一种用于知识产权多维数据的关系模型建立方法及其系统与流程
本发明涉及数据挖掘的技术领域,尤其是涉及一种用于知识产权多维数据的关系模型建立方法及其系统。
背景技术:
在数据仓库领域中,数据一般以多维度的形式进行建模。
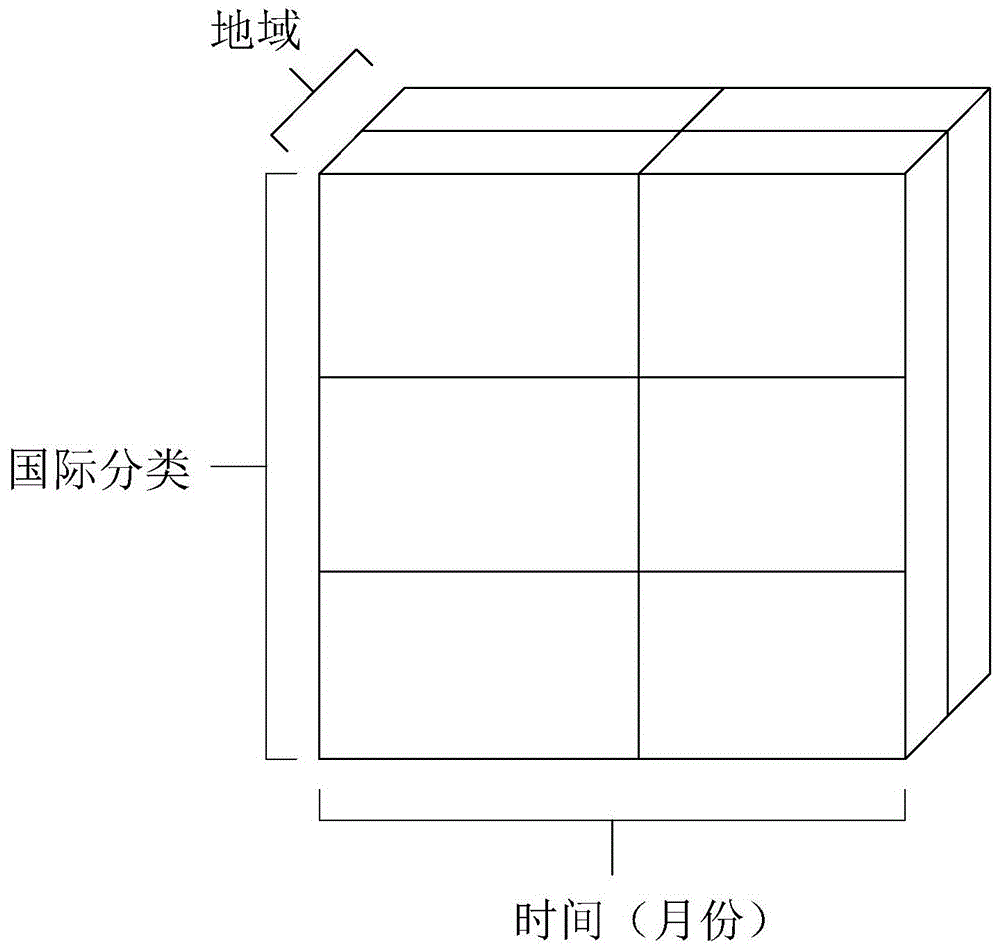
参照图1所示,以知识产权的商标销售数据为例,既想统计哪一个国际分类(类别维度)的注册数最高,又想统计哪一个月份(年份)的注册数最高。通常,在建模的过程中,会确认一个主题,主题即需要统计的内容。如确认商标销售数量作为模型主题;在确立的主题之后,还会建立确立数据的度量,即统计维度。如确认国际分类,月份,地域三个度量维度。通常,会用数据立方体表达这种复杂的关系。
在数据仓库中,实际上是n维立方体,这里为了显示方便,只显示了三维立方体。立方体的每个坐标轴代表一个统计维度。常用的专业数据仓库软件都能很好的表示这种立方体结构。
关系数据库是在企业内部一种广泛使用的技术,具有很高的通用性,利用关系数据库构建数据仓库也成为了一种低成本通用的方式
传统的构建方式包括星型模型和星系模型。
参照图2所示,在星型模式中,主要包含:
1)一个中心表,主要用来存储某个主题下所有数据维度的键;
2)多个维表,主要用来存储单个维度的具体内容;
在需要统计某个维度数据时,先从维表中找到提取具体的键集合,再去中心表提取具体统计数据。
参照图3所示,星系模式是多个型星型模式的组合,主要是用在存在多个主题时,不同主题间可以共用维表。如除了商标注册数主题,还可以新建个统计主题为商标销售额,其统计维度与商标注册数也一样为三种。
上述中的现有技术方案存在以下缺陷:专业化的数据仓库软件一般复杂度比较高,同时对硬件的要求比较高(一般是要求小型机),也需要专业化的人员去维护;同时,采用星型模型和星系模型时,中心表会变得特别大,导致查询效率不高,访问效率低下,还有改进的空间。
技术实现要素:
本发明的第一目的是提供一种用于知识产权多维数据的关系模型建立方法,通过新的中心表构建方式,拟构建多张同主题的中心表协同工作,减少单个中心表的数据量,提高中心表的访问效率。
本发明的上述发明目的是通过以下技术方案得以实现的:
一种用于知识产权多维数据的关系模型建立方法,包括如下步骤:
p101、确立主题与维度;
p102、构建动态哈希环;
p103、调节哈希环;
p104、数据定位;
p105、完成数据抽取并提取数据。
通过采用上述技术方案,通过维度的确立与主题的确立,从而对查询的主题进行明确,动态哈希环属于一致哈希环的一种,通过动态哈希环从而对数据形成一个可以循环的密闭圆环,再对哈希环进行调节,后期通过数据的定位以及抽取从而提取出数据,拟构建多张同主题的中心表协同工作,减少单个中心表的数据量,提高中心表的访问效率。
本发明进一步设置为:在步骤p101中包括以下步骤:
p1011、确定需要统计的中心主题;
p1012、确定数据维度,根据用户需求,从a个不同方向分别确定数据,则包含a个数据维度,分别记为d1、d2、d3……da,每个维度里面又包含具体的维度数据。
通过采用上述技术方案,通过对需要统计的中心主题进行确认,从而提高了整体的统计方向,而数据维度的确认对需要添加的附加条件进行匹配,同时将数据维度进行分割,以供用户进行选择。
本发明进一步设置为:在步骤p102中包括以下步骤:
p1021、首先选取一个哈希空间大小,空间大小为g,选取结点数量,记为n;
p1022、定义所有中心表的数量为步骤p1021中的结点数量n,设置一个向量v的长度为n,每个分量对应空间g内的一个任意自然数;
p1023、对所有的中心表用向量v的分量值编号,把单个中心表拆分成了n个;
p1024、把维表中的数据按列拼接成一个字符串,然后利用数字哈希函数,生成一个唯一的数字串,将这个得到的数字记为num,输入到以下公式:
o=num*mod(g);
其中mod代表取模运算,o为输出值,则把该记录映射到了空间g内;
p1025、定义在半区间内的数值存入左边的中心表中,且半区间为左闭右开区间,对各个维表d1、d2、d3……da内的数据重复同样的操作,即可以把各个数据分发到不同的中心表中。
通过采用上述技术方案,通过对哈希空间的选取,配合结点数量的配合,从而对哈希环进行暂时的分割,通过对中心表的分割,使每个中心表中的数据量减少,从而提高查询时的效率。
本发明进一步设置为:在步骤p103中包括以下调整步骤:
p1031、添加新的中心表,对原中心表任意在空间g内取一个值,将该值按顺序插入到原向量v中,则新生成了向量v’,把原区间内的数据移动到结点内,即把前向的中心表分裂为两个新的中心表;
当原中心表的存储空间大于最高存储空间时,运行步骤p1031。
通过采用上述技术方案,对中心表的空间进行判断,从而减少中心表因为数据过多而造成的运行效率的问题,通过自动增加中心表的方式,从而提高了运行效率。
本发明进一步设置为:在步骤p103中还包括以下调整步骤:
p1032、移除原中心表,将相邻的原中心表内的内容进行合并,然后移除原两个相邻的中心表并生成新的中心表;
当相邻的原中心表的存储空间均小于最存储空间时,运行步骤p1032。
通过采用上述技术方案,通过移除中心表的方式,从而节约的运行的空间,通过对计算量少的空间统计,从而提高了整体的资源的利用率,实用性强。
本发明进一步设置为:在步骤p104中包括以下步骤:
p1041、寻找数据位于哪个中心表时,重复步骤p102的计算方法算出该条数据位于空间g的数字串,记为n;
p1042、找到相应的数字区间,满足以下不等式:
对应区域的左边结点i≤n<对应区域的右边结点j,(i,j∈g),区间的左边结点i即为数据存放的结点。
通过采用上述技术方案,通过对中心表中数据的查找,从而寻找到对应的数据链,通过与建立时相同的方式,以提高了整体运行的稳定性,减少系统出现问题。
本发明进一步设置为:在步骤p105中包括以下步骤:
p1051、首先在维表中找到对应的数据记录集合c;
p1052、然后对数据记录集合c内这些记录运行步骤p104的定位方法,找到对应的数据分别位于哪些中心表中;
p1053、找到具体的中心表后,根据需要提取的数据维度去匹配中心表中的具体记录,则得到该记录的数据;
p1054、把所有的该记录的数据累加后就得到了需要提取的数据维度。
通过采用上述技术方案,通过对维表中对应数据的获取,从而对数据进行定位,从而获取对应记录的数据,通过对数据维度的提取,从而将数据匹配出,实用性强。
本发明的第二目的是提供一种用于知识产权多维数据的关系模型建立系统,通过新的中心表构建方式,拟构建多张同主题的中心表协同工作,减少单个中心表的数据量,提高中心表的访问效率。
本发明的上述发明目的是通过以下技术方案得以实现的:
一种用于知识产权多维数据的关系模型建立系统,包括:
主控模块,用户数据存储以及数据处理;
维度确立模块,与主控模块连接且用于确立数据的主题与统计的维度;
动态哈希环构建模块,与主控模块连接且用于拆分多个中心表并控制多个中心表同时工作;
哈希环调节模块,与主控模块连接且用于调节位于哈希环中的中心表的数量;
数据定位模块,与主控模块连接且用于寻找数据属于的中心表并输出数字串;
数据抽取模块,与主控模块连接且用于对需要获取的数据进行提取;
显示模块,与主控模块连接且用于接收提取的数据并进行显示。
通过采用上述技术方案,通过维护建立模块的设置,对需要统计的中心主题进行确认,从而提高了整体的统计方向,动态哈希环构建模块与哈希环调节模块的使用,从而对数据形成一个可以循环的密闭圆环,再对哈希环进行调节,数据定位模块与数据抽取模块的设置,最后通过显示模块进行显示,对数据的定位以及抽取从而提取出数据,拟构建多张同主题的中心表协同工作,减少单个中心表的数据量,提高中心表的访问效率。
本发明进一步设置为:所述动态哈希环构建模块包括:
结点数量单元,选取一个哈希空间大小,空间大小为g,选取结点数量,记为n;
分割单元,定义所有中心表的数量为结点数量单元中的结点数量n,设置一个向量v的长度为n,每个分量对应空间g内的一个任意自然数;
拆分单元,对所有的中心表用向量v的分量值编号,把单个中心表拆分成了n个;
余数单元,把维表中的数据按列拼接成一个字符串,然后利用数字哈希函数,生成一个唯一的数字串,将这个得到的数字记为num,输入到o=num*mod(g)公式中,其中mod代表取模运算,o为输出值,则把该记录映射到了空间g内;
区间确认单元,定义在半区间内的数值存入左边的中心表中,且半区间为左闭右开区间,对各个维表d1、d2、d3……da内的数据重复同样的操作,即可以把各个数据分发到不同的中心表中。
通过采用上述技术方案,分割单元与拆分单元的设置,将数据进行分离,配合余数单元的设置,与区间确认单元的配合,从而将对应的数据进行获取,实用性强。
本发明进一步设置为:所述哈希环调节模块包括:
中心表空间检测单元,用于检测当前中心表的数据大小并输出空间检测信号;
增加单元,用于增加中心表个数;
移除单元,用于减少中心表个数;
所述主控模块中预设有最高空间基准信号与最低空间基准信号,且最高空间基准信号大于最低空间基准信号;
当空间检测信号大于最高空间检测信号时,所述增加单元将当前中心表分裂为两个中心表以增加中心表个数;反之,不增加;
当相邻两个空间检测信号均小于最低空间检测信号时,所述移除单元将当前相邻的两个中心表合并为一个中心表以减少中心表个数;反之,不减少。
通过采用上述技术方案,通过增阿基单元与移除单元的设置,将中心表进行拆分以及组合,从而对空间的整理,以提高整体的运行效率,同时节约整体空间。
综上所述,本发明的有益技术效果为:通过新的中心表构建方式,拟构建多张同主题的中心表协同工作,减少单个中心表的数据量,提高中心表的访问效率。
附图说明
图1是背景技术中数据立体体的示意图。
图2是背景技术中星型模式图。
图3是背景技术中星系模式图。
图4是用于知识产权多维数据的关系模型建立方法的示意图。
图5是数据内容示意图。
图6是用于知识产权多维数据的关系模型建立系统的系统示意图。
图中,1、主控模块;2、维度确立模块;3、动态哈希环构建模块;4、哈希环调节模块;5、数据定位模块;6、数据抽取模块;7、显示模块;8、结点数量单元;9、分割单元;10、拆分单元;11、余数单元;12、区间确认单元;13、中心表空间检测单元;14、增加单元;15、移除单元。
具体实施方式
以下结合附图对本发明作进一步详细说明。
参照图4,为本发明公开的一种用于知识产权多维数据的关系模型建立方法,包括如下步骤:
p101、确立主题与维度;
p102、构建动态哈希环;
p103、调节哈希环;
p104、数据定位;
p105、完成数据抽取并提取数据。
参照图5所示,在进行步骤p101时,包括以下步骤:
p1011、确定需要统计的中心主题;
p1012、确定数据维度,根据用户需求,从a个不同方向分别确定数据,则包含a个数据维度,分别记为d1、d2、d3……da,每个维度里面又包含具体的维度数据。
在确定中心主题时,假设主题为商标销售的数量,则当确定数据维度时,根据业务场景,可以从时间、国际分类、地域分别统计商标销售的数据,此时包含了3个数据维度,分为为时间d1、国际分类d2、地域d3。在每个维度里面又包含具体的数据维度,例如在d1中包含了2012-02-13、2013-03-15等。
而在构建动态哈希环时,哈希环是个圆环,数据在哈希环上进行重复的循环,动态哈希环是一种数据定位技术,用来拆分多个中心表,让他们协同工作。
在步骤p102中包括以下步骤,以下步骤是构建动态哈希环的步骤:
p1021、首先选取一个哈希空间大小,空间大小为g,选取结点数量,记为n。
本实施例中,空间大小选取为232-1。
p1022、定义所有中心表的数量为步骤p1021中的结点数量n,设置一个向量v的长度为n,每个分量对应空间g内的一个任意自然数。
如当n为5时,向量v的可取值为40,1010,29392,30000,94039220,且向量v的取值为随机抽取的,且按照从大到小或者从小到大进行排列,且必须为自然数,因此均为整数并形成一个环形的数据。
p1023、对所有的中心表用向量v的分量值编号,把单个中心表拆分成了n个。
本实施例中,对所有中心表用向量v的分量值编号,记编号为tc-40,tc-1010,tc-29392,tc-30000,tc-94039220,至此,把单个中心表拆分成了5个。
p1024、把维表中的数据按列拼接成一个字符串,然后利用数字哈希函数,生成一个唯一的数字串,将这个得到的数字记为num,输入到以下公式:
o=num*mod(g);
其中mod代表取模运算,o为输出值,则把该记录映射到了空间g内。
本实施例中,数字哈希函数为一个函数y=f(x),可以把输入参数x映射成一个数字串y进行输出,并优选采用crc32函数,生成一个唯一的数字串,如39029311,此时公式为o=39029311*mod(232-1)。
p1025、定义在半区间内的数值存入左边的中心表中,且半区间为左闭右开区间,对各个维表d1、d2、d3……da内的数据重复同样的操作,即可以把各个数据分发到不同的中心表中。
本实施例中,从p1024中取出的余数放到2中的区间内,找到区间的启始表,定义在半区间(左闭右开)内的数值存入左边的中心表tc-i中。如第p1024步内的39029311位于区间[tc-30000,tc-94039220)内,所以数据存入tc-30000这张中心表内。这样,对各个维表d1,d2,d3内的数据重复同样的操作,即可以把各个数据分发到不同的中心表tc-i中。在数据定位时,进行同样的运算,也能够定位到某条维表数据在哪个中心表中。
在步骤p103中包括以下调整步骤,以下在中心表的数量需要调整时,主要受到性能等原因,因此需要做哈希环的调整,整个调整的规则如下:
p1031、添加新的中心表,对原中心表任意在空间g内取一个值,将该值按顺序插入到原向量v中,则新生成了向量v’,把原区间内的数据移动到结点内,即把前向的中心表分裂为两个新的中心表;
当原中心表的存储空间大于最高存储空间时,运行步骤p1031。
p1032、移除原中心表,将相邻的原中心表内的内容进行合并,然后移除原两个相邻的中心表并生成新的中心表;
当相邻的原中心表的存储空间均小于最存储空间时,运行步骤p1032。
步骤p1031为增加中心表的规则,而步骤p1032为移除中心表的规则。当原中心表的存储空间大于最高存储空间时,运行步骤p1031;当原中心表的存储空间大于最高存储空间时,运行步骤p1031。本实施例中最高存储空间为1000万条数据,最低存储空间为100万条数据。
在步骤p1031中,添加新的中心表tc-i。对tc-i任意在空间232-1内取一个值,如tc-210202。将该值按顺序插入到原向量v中,则新生成了向量v’(40,1010,29392,30000,210202,94039220)。此时,把区间[tc-21020,tc-94039220)内(之前位于tc-30000中心表内)的数据移动到tc-21020结点内,即把前向的中心表tc-(i-1)分裂。
在步骤p1032中,移除中心表tc-i。则执行在步骤p1031中的反向操作,先把tc-i内的内容合并到tc-(i-1)内,然后移除tc-i中心表。
在步骤p104中包括以下步骤:
p1041、寻找数据位于哪个中心表时,重复步骤p102的计算方法算出该条数据位于空间g的数字串,记为n;
p1042、找到相应的数字区间,满足以下不等式:
对应区域的左边结点i≤n<对应区域的右边结点j,(i,j∈g),区间的左边结点i即为数据存放的结点。
当根据步骤p102的计算方法算出该条数据位于空间232-1的数字串,记做n,则不等式为tc-i≤n<tc-j,(i,j∈232-1),区间的左边结点tc-i即为数据存放的结点。
在步骤p105中包括以下步骤:
p1051、首先在维表中找到对应的数据记录集合c;
p1052、然后对数据记录集合c内这些记录运行步骤p104的定位方法,找到对应的数据分别位于哪些中心表中;
p1053、找到具体的中心表后,根据需要提取的数据维度去匹配中心表中的具体记录,则得到该记录的数据;
p1054、把所有的该记录的数据累加后就得到了需要提取的数据维度。
例如:想要提取2018年的销售数量,则首先在维表中找到年份为2018年的数据记录集合c。然后对c内这些记录运行p104步骤的定位方法,找到对应的数据分别位于哪些中心表tc-i中。找到具体的tc-i表后,根据键time_key去匹配中心表中tc-i中的具体记录,则得到该记录的销售数量number-i。把所有的number-i累加后就得到了2018全年的销售数据。且number-t=number-1+number-2+…+number-n。
参照图6所示,基于同一发明构思,本发明实施例提供一种用于知识产权多维数据的关系模型建立系统,包括主控模块1,与主控模块1连接的维度确立模块2、动态哈希环构建模块3、哈希环调节模块4、数据定位模块5、数据抽取模块6、显示模块7。
本实施中,主控模块1为大型计算机,而显示模块7为显示屏。且主控模块1用于进行数据的存储以及进行数据的处理分析运算。显示模块7进行将提取的数据进行显示。
维度确立模块2用于确立数据的主题与统计的维度,动态哈希环构建模块3用于拆分多个中心表并控制多个中心表同时工作,哈希环调节模块4用于调节位于哈希环中的中心表的数量,数据定位模块5用于寻找数据属于的中心表并输出数字串,数据抽取模块6用于对需要获取的数据进行提取。
维度确认模块对中心主题进行确认,假设的主题为商标销售的数量,记为tc。根据业务场景,需要从时间,国际分类,地域分别统计商标销售的数据。则包含三个数据维度,分别记为时间d1,国际分类d2,地域d3。每个维度里面又包含具体的维度数据,如d1中包含2018-01-01,2018-01-02等。
动态哈希环构建模块3包括结点数量单元8、分割单元9、拆分单元10、余数单元11、区间确认单元12。
结点数量单元8用于选取一个哈希空间大小,空间大小为g,选取结点数量,记为n。本实施例中,空间大小选取为232-1。
分割单元9定义所有中心表的数量为结点数量单元8中的结点数量n,设置一个向量v的长度为n,每个分量对应空间g内的一个任意自然数。如当n为5时,向量v的可取值为40,1010,29392,30000,94039220,且向量v的取值为随机抽取的,且按照从大到小或者从小到大进行排列,且必须为自然数,因此均为整数并形成一个环形的数据。
拆分单元10对所有的中心表用向量v的分量值编号,把单个中心表拆分成了n个。本实施例中,对所有中心表用向量v的分量值编号,记编号为tc-40,tc-1010,tc-29392,tc-30000,tc-94039220,至此,把单个中心表拆分成了5个。
余数单元11把维表中的数据按列拼接成一个字符串,然后利用数字哈希函数,生成一个唯一的数字串,将这个得到的数字记为num,输入到o=num*mod(g)公式中,其中mod代表取模运算,o为输出值,则把该记录映射到了空间g内。本实施例中,数字哈希函数为一个函数y=f(x),可以把输入参数x映射成一个数字串y进行输出,并优选采用crc32函数,生成一个唯一的数字串,如39029311,此时公式为o=39029311*mod(232-1)。
区间确认单元12定义在半区间内的数值存入左边的中心表中,且半区间为左闭右开区间,对各个维表d1、d2、d3……da内的数据重复同样的操作,即可以把各个数据分发到不同的中心表中。本实施例中,从p1024中取出的余数放到2中的区间内,找到区间的启始表,定义在半区间(左闭右开)内的数值存入左边的中心表tc-i中。如第p1024步内的39029311位于区间[tc-30000,tc-94039220)内,所以数据存入tc-30000这张中心表内。这样,对各个维表d1,d2,d3内的数据重复同样的操作,即可以把各个数据分发到不同的中心表tc-i中。在数据定位时,进行同样的运算,也能够定位到某条维表数据在哪个中心表中。
哈希环调节模块4包括中心表空间检测单元13、增加单元14、移除单元15。中心表空间检测单元13用于检测当前中心表的数据大小并输出空间检测信号,增加单元14用于增加中心表个数,移除单元15用于减少中心表个数。
主控模块1中预设有最高空间基准信号与最低空间基准信号,且最高空间基准信号大于最低空间基准信号。
当空间检测信号大于最高空间检测信号时,增加单元14将当前中心表分裂为两个中心表以增加中心表个数;当空间检测信号不大于最高空间检测信号时,增加单元14不将当前中心表分裂为两个中心表。
当相邻两个空间检测信号均小于最低空间检测信号时,移除单元15将当前相邻的两个中心表合并为一个中心表以减少中心表个数;当相邻两个空间检测信号均不小于最低空间检测信号时,移除单元15不将当前相邻的两个中心表合并为一个中心表。当仅有一个小于最低空间检测信号时,不进行合并。
数据定位模块5用于查询数据位于哪个中心表,当需要找到数据位于哪个中心表时,则根据动态哈希环构建模块3的计算方法算出该条数据位于空间232-1的数字串,记为n。然后找到相应的数字区间,满足不等式:tc-i≤n<tc-j,(i,j∈232-1),且区间的左边结点tc-i即为数据存放的结点。
数据抽取模块6用于对收据进行提取,如想要提取2018年的销售数量,则首先在维表中找到年份为2018年的数据记录集合c。然后对c内这些记录运行数据定位模块5的定位方法,找到对应的数据分别位于哪些中心表tc-i中。找到具体的tc-i表后,根据键time_key去匹配中心表中tc-i中的具体记录,则得到该记录的销售数量number-i。把所有的number-i累加后就得到了2018全年的销售数据。
即number-t=number-1+number-2+…+number-n。
本发明内容与传统的关系建模相比,利用分布式数据的分发算法,把庞大的中心表拆分成多个中心子表配合工作,能大量的提高数据量的伸缩性。
本具体实施方式的实施例均为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!