基于蝙蝠优化的用户偏好聚类协同过滤推荐算法的制作方法
本发明属于信息过滤技术领域,具体为一种基于蝙蝠优化的用户偏好聚类协同过滤推荐算法。
背景技术:
随着互联网的普及和电子商务的发展,网络资源不断丰富,网络信息量不断膨胀,用户要在众多的选择中挑选出自己真正需要的信息好比大海捞针。推荐系统应运而生,推荐系统为不同用户提供不同的服务,以满足不同的需求。推荐系统成为电子商务的核心。目前,几乎所有的大型电子商务系统,如淘宝、京东、当当、亚马逊等系统均采用了个性化推荐系统来提高服务质量。
在传统研究中,常见的推荐算法是协同过滤算法。其推荐算法计算的核心数据是用户—项目评分矩阵。随着电子商务规模的扩大,产品信息的增多,现有的协同过滤推荐算法需要对海量数据进行处理,导致推荐算法的可扩展性以及结果准确性受到了巨大的挑战,研究一种包容性更强的推荐算法势在必行。
技术实现要素:
本发明的目的在于解决现有协同过滤推荐算法的可扩展性以及结果准确性受到了巨大的挑战的问题,提供了一种基于蝙蝠优化的用户偏好聚类协同过滤推荐算法。
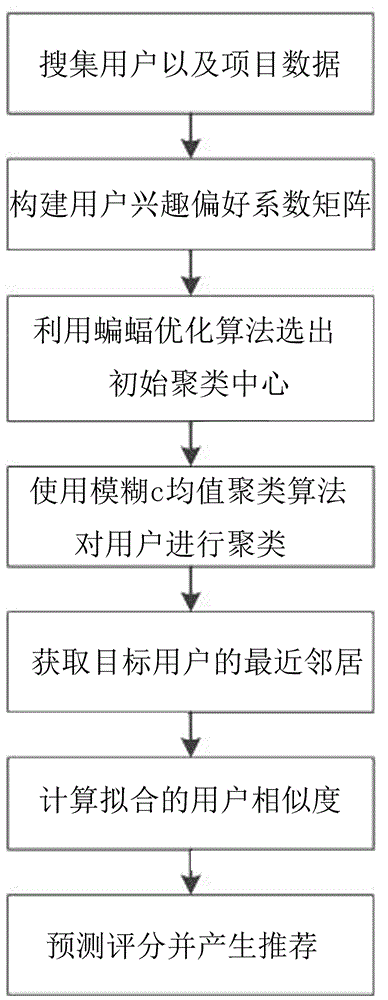
本发明解决其技术问题的技术方案是:基于蝙蝠优化的用户偏好聚类协同过滤推荐算法,包括以下步骤:
①搜集用户以及项目数据,形成用户-项目评分矩阵r以及项目-类型矩阵m:所述用户-项目评分矩阵r的每个矩阵元素表示不同用户对不同项目的具体打分情况,未评分的数据记为0;在项目-类型矩阵m中,当项目包含某一类型属性时,相应的矩阵元素记为1,反之为0;
②构建用户兴趣偏好系数矩阵:利用公式(1)对步骤①得到的用户-项目评分矩阵r以及项目-类型矩阵m进行重构,得到用户对项目类型的“用户兴趣偏好系数矩阵p”,具体计算公式(1)如下:
其中,
③利用基于蝙蝠优化算法和模糊c均值的混合聚类算法对步骤②得到的用户兴趣偏好系数矩阵p进行聚类:先用蝙蝠优化算法查找初始聚类中心,再对步骤②中的用户兴趣偏好系数矩阵p的全部用户进行模糊c均值聚类;
④生成用户的最近邻居:根据步骤③得到的用户聚类结果,找出目标用户所述的类簇,并且通过相似度计算公式(2)计算目标用户与该类簇中的其他用户之间的用户项目类型偏好相似度,并且按照从高到低排序,将前k个用户作目标用户的最近邻居,相似度计算公式(2)具体如下:
其中,e表示项目的所有类型,au表示目标用户,u表示目标用户au的候选邻居,rau,e表示的是目标用户au对具有类型e的项目评分,ru,e表示的是用户u对具有类型e的项目评分,
⑤计算拟合的用户相似度;采用线性拟合方法将步骤④得到的用户项目类型偏好相似度和传统的用户项目评分相似度进行合并,其中传统的用户项目评分相似度计算公式(3)如下:
其中,rau,i表示目标用户au对项目i的评分,ru,i表示用户u对项目i的评分,
sim(au,u)=simu(au,u)·λ+sime(au,u)·(1-λ)(4),
其中,simu(au,u)表示传统的用户项目评分相似度,sime(au,u)表示用户项目类型偏好相似度,λ表示拟合参数,取值在[0,1]之间;
⑥对目标用户进行评分预测:预测目标用户au的未评级项目集合中的每个项目i的评级分数,将目标用户对未评分项目的评分结果值按照递减的方式来排序,选取预测评分高的前n个物品作为推荐结果,评分计算公式(5)如下:
其中,pau,i代表目标用户au对项目i的预测值,ui代表所有评价过项目i的用户集合,nau代表目标用户au的所有邻居集合,
优选的,步骤③具体包括如下步骤:
a)初始化种群大小m、速度vi、频率fi、脉冲发射率ri、响度ai和最大迭代次数t;
b)随机创建初始蝙蝠种群;
c)使用范围0-1之间的随机值初始化隶属度uij并生成隶属度矩阵u;
d)使用模糊c均值聚类算法中的聚类中心公式(6)计算蝙蝠个体的簇中心,其中聚类中心公式(6)如下:
e)使用模糊c均值聚类算法中的目标价值函数(7)和隶属度公式(8)估算每只蝙蝠的适应度值,并选出当前全局最优个体所在位置即当前全局最优位置xbest以及最优适应度值f(xbest),其中目标价值函数(7)和隶属度公式(8)具体为:
f)根据蝙蝠优化算法中的频率更新公式(9)、速度更新公式(10)和蝙蝠个体的位置更新公式(11)对蝙蝠个体的速度和位置进行修改,其中频率更新公式(9)、速度更新公式(10)和蝙蝠个体的位置更新公式(11)如下:
fi=fmin+(fmax-fmin)∪(0,1)(9),
其中,fi、fmin、fmax分别表示第i只蝙蝠在当前时刻发出声波的频率、声波频率的最小值、声波频率的最大值,xbest表示当前全局最优个体所在位置即当前全局最优位置;
g)如果随机数rand1>脉冲发射率ri,则在当前全局最优位置处进行随机扰动,生成一个新的位置并计算更新位置后蝙蝠个体的适应度值f(xnew);
h)如果随机数rand2<响度ai且适应度值f(xnew)<f(xbest),则接受上一步产生的新位置,并根据蝙蝠优化算法中的脉冲发射率ri更新公式(12)和响度ai更新公式(13)对蝙蝠个体的脉冲发射率和响度进行修改,脉冲发射率ri更新公式(12)和响度ai更新公式(13)如下:
rit+1=ri0[1-exp(-γt)](12),
其中,α、γ为常数;
i)如果迭代次数小于t,则转向步骤3.4继续迭代;否则,输出全局最优个体所在位置即全局最优位置xbest作为初始聚类中心,并运用模糊c均值聚类算法将用户聚类到不同的类簇中,得到的用户聚类结果。
步骤③中在用户兴趣偏好系数矩阵p上利用基于蝙蝠优化的模糊c均值聚类算法对用户进行聚类,能减少可扩展性问题,增强聚类,提高推荐质量
与现有技术相比,本发明的有益效果是:本发明所述算法首先利用用户评分信息和项目类型信息构建了用户兴趣偏好系数矩阵,以缓解数据稀疏性并真实地反映用户兴趣偏好;然后在用户兴趣偏好系数矩阵上利用基于蝙蝠优化的模糊c均值聚类算法对用户进行聚类,以减少可扩展性问题,增强聚类,提高推荐质量;最后,对目标用户采用线性拟合的相似度模型进行评分预测并做出推荐;此算法大幅度降低了数据处理量,显著提高可扩展性和推荐结果的准确性。
附图说明
图1是本发明所述基于蝙蝠优化的用户偏好聚类协同过滤推荐算法的流程图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其他实施方式,都属于本发明所保护的范围。
参见附图1,现对本发明提供的基于蝙蝠优化的用户偏好聚类协同过滤推荐算法进行说明。
一种基于蝙蝠优化的用户偏好聚类协同过滤推荐算法,包括以下步骤:
①搜集用户以及项目数据,形成用户-项目评分矩阵r以及项目-类型矩阵m:所述用户-项目评分矩阵r的每个矩阵元素表示不同用户对不同项目的具体打分情况,未评分的数据记为0;在项目-类型矩阵m中,当项目包含某一类型属性时,相应的矩阵元素记为1,反之为0;本发明主要是提取用户的显性行为数据,包括能够明确看出用户对项目的喜爱度的行为,例如数值打分行为,用户对项目的喜爱水平随分数的增加而增高,即分数越大用户对项目越喜;具体例如,
②构建用户兴趣偏好系数矩阵:利用公式(1)对步骤①得到的用户-项目评分矩阵r以及项目-类型矩阵m进行重构,得到用户对项目类型的“用户兴趣偏好系数矩阵p”,具体计算公式(1)如下:
其中,
p1,1=(3+1)/(3+1+5+1+3+1+3+5)·ln3/(1+1)=0.0737;以此可得,
③利用基于蝙蝠优化算法和模糊c均值的混合聚类算法对步骤②得到的用户兴趣偏好系数矩阵p进行聚类:先用蝙蝠优化算法查找初始聚类中心,再对步骤②中的用户兴趣偏好系数矩阵p的全部用户进行模糊c均值聚类,本发明采用的聚类样本为步骤②得到的用户兴趣偏好系数矩阵p,这里利用基于蝙蝠优化的模糊c均值聚类算法对用户进行聚类,减少了可扩展性问题,增强聚类,提高推荐质量,具体步骤如下:
a)初始化种群大小m、速度vi、频率fi、脉冲发射率ri、响度ai和最大迭代次数t;
b)随机创建初始蝙蝠种群;
c)使用范围0-1之间的随机值初始化隶属度uij并生成隶属度矩阵u;
d)使用模糊c均值聚类算法中的聚类中心公式(6)计算蝙蝠个体的簇中心,其中聚类中心公式(6)如下:
e)使用模糊c均值聚类算法中的目标价值函数(7)和隶属度公式(8)估算每只蝙蝠的适应度值,并选出当前全局最优个体所在位置即当前全局最优位置xbest以及最优适应度值f(xbest),其中目标价值函数(7)和隶属度公式(8)具体为:
f)根据蝙蝠优化算法中的频率更新公式(9)、速度更新公式(10)和蝙蝠个体的位置更新公式(11)对蝙蝠个体的速度和位置进行修改,其中频率更新公式(9)、速度更新公式(10)和蝙蝠个体的位置更新公式(11)如下:
fi=fmin+(fmax-fmin)∪(0,1)(9),
其中,fi、fmin、fmax分别表示第i只蝙蝠在当前时刻发出声波的频率、声波频率的最小值、声波频率的最大值,xbest表示当前全局最优个体所在位置即当前全局最优位置;
g)如果随机数rand1>脉冲发射率ri,则在当前全局最优位置处进行随机扰动,生成一个新的位置并计算更新位置后蝙蝠个体的适应度值f(xnew);
h)如果随机数rand2<响度ai且适应度值f(xnew)<f(xbest),则接受上一步产生的新位置,并根据蝙蝠优化算法中的脉冲发射率ri更新公式(12)和响度ai更新公式(13)对蝙蝠个体的脉冲发射率和响度进行修改,脉冲发射率ri更新公式(12)和响度ai更新公式(13)如下:
rit+1=ri0[1-exp(-γt)](12),
其中,α、γ为常数;
i)如果迭代次数小于t,则转向步骤3.4继续迭代;否则,输出全局最优个体所在位置即全局最优位置xbest作为初始聚类中心,并运用模糊c均值聚类算法将用户聚类到不同的类簇中,得到的用户聚类结果;
④生成用户的最近邻居:根据步骤③得到的用户聚类结果,找出目标用户所述的类簇,并且通过相似度计算公式(2)计算目标用户与该类簇中的其他用户之间的用户项目类型偏好相似度,并且按照从高到低排序,将前k个用户作目标用户的最近邻居,相似度计算公式(2)具体如下:
其中,e表示项目的所有类型,au表示目标用户,u表示目标用户au的候选邻居,rau,e表示的是目标用户au对具有类型e的项目评分,ru,e表示的是用户u对具有类型e的项目评分,
⑤计算拟合的用户相似度;采用线性拟合方法将步骤④得到的用户项目类型偏好相似度和传统的用户项目评分相似度进行合并,其中传统的用户项目评分相似度计算公式(3)如下:
其中,rau,i表示目标用户au对项目i的评分,ru,i表示用户u对项目i的评分,
sim(au,u)=simu(au,u)·λ+sime(au,u)·(1-λ)(4),
其中,simu(au,u)表示传统的用户项目评分相似度,sime(au,u)表示用户项目类型偏好相似度,λ表示拟合参数,取值在[0,1]之间;
⑥对目标用户进行评分预测:预测目标用户au的未评级项目集合中的每个项目i的评级分数,将目标用户对未评分项目的评分结果值按照递减的方式来排序,选取预测评分高的前n个物品作为推荐结果,其中评分计算公式(5)如下:
其中,pau,i代表目标用户au对项目i的预测值,ui代表所有评价过项目i的用户集合,nau代表目标用户au的所有邻居集合,
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!