类别中心点都被标注或者没有发现新的潜在类别。申请号为cn106991444a的专利公开了一种基于峰值密度聚类的主动学习方法。该方法通过对未标记数据的聚类结果构建选择器,从未标记的样本中选择最有价值样本交给标注专家标注;然后根据已标记样本和已有聚类结构对原始样本进行预测和分类;迭代上述步骤直到所有样本都被分类。
技术实现要素:
为了从一组包含噪声和冗余的数据集中筛选代表性图像用于训练机器学习模型,本发明提供了一种基于多示例主动学习的代表性图像选取方法,所述方法包括以下步骤:
(1)图像原始特征提取
为了充分利用原始数据间潜在的分布特征,需要对原始输入图像进行预聚类;将聚类结果中的每一簇作为一个包,并依次为每个包设定唯一标签代表其类别。聚类前需要先提取原始输入图像特征,具体方法如下:
方向梯度直方图(histogramoforientedgradient,hog)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。与其它特征描述方法相比,因为hog在图像的局部进行特征提取操作,所以hog特征具有较好的旋转不变性;其次特征计算过程中的归一化操作使得hog特征对光照变化不敏感。因此本发明对所有原始输入图像提取hog特征,并将其用于聚类。
首先将n张原始输入图像都调整至指定大小w×w,并进行灰度化,其中w的取值范围为[512,1024];使用gamma矫正方法对灰度图像进行归一化处理,调节图像对比度,作为原始样本图像,从而降低原始输入图像的局部阴影和光照的影响;然后对原始样本图像每个像素分别求其梯度,并将梯度图划分为8×8大小的元图像块(cell),计算每个cell的梯度直方图,得到每个cell的特征描述子;接着将每2×2大小的cell重组成大的、空间上连通的基础图像块(block),串联block中每一个cell的特征描述子即为block的特征描述子;最终图像的特征即为所有block特征描述子串联的结果。记cn和bn分别为图像中cell和block的个数,则cn=(w/8)2、bn=(w/8-1)2,其中w为图像的宽和高;则n张原始输入图像的hog特征组合成大小为n×r的矩阵xs,其中r=36×bn为原始hog特征的维度。
(2)特征降维
原始hog特征的维数较高,对于大小为640×640的图像,可将其分为79×79个block,则最终得到特征维度为224676。特征维数过高的情况下进行聚类所需的内存可能超出计算机的支持范围,且计算量过大,会导致计算过于缓慢。
本发明使用主成分分析(principalcomponentsanalysis,pca)将原始hog特征降至指定维度。对步骤(1)得到的矩阵xs每一行进行标准化;按式(1)计算xs的协方差矩阵;
然后计算协方差矩阵的特征值与特征向量,并选择特征值最大的前m个相应特征向量组成矩阵p,m的取值范围为[128,1024];最后按式(2)计算得到降维后的数据特征集合x:
x=pxs(2)
(3)图像预聚类
本发明使用基于密度的聚类算法dbscan利用降维后的hog特征对原始样本图像进行预聚类,该步骤只需做一次即可,后续无须迭代。对于降维后特征集合x中的特征xi(i∈[1,n]),可被标记为核心对象、噪声点或由核心对象密度直达。初始状态下,所有特征都处于未标记状态。对特征xi,通过距离度量计算其ε邻域子样本集nε(xi),其中ε的取值范围为[0.01,0.1]。如果样本集中样本个数大于阈值t∈[20,100],则标记xj为核心对象,所有核心对象构成核心对象样本集合ω=ω∪xi。在核心对象集合中随机选择一个核心对象ε邻域内的所有核心对象,寻找与这些核心对象密度直达的对象,直到遍历完所有核心对象,得到一个聚类簇cj,将已划分为聚类簇cj中的核心对象从核心对象集合ω中移除。重复上述步骤,直到ω为空,即可得聚类结果c={c1,c2,...,cm},剩余没有被标记的特征点被标记为游离点。
(4)选取初始训练样本
为了训练分类器,需要在原始样本集合中选择部分原始样本图像作为训练样本。遍历集合
本发明流程涉及三个样本集合,分别是原始样本集合dp、难分类样本集合dhs和训练样本集合dtrain。其中训练样本集合dtrain用于保存所有用于训练的原始样本图像,难分类样本集合dhs用于保存分类器难以分类的原始样本图像。初始时所有原始样本图像属于原始样本集合dp,选取训练样本后,训练样本从原始样本集合dp中转移到训练样本集合dtrain。所有样本有且仅有一个所属集合。
(5)训练分类器
利用步骤(4)得到的训练样本集dtrain中的样本训练分类器,得到初始分类器。为了提高分类器的分类精度,本发明使用xception网络作为分类器,实现分类任务。传统的卷积方法中,卷积核对输入特征图所有通道进行卷积操作后特征图相应位置值相加作为输出特征图中一个通道。这种卷积方法只考虑了特征图通道内的空间相关性,而忽略了通道间的相关性,同时如果输入特征图通道数过高的话,网络的参数也会增多,为网络的训练带来不便。xception中使用组卷积代替经典卷积方法,在卷积层间加入1×1卷积操作。对输入n通道的特征图,xception先使用1×1卷积核对输入特征图进行降维。对降维后的特征图使用卷积核对其进行卷积,但卷积后不对特征图对应位置相加,而是使用1×1的卷积核对其再次进行卷积,这样不仅可以利用通道内相关性还可以充分利用通道间的相关性。
为了在本发明中使用xception网络,需要将xception网络最后一个全连接层的输出个数从1000修改为聚类的类别数m。然后分别设置xception网络最后一层和其它层学习率为lr和lr/20,其中lr取值范围为[0.0001,0.05]。使用训练样本集合dtrain中的样本对网络进行训练,得到分类器。
(6)调整难分类样本集合
样本集合中不同样本对于分类器分类精度的贡献不同。例如对于svm分类器,远离分类超平面的样本点对于分类器的贡献小,而越靠近分类平面的样本点对分类器分类精度贡献越大。通过一定的方法可以从所有样本中选择出对分类器分类精度贡献高的样本。样本选择策略有多种,如随机选择策略、基于概率的选择策略、基于版本空间缩减标准的选择策略等。
为了从原始样本集合dp中选择代表性图像,本发明根据主动学习思想,利用bvsb准则从原始样本集合dp中筛选样本。bvsb准则是一种基于概率的选择策略,针对多分类问题下基于熵的选择策略ebq的不足,bvsb对样本的所有预测结果,只取其概率最大的两个结果。将原始样本集合dp中所有样本输入网络,得到其预测值yout。再对预测值使用softmax算法,得到对应每类别的概率
其中bvsb*表示根据bvsb准则从原始样本集合dp中选择的样本,即bvsb准则从原始样本集合dp中选择样本所属类别概率最高和次高差值最小的样本。由于bvsb准则只考虑样本分类概率最高和次高的两个类别,忽略了剩余类别对样本产生的干扰,所以bvsb准则在多分类问题时效果优于考虑了样本所有预测类别的ebq准则。
对难分类样本进行调整时,若难分类样本集合dhs为空,则跳过该步骤,执行步骤(7);否则,使用分类器对dhs进行预测得到每个样本所属类别的概率yhs,根据bvsb采样策略与预测结果yhs,计算yhs中每个样本最大两个的概率差值diffhs。设定阈值vthre∈[0.05,0.3],如果差值大于阈值vthre,则将该样本放回dp中,否则该样本保留在dhs中。
(7)调整原始样本集合
使用分类器对原始样本集合dp中的每个样本进行预测得到每个样本所属类别的概率yp,根据bvsb采样策略,yp中最大的两个概率差值diff越小,表示分类器越难以分类该样本。将yp中每个样本最大的两个概率差值diffp排序,选择其中差值最小的u=np×αp个样本加入难分类样本集dhs,选择差值最大的v=np×βp个样本加入训练集合dtrain,加入dhs和dtrain的样本从dp中移除,其中n为原始样本集合dp中样本总数,αp和βp的取值范围为[0.01,0.1]。
(8)重复执行步骤(5)至步骤(7)进行迭代训练
为了进行代表性图像选取,需要在样本集dp、dtrain、dhs上迭代训练分类器,具体步骤如下:
(8-1)使用步骤(5)所述的方法对训练样本集dtrain进行训练,得到分类器。
(8-2)使用步骤(6)所述的方法对难分类样本集合dhs进行调整。
(8-3)使用步骤(7)所述的方法对原始样本集合dp进行调整。
(8-4)重复上述训练步骤,直到原始样本集合dp中总样本数量小于指定数量p=n×αt,其中n为输入样本总数,αt的取值范围为[0.1,0.3]。
(9)输出代表性图像
最终输出的代表性图像是基于难分类样本集合dhs和训练样本集合dtrain选取:对于难分类样本集合dhs,选择其所有样本对应的原始输入图像作为代表性图像;对于训练样本集合dtrain,按照一定的比例随机从集合中选择q个样本对应的原始输入图像作为代表性图像,其中q=nh×αo,nh为难分类样本集合dhs中样本总数,αo的取值范围为[0.05,0.4]。
附图说明
图1为本发明流程图。
图2为本发明中样本集合调整流程图。
具体实施方式
下面结合实施例和附图来详细描述本发明,但本发明并不仅限于此。主动学习框架是指,首先使用初始样本训练初始分类器,将初始分类器用于预测原始样本集合中所有未标注的样本;然后根据分类器的预测结果及采样策略,从原始样本集合中选择对分类器分类精度贡献大的样本,交给标注专家进行标注;再将标注后的样本与初始样本一起训练分类器。如此迭代,直到分类器的精度不再变化,此时分类器虽然仅使用少数的标注样本,但可以达到较好的分类精度。
coco数据集是微软提供的目标检测、分类数据集,数据集中图像主要从复杂的日常场景中截取,数据集中有超过30万张图像。本实施例基于coco数据集。
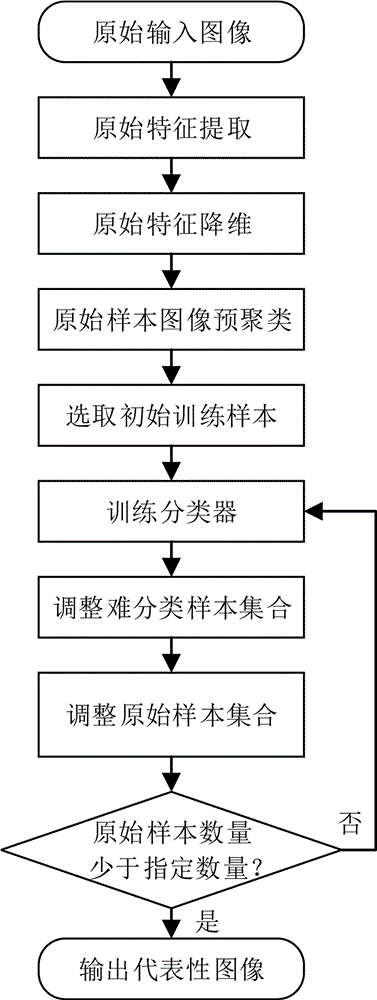
如图1所示,一种基于多示例主动学习的代表性图像选取方法包括以下步骤:
(1)对原始输入图像进行原始特征提取;
(2)对提取的原始特征进行降维;
(3)利用降维后的特征对原始样本图像进行预聚类;
(4)计算聚类结果中聚类簇的密度中心,选取密度中心邻近区域的原始样本图像为初始训练样本,并初始化原始样本集合dp、训练样本集合dtrain和难分类样本集合dhs;
(5)利用训练样本集合dtrain中的样本训练分类器xception网络;
(6)若难分类样本集合dhs为空,则执行步骤(7);否则利用步骤(5)中训练的xception网络对难分类样本进行预测,根据预测结果利用主动学习方法调整难分类样本集合dhs;
(7)利用步骤(5)中训练的xception网络对原始样本集合dp进行预测,根据预测结果利用主动学习方法调整原始样本集合dp;
(8)重复执行步骤(5)至步骤(7)进行迭代训练,直到原始样本集合dp中总样本数量小于指定数量p;
(9)输出代表性图像。
步骤(1)具体包括:
从coco数据集中随机选择n=300000张图像作为原始输入图像,将n张原始输入图像统一调整为w×w大小后进行灰度化处理,对灰度图像使用gamma矫正方法进行灰度归一化,调整图像对比度,作为原始样本图像,其中w=640。然后对原始样本图像中每个像素计算梯度,得到梯度图。将梯度图分为8×8大小的cell,对每个cell计算梯度直方图。再每4个cell单元组合成大的、空间上连通的区间block;cell的特征描述子串联为block的特征描述子。一副图像中可得6400个cell和6421个block,然后将所有block的特征描述子串联成的224676维向量即为原始样本图像的原始hog特征。最后将300000张原始输入样本的原始hog特征组合成大小为300000×224676的矩阵xs。
步骤(2)具体包括:
由于原始特征维数过高,不利于聚类计算,因此本发明使用pca对原始特征进行降维后再进行聚类。协方差矩阵表征了变量之间的相关性,根据xs协方差矩阵可计算xs的主成分,从而达到降维的目的。
将步骤(1)中得到的矩阵xs每一行使用该行减去该行均值,对矩阵行进行标准化处理。然后根据式(1)计算矩阵xs的协方差矩阵c,然后计算协方差矩阵的特征值与相应的特征向量。从协方差矩阵c的特征值中选择1024个最大的特征值,取其对应的特征向量组合成矩阵p,则根据式(2)可计算降维后特征集合x。
步骤(3)具体包括:
使用dbscan算法和步骤(2)降维后的特征对原始样本图像进行预聚类。首先对于降维特征集合x内的点xi(i∈[1,n])计算与其距离度量小于ε=0.05的样本点集合nε(xi)。如果nε(xi)中样本个数大于阈值t=20,则将该点标记为核心对象。遍历特征集合y,找到所有满足核心对象要求的点,将其标记为核心对象,生成核心对象集合ω。从核心对象集合ω中随机选择一个对象xj,寻找与该核心对象密度直达的所有核心对象,这些核心对象与其ε邻域内的所有特征点构成一个聚类簇cj,同时将这些划分为簇的核心对象从核心对象集合中移除。重复上述步骤直到核心对象集合ω为空。此时所有聚类簇构成特征空间的聚类结果c={c1,c2,...,cm}。
步骤(4)具体包括:
根据聚类结果选取初始训练样本用于训练分类器。初始化训练集合dtrain为空、难分类集合dhs为空,并将所有原始样本图像加入原始样本集合dp中。对聚类簇cj,根据以下准则计算其密度中心:对簇中每一个特征点计算其ε邻域内的特征点个数,选择邻域内特征点数量最多的特征点作为簇cj的密度中心。按照每个簇内样本总数nc,从簇密度中心选择s=nc×αc个簇内原始样本图像作为初始训练样本,加入集合dtrain中,并将这些样本从原始样本集合dp中移除,其中n为簇内原始样本图像总数,αc取值0.05。将每个聚类簇视为一个包,为每个包赋予一个类别标签。包中的样本视为示例,包中示例的标签与对应的包相同。
步骤(5)具体包括:
采用xception网络作为分类器,将xception网络最后一个全连接层的输出个数从1000修改为聚类的类别数m,则该层为瓶颈层。加载网络除瓶颈层外其它层的预训练参数,设置瓶颈层学习率为lr=0.0005,其它层学习率lr/20。使用训练样本集合dtrain中的样本对网络进行训练,得到分类器。
步骤(6)具体包括:
若难分类样本集合dhs为空,则跳过该步骤,执行步骤(7);否则,使用步骤(5)得到的分类器对难分类样本集合dhs中的每个样本进行预测,得到每个样本所属类别的概率yhs。基于bvsb准则,计算样本预测结果yhs中样本最大两个概率差值
步骤(7)具体包括:
使用步骤(5)得到的分类器对原始样本集合dp中每个样本进行预测得到每个样本所属类别的概率yp。基于bvsb准则,计算预测结果yp中最大两个概率的差值diffp=p(ybest|xi)-p(ysecond-best|xi)。根据集合中样本总数np,分别取u=np×αp、v=np×βp,这里αp和βp取值分别为0.02和0.03。将diff按值从大到小排序,选择值最大的u个样本从原始样本集合dp中移动到训练样本集合dtrain,选择值最小的v个样本从原始样本集合dp中移动到难分类样本集合dhs。
步骤(8)具体包括:
图2所示为步骤(8)流程图。重复执行步骤(5)至步骤(7),在所有样本集合上进行迭代训练。迭代训练时对原始样本集合dp和难分类样本集合dhs中的样本预测结果yp和yhs选择不同的采样策略,但都是基于bvsb准则,都计算集合中每个样本预测结果所属类别概率最大两个概率的差值
步骤(9)具体包括:
对于难分类样本集合dhs中的样本,选择其所有样本对应的原始输入图像作为代表性图像;对于训练样本集合dtrain中的样本,从集合中随机选取q个样本对于的原始输入图像作为代表性图像,其中q=nh×αo,nh为难分类样本集合dhs中样本总数,αo取值为0.1。
- 还没有人留言评论。精彩留言会获得点赞!