一种基于剪枝搜索的简单吃墩博弈求解方法与流程
本发明属于博弈论、计算机博弈、集合论、人工智能技术领域,尤其通过数学推理构建精确决策树、哈希缓存、特征构建、模型设计、流程设计等。
背景技术:
计算机博弈(也称机器博弈)是人工智能领域最具挑战性的研究方向之一。牌类博弈是人类长期从事的智力活动,对其泛型的研究与认知不仅能提高人类的智力水平,而且对工业生产、经济活动以及其他科学技术的研究都具有很高的指导价值。
计算机牌类博弈的发展总体不及棋类,因为牌类博弈基本是不完全信息的,在计算机拥有中等人工智能以前,对不完全信息的策略分析主要基于概率统计和深度学习,决策能力远不及人类。因此,普遍的思路是把牌类博弈的研究分为其完全信息子类与根据不完全信息对完全信息的预测两个部分,而前者的已有一定的进展。
牌类博弈的典型是吃墩博弈,吃墩博弈的典型有合约桥牌(简称桥牌)与塔罗牌等,桥牌的完全信息子类又叫“双明手桥牌”。目前,计算机双明手桥牌的求解方法主要有哈希缓存、机器学习、深度学习以及它们的组合,它们有一个共同的缺陷:如果把特征维度推广,则多项式时间内只能求近似解。而推广后的求解是否存在多项式算法,目前既未证明也未反证。
任何问题的研究都应该从简单到复杂,从特殊到一般。要研究双明收桥牌的求解问题,从吃墩博弈的最简形式着手是一条新的思路。所谓最简单的吃墩博弈(后续统称简单吃墩博弈),即是把偶数张不带花色仅有大小之分的卡牌随机分发给两名玩家,双方一攻一守是一回合,产生一敦牌,赢墩方继续攻牌,最后结算墩数。简单吃墩博弈因其具有吃墩博弈最简形式的特点,其任何规律对于其他吃墩博弈而言都是元子的,对其进行的任何研究都可以作为对它们的研究的拆分和组成部分。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种能够帮助桥牌或塔罗牌玩家在博弈时更精确地分析策略,能够帮桥牌或塔罗牌的计算机智能程序降低搜索空间,从而提升它们的时间效率的基于剪枝搜索的简单吃墩博弈求解方法。本发明的技术方案如下:
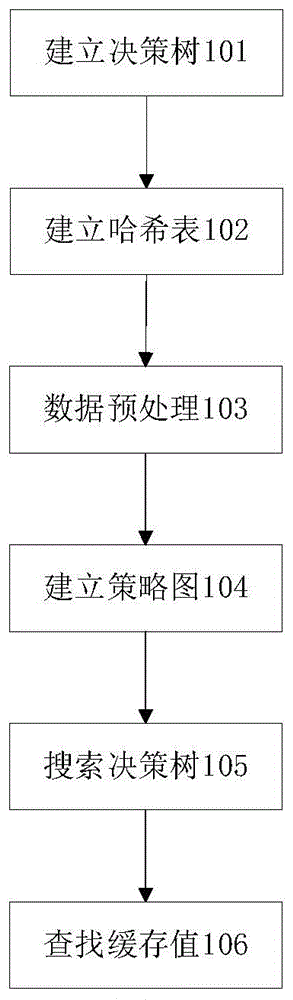
一种基于剪枝搜索的简单吃墩博弈求解方法,其包括以下步骤:
101、建立决策树:根据博弈理论,建立用于剪枝搜索精确最优解的决策树,包括:进攻分枝树、防守分枝树;进攻分枝树用于进攻方快速选择进攻策略,防守分枝树用于防守方根据进攻方的进攻策略快速回应防守策略;
102、建立哈希表:建立哈希表,遍历给定范围内的阶数的所有博弈实例,求出每个实例的最优解,并以每个实例的输入为键、输出为值写入哈希表;
103、数据预处理:根据输入的博弈实例,对实例的数据结构进行初步建模;
104、建立策略图:根据内部策略连续性特征,对实例的数据结构进行再次包括策略排序、连续策略组合成结点、双方相邻策略结点连成边加工,建立与原始结构一一对应的有向图;
105、搜索决策树、根据101所建立的决策树模型,对当前实例的策略进行决策搜索;
106、查找缓存值:根据102所建立的哈希缓存表,当搜索进行到阶数低于缓存边界时,在缓存中查找局部博弈的最优解。
进一步的,所述步骤101建立决策树,包括:进攻分枝树、防守分枝树,具体包括:
进攻分枝树:在进行105搜索决策树且遍历到第n、n+1个进攻策略时,若采用ccn+1所造成的条件最优分数与采用ccn所造成的条件最优分数不同,则停止搜索,并返回两者中较大的一个作为最优分数:
thenreturnmax(otd(cc1),otd(cc2))
elsecontinue
防守分枝树:当进攻方采用非最高价值策略时,回应“刚吃”策略,即采用价值大于进攻策略的防守策略中的最低价值策略;当进攻方采用最高价值策略且防守方拥有双方最低价值策略时,回应“垫让”策略,即采用该最低价值策略;其余情况需遍历所有防守策略:
ifcca<a.max
thenccb=g.next(cca)
elseifb.min==g.min
thenccb=b.min
elseccb=search(b)
进一步的,所述步骤102建立哈希表,具体包括:构建n阶及以下阶数博弈的哈希缓存表:遍历n=1..n,采用排列组合算法逐个生成阶数为n的博弈实例,对每个实例采用搜索决策树进行求解,求解时只需搜索第一层树即可,搜索到第二层时阶数变为n-1,由于n-1阶及以下阶数的解已缓存,故直接进行查找缓存值,在生成哈希表的同时对每个阶数的最优解进行统计,按照最优解进行分组,得到相同最优解个数分布表及曲线图,该表和图可用于人类选手在博弈时进行对手牌实力的直观估计。
进一步的,所述步骤103数据预处理,根据输入的博弈实例,对实例的数据结构进行初步建模,具体为:
(1)定义:一类博弈称为简单吃墩博弈,记为sttg,满足:任取g属于sttg,g的参与者集合p的基数|p|=2,g具有属性集首攻守方{a,b}=p,g具有属性阶数o,任取pi属于p,pi具有属性卡牌集c包含于自然数集n,|c|=o,
a.c与b.c之交=空集,令他们的并集为={1,2,…,o};
(2)对具体的博弈实例,将其数据按照(1)定义所述模型建立对应的数据结构。
进一步的,所述步骤104建立策略图:根据内部策略连续性特征,对实例的数据结构进行再次加工,建立与原始结构一一对应的有向图,具体包括:
(1)定义:任取g属于sttg,称a.c的子集cc是a的一个连续区间:任取卡牌c属于b.c均有c<min(cc)或c>max(cc),任取ca属于a.c-cc均存在cb属于b.c使得ca<cb<min(cc)或max(cc)<cb<ca;同理可定义b的连续区间;显然,对于a,存在唯一的连续区间序列a.ccl={cci}1..n使得a.c=cci之并,同理存在b.ccl;
(2)定义:任取g属于sttg,存在唯一的连续区间序列g.ccl=a.ccl与b.ccl之交,任取cci,cci+1属于g.ccl均有max(cci)<min(cci+1);以连续区间为节点,由路径g.ccl、a.ccl、b.ccl之并构成的有向图称为g的策略图,记为sgr;
(3)定义:任取g属于sttg,g的两个参与者pi按极大极小最优策略进行博弈,最终所得墩数称为双方的最优墩数,记为t;墩数差a.t-b.t称为g的最优墩数差,记为otd;当首攻策略cc给定时,首守方采用极大极小最优策略,最终的最优墩数和墩数差记为t(cc)和otd(cc);
(4)定义:任取g属于sttg,当a进攻时,a打出属于连续区间cc的某张卡牌,剩余的攻防均采用极大极小最优策略,则记g的最终墩数差为td(cc);当a的进攻策略为cca轮到b防守时,b打出属于连续区间ccb的某张卡牌,剩余的攻防均采用极大极小最优策略,则记g的最终墩数差为td(cca,ccb);
(5)定义:任取g属于sttg,a进攻时的所有极大极小最优策略所属的连续区间构成的集合称为a的最优进攻策略集,记为oa,即任取cc属于oa,均有td(cc)=otd;当g.a进攻时打出某连续区间cca中的牌,b防守时的所有极大极小最优策略所属的连续区间构成的集合称为b的最优防守策略集,记为od(cca),即任取ccb属于od(cca),均有td(cca,ccb)=otd(cca);
对具体的博弈实例,将其预处理数据结构按照(1-2)所述模型建立策略图,并按照(3-5)所述模型确定求解目标。
进一步的,所述步骤105搜索决策树,具体搜索流程如下:
(1)遍历a.ccl的每个cc,记为迭代器cca,初始化otd(cca)=-o-1;
(2)根据防守引理:若cca<a.tail,则取ccb=g.next(cca),否则若b.head==g.head,则取ccb=b.head,否则遍历b.ccl的所有cc,记为迭代器ccb;
(3)将cca与ccb暂时抽离各自的ccl,此时g坍缩为自身的局部博弈,其o减少了1,递归调用(1),求得局部的otds,此时若cca<ccb,则更新otd(cca)t=otds+1,否则更新otd(cca)t=-otds-1;
(4)若otd(cca)t>otd(cca),则更新otd(cca)=otd(cca)t;根据进攻引理:更新前若otd(cca)<-o,则继续搜索,否则更新后返回otd=-otd(cca),流程结束。
进一步的,所述步骤106查找缓存值,具体包括:随着步骤105搜索决策树的进行,每次递归搜索都会经历阶数坍缩的过程,当阶数坍缩到缓存边界以内时,以当前子博弈的结构编码为键查找步骤102所构建的哈希缓存表,若查到有值则返回该值,否则继续搜索。
本发明的优点及有益效果如下:
本发明将吃墩类博弈的结构及流程进行了数学建模,提炼出最简形式的吃墩博弈,并通过数学推导发现了求解搜索中的精确剪枝规律,并基于这些规律建立了剪枝决策树和哈希缓存表。这种基于数学原理的搜索剪枝,其最大的优点在于保证剪枝后的搜索结果与朴素的极大极小搜索结果完全一致,并且无需对结果进行后验评价或对抗分析。由于简单吃墩博弈是桥牌和塔罗牌等经典吃墩博弈的真子博弈,在这些博弈的实战残局中,当面临与简单吃墩博弈相一致的策略选择场景时,可以根据本发明的决策树和哈希缓存快速求出最终墩数和最优策略,其效率和准确率远高于其他拟合分析方法(准确率为100%)。
附图说明
图1是本发明提供优选实施例提供一种基于剪枝搜索的简单吃墩博弈求解方法的流程图;
图2为本发明实例一提供一种基于剪枝搜索的简单吃墩博弈求解方法的一个8阶博弈实例的数据预处理结构图;
图3为本发明实例一提供一种基于剪枝搜索的简单吃墩博弈求解方法的一个8阶博弈实例的策略有向图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
一种基于剪枝搜索的简单吃墩博弈求解方法,其包括以下步骤:
101、建立决策树:根据对博弈类的理论研究所得出的结论,建立用于剪枝搜索精确最优解的决策树;
102、建立哈希表:建立哈希表,遍历给定范围内的阶数的所有博弈实例,利用103至106的过程求出每个实例的最优解,并以每个实例的输入为键、输出为值写入哈希表;
103、数据预处理:根据输入的博弈实例,对实例的数据结构进行初步建模;
104、建立策略图:根据内部策略连续性等特征,对实例的数据结构进行再次加工,建立与原始结构一一对应的有向图;
105、搜索决策树:根据101所建立的决策树模型,对当前实例的策略进行决策搜索;
106、查找缓存值:根据102所建立的哈希缓存表,当搜索进行到阶数低于缓存边界时,在缓存中查找局部博弈的最优解。
(1)建立决策树
已知任意两个进攻策略所造成的条件最优分数半差不超过1。因此在进行搜索决策树且遍历到第n、n+1个进攻策略时,若采用ccn+1所造成的条件最优分数与采用ccn所造成的条件最优分数不同,则停止搜索,并返回两者中较大的一个作为最优分数:
已知而面对给定进攻策略,任意两个防守策略所造成的条件最优分数半差不超过1。因此当进攻方采用非最高价值策略时,回应“刚吃”策略,即采用价值大于进攻策略的防守策略中的最低价值策略;当进攻方采用最高价值策略且防守方拥有双方最低价值策略时,回应“垫让”策略,即采用该最低价值策略;其余情况需遍历所有防守策略:
ifcca<a.max
thenccb=g.next(cca)
elseifb.min==g.min
thenccb=b.min
elseccb=search(b)
(2)建立策略图
将每方价值连续的策略看成一个整体即一个结点,从而使实例的初始结构等价于一个有向图,按照有向图的结点与边建立的数据结构。
(3)剪枝搜索
根据前面建立的模型,进行如下流程的剪枝:
①遍历a.ccl的每个cc,记为迭代器cca,初始化otd(cca)=-o-1;
②根据防守引理:若cca<a.tail,则取ccb=g.next(cca),否则若b.head==g.head,则取ccb=b.head,否则遍历b.ccl的所有cc,记为迭代器ccb;
③将cca与ccb暂时抽离各自的ccl,此时g坍缩为自身的局部博弈,其o减少了1,递归调用(1),求得局部的otds,此时若cca<ccb,则更新otd(cca)t=otds+1,否则更新otd(cca)t=-otds-1;
④若otd(cca)t>otd(cca),则更新otd(cca)=otd(cca)t;根据进攻引理:更新前若otd(cca)<-o,则继续搜索,否则更新后返回otd=-otd(cca),流程结束。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!