一种基于DFS与改进中心聚类法的破碎文档拼接方法与流程
本发明属于破碎文档拼接技术领域,尤其涉及一种基于dfs与改进中心聚类法的破碎文档拼接方法。
背景技术:
现阶段规则切割文档碎片拼接问题的处理大多分两步,第一步,使用聚类方法对所有碎片进行聚类,以便找出原本属于一行的碎片,方便后续处理。第二步,对属于一行碎纸片,基于相似度算法或者遗传算法单独进行拼接,部分特殊拼接情况进行人工干预。但是,由于碎纸片切割情况复杂,导致聚类方法和拼接算法经常无法应对特殊情况。现阶段拼接算法主要包含以下缺点:聚类算法易失效。对于文档中分段造成的段前空白等特殊情况,现阶段聚类算法往往会无法应对而失效。基于相似度的拼接算法原则太过单一,缺乏鲁棒性,并不能涵盖拼接过程中所有的可能性。对于碎纸片拼接这类np难问题,随着碎片拼接规模的上升,该方法并不能取得很好的效果。另一方面,用于解决np难问题常用的优化算法—遗传算法,实际效果并不好,这主要是因为遗传算法中种群规模、种群变异率与交叉率等参数需要进行人为设定,若设置不合理将使得计算结果收敛到局部最优而达不到期望的效果。
综上所述,现有技术存在的问题是:现阶段存在的拼接算法要么使用聚类方法要么使用遗传算法。而聚类方法所选取的聚类特征太过单一,遗传算法又需要人为制定参数,以上原因导致算法对实际碎片拼接效果较差。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于dfs与改进中心聚类法的破碎文档拼接方法。
本发明是这样实现的,一种基于dfs与改进中心聚类法的破碎文档拼接方法,所述基于dfs与改进中心聚类法的破碎文档拼接方法包括以下步骤:
步骤一:预处理。包括将所有碎片图像灰度化、归一化并反色,使得有字部分像素值为1,无字部分像素值为0。
步骤二:提取特征并获得中心向量。提取每张纸片两侧的像素向量作为特征向量,并根据特征向量是否连续出现0获得每行字中心位置以得到中心向量。对两张待拼接的碎纸片来说,可以计算出各自的中心向量。分别记作hi和hj。设定中线偏移误差阈值t1,将第一个向量的各个分量与第二个向量的某分量分别相减。只有|hi,k-hj,l|<t1时才认为第一个向量中第k个分量匹配成功。综合匹配成功的数目,认为只有匹配成功分量数目达到一半以上才能够算作匹配不触发人工干预。记满足条件的差值有f1,不满足的有f2个。则f1>1。综合以上可得满足条件
的纸片才属于同一行,其中w表示中心向量的维度,
步骤三:将每张纸片特征向量的内积作为两张纸片间的相似度。
si,j=vecitvecj
其中veci与vecj分别代表不同的碎片对应的特征。获得相似度矩阵后,对每一张纸片,按照相似度大者优先拼接的贪心原则先进行一次拼接。
步骤四:每按照相似度最大的“贪心准则”拼接一次,就使用差异度准则
di,j=||veci-vecj||1
构造的“检查函数”对拼接结果进行检查。如果通过检查,则拼接下一张纸片,否则进行人工干预或者按照相似度大者先拼接的原则使用下一个较低相似度的纸片拼接。“检查函数”主要从以下几方面对拼接结果进行评估。
1.设定留黑阈值tb=20,当两张纸片中任意一张纸片拼接处的两个像素向量包含有字部分的像素数目少于tb时,就说明拼接信息太少,容易拼接错误,“检查函数”将转为人工拼接碎片。
2.如果在人工干预模式下所有的拼接方案均不是正确方案,那么说明前面的拼接可能出现问题,“检查函数”将按照深度优先搜索的顺序回溯遍历相似度搜索树,从而保证前面的拼接方式是正确的。
3、“检查函数”将检查两张碎片拼接后在拼接处的字宽,这可以通过计算两边像素值为1的像素点数目实现。若它远大于或远小于正常字宽,则认为拼接错误,算法将寻找下一个候选纸片。
步骤五:重复步骤1~4直到碎片拼接完成。
进一步,改进中心聚类法包括:两张待拼接的碎纸片,计算出各自的中心向量,分别记作hi,hj;中线偏移误差阈值t1,将第一个向量的各个分量与第二个向量的某分量分别相减;只有|hi,k-hj,l|<t1时才认为第一个向量中第k个分量匹配成功;记满足条件的差值有f1,不满足的有f2个;则f1>1;
满足条件:
的纸片才属于同一行,其中w表示中心向量的维度,
相似度函数:
si,j=vecitvecj;
加入差异度d,即求两边缘像素向量差向量的1范数,与相似度一起组成评价指标:
di,j=||veci-vecj||1。
本发明的优点及积极效果为:改进中心聚类法在保留原始中心聚类的优势基础上,新增判定准则,进一步降低人为因素,并取得了很好的聚类效果;使用相似度进行拼接,再基于差异度进行纠错;避开遗传算法,增加了算法的正确率。本发明基于改进中心聚类法以及dfs复原拼接算法,通过推导阈值范围公式使得中心聚类法效果更好,并在dfs拼接复原算法中综合相似度、差异度、留黑阈值等参数来充分挖掘两张碎片的匹配程度,进一步降低了人工干预次数。实验证明,本发明获得了很好的效果。
附图说明
图1是本发明实施例提供的基于dfs与改进中心聚类法的破碎文档拼接方法流程图。
图2是本发明实施例提供的中心聚类法提取特征向量示意图。
图3是本发明实施例提供的特殊情况处理示意图。
图4是本发明实施例提供的三种特殊情况示意图。
图5是本发明实施例提供的集成相似度与差异度的dfs拼接算法示意图。
图6是本发明实施例提供的改进中心聚类法与中心聚类法对比示意图。
图7是本发明实施例提供的遗传算法重复计算50次取最优结果(上)与dfs搜索算法拼接结果(下)对比示意图。
图8是本发明实施例提供的每次迭代最高适应度与最优解对比示意图。
图9是本发明实施例提供的复原结果示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
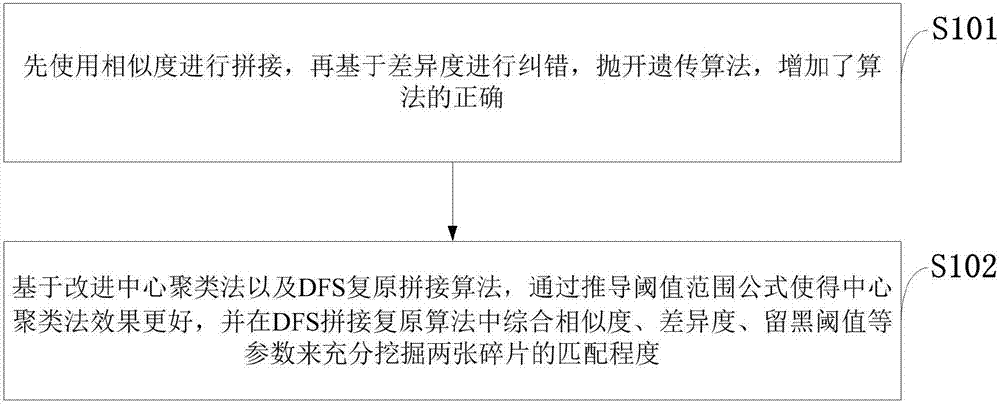
如图1所示,本发明实施例提供的基于dfs与改进中心聚类法的破碎文档拼接方法包括以下步骤:
s101:首先使用相似度进行拼接,再基于差异度进行纠错,抛开遗传算法,增加了算法的正确;
s102:基于改进中心聚类法以及dfs复原拼接算法,通过推导阈值范围公式使得中心聚类法效果更好,并在dfs拼接复原算法中综合相似度、差异度、留黑阈值等参数来充分挖掘两张碎片的匹配程度。
本发明实施例提供的基于dfs与改进中心聚类法的破碎文档拼接方法具体包括以下步骤:
步骤一:预处理。包括将所有碎片图像灰度化、归一化并反色,使得有字部分像素值为1,无字部分像素值为0。
步骤二:提取特征并获得中心向量。提取每张纸片两侧的像素向量作为特征向量,并根据特征向量是否连续出现0获得每行字中心位置以得到中心向量。对两张待拼接的碎纸片来说,可以计算出各自的中心向量。分别记作hi和hj。设定中线偏移误差阈值t1,将第一个向量的各个分量与第二个向量的某分量分别相减。只有|hi,k-hj,l|<t1时才认为第一个向量中第k个分量匹配成功。综合匹配成功的数目,认为只有匹配成功分量数目达到一半以上才能够算作匹配不触发人工干预。记满足条件的差值有f1,不满足的有f2个。则f1>1。综合以上可得满足条件
的纸片才属于同一行,其中w表示中心向量的维度,
步骤三:将每张纸片特征向量的内积作为两张纸片间的相似度。
si,j=vecitvecj;
其中veci与vecj分别代表不同的碎片对应的特征。获得相似度矩阵后,对每一张纸片,按照相似度大者优先拼接的贪心原则先进行一次拼接。
步骤四:每按照相似度最大的“贪心准则”拼接一次,就使用差异度准则:
di,j=||veci-vecj||1;
构造的“检查函数”对拼接结果进行检查。如果通过检查,则拼接下一张纸片,否则进行人工干预或者按照相似度大者先拼接的原则使用下一个较低相似度的纸片拼接。“检查函数”主要从以下几方面对拼接结果进行评估。
1、设定留黑阈值tb=20,当两张纸片中任意一张纸片拼接处的两个像素向量包含有字部分的像素数目少于tb时,就说明拼接信息太少,容易拼接错误,“检查函数”将转为人工拼接碎片。
2、如果在人工干预模式下所有的拼接方案均不是正确方案,那么说明前面的拼接可能出现问题,“检查函数”将按照深度优先搜索的顺序回溯遍历相似度搜索树,从而保证前面的拼接方式是正确的。
3、“检查函数”将检查两张碎片拼接后在拼接处的字宽,这可以通过计算两边像素值为1的像素点数目实现。若它远大于或远小于正常字宽,则认为拼接错误,算法将寻找下一个候选纸片。
步骤五:重复步骤1~4直到碎片拼接完成。
下面结合附图对本发明的应用原理作进一步的描述。
1、改进的中心聚类法应用于碎片聚类
1.1中心聚类法
图2展示聚类过程中提取聚类特征的过程;首先对于经过二值化预处理的碎片图像,从上至下搜寻每一行像素。若出现0(黑色)则将该行的像素值全部置为0(全部涂黑)。然后,获得每一个“黑色宽带”的中心位置,最后,计算各行中心相对于顶部的距离,就可得到用于进行中心聚类的特征向量。获得特征向量后,使用k-means聚类等聚类方法就可以实现对碎片归类,降低拼接算法复杂度,如图2所示。
如图2所示,(11)和(21)代表在涂黑操作过程中,由于存在“云”这类特殊的字,使得涂黑操作可能出现问题;本发明设置了一个阈值,如果涂黑部分之间的间隙小于该阈值则将该间隙涂黑(全部设为0),该阈值不能取得太小,将这一阈值设置为了行间距的四分之三。
(13)与(23)这一组样本却很特殊。由于段落换行使得(13)成为了唯一只有一行字的碎片。这种特例将严重影响碎片拼接复原。(14)与(24)这组特例则由于一行文字未显示完全,导致中心线与同属一行的碎片的中心线相差较大。这种情形同样会影响后面的拼接复原。
1.2、改进的中心聚类法
在以上特殊情况的情形下,衡量两张碎片是否在同一行就不能使用传统的诸如k-means聚类方法来聚类。
对两张待拼接的碎纸片来说,可以计算出各自的中心向量。分别记作hi,hj。设定中线偏移误差阈值t1,将第一个向量的各个分量与第二个向量的某分量分别相减。只有|hi,k-hj,l|<t1时才认为第一个向量中第k个分量匹配成功。综合匹配成功的数目,认为只有匹配成功分量数目达到一半以上才能够算作匹配不触发人工干预。记满足条件的差值有f1,不满足的有f2个;则f1>1。
综合以上可得满足条件:
的纸片才属于同一行,其中w表示中心向量的维度,
本发明在碎片集合中找到位于同一行的碎片的方法包括以下步骤:
step1:选取两张纸片i,j,采用之前的办法求得各自的中心向量hi,hj,并将两个中心向量作差;
step2:设定阈值t1=1(中线偏移的误差),统计出分量差值小于等于t1的个数f1,以及大于t1的个数f2;
step3:进行判断,如果f1≥1(即两张纸片至少有一行文字的中线大致在一条直线上),并且
step4:重复以上过程,直到所有的纸片都已经完成归类。
使用该方法对碎片进行聚类,就可以很好地排除掉由于标点、换行等特殊情况所带来的麻烦。
2、dfs拼接算法
要对碎片进行拼接复原,使用单一指标将很难刻画纸片间的相似性。所以,这里引入了相似度、差异度以及字宽、留黑阈值等参数来充分描述两张纸片的匹配程度。
2.1相似度、差异度与检查函数的设定
相似度的主要思想在于图像经过归一化、二值化并反色处理后,原本相邻两碎片的边缘像素向量veci与vecj具有大量相同的像素点,为此,可以使用两向量内积定义相似度函数。
si,j=vecitvecj;
除上述相似度定义外,使用其它相似度定义来综合各个相似度的优势。如余弦相似度:
si,j=vecitvecj/||veci||2||vecj||2;
相关系数相似度:
让相似度拼接方法更加有效。图3反映了使用贪心搜索策略进行拼接过程中出现的特殊情况。第一张图由于标点符号太小使得标点符号造成的相似度下降并没有阻止两张碎片拼接在一起。
为此加入差异度d(即求两边缘像素向量差向量的1范数),与相似度一起组成评价指标:
di,j=||veci-vecj||1;
并根据相似度最大差异度最小的原则来辅助进行判断,这种方法可以除去第一种情况的干扰。但是,对于第二张与第三张图所示的情况,仍然会有差异度不满足要求、相似度差异度评价方法失效等情况,如图4所示。
从以下方面确定一种拼接方案(i,j)是否是合格的候选纸片:
第一,设定留黑阈值tb=20,当两张纸片中任意一张纸片拼接处的两个像素向量包含有字部分的像素数目少于tb时,就说明拼接信息太少,容易拼接错误,“检查函数”将转为人工拼接碎片(这主要用于解决图4中的第一种情况)。
第二,如果在人工干预模式下所有的拼接方案均不是正确方案,那么说明前面的拼接可能出现问题,“检查函数”将按照深度优先搜索的顺序回溯遍历的搜索树,从而保证前面的拼接方式是正确的。
第三,“检查函数”将检查两张碎片拼接后在拼接处的字宽,若它远大于或远小于正常字宽,则认为拼接错误,算法将寻找下一个“候选人”。
至此,综合相似度、差异度以及“检查函数”的dfs拼接算法已经成型。
3、集成相似度与差异度的dfs拼接纠错算法
如图5所示。当选定了一张纸片向后拼接时,程序将会从与当前纸片相似度最大的纸片开始选取,通过筛选机制,程序会对当前拼接的匹配情况进行判定,如果拼接结果不满足对于字宽或者差异度的要求,那么该纸片会被标注为0(匹配不成功状态),然后程序将选取相似度次大的纸片再来进行拼接判定;如果满足要求,则向后继续拼接,重复以上过程,直到相应行中的所有纸片都已经完成拼接且所有的拼接均满足要求,或者所有可能的方案都无法满足要求(全为0),此时程序将回溯到最近一个还有未探索节点(没有选取过的待拼接纸片)的位置,选取其他方案再次进行拼接。另外,如果程序判定当前的拼接需要人工干预,则会显示出当前纸片与其他所有剩余纸片的拼接效果,用户选出正确的方案之后,选取的方案将会被记录下来,在之后的拼接中将直接选取该结果,无需再进行人工干预。
下面结合实验对本发明的应用效果作详细的描述。
1、与传统中心聚类法对比
本实验采用2013年数学建模赛题所提供的碎纸片进行拼接。该碎纸片数据集将文档分割成了11行19列共计209张碎纸片。采用改进中心聚类法先对碎片进行聚类,设定中线偏移误差阈值t1=1,并与原始的中心聚类法进行性能对比。所得结果如图6。
由图6可以看出,传统中心聚类在设定阈值为1时将碎片聚为了20类,其中每一类碎片中最多的有20张,最少的有1张。改进中心聚类法则将碎片聚为12类,只比正确答案多聚了一类,并且只有一张碎片因为比较特殊而被聚错。由此可见,改进中心聚类法相比中心聚类法更加可靠。因为在没有其它人工干预的情况下改进的算法拼接错误更少;所得结果需要进行调整的次数更少,可以降低拼接人员的工作量。
2、与遗传算法对比
本发明所实现的遗传算法首先初始化一系列排列顺序组成种群(实验中取种群数目为200),并根据每个个体的排列顺序计算出一个相似度向量,每个个体的相似度是排列中所有碎片相似度之和,也被叫做适应度。得出适应度后,通过记录种群中适应度大于最大适应度targetr(实验中设为0.72)倍的个体并将他们以crossoverrat(实验中设为0.3)的比例进行杂交。最后再以变异率mutationrat=0.2的比例进行变异,更新种群。算法将在种群最大适应度变化不超过1时结束。由于遗传算法具有不确定性,所以实验中将遗传算法程序段重复执行50次并记录每次迭代中适应度最高的个体的适应度。在50次迭代结束后,以适应度最高的个体对碎片进行复原。
以既有横切又有纵切情况碎片拼接复原为例,将上一步改进中心聚类法执行得到的聚类结果作为输入,使用遗传算法求解,并将结果与dfs深度优先搜索求得的结果进行对比。图7给出了深度优先搜索算法和遗传算法对某一类碎片进行拼接复原的结果。可以看到,遗传算法求解得到的复原碎片只是初具雏形。然而,dfs深度优先搜索算法得到的碎片则将原始碎片成功复原。
图8则给出了遗传算法实现碎片拼接过程中最优适应度在50次迭代中的的变化情况。可以看出,遗传算法求解碎片拼接问题结果不稳定,最高的适应度则只有430左右,而正确的解适应度却是648。就算是执行了50次,求得的结果也与正确的解有一定差距。
最后,给出综合了改进中心聚类法以及dfs拼接复原算法的拼接结果。如图9所示。本发明基于改进中心聚类法以及dfs复原拼接算法,通过推导阈值范围公式使得中心聚类法效果更好,并在dfs拼接复原算法中综合相似度、差异度、留黑阈值等参数来充分挖掘两张碎片的匹配程度,进一步降低人工干预次数。实验证明,综合上述两种方法的拼接算法获得了很好的效果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!