一种结合森林优化和粗糙集的数据离散化方法与流程
本发明属于机器学习数据处理领域,具体涉及一种结合森林优化和粗糙集的数据离散化方法。
背景技术:
机器学习已成为当今人工智能领域研究的热点。多数机器学习算法仅适用于离散型数据,如决策树和贝叶斯网络。实际使用中,所获取数据集的属性多为连续型,需要对数据属性进行一定的离散化处理。利用离散化后的数据集进行算法学习时,结果精度会得到明显改善,算法的分类、预测性能显著提升。
离散化方法分为监督离散化算法和无监督离散化算法。无监督离散化不考虑属性对应的类别信息,直接对属性离散化。例如等频率和等间距算法,效率高但精度差,使用较少。监督离散化算法主要有基于布尔逻辑和粗糙集理论的离散化算法、chi2算法以及基于caim统计量的离散化算法等。该类算法利用属性的类别信息,计算复杂度高,但会获得较优离散化效果。其中基于布尔逻辑和粗糙集理论的离散化算法,复杂度呈指数级,无法实用。caim离散化算法利用caim统计量评价类别信息与属性间的依赖程度,选择caim值最大的断点为最优断点,但其只考虑了具有最多实例数的类别,忽略了其他类别信息。且常用的监督离散化算法多是单属性离散化算法,割裂了属性之间的关联性。而在机器学习算法中,数据的最优断点集是多维属性上的合集,通常其数目少且离散性能优。因此多属性离散化成为离散化新的研究热点,近年来有学者提出了一种基于信息熵的两阶段离散化(tsd)算法等。
技术实现要素:
本发明的目的在于克服传统连续属性离散化算法割裂属性之间关联的缺点,使用森林优化算法对基于粗糙集的离散化方法进行改进,提出一种搜索效率高、避免局部最优的结合森林优化和粗糙集的数据离散化方法forsd,并将该方法应用在机器学习的数据预处理过程,与传统离散化方法相比,本发明可以提高模型的预测及分类精度。
一种结合森林优化和粗糙集的数据离散化方法,该方法包括以下步骤:
步骤1:计算候选断点集;
步骤1.1:对数据集进行数据清洗,包括处理数据不平衡问题、缺失值问题;
步骤1.2:利用粗糙集理论,对清洗过的数据进行属性约简;
步骤1.3:筛选出约简后属性中的连续属性,利用变精度粗糙集理论,对其进行初步的属性值候选断点集划分;
步骤2:适宜度函数评价断点;
步骤2.1:利用变精度粗糙集近似依赖度和断点数目两个指标,设计适宜度评价函数;
步骤2.2:计算当前断点集的β近似依赖度;
步骤2.3:计算森林初始候选断点集的适宜度评价函数;
步骤3:森林优化算法迭代;
步骤3.1:将候选断点集映射成森林中每棵树,进行森林优化算法编码;
步骤3.2:初始化森林,预设算法参数;
步骤3.3:森林就地传播,进行局部森林寻优;
步骤3.4:近似依赖度指导,更新森林每棵树的适宜度,对其进行评价,同时更新树的年龄等其他参数;
步骤3.5:形成或更新备选森林;
步骤3.6:远处播种,进行全局森林寻优;
步骤3.7:更新森林中每棵树的适宜度,并更新其他森林参数;
步骤3.8:森林迭代次数g进行加1操作,若g≤gmax,则执行步骤3.3;若反之,则执行步骤3.9;
步骤3.9:计算森林中各树的适宜度,选取最大适宜度的树,即为最优树,将其反映射为最优断点集eopt,最优断点集,即为本方法对连续属性离散化的最优结果。
步骤1.1所述的处理数据不平衡问题包括:首先分析正负样本比例,其次根据数据集的大小采用不同的采样方法处理,如果数据量较充足,采取欠采样的方法,通过减少样本数据较多的类的数量来平衡数据集;如果数据量较少,采取过采样的方法,通过增加数量较少的类的数量来平衡数据集;
步骤1.1所述的处理数据缺失值问题包括:采用k最近距离邻法,先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的k个样本,将这k个值加权平均来估计该样本的缺失数据,加快后期模型的建立。
步骤1.3所述的变精度粗糙集中,一个信息系统可表示为s=(u,a,v,f),其中,u是有限非空集合,称为论域;a是属性集合;
步骤1.3包括以下步骤:
步骤1.3.1:对所有的连续条件属性,每个属性其值按照属性大小排序,依次计算每个属性断点集
步骤1.3.2:计算全部连续属性的候选断点集pcandidate。
步骤1.3.1所述每个属性断点集
其中,
步骤1.3.2所述全部连续属性的候选断点集pcandidate表示为下式:
其中,k最大取值为连续条件属性的个数。
步骤2.1所述当前断点集的β近似依赖度表示为下式:
其中,f=u/d={d1,d2,…,dk}是由决策属性集d导出的论域u的划分,
步骤2.2所述适宜度评价函数表示为下式:
其中,e设为多维连续属性集c的断点集,其中,f为决策属性d导出的论域u的划分,
步骤3.1包括以下步骤:
步骤3.1.1:一棵树代表一个断点集集合,编码方式采用实数编码,即为一个一维实数数组tree=[age,v1,v2,…,vn],其中除去年龄age,v1到vn对应多维连续属性候选断点集的断点取值,n为候选断点集的断点数目;
步骤3.1.2:断点值处理过程,i∈(1,n),当vi取值不变,表示某个候选断点被选为最优断点集中的一个断点,当vi取值是“0”表示不选择该断点;由于数据集中连续属性值为0的情况极少,故vi取值不为“0”,即对于断点值为0的值,不作处理。
步骤3.2所述初始化森林,预设算法参数为:森林播种代数gmax=500、树的最大年龄lifetime=6、森林中树数量tnum=30、候选断点集个数n、就地播种参数lsc=2和δx、远处播种参数gsc=1和transferrate=10%的值以及变精度粗糙集多数包含关系β=0.15,树的编码维度为n+1。
步骤3.3包括以下步骤:
步骤3.3.1:对数量tnum的树,每一棵0-age树先通过复制产生出一颗与其相同的新树;
步骤3.3.2:在该新树所有维中随机的选择1维,但不包括age维,随机产生微量dx∈[-δx,δx],将dx加到被选中的维变量值上,以变更该维参数值;其中,一棵0-age树产生的新树的数量记为lsc,δx较小。
步骤3.5包括以下步骤:
步骤3.5.1:筛选适宜度较小的树,进入备选森林;
步骤3.5.2:筛选age超过lifetime限制的树,进入备选森林;
步骤6包括以下步骤:
步骤3.6.1:在备选森林中随机选择转移率为“transferrate”的树,在树的维度中,随机选取gsc个维,不包含age维;按每维参数的取值范围,随机产生一个数值,并将该数值赋给该维上的参数;
步骤3.6.2:设置该部分新树age为0,并将该树添加到森林中。
本发明的有益效果在于:本发明所述的一种结合森林优化和粗糙集的数据离散化方法,最大程度保留了数据集不同属性间的关联性,增强机器学习模型的记忆能力,克服传统离散化方法易陷入局部最优、割裂属性之间关联以及优化效率低等问题,是一种多维属性离散化方法,并应用其建立数据预处理模型,可在机器学习算法中使用,如c4.5分类器,可提高其分类、预测精度。
附图说明
图1为forsd基本步骤示意图。
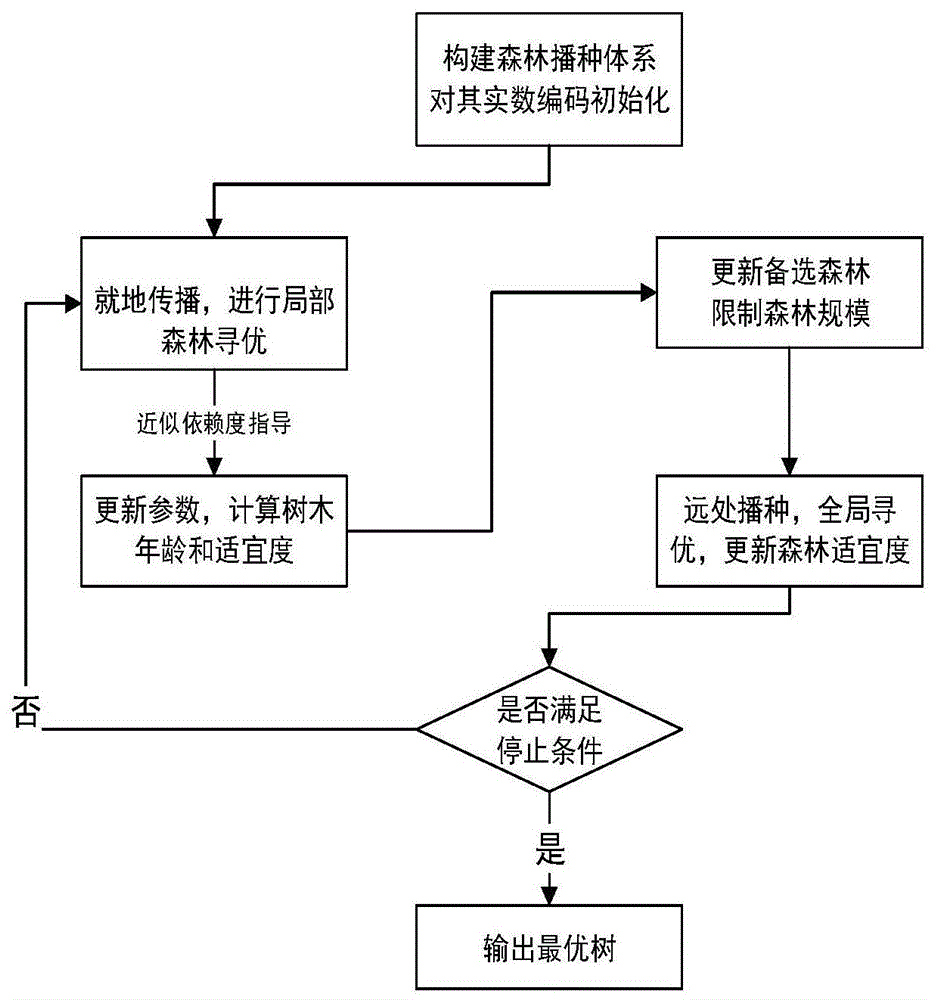
图2为forsd迭代处理流程示意图图。
图3为森林优化算法局部播种示意图。
具体实施方式
下面结合附图对本发明做进一步描述,应指出的是,所描述的实施例仅旨在便于解释本发明,并不构成对本发明的限制。
本发明提出一种结合森林优化和粗糙集的数据离散化方法,如图1所示,该算法包括计算候选断点集、适宜度函数评价断点集以及森林优化算法迭代。具体方法流程如下。
计算候选断点集阶段:
步骤a1:对数据集进行数据清洗,包括处理数据不平衡问题、缺失值等问题。
步骤a11:数据不平衡问题的处理,首先分析正负样本比例,其次根据数据集的大小采用不同的采样方法处理,如果数据量较充足,可采取欠采样的方法,通过减少样本数据较多的类的数量来平衡数据集;如果数据量较少,可采取过采样的方法,通过增加数量较少的类的数量来平衡数据集;
步骤a12:数据缺失值处理,采用k最近距离邻法(k-meansclustering),先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的k个样本,将这k个值加权平均来估计该样本的缺失数据,加快后期模型的建立。
步骤a2:利用粗糙集理论,对清洗过的数据进行属性约简,减轻训练负担。
步骤a3:筛选出约简后属性中的连续属性,利用变精度粗糙集理论,对其进行初步的属性值候选断点集划分。
变精度粗糙集中,一个信息系统可表示为s=(u,a,v,f)。其中:u是有限非空集合,称为论域;a是属性集合;
定义1:对两个任意的集合x和y,集合x关于集合y的相对错误率为:
其中,|x|代表集合x包含元素的个数,即|x|的基数。
定义2:多数包含意味着超过50%的集合x中的元素包含在集合y中,故对论域u中的任意两个非空子集x和y,令0≤β≤0.5,多数包含关系定义为:
其中β为错误分类率。
定义3:对任意集合
其中,[x]b表示由条件属性集c导出的包含对象x的等价类。cβ(x)为下近似,表示将u中的对象以不大于β的分类误差分于x的集合。
定义4:设f=u/d={d1,d2,…,dk}是由决策属性集d导出的论域u的划分,
β近似依赖度
定义5设决策表s=(u,a,v,f)如前所述,对某个连续型条件属性ak∈c,论域中其有限个属性值经过排序后为:
则该属性候选断点可取为
步骤a31:对所有的连续条件属性,每个属性其值按照属性大小排序,依据公式(5),依次计算每个属性断点集
步骤a32:依据公式(6),计算全部连续属性的候选断点集pcandidate。
适宜度函数评价断点阶段:
步骤b1:利用变精度粗糙集近似依赖度和断点数目两个指标,设计适宜度评价函数。近似依赖度越大,属性子集对论域分类精度越高;断点数目尽越少,离散化效果越好。
设e设为多维连续属性集c的断点集,则适宜度评价函数定义为:
其中,f为决策属性d导出的论域u的划分,
步骤b11:依据公式(4),计算当前断点集的β近似依赖度;
步骤b12:依据公式(7),计算森林初始候选断点集的适宜度评价函数。
森林优化算法迭代阶段,本阶段具体流程如图2所示,步骤如下:
森林优化算法(forestoptimizationalgorithm,foa)是由manizhehghaemi在2014年提出的一种仿生类优化算法,相比于遗传算法、粒子群算法,该算法具有搜索效率高、更易获得全局最优解等优点。是模拟树木播种过程的启发式全局随机搜索算法,可用森林优化算法指导、搜索全局最优的离散化断点集。
在森林当中,一棵树代表一组解,本发明将断点集映射成森林中每棵树,利用森林优化算法进行全局寻优。种子传播分为就地播种和远处播种。就地播种即树的种子随机散落在树的附近区域;远处播种种子被散播到距离树较远的地方。森林优化算法模拟并利用种子传播,不断迭代传播并寻优,从而得到最佳树,即断点最优解。与多数优化算法不同,森林优化算法中每棵树都拥有年龄,设有年龄参数。初始的年龄为0,随着播种进行,树的年龄逐步增加。当其年龄达到一定岁数lifetime,从森林中剔除。对于被剔除的树,还有一定几率形成备选森林。由于种子播种,森林中树的数量不断增加,竞争激烈,因此要通过自然选择对森林规模进行限制。此阶段,淘汰年龄过大和适宜值较小的树,并将其组成备选森林。
步骤c1:将候选断点集映射成森林中每棵树,进行森林优化算法编码。
步骤c11:一棵树代表一个断点集集合,编码方式采用实数编码,即为一个一维实数数组tree=[age,v1,v2,…,vn]。其中除去年龄age,v1到vn对应多维连续属性候选断点集的断点取值,n为候选断点集的断点数目;
步骤c12:断点值处理过程,i∈(1,n),当vi取值不变,表示某个候选断点被选为最优断点集中的一个断点,当vi取值是“0”表示不选择该断点。由于数据集中连续属性值为0的情况极少,故vi取值不为“0”,即对于断点值为0的值,不作处理。
步骤c2:初始化森林,预设算法参数。森林播种代数gmax=500、树的最大年龄lifetime=6、森林中树数量tnum=30、候选断点集个数n、就地播种参数lsc=2和δx、远处播种参数gsc=1和transferrate=10%的值以及变精度粗糙集多数包含关系β=0.15,树的编码维度为n+1。
步骤c3:森林就地传播,进行局部森林寻优。
步骤c31:对数量tnum的树,每一棵0-age树先通过复制产生出一颗与其相同的新树;
步骤c32:在该新树所有维中随机的选择1(不包括age维)维,随机产生微量dx∈[-δx,δx],将dx加到被选中的维变量值上,以变更该维参数值;其中,一棵0-age树产生的新树的数量记为lsc(localseedingchanges),δx较小。lsc取2时,一次就地传播的过程,如图3所示。
步骤c4:近似依赖度指导,依据公式(7)更新森林每棵树的适宜度,对其进行评价,同时更新树的年龄等其他参数。
步骤c5:形成或更新备选森林。
步骤c51:筛选适宜度较小的树,进入备选森林;
步骤c52:筛选age超过lifetime限制的树,进入备选森林。
步骤c6:远处播种,进行全局森林寻优。
步骤c61:在备选森林中随机选择转移率为“transferrate”的树,在树的维度中,随机选取gsc(globalseedingchanges)个维,不包含age维;按每维参数的取值范围,随机产生一个数值,并将该数值赋给该维上的参数;
步骤c62:设置该部分新树age为0,并将该树添加到森林中。
步骤c7:依据公式(7)更新森林中每棵树的适宜度,并更新其他森林参数。
步骤c8:森林迭代次数g进行加1操作,若g≤gmax,则执行步骤c3;若反之,则执行步骤c9。
步骤c9:计算森林中各树的适宜度,选取最大适宜度的树,即为最优树。将其反映射为最优断点集eopt。
步骤c9得出的最优断点集,即为本方法对连续属性离散化的最优结果。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!