论坛网民兴趣分析预测系统的制作方法
本发明是一种网络虚拟环境的分析技术,具体涉及一种论坛网民兴趣分析预测系统,属于数据挖掘技术领域。
背景技术:
随着网络信息化的发展,出现了大量的网络虚拟社区,形成了一个网络虚拟环境,网络论坛就是其中的一种主要形式。在传统的社会化经中,长期已经具有一套行之有效的人和群的管理体系,但是网络虚拟环境这是一个新生事物,它不仅仅具有网上自由发言的特点,还具有网民匿名性的特点,加大了监管的难度。目前,网络舆情已经成为一个不可忽视的方面,而网络论坛更能体现出网络聚众的特点,和其它网络应用相比,更能反映网络舆情态势。因此,对于网站论坛中舆情的主要推动力量——网民的分析具有重大意义。通过对论坛中网民兴趣的分析,可以准确掌控某一时间段内网络舆情态势发展的主要趋向。
虽然对基于论坛的网民兴趣分析具有较好的发展前景和应用前途,也出现了一些相关的系统,但是,目前在该领域的系统仍然存在着一系列的问题,主要有几下几种:
1.单纯的网民和发表文章的关联分析,缺乏对网民参与议题、热点话题、内容类别的时间跨度上的系统分析,使得对个体网民的分析缺乏立体感。
2.网民在网络上的活动往往带有团体的性质,目前的系统和方法往往忽略了这一点。网络舆情基本上都是在网络团体的带动下而形成的,个体的网民很难形成一股力量,
因此,需要对网络人群进行深入的分析。
3.目前的系统和方法都是对即时的、局部的数据进行分析,但是,网民的兴趣不是独立的,他们往往和大的网络环境、网络发展过程相关联的,目前的系统和方法缺乏一个网民模型知识库,用于对网民兴趣从总体上进行分析和预测。
由此可见,网络论坛中网民兴趣的分析是非常重要的,对网民兴趣的分析在数据挖据上有着深度的要求,而现有的系统在网民和内容关联、网民之间关联、网民模型知识库都存在着缺陷,还无法满足网民兴趣分析的深层次要求。
技术实现要素:
本发明的目的主要是针对现有基于论坛的网络虚拟环境网民兴趣分析的系统中存在的缺陷,提出一种以网民和内容关关联、网民之间关联、网民模型知识库为技术基础实现的基于数据挖掘的论坛网民兴趣分析预测系统,它主要通过网民和热点话题、议题、内容分类、倾向性分析,网民和网民之间关系分析,长期网民模型知识库的积累等方面,深度挖掘了网民兴趣的起源和发展,并作出预测,实现论坛网民兴趣的深层次分析。
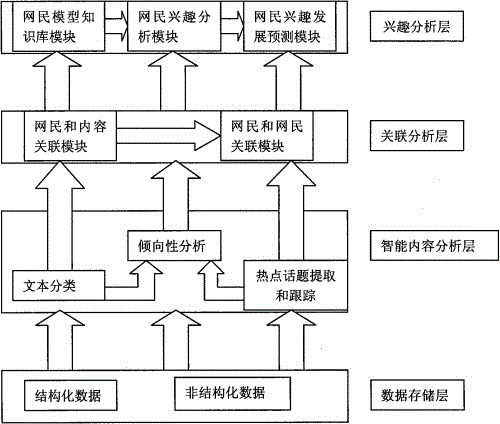
本发明所述的以网民和内容关关联、网民之间关联、网民模型知识库为技术基础实现的基于数据挖掘的论坛网民兴趣分析预测系统由数据存储层、智能内容分析层、关联分析层和兴趣分析层组成。
所述数据存储层在本地系统中负责存放结构化数据和非结构化数据,数据的入库和索引都是在该层完成。对于结构化数据,如网民id、时间等,所述数据存储层将其存放于通用的商业数据库中,这里采用的是oracle;而对于非结构化数据,主要是文本内容,如果存放在通用的商业数据库中,随着数据量的增加,索引性能将会急剧降低,因此,我们将其置于自主开发的专用的非结构化数据存储库内。每篇文章的结构化数据和非结构化数据因为存于不同的数据库内,而且类型不一样,因此需要将数据统一关联起来,我们采用结构化数据在通用商业数据库内的唯一标志id作为关联的依据。
所述智能内容分析层针对非结构化数据,采用数据挖掘的方法,主要包括文本分类、文本聚类、文本摘要等,进行智能化文本内容分析,实现了主题分类、热点话题提取和跟踪、倾向性分析等功能。
所述文本分类是采用人工和自动化相结合的方式,对既设主题进行类别的识别。分类的方法有很多种,我们采用了supportvectormachine(支持向量机)的方法,该方法建立在对词的统计基础之上。其工作流程主要如下:第一步,人工提取一部分文章作为训练集;第二步,对特征集进行中文分词,过滤停用词,提取特征词,并将特征集内的每篇文章转化为特征词向量表示;第三步,调用分类训练器,对特征集向量进行训练,得到分类器;第四步,输入待分类文本内容,根据训练集特征词提取特征,形成特征向量,利用分类器对其进行分类。
所述热点话题提取和跟踪采用文本聚类和分类相结合的方式,具体做法上是对热点话题的提取采用文本聚类的方法,而对热点话题的跟踪采用文本分类的方法,其工作流程如下:第一步,对指定时间段内的文本数据进行中文分词、特征提取,形成向量;第二步,对形成的向量进行自动化聚类,聚类的算法有很多,我们采用的是基于层次的聚类算法;第三步,将聚类出的类别作为新的热点话题;如果需要跟踪该话题,将新热点话题内的文章作为文本分类的训练集,对其进行训练,得到分类器;第四步,利用得到的分类器,对新输入的文章进行分类,将其归入某个热点话题,从而实现了对热点话题的跟踪。
所述倾向性分析采用人工和自动相结合的方式,首先,我们对通用词形成了语义库,在这个语义库内,我们对每个词进行了倾向性的权值分析;其次,输入文本内容,利用语义库对文本内容中的词进行语义加权,从而得到文本内容的倾向性;再次,介入人工的方式,调节倾向性分析结果。
所述关联分析层,根据所述主题分类和所述热点话题,依次进行网民与内容关联、网民与网民关联。所述网民与内容关联不是指网民和他所发表文章的关联,而是利用上述的所述智能内容分析层的输出结果,对网民和当前的主题分类、热点话题、言论倾向性进行关联,从而可以看出该网民在这段时间内的兴趣在哪个主题分类、哪个热点话题,持何种态度主要采用概率统计的方法,统计分析网民在各个方向的关注情况,从而判断出兴趣点。
所述网民与网民关联,综合运用所述结构化数据、所述智能内容分析层的结果数据、所述网民与内容关联的分析结果数据,采用数据关联的方法,分析得出网络社会结构,包括网络社区、网络群体、网络团伙。根据论坛结构化数据,包括网站、版面、网民、时间等,分析出某段时间内,经常活跃于某个网站某个版面某个分类的网民群,我们定义为网络社区;在网络社区内,经常同时参与某类敏感话题的网民群,我们定义为网络群体;在网络群体内,经常参与统一个议题,即统一个根贴和回帖的群,我们定义为网络团伙。
所述兴趣分析层,依据所述网民与内容关联、所述网民与网民关联和所述倾向性分析,进行网民兴趣分析预测。所述兴趣分析层包括:网民模型知识库模块,用于对单个网民和网民群体过去兴趣分析的归纳和总结,形成经验模型,并作为机器学习知识供后续分析;网民兴趣分析模块,用于根据所述网民模型知识库模块,分析单个网民的兴趣和网民群体的兴趣点;网民兴趣发展预测模块,用于根据所述网民模型知识库模块,预测判断单个网民和网民群体的未来兴趣发展。
所述网民模型知识库模块是对网民和群过去兴趣分析的归纳和总结,形成经验模型,并作为机器学习知识,以供后续的分析。网民模型知识库记录了网民和群的兴趣概率统计分布,并在一段时间上的发展变化。
所述网民兴趣分析模块,不仅仅分析了单个网民的兴趣,也分析了网络群的兴趣点。主要采用的方法是根据网民和内容关联模块分析结果,网民和网民关联模块分析结果,结合网民模型知识库,综合考虑网民和群以往的兴趣经验,判断出网民当前兴趣分布。
所述网民兴趣发展预测模块根据网民和群当前的讨论热点所在,运用网民模型知识库得出以往发展模式,经过对比后,对网民和群的今后兴趣发展做出适当的预测判断。我们采用了马尔科夫模型,在每个时间点上采用了兴趣点的概率分布,根据当前兴趣点的概率分布,从而在某种程度上对未来兴趣点的发展做出了预测分析。
本发明具有实质性特点和显著进步:(1)通过对网民和内容关联的深度挖掘,对网民进行兴趣分析;(2)通过对网络人群的分析,挖掘,得到网民在网络上所扮演的角色和起到的作用,从而发掘出网民的动机;(3)采用网民模型知识库的方式,积累大量的网民相关信息的模型,再应用到当前的数据分析中,有利于从总体上分析网民的兴趣所在,并作出适当预测。
本发明提出的以网民和内容关关联、网民之间关联、网民模型知识库为技术基础实现的基于数据挖掘的论坛网民兴趣分析预测系统,充分利用网络内容信息、网民信息、历史数据信息,有效的解决了对基于论坛的网民兴趣分析的深度挖掘需求,适用于网络舆情分析系统的实施。
附图说明
附图1为论坛网民兴趣分析预测系统实施方式的系统架构图。
具体实施方式
下面结合附图对本发明的实施方式进行详细说明。
附图所示为论坛网民兴趣分析预测系统实施方式的系统架构图。如图所示,整个系统架构分为四个层次:第一层是数据存储层,负责管理结构化数据和非结构化数据的入库、索引;第二层是智能内容分析层,采用数据挖掘的方法对文章内容进行文本分类、热点话题提取和跟踪、倾向性分析;第三层是关联分析层,包括网民和内容关联模块、网民和网民关联模块,其中网民和内容关联模块的分析结果是网民和网民关联模块的分析基础;第四层,也是最上一层是兴趣分析层,包括网民模型知识库模块、网民兴趣分析模块、网民兴趣发展预测模块,其调用次序是,网民兴趣分析模块调用网民模型知识库模块,这两个模块又是网民兴趣发展预测模块的基础。
在所述智能内容分析层,首先将文本数据输入该模块,内容分析模块调用中文分词功能,对中文文本进行分词,然后再进入特征选择,主要有两项工作,首先去掉停用词,再计算tfidf值,进行特征选择。文本分类和文本聚类的特征选择是不一样的,文本分类直接对训练文档进行特征选择,而文本聚类将所有的测试文档看作不同的类别,进行特征选择,因此,得到两个特征选择结果。特征选择结束以后,分为两部分,一部分是进行文本分类,另一部分是进行文本聚类。在文本分类这一部分,首先调用分类训练功能,经过训练后得到分类的分类器;其次进行文本分类;最后对分类结果进行倾向性分析,得到每个类别的言论倾向性情况。在文本聚类这一部分,首先调用文本聚类功能,自动举出类别;再次将自动聚出的类别提取出来,形成新的热点话题和跟踪;最后,对热点话题进行倾向性分析,得出每个热点话题的言论倾向性。
在所述关联分析层,既有网民和内容关联模块,又有网民和网民关联模块。首先是网民和内容关联模块,分为三个部分,第一个是文本分类结果和网站版面网民关联分析,第二个是热点话题分析结果和网站版面网民刮脸分析,第三个是同题目议题与网站版面网民关联分析;其次是网民和网民关联模块,也分为三个部分,分别对应着上述三个部分,第一个将相同网站相同版面相同分类的网络群划分为网络社区;第二个将相同网站相同版面相同话题的网络群划分为网络群体;第三个将相同网站相同版面同题目议题的网络群划分为网络团伙。
在所述兴趣分析层,将上述得到的网络社区、网络群体、网络团伙、个体网民和倾向性分析结果结合起来,经过统计分析,我们可以得到网民和网络群的兴趣分析点;在此基础上,再结合网民模型知识库,分别对网民和网路群的兴趣发展做出预测,包括网络社区兴趣分析和发展预测、网络群体兴趣分析和发展预测、网络团伙兴趣分析和发展预测、网民兴趣分析和发展预测。
从上述实施过程可以看出,本发明所做的以网民和内容关关联、网民之间关联、网民模型知识库为技术基础实现的基于数据挖掘的论坛网民兴趣分析预测系统,有效的实现了论坛网民兴趣分析的深度挖掘,为网络舆情分析中的网络人和群的分析提供了可靠信息。
- 还没有人留言评论。精彩留言会获得点赞!