日志处理方法、装置、存储介质和电子装置与流程
本发明涉及计算机领域,具体而言,涉及一种日志处理方法、装置,存储介质和电子装置。
背景技术:
随着互联网+时代的来临,数据的价值越来越凸显。产品的数据呈现指数型增长,非结构化的特点。利用分布式处理平台spark和hadoop技术,构建大数据平台是最为核心的基础数据的存储、处理能力中心,提供了强大的数据处理能力,满足了数据的交互需求。同时通过sparkstreaming,可以有效满足企业实时数据的要求,构建企业发展的实时指标体系。
但现有的对日志的存储方式存在日志处理不够实时,在分布式的系统中扩容,容错有所欠缺,不能方便的进行大数据日志的etl(extract-transform-load的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程)的清洗。
针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
本发明实施例提供了一种日志处理方法、装置,存储介质和电子装置,以至少解决相关技术中对日志的处理效率低,不能满足对日志数据的需要的技术问题。
根据本发明实施例的一个方面,提供了一种日志处理方法,包括:接收开源组件发送的多个待处理日志,其中,多个待处理日志的日志格式是开源组件利用预设日志格式对多个日志进行的转换;对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。
根据本发明实施例的另一方面,还提供了一种日志处理方法,包括:利用预设日志格式对获取的多个日志进行格式转换,得到多个待处理日志;将多个待处理日志分别存储至与各个待处理日志对应的主题文件夹中;将主题文件夹中的多个待处理日志发送至分布式处理平台中。
根据本发明实施例的另一方面,还提供了一种日志处理装置,包括:接收模块,用于接收开源组件发送的多个待处理日志,其中,多个待处理日志的日志格式是开源组件利用预设日志格式对多个日志进行的转换;第一确定模块,用于对多个待处理日志进行数据清洗,得到多个第一目标日志;第二确定模块,用于按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。
根据本发明实施例的另一方面,还提供了一种日志处理装置,包括:第三确定模块,用于利用预设日志格式对获取的多个日志进行格式转换,得到多个待处理日志;存储模块,用于将多个待处理日志分别存储至与各个待处理日志对应的主题文件夹中;发送模块,用于将主题文件夹中的多个待处理日志发送至分布式处理平台中。
根据本发明实施例的另一方面,还提供了一种日志处理系统,包括:分布式处理平台spark,其中,spark被设置为运行时执行上述中的方法;开源组件kafka,与分布式处理平台连接,其中,kafka被设置为运行时执行上述的方法;
根据本发明的又一个实施例,还提供了一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
在本发明实施例中,利用开源组件将收集的日志进行格式转换,得到多个待处理日志,将待处理日志发送至分布式处理平台;分布式处理平台对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。可以实现实时处理日志,提高了日志处理的效率,进而解决了相关技术中日志的处理效率低,不能满足对日志数据的需要的技术问题。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
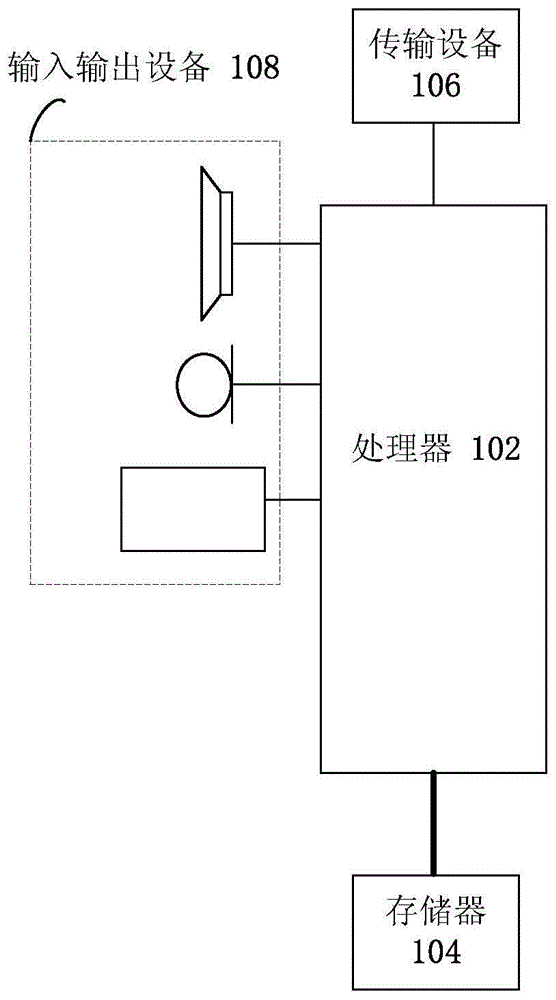
图1是本发明实施例的一种日志处理方法的移动终端的硬件结构框图;
图2是根据本发明实施例提供的日志处理方法的流程示意图(一);
图3是根据本发明实施例提供的日志处理方法的流程示意图(二);
图4是根据本发明实施例提供的日志处理装置的结构示意图(一);
图5是根据本发明实施例提供的日志处理装置的结构示意图(二);
图6是根据本发明实施例提供的日志处理系统的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
根据本发明实施例,提供了一种日志处理方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
本发明实施例所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。以运行在移动终端上为例,图1是本发明实施例的一种日志处理方法的移动终端的硬件结构框图。如图1所示,移动终端10可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)和用于存储数据的存储器104,可选地,上述移动终端还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述移动终端的结构造成限定。例如,移动终端10还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
存储器104可用于存储计算机程序,例如,应用软件的软件程序以及模块,如本发明实施例中的日志处理方法对应的计算机程序,处理器102通过运行存储在存储器104内的计算机程序,从而执行各种功能应用以及数据处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至移动终端10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
传输装置106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括移动终端10的通信供应商提供的无线网络。在一个实例中,传输装置106包括一个网络适配器(networkinterfacecontroller,简称为nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(radiofrequency,简称为rf)模块,其用于通过无线方式与互联网进行通讯。
图2是根据本发明实施例提供的日志处理方法的流程示意图(一),如图2所示,该方法包括如下步骤:
步骤s202,接收开源组件发送的多个待处理日志,其中,多个待处理日志的日志格式是开源组件利用预设日志格式对多个日志进行的转换;
步骤s204,对多个待处理日志进行数据清洗,得到多个第一目标日志;
步骤s206,按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。
通过上述步骤,利用开源组件将收集的日志进行格式转换,得到多个待处理日志,将待处理日志发送至分布式处理平台;分布式处理平台对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。可以实现实时处理日志,提高了日志处理的效率,进而解决了相关技术中日志的处理效率低,不能满足对日志数据的需要的技术问题。
需要说明的是,上述中的执行主体可以是分布式处理平台spark,但不限于此。
需要说明的是,上述中的开源组件kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,kafka可以通过kafkaconnect连接到外部系统(用于数据输入/输出),并提供了kafkastreams,一个java流式处理库(计算机)。kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
需要说明的是,多个待处理日志的格式是kafka规范的,便于结构化的解析,、预设日志格式可以为:[logtime][operation],json;例如:[2013-04-101:00:09][click],{"time":12344343,"server":"1001"}。
在本实施例中,kafka中的应用程序可以通过logging模块,或者通过nginxaccesslog收集客户端的日志存储在本地,然后使用以下开源组件rsyslog,filebeat,scribeagent等收集日志,producer到kafka的topic中。
需要说明的是,apachespark是一个开源集群运算框架,最初是由加州大学柏克莱分校amplab所开发。相对于hadoop的mapreduce会在运行完工作后将中介数据存放到磁盘中,spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
在一个可选的实施例中,spark通过以下方式对多个待处理日志进行数据清洗:利用预设活动算法触发多个待处理日志的数据清洗;利用预设转换算法对触发之后的多个待处理日志进行数据清洗。例如,利用spark丰富的转换算法tranform,例如:map,flatmap,fliter,用户自定义函数(user-definedfunction,简称为udf)等实现数据的清洗,利用活动算法action,例如collect,save等触发数据清洗流程。
在一个可选的实施例中,通过以下方式按照预设时间间隔对多个第一目标日志进行分区处理:确定多个第一目标日志中各个第一目标日志的日志类型和日志时间,其中,日志时间是获取各个第一目标日志的时间;基于日志类型和日志时间将各个第一目标日志分区存储至第一预设目录中,得到多个第二目标日志。例如:通过设置合理的sparkstreaming的batchinterval(即是预设时间间隔)的时间(例如设置为5分钟),分批按照logtype(日志类型)和logtime(日志时间)做二级分区写入到hdfs的目录下/warehouses/{logtype}/{logtime}(第一预设目录)做存储。数据的延迟时间大致和batchinterval相当,如果是前面设置的5分钟,数据在hive中的展示也是5分钟的延迟。通过设置合理的batchinterval,可以达到数据近实时收集的目的。在本实施例中,spark计算引擎是存储到hadoop存储系统中的。
需要说明的是,时间片或批处理时间间隔(batchinterval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个rdd实例。
需要说明的是,hdfs是hadoopdistributefilesystem的简称,也就是hadoop的一个分布式文件系统。
在一个可选的实施例中,在得到多个第二目标日志之后,需要对多个第二目标日志实现正好一次的存储。我们知道2.0之前sparkstreaming只能做到at-leastonce(至少一次),spark框架很难帮你做到exactlyonce(正好一次),需要程序直接实现可靠的数据源和支持幂等性操作的下流。但是sparkstructurestreaming可以简单的实现exactlyonce。
需要说明的是,exactly-once即是每条数据只处理一次,是实时计算的难点之一,要做到每一条记录只会被处理一次的目的。
具体包括以下方式:
1)利用预设特征源接口对多个第二目标日志以正好一次exactlyonce的方式存储至第二预设目录中;例如:利用kafkasource,具体到源码上,source是一个抽象的接口traitsource(即是预设特征源接口),包括了structuredstreaming实现end-to-endexactly-once(端到端的正好一次)处理所一定需要提供的功能,kafka(kafkasource)的getoffset()通过读取上一个批次保存的kafka的offset,会通过在driver端的一个长时运行的consumer从kafkabrokers处获取到各个topic最新的offsets,getbatch方法从根据offset返回一个dataframe数据,commit会通过checkpoint机制在hdfs上面保存文件,记录kafka的offset位置,用于在故障时getoffset获取有效的offset值。在本实施例中,getoffset()的含义如下:每次读取hdfs的checkpoint的文件,获取本次读取kafka的开始位置,获取完之后更新本次读取的结束位置到checkoing文件。
2)利用预设批处理函数对多个第二目标日志以正好一次exactlyonce的方式存储至第二预设目录中。例如:hdfssink:这个仅有的addbatch()方法支持了structuredstreaming实现end-to-endexactly-once处理所一定需要的功能。hdfssinkaddbatch()的具体实现是会在hdfs的目录下有一个metadata记录当前完成的最大batchid,当从故障恢复的时候,如果作业的batchid小于等于metadata的最大batchid,作业会跳过。从而实现数据的幂等性写入。在本实施实施例中,addbatch()包括以下功能:如果本次提交的batchid小于hdfs元数据中记录的batchid,认为任务这个batchid已经写入过,直接跳过。如果大于,则把日志数据写入分区目录,并且hdfs元数据batchid加1。
需要说明的是,sparkstreaming是spark核心应用程序编程接口(applicationprogramminginterface,简称为api)的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括kafk、flume、twitter、zeromq、kinesis以及tcpsockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“onestackrulethemall”的基础上,还可以使用spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
在一个可选的实施例中,在确定多个第二目标日志存储至第二预设目录失败的情况下,可以通过以下方式恢复多个待处理日志重新对日志进行处理:
1)在第一预设天数内,从本地缓存中重新获取多个待处理日志;例如:日志打印在本地文件系统保存按天滚动压缩保存10天,首先线上机器有完善的操作系统报警可以及时检测到硬盘容量问题避免写盘失败的问题。保存10天是避免下游系统出现问题,最糟糕的情况就是国庆长假没有及时发现,可以从数据源重新推送恢复。
2)利用日志收集系统从本地磁盘中恢复多个待处理日志;例如:scribeagent有心跳检测和日志的延迟检测可以及时发现问题,scribeagent记录发送文件的元数据信息,最主要的是文件的发送位置,可以用于数据的故障精确的恢复,并且采取tcp协议发送数据。
需要说明的是,scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是nfs,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。scribe的架构比较简单,主要包括三部分,分别为scribeagent,scribe和存储系统。
3)从开源组件中存储的副本中恢复多个待处理日志;例如,kafka线上副本数为3,日志持久化保存3天。如果sparkstructurestreaming失败,可以直接从kafka恢复数据。
4)读取多个待处理日志的元数据文件metadata和弥补函数offset恢复多个待处理日志;例如:sparkcheckpoint的机制保存kafka的offset等状态信息,当任务失败的时候spark任务启动会读取checkpoint文件夹下的metadata和offset文件,kafkaconsumer可以指定分区的offset读取数据,从而不会出现重复和遗漏。
5)从存储的多个副本文件中获取多个待处理日志,其中,多个副本文件存储在以下之一:本地节点,本地机架上的节点,不同机架上的节点。例如:hdfs的block机制:文件的副本数为3,hdfs的副本放置策略是:将第一个副本放在本地节点,将第二个副本放到本地机架上的另外一个节点,而将第三个副本放到不同机架上的节点。这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的几率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽。
6)insertoverwrite:hive的数据提取采用insertoverwrite的覆盖操作,相对于insertinto可以实现幂等性,可以重复操作。
在一个可选的实施例中,为了增加日志处理的效率,可以对kafka进行横向扩展,具体包括:
(1)增大kafkabrokes数目和topics的partitions,根据kakfa默认的dafaultpartionsabs(key.hashcode)%(numpartitions),可以让topic的数据分布到更多的broke及机器上,增大上下游的数据处理能力。
(2)增大kafka的partitions之后,spark的就可以根据kafka的consumergroups机制设置相同的rdd的partitions增大数据的消息能力
综上所述,通过日志的实时收集,高性能的kafka信息中间件,sparkonyarn的优异的分布式特性:高容错,易扩展,extractlyonce,解决了日志在分布式的系统中扩容,容错有所欠缺,不能方便的进行大数据日志的etl清洗的问题。
在一个可选的实施例中,为了增加spark对日志处理的效率,可以对spark应用进行优化:具体如下:
对spark长时间程序运行参数的优化:spark-submit--masteryarn--deploy-modecluster\
--confspark.yarn.maxappattempts=4\
--confspark.yarn.am.attemptfailuresvalidityinterval=1h\
--confspark.yarn.max.executor.failures={8*num_executors}\
--confspark.yarn.executor.failuresvalidityinterval=1h\
--confspark.task.maxfailures=8\
以cluster模型运行程序,spark驱动程序中的任何错误都会阻止我们长期运行的工作。幸运的是,可以配置spark.yarn.maxappattempts=4重新运行应用程序的最大尝试次数。如果应用程序运行数天或数周,而不重新启动或重新部署在高度使用的群集上,则可能在几个小时内耗尽4次尝试。为了避免这种情况,尝试计数器应该在每个小时都重置(spark.yarn.am.attemptfailuresvalidityinterval=1h),另一个重要的设置是在应用程序发生故障之前executor失败的最大数量。默认情况下是max(2*numexecutors,3),非常适合批处理作业,但不适用于长时间运行的作业。该属性具有相应的有效期间,对于长时间运行的作业,您也可以考虑在放弃作业之前提高任务失败的最大数量(spark.task.maxfailures=8)。通过这些优化配置项,spark应用在负责的分布式环境中可以保持长期可靠的运行。
在一个可选的实施例中,在spark中,按照二级分区存储格式建立第一表格,其中,第一表格用于存储多个第二目标日志的概括信息;在第一表格中建立第一子表格,其中,第一子表格用于存储查询多个第二目标日志的查询信息;定时为第一子表格添加分区,其中,分区用于存储信添加的日志的查询信息。
例如:按照前面的etl的二级分区存储格式,建立一个总表用于获取日志的概括信息,然后对logtype目录建立各个子表用于任务的查询和使用。通过调度系统定时为表添加分区。在此基础上面,我们编写python脚本识别新增的日志和日志格式,建立json格式到hiveschema的自动映射,自动创建建表语句,在hive仓库中建立表。这样自动化,减少人工维护和新数据的快速上线。
在一个可选的实施例中,可以对日志的小文件进行压缩和合并,将多个第二目标日志中的各个第二目标日志进行分割,得到多个分解日志;解析多个分解日志;将预设时间段内解析之后的多个分解日志进行合并,得到合并日志;压缩合并日志。
例如:为了追求近实时的效果,sparkstreaming会把每天的日志分割成多个小分解,这对namenode的内存使用和datanode的磁盘是不友好的。我们采用调度系统合并和压缩前一周的小文件,进行优化。具体的是通过设置mapreduce的map和reduce的处理的数据量,并发个数,设置动态分区,设置中间结果和输出结果的snappy压缩。然后巧妙的使用insertoverwrite的语句在合并和压缩过程中不会影响查询。
在一个可选的实施例中,对日志的存储进行监控:对多个第二目标日志的存储进行监控;在存储出现故障的情况下,发出报警信息。例如:重写spark的eventlistener监控,通过statsd发送metrics,存储于graphite,然后通过cabot配置报警规则,一旦触发,通过alarm服务报警。并且通过yarn提供的restful接口实时轮询作业状态,自动拉起服务,大幅度提供的作业的可靠性。
综上所述,通过sparkonyarn的技术实现存储的容错,扩容,监控等分布式健壮的系统方案,有效的提供产品的稳定性、数据分析的实时性、日志的大规模可靠存储。同时考虑到冷热数据的合并和压缩,在不影响数据分析的性能上,合理的减少hadoop的负载。
图3是根据本发明实施例提供的日志处理方法的流程示意图(二),如图3所示,该方法包括如下步骤:
步骤s302:利用预设日志格式对获取的多个日志进行格式转换,得到多个待处理日志;
步骤s304:将多个待处理日志分别存储至与各个待处理日志对应的主题文件夹中;
步骤s306:将主题文件夹中的多个待处理日志发送至分布式处理平台中。
通过上述步骤,利用开源组件将收集的日志进行格式转换,得到多个待处理日志,将待处理日志发送至分布式处理平台;分布式处理平台对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。可以实现实时处理日志,提高了日志处理的效率,进而解决了相关技术中日志的处理效率低,不能满足对日志数据的需要的技术问题。
需要说明的是,上述中的执行主体可以是开源组件kafka,但不限于此。
需要说明的是,上述中的开源组件kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,kafka可以通过kafkaconnect连接到外部系统(用于数据输入/输出),并提供了kafkastreams,一个java流式处理库(计算机)。kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
需要说明的是,多个待处理日志的格式是kafka规范的,便于结构化的解析,、预设日志格式可以为:[logtime][operation],json;例如:[2013-04-101:00:09][click],{"time":12344343,"server":"1001"}。
在本实施例中,kafka中的应用程序可以通过logging模块,或者通过nginxaccesslog收集客户端的日志存储在本地,然后使用rsyslog,filebeat,scribeagent等工具收集日志,producer到kafka的topic中。
需要说明的是,apachespark是一个开源集群运算框架,最初是由加州大学柏克莱分校amplab所开发。相对于hadoop的mapreduce会在运行完工作后将中介数据存放到磁盘中,spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
需要说明的是,kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(consumer)的进程可以从分区查询消息。kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
kafka高效地处理实时流式数据,可以实现与storm、hbase和spark的集成。作为群集部署到多台服务器上,kafka处理它所有的发布和订阅消息系统使用了四个api,即生产者api、消费者api、streamapi和connectorapi。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如jms、amqp等。
kafka架构的主要术语包括topic、record和broker。topic由record组成,record持有不同的信息,而broker则负责复制消息。kafka有四个主要api。
生产者api:支持应用程序发布record流。
消费者api:支持应用程序订阅topic和处理record流。
streamapi:将输入流转换为输出流,并产生结果。
connectorapi:执行可重用的生产者和消费者api,可将topic链接到现有应用程序。
topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
broker用来实现数据存储的主机服务器。
partition每个topic中的消息会被分为若干个partition,以提高消息的处理效率。
本发明实施例还提供了一种日志处理装置,图4是根据本发明实施例提供的日志处理装置的结构示意图(一),如图4所示,该装置包括:
接收模块42,用于接收开源组件发送的多个待处理日志,其中,多个待处理日志的日志格式是开源组件利用预设日志格式对多个日志进行的转换;
第一确定模块44,用于对多个待处理日志进行数据清洗,得到多个第一目标日志;
第二确定模块46,用于按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。
通过上述步骤,利用开源组件将收集的日志进行格式转换,得到多个待处理日志,将待处理日志发送至分布式处理平台;分布式处理平台对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。可以实现实时处理日志,提高了日志处理的效率,进而解决了相关技术中日志的处理效率低,不能满足对日志数据的需要的技术问题。
需要说明的是,上述中的开源组件kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,kafka可以通过kafkaconnect连接到外部系统(用于数据输入/输出),并提供了kafkastreams,一个java流式处理库(计算机)。kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
需要说明的是,多个待处理日志的格式是kafka规范的,便于结构化的解析,、预设日志格式可以为:[logtime][operation],json;例如:[2013-04-101:00:09][click],{"time":12344343,"server":"1001"}。
在本实施例中,kafka中的应用程序可以通过logging模块,或者通过nginxaccesslog收集客户端的日志存储在本地,然后使用以下开源组件rsyslog,filebeat,scribeagent等收集日志,producer到kafka的topic中。
需要说明的是,apachespark是一个开源集群运算框架,最初是由加州大学柏克莱分校amplab所开发。相对于hadoop的mapreduce会在运行完工作后将中介数据存放到磁盘中,spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
在一个可选的实施例中,spark通过以下方式对多个待处理日志进行数据清洗:利用预设活动算法触发多个待处理日志的数据清洗;利用预设转换算法对触发之后的多个待处理日志进行数据清洗。例如,利用spark丰富的转换算法tranform,例如:map,flatmap,fliter,用户自定义函数(user-definedfunction,简称为udf)等实现数据的清洗,利用活动算法action,例如collect,save等触发数据清洗流程。
在一个可选的实施例中,通过以下方式按照预设时间间隔对多个第一目标日志进行分区处理:确定多个第一目标日志中各个第一目标日志的日志类型和日志时间,其中,日志时间是获取各个第一目标日志的时间;基于日志类型和日志时间将各个第一目标日志分区存储至第一预设目录中,得到多个第二目标日志。例如:通过设置合理的sparkstreaming的batchinterval(即是预设时间间隔)的时间(例如设置为5分钟),分批按照logtype(日志类型)和logtime(日志时间)做二级分区写入到hdfs的目录下/warehouses/{logtype}/{logtime}(第一预设目录)做存储。数据的延迟时间大致和batchinterval相当,如果是前面设置的5分钟,数据在hive中的展示也是5分钟的延迟。通过设置合理的batchinterval,可以达到数据近实时收集的目的。在本实施例中,spark计算引擎是存储到hadoop存储系统中的。
需要说明的是,时间片或批处理时间间隔(batchinterval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个rdd实例。
需要说明的是,hdfs是hadoopdistributefilesystem的简称,也就是hadoop的一个分布式文件系统。
在一个可选的实施例中,在得到多个第二目标日志之后,需要对多个第二目标日志实现正好一次的存储。我们知道2.0之前sparkstreaming只能做到at-leastonce(至少一次),spark框架很难帮你做到exactlyonce(正好一次),需要程序直接实现可靠的数据源和支持幂等性操作的下流。但是sparkstructurestreaming可以简单的实现exactlyonce。
需要说明的是,exactly-once即是每条数据只处理一次,是实时计算的难点之一,要做到每一条记录只会被处理一次的目的。
具体包括以下方式:
1)利用预设特征源接口对多个第二目标日志以正好一次exactlyonce的方式存储至第二预设目录中;例如:利用kafkasource,具体到源码上,source是一个抽象的接口traitsource(即是预设特征源接口),包括了structuredstreaming实现end-to-endexactly-once(端到端的正好一次)处理所一定需要提供的功能,kafka(kafkasource)的getoffset()通过读取上一个批次保存的kafka的offset,会通过在driver端的一个长时运行的consumer从kafkabrokers处获取到各个topic最新的offsets,getbatch方法从根据offset返回一个dataframe数据,commit会通过checkpoint机制在hdfs上面保存文件,记录kafka的offset位置,用于在故障时getoffset获取有效的offset值。在本实施例中,getoffset()的含义如下:每次读取hdfs的checkpoint的文件,获取本次读取kafka的开始位置,获取完之后更新本次读取的结束位置到checkoing文件。
2)利用预设批处理函数对多个第二目标日志以正好一次exactlyonce的方式存储至第二预设目录中。例如:hdfssink:这个仅有的addbatch()方法支持了structuredstreaming实现end-to-endexactly-once处理所一定需要的功能。hdfssinkaddbatch()的具体实现是会在hdfs的目录下有一个metadata记录当前完成的最大batchid,当从故障恢复的时候,如果作业的batchid小于等于metadata的最大batchid,作业会跳过。从而实现数据的幂等性写入。在本实施实施例中,addbatch()包括以下功能:如果本次提交的batchid小于hdfs元数据中记录的batchid,认为任务这个batchid已经写入过,直接跳过。如果大于,则把日志数据写入分区目录,并且hdfs元数据batchid加1。
需要说明的是,sparkstreaming是spark核心应用程序编程接口(applicationprogramminginterface,简称为api)的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括kafk、flume、twitter、zeromq、kinesis以及tcpsockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“onestackrulethemall”的基础上,还可以使用spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
在一个可选的实施例中,在确定多个第二目标日志存储至第二预设目录失败的情况下,可以通过以下方式恢复多个待处理日志重新对日志进行处理:
1)在第一预设天数内,从本地缓存中重新获取多个待处理日志;例如:日志打印在本地文件系统保存按天滚动压缩保存10天,首先线上机器有完善的操作系统报警可以及时检测到硬盘容量问题避免写盘失败的问题。保存10天是避免下游系统出现问题,最糟糕的情况就是国庆长假没有及时发现,可以从数据源重新推送恢复。
2)利用日志收集系统从本地磁盘中恢复多个待处理日志;例如:scribeagent有心跳检测和日志的延迟检测可以及时发现问题,scribeagent记录发送文件的元数据信息,最主要的是文件的发送位置,可以用于数据的故障精确的恢复,并且采取tcp协议发送数据。
需要说明的是,scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是nfs,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。scribe的架构比较简单,主要包括三部分,分别为scribeagent,scribe和存储系统。
3)从开源组件中存储的副本中恢复多个待处理日志;例如,kafka线上副本数为3,日志持久化保存3天。如果sparkstructurestreaming失败,可以直接从kafka恢复数据。
4)读取多个待处理日志的元数据文件metadata和弥补函数offset恢复多个待处理日志;例如:sparkcheckpoint的机制保存kafka的offset等状态信息,当任务失败的时候spark任务启动会读取checkpoint文件夹下的metadata和offset文件,kafkaconsumer可以指定分区的offset读取数据,从而不会出现重复和遗漏。
5)从存储的多个副本文件中获取多个待处理日志,其中,多个副本文件存储在以下之一:本地节点,本地机架上的节点,不同机架上的节点。例如:hdfs的block机制:文件的副本数为3,hdfs的副本放置策略是:将第一个副本放在本地节点,将第二个副本放到本地机架上的另外一个节点,而将第三个副本放到不同机架上的节点。这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的几率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽。
(6)insertoverwrite:hive的数据提取采用insertoverwrite的覆盖操作,相对于insertinto可以实现幂等性,可以重复操作。
在一个可选的实施例中,为了增加日志处理的效率,可以对kafka进行横向扩展,具体包括:
(1)增大kafkabrokes数目和topics的partitions,根据kakfa默认的dafaultpartionsabs(key.hashcode)%(numpartitions),可以让topic的数据分布到更多的broke及机器上,增大上下游的数据处理能力。
(2)增大kafka的partitions之后,spark的就可以根据kafka的consumergroups机制设置相同的rdd的partitions增大数据的消息能力
综上所述,通过日志的实时收集,高性能的kafka信息中间件,sparkonyarn的优异的分布式特性:高容错,易扩展,extractlyonce,解决了日志在分布式的系统中扩容,容错有所欠缺,不能方便的进行大数据日志的etl清洗的问题。
在一个可选的实施例中,为了增加spark对日志处理的效率,可以对spark应用进行优化:具体如下:
对spark长时间程序运行参数的优化:spark-submit--masteryarn--deploy-modecluster\
--confspark.yarn.maxappattempts=4\
--confspark.yarn.am.attemptfailuresvalidityinterval=1h\
--confspark.yarn.max.executor.failures={8*num_executors}\
--confspark.yarn.executor.failuresvalidityinterval=1h\
--confspark.task.maxfailures=8\
以cluster模型运行程序,spark驱动程序中的任何错误都会阻止我们长期运行的工作。幸运的是,可以配置spark.yarn.maxappattempts=4重新运行应用程序的最大尝试次数。如果应用程序运行数天或数周,而不重新启动或重新部署在高度使用的群集上,则可能在几个小时内耗尽4次尝试。为了避免这种情况,尝试计数器应该在每个小时都重置(spark.yarn.am.attemptfailuresvalidityinterval=1h),另一个重要的设置是在应用程序发生故障之前executor失败的最大数量。默认情况下是max(2*numexecutors,3),非常适合批处理作业,但不适用于长时间运行的作业。该属性具有相应的有效期间,对于长时间运行的作业,您也可以考虑在放弃作业之前提高任务失败的最大数量(spark.task.maxfailures=8)。通过这些优化配置项,spark应用在负责的分布式环境中可以保持长期可靠的运行。
在一个可选的实施例中,在spark中,按照二级分区存储格式建立第一表格,其中,第一表格用于存储多个第二目标日志的概括信息;在第一表格中建立第一子表格,其中,第一子表格用于存储查询多个第二目标日志的查询信息;定时为第一子表格添加分区,其中,分区用于存储信添加的日志的查询信息。
例如:按照前面的etl的二级分区存储格式,建立一个总表用于获取日志的概括信息,然后对logtype目录建立各个子表用于任务的查询和使用。通过调度系统定时为表添加分区。在此基础上面,我们编写python脚本识别新增的日志和日志格式,建立json格式到hiveschema的自动映射,自动创建建表语句,在hive仓库中建立表。这样自动化,减少人工维护和新数据的快速上线。
在一个可选的实施例中,可以对日志的小文件进行压缩和合并,将多个第二目标日志中的各个第二目标日志进行分割,得到多个分解日志;解析多个分解日志;将预设时间段内解析之后的多个分解日志进行合并,得到合并日志;压缩合并日志。
例如:为了追求近实时的效果,sparkstreaming会把每天的日志分割成多个小分解,这对namenode的内存使用和datanode的磁盘是不友好的。我们采用调度系统合并和压缩前一周的小文件,进行优化。具体的是通过设置mapreduce的map和reduce的处理的数据量,并发个数,设置动态分区,设置中间结果和输出结果的snappy压缩。然后巧妙的使用insertoverwrite的语句在合并和压缩过程中不会影响查询。
在一个可选的实施例中,对日志的存储进行监控:对多个第二目标日志的存储进行监控;在存储出现故障的情况下,发出报警信息。例如:重写spark的eventlistener监控,通过statsd发送metrics,存储于graphite,然后通过cabot配置报警规则,一旦触发,通过alarm服务报警。并且通过yarn提供的restful接口实时轮询作业状态,自动拉起服务,大幅度提供的作业的可靠性。
综上所述,通过sparkonyarn的技术实现存储的容错,扩容,监控等分布式健壮的系统方案,有效的提供产品的稳定性、数据分析的实时性、日志的大规模可靠存储。同时考虑到冷热数据的合并和压缩,在不影响数据分析的性能上,合理的减少hadoop的负载。
本发明实施例还提供了一种日志处理装置,图5是根据本发明实施例提供的日志处理装置的结构示意图(二),如图5所示,该装置包括:
第三确定模块52,用于利用预设日志格式对获取的多个日志进行格式转换,得到多个待处理日志;
存储模块54,用于将多个待处理日志分别存储至与各个待处理日志对应的主题文件夹中;
发送模块56,用于将主题文件夹中的多个待处理日志发送至分布式处理平台中。
通过上述步骤,利用开源组件将收集的日志进行格式转换,得到多个待处理日志,将待处理日志发送至分布式处理平台;分布式处理平台对多个待处理日志进行数据清洗,得到多个第一目标日志;按照预设时间间隔对多个第一目标日志进行分区处理,得到多个第二目标日志。可以实现实时处理日志,提高了日志处理的效率,进而解决了相关技术中日志的处理效率低,不能满足对日志数据的需要的技术问题。
需要说明的是,上述中的执行主体可以是开源组件kafka,但不限于此。
需要说明的是,上述中的开源组件kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,kafka可以通过kafkaconnect连接到外部系统(用于数据输入/输出),并提供了kafkastreams,一个java流式处理库(计算机)。kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
需要说明的是,多个待处理日志的格式是kafka规范的,便于结构化的解析,、预设日志格式可以为:[logtime][operation],json;例如:[2013-04-101:00:09][click],{"time":12344343,"server":"1001"}。
在本实施例中,kafka中的应用程序可以通过logging模块,或者通过nginxaccesslog收集客户端的日志存储在本地,然后使用rsyslog,filebeat,scribeagent等工具收集日志,producer到kafka的topic中。
需要说明的是,apachespark是一个开源集群运算框架,最初是由加州大学柏克莱分校amplab所开发。相对于hadoop的mapreduce会在运行完工作后将中介数据存放到磁盘中,spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
需要说明的是,kafka存储的消息来自任意多被称为“生产者”(producer)的进程。数据从而可以被分配到不同的“分区”(partition)、不同的“topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(consumer)的进程可以从分区查询消息。kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
kafka高效地处理实时流式数据,可以实现与storm、hbase和spark的集成。作为群集部署到多台服务器上,kafka处理它所有的发布和订阅消息系统使用了四个api,即生产者api、消费者api、streamapi和connectorapi。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如jms、amqp等。
kafka架构的主要术语包括topic、record和broker。topic由record组成,record持有不同的信息,而broker则负责复制消息。kafka有四个主要api。
生产者api:支持应用程序发布record流。
消费者api:支持应用程序订阅topic和处理record流。
streamapi:将输入流转换为输出流,并产生结果。
connectorapi:执行可重用的生产者和消费者api,可将topic链接到现有应用程序。
topic用来对消息进行分类,每个进入到kafka的信息都会被放到一个topic下。
broker用来实现数据存储的主机服务器。
partition每个topic中的消息会被分为若干个partition,以提高消息的处理效率。
本发明实施例还提供了一种日志处理系统,图6是根据本发明实施例提供的日志处理系统的结构示意图,如图6所示,该装置包括:
分布式处理平台spark,其中,spark被设置为运行时执行权利要求8任一项中的方法;
开源组件kafka,与分布式处理平台连接,其中,kafka被设置为运行时执行权利要求9的方法。
如图6所示,本系统还包括:服务器server,kafka从服务器收集客户端的日志。将日志传输至spark进行日志的处理,将处理之后的日志传输至hadoop进行进一步的存储。
本发明的实施例还提供了一种存储介质,该存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
可选地,在本实施例中,上述存储介质可以被设置为存储用于执行以上各步骤的计算机程序。
可选地,在本实施例中,上述存储介质可以包括但不限于:u盘、只读存储器(read-onlymemory,简称为rom)、随机存取存储器(randomaccessmemory,简称为ram)、移动硬盘、磁碟或者光盘等各种可以存储计算机程序的介质。
本发明的实施例还提供了一种电子装置,包括存储器和处理器,该存储器中存储有计算机程序,该处理器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。
可选地,上述电子装置还可以包括传输设备以及输入输出设备,其中,该传输设备和上述处理器连接,该输入输出设备和上述处理器连接。
可选地,在本实施例中,上述处理器可以被设置为通过计算机程序执行以上各步骤。
可选地,本实施例中的具体示例可以参考上述实施例及可选实施方式中所描述的示例,本实施例在此不再赘述。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!