一种数据差异比较方法与流程
本发明涉及计算机数据传输领域,尤其涉及一种数据差异比较方法。
背景技术:
同一数据多处存放、多次存储的情况经常发生,比如:数据的备份、资料的归档,甚至是不当的使用习惯,都会在有意或无意间生成原有数据的一个或多个副本,当相同数据的占用量越来越大时,势必会造成存储空间的短缺、查找过程的繁琐。
传统意义上,在不同数据之间查询比较的方式方法多种多样,数据量不大时,简单的人工筛选就可能解决问题,无论人工方法或者借助于专门的工具,在比较的过程中都会使用这样那样的比对规则,或称之为差异算法。
简单的差异算法,像,手工的名称比对、大小判断、时间比较、实际内容比较等方式在二个或少量的比较对象之间操作,方便有效。使用适当的比较规则,再加上特定的差异算法或工具,来批量地处理大数据集之间的差异关系,是当前企事单位中较为迫切的需求。
一般情况下,排除软硬件上的限制因素和算法规模(需要解决的问题的大小)外,判断一种算法的优劣可能有二种方式:
(1)时间:即完成此算法使用的执行时间,可能是算法执行所使用的总时间,也或是单次执行某个特定步骤所返回的时间;
(2)空间:完成算法执行所需的存储空间数量大小;此处的空间多指内存空间大小,比如:编译指令所使用的内存数量,调用函数或中间库时使用的堆栈数量,存储常量、变量或中间结果的内存使用量等;
理论上,较为合适的算法规则可能会同时兼顾时间和空间,但随着硬件设备的发展,空间因素影响的比例在逐渐减低,很多情况下,用空间(增加存储容量)换取时间的做法也越来越广泛。比如,常见数组排序中的冒泡算法,通过增加中间变量(会导致内存占用量提高),用空间换时间,执行速度加快;而通过异或运算不使用中间变量的情况下,执行时间会延长。
但是一般的算法中对于算法数据的比较不合理,无法满足数据传输要求。
技术实现要素:
有鉴于此,本发明要为了解决现有技术中算法的数据的比较不合理的问题,从而提供一种数据差异比较方法。
本发明的技术方案是这样实现的:
一种数据差异比较方法,包括源文件、目标文件和系统组件,包括以下步骤:
(1)将目标文件分隔成多个字节的数据块,生成目标数据块编码;
(2)所述系统组件为所述目标数据块编码中的每个所述数据块计算出十六进制的目标校验和;
(3)所述系统组件将所述目标数据块编码和所述目标校验和合并形成十六进制的目标文件序列列表;
(4)将所述目标文件序列列表传输至所述源文件;
(5)所述系统组件将所述源文件按照所述目标文件的字节个数,生成源数据块编码;
(6)所述系统组件为所述源数据块编码中的每个数据块计算十六进制的源校验和;
(7)从所述目标文件序列列表中,按照顺序获取目标数据块的每个所述目标数据块编码和所述目标校验和;
(8)将步骤7生成的所述目标数据块编码和所述目标校验和,同步骤5、步骤6生成的所述源数据块编码和所述源校验和,交集比较,当所述源数据块与所述目标数据块对比相同时,表示源文件和目标文件的相同部分,无需再次传输相同部分;当所述源数据块和所述目标数据块异同时,表示所述源文件和所述目标文件的异同部分;所述系统组件记录源文件中此异同数据块的实际物理存储地址,和实际数据块内容,生成所述源文件的差异数据地址数据列表;同时比较下一组所述源数据块与所述目标数据块;
(9)步骤8重复运行,直至步骤7中所述目标文件序列列表中的所有列表配比结束;
(10)当上述过程完成后,所述源数据块按顺序组织差异数据地址数据列表,所述系统组件生成源数据与目标数据的差异数据,同时,将所述差异数据返回给目标文件;至此,所述源文件和所述目标文件二者数据的差异比较完毕。
优选的,所述步骤1中,分隔目标文件数据块的大小由系统变量。
优选的,所述步骤2中,如果所述目标校验和的计算数值超过十六进制的最大值ff,则使用目标补码作为目标检验和。
优选的,所述步骤6中,如果所述源校验和的计算数值超过十六进制的ff,则使用源补码作为所述源检验和。
优选的,包括所述步骤10中,将所述目标数据与所述差异数据合并,完成所述源文件的传输。
有益效果:
(1)使用源和目标数据的内存映像,快速比对数据集合中的差异部分。差异数据的形成规则(或对比规则)是基于内存初始化地址和数据偏移量的组合方式,当数据分割的大小控制在适当的范围时,数据差异的对比率、准确率、消耗的实际时间都具备较高的水平。
(2)在确定差异数据的传输方式时,即可以传输差异数据部分,也可以传输相同数据部分,并且源或目标的对比基准可以自由定义,配置方式灵活多样。
附图说明
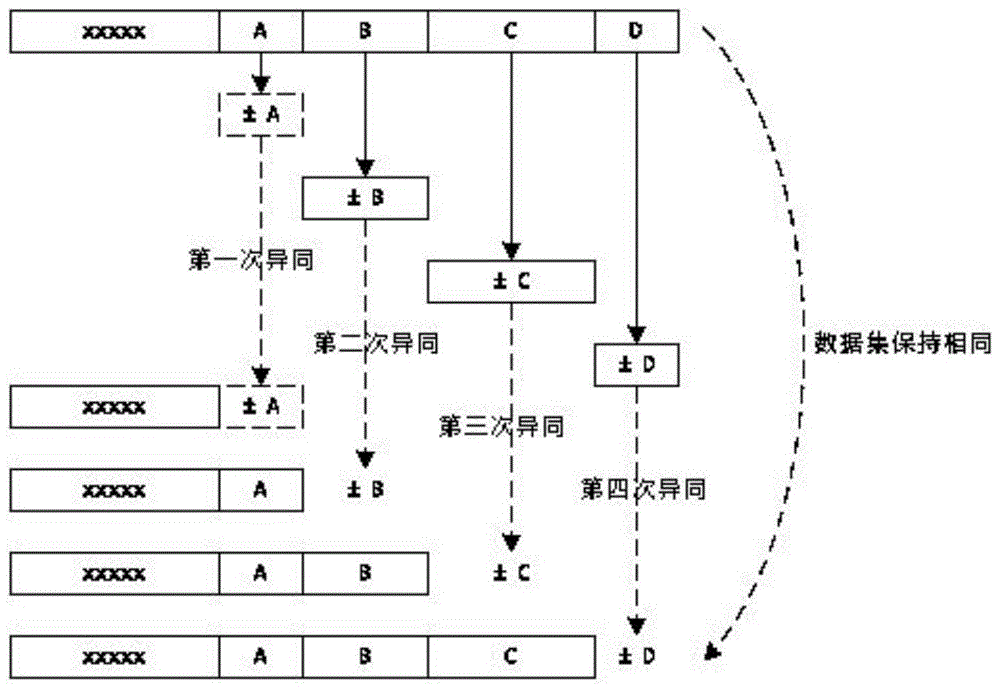
图1为本发明数据差异比较方法的原理图;
图2为本发明中差异数据的示意图;
图3为本发明中差异比较时内存起始地址及偏移量示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1-3所示,本发明实施例提出了一种数据差异比较方法,包括源文件、目标文件和系统组件,包括以下步骤:
(1)首先,分隔目标文件数据块的大小由系统变量定义,本实施例将目标文件分隔成1024字节的数据块,生成目标数据块编码;
(2)所述系统组件为所述目标数据块编码中的每个所述数据块计算出十六进制的目标校验和,如果所述目标校验和的计算数值超过十六进制的最大值ff,则使用目标补码作为目标检验和;
(3)所述系统组件将所述目标数据块编码和所述目标校验和合并形成十六进制的目标文件序列列表;
(4)将所述目标文件序列列表传输至所述源文件;
(5)所述系统组件将所述源文件按照所述目标文件的1024个单位分隔,生成源数据块编码;
(6)所述系统组件为所述源数据块编码中的每个数据块计算十六进制的源校验和,如果所述源校验和的计算数值超过十六进制的ff,则使用源补码作为所述源检验和;
(7)从所述目标文件序列列表中,按照顺序获取目标数据块的每个所述目标数据块编码和所述目标校验和;
(8)将步骤7生成的所述目标数据块编码和所述目标校验和,同步骤5、步骤6生成的所述源数据块编码和所述源校验和,交集比较,当所述源数据块与所述目标数据块对比相同时,表示源文件和目标文件的相同部分,无需再次传输相同部分;当所述源数据块和所述目标数据块异同时,表示所述源文件和所述目标文件的异同部分;所述系统组件记录源文件中此异同数据块的实际物理存储地址,和实际数据块内容,生成所述源文件的差异数据地址数据列表;同时比较下一组所述源数据块与所述目标数据块;
(9)步骤8重复运行,直至步骤7中所述目标文件序列列表中的所有列表配比结束;
(10)当上述过程完成后,所述源数据块按顺序组织差异数据地址数据列表,所述系统组件生成源数据与目标数据的差异数据,同时,将所述差异数据返回给目标文件;至此,所述源文件和所述目标文件二者数据的差异比较完毕。最后将所述目标数据与所述差异数据合并,完成所述源文件的传输。
在本实施例中,我们为什么需要做到差异比较呢。下面假设某人甲办公室设备中有一个文件a,家庭里也有一个同名文件a(为了区分办公室的a文件,此处取名称是b),现在用户甲需要在家庭中处理这个文件a,由于不清楚a和b文件之间到底哪个文件是最后一次使用的(或新近修改的),他可能使用的常规办法如下:将办公室的a文件,通过网络复制到家庭,然后比较a和b的实际内容,以确认最终的结果。
上面的办法是可行的。但问题也随期而至,比如:(1)文件a的容量较大,网络传输的时间是个问题;(2)文件a和文件b有着很大的相似度,实际内容差别很少,如何筛选出这些差别?通过人工的方式是否总是可行的?(3)如若需要比较的文件数量较多,比如办公室和家庭中都有10个同名文件,怎么办?50个同名文件呢?100个同名文件呢?(4)采用直接覆盖更新的方式,比如,将办公室的文件全部更新到家庭中,遇到名称相同、大小相同或时间相同的都以办公室的文件为准(或反过来,以家庭文件为准),就一定准确吗?无论上面的哪种方式,都不能很好的解决二个或多个数据集之间相似度的比对问题。
差异性的比较一般是用在checkincrementframe算法中,其中checkincrementframe算法中采用的系统组件为差异数据同步dicompsync组件。
checkincrementframe算法的一般判断过程如下:
(1)使用文件名称(开启checkframefilename=on)进行二个数据集合的文件列表判断;比如:源端有a文件,目标端没有a文件,则checkincrementframe算法会直接同步a文件,相当于复制a文件;
(2)在源和目标端都有同名称的a文件的情况下,checkincrementframe算法开启checkframeothers=0n|off,表示比较二个同名称文件的文件(二进制)类型、数据大小、占用空间大小(checkframersize=on|off)、创建时间、修改时间(checkframemtime=on|off)和读取时间(checkframertime=on|off);若上述六个选项中的任一个的比较结果是否定的,则checkincrementframe算法开启差异比较(checkframereturn=on|off);
(3)由步骤(2)的结果,目标端发送差异比较请求给源端,源在内存中按照目标数据的大小按照固定数据块(默认1024字节,选项本发明中系统变量为checkframeinitsiz,checkframeinitsize=1024可自定义修改)分割目标数据,每个分割的固定内存块按照实际内存地址编码(相当于唯一编号),分割的内存块同时记录此块相对于整个数据在内存起始地址的偏移量;
(4)源端对由步骤(3)形成的目标数据块进行块比较,比如,数据块是1024,则按照1024的大小比较每个对应的内存块,如数据块相同,则说明源和目标之间的实际内容是相同的,反之,数据块不会相同,则异同的内存数据块置df标识位。
(5)将步骤(4)中产生的df标识位内存块信息(包括起始地址,数据块长度,内存地址偏移量,实际数据块内容等)发送至目标数据端,使用数据块内容覆盖起始地址+偏移量的目标内容,完成异同数据的比较。
是否可以试想如下的过程呢?二个数据集之间,有着很大的相似度,当需要保持二者之间的一致性,仅需同步二者之间的异同部分,而跳过(或忽略)相同的部分,如此,无论是数据的传输或数据的比较,传输量和比对工作量都将会大大降低。为此,应用框架atombaseframe下的差异数据同步dicompsync组件实现了此类功能需要,而数据差异比较算法checkincrementframe是实现此功能的核心方案。
(3)checkincrementframe算法支持定时执行功能,实际时间间隔、实际执行时间点、数据差异的执行频率(次数)可由使用者自定义安排。如此,对于源端、目标端的系统资源分配、负荷大小控制等问题都可以伸缩自如的应对。特别是在大批量的、单位数据较小的情况下,算法执行效率高。
(4)checkincrementframe算法配合atombaseframe应用框架下的差异数据同步dicompsync组件可实现增量数据传送,配合自定义应用组件baseplugins也可以实现框架中需要使用差异数据算法的其他功能,比如,人脸图像识别,车牌识别对比等。
最后需要说明的是:以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!