一种基于对偶自编码器的组推荐方法与流程
本发明属于计算机技术推荐方法领域,涉及一种基于对偶自编码器的组推荐方法。
背景技术:
近年来,推荐系统逐渐成为人们在海量数据中发现有价值信息的重要工具.在目前的研究中,大部分的推荐算法是针对单独用户设计的,实际中还有很多应用是针对多人进行推荐,例如,针对多人的电视节目推荐或者旅游地点推荐.在这些情景下,根据适合单独用户的推荐算法无法给多人产生满意的推荐结果,因为一个用户满意的推荐结果对其他人来说很可能不是太好的选择.因此,如何选择推荐内容使群组内每个组员都满意或者接受是面向群组的推荐算法需要解决的主要难题.
根据组推荐过程中偏好融合的时机,偏好融合方法可以分为模型融合和推荐融合。模型融合方法根据群组成员的用户偏好模型融合生成群组偏好模型,然后基于群组偏好模型生成组推荐;推荐融合方法先利用传统推荐算法对每个群组成员生成推荐,然后将所有群组成员的推荐结果融合得到群组推荐结果。本发明提出的算法属于模型融合。
组推荐过程中不仅要考虑组内成员差异性对推荐结果的影响,还要考虑组间差异性和物品间差异性对推荐结果的影响。因此我们在研究过程中要同时考虑三者对推荐结果的影响,同时我们发现在现阶段的群组推荐系统中缺乏融合方面信息的群组推荐。因此我们提出一种对偶自编码器模型来融合群组对方面的偏好的信息的同时考虑组内成员差异性、组内成员差异性、物品间差异性对推荐结果影响。
技术实现要素:
为了解决现有技术存在的问题,本发明提出了一种新颖的基于深度学习的组推荐,该框架使用了对偶自编码器模型并同时融合了群组对方面的偏好信息,并提出了一种有效的计算方法来衡量用户在群组中的影响力。该对偶自编码器通过同时输入某个群组方面偏好向量、某个物品方面质量向量、群组关系向量和物品关系向量得到群组隐式的偏好表达式和物品隐式的质量表示式。将获取的两个表达式点集获取群组对物品的预测评分。
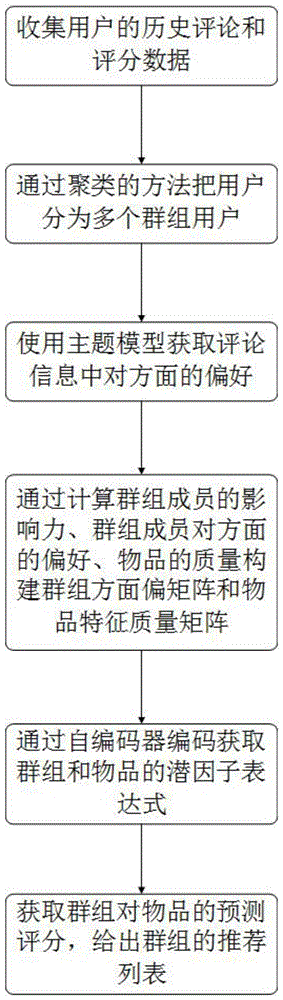
为实现本发明的目的,本发明再将用户融合成群组的同时将方面信息融合进去,本发明的方面信息是通过文本主题模型lda获取的,并且本发明考虑了群组推荐过程中群组间差异性和物品间差异性对群组推荐的影响。本发明将获取的各个矩阵的每一行送入到自编码器中获取潜特征表达后获得与测评分,再根据top-k为群组推荐k个项目。本发明的群组推荐包括以下步骤
a.从互联网中采集需要用到的数据集,并对数据集进行预处理,生成用户行为数据存放到用户行为信息数据库。
b.本发明中的数据集是未分组的数据集,此时我们需要通过未分组的用户进行分组,在分组过程中我们有以下实施方式:
b1.考虑到群组规模会对群组推荐产生影响,我们可以对未分组的用户分取不同规模大小的群组然后根据实验对比获取最佳规模的群组。
b2.考虑到组内相似性对群组推荐的影响,我们可以通过分取高相似度的群组、低相似度的群组和随机群组三个分组模式对用户进行分组人后分、根据实验结果的对比获取最佳相似度的群组。
b3.本发明中我们可以预定义群组大小,然后根据k-mean聚类算法对未分组的用户进行聚类分组,然后将分组信息存储到数据库中。
c.方面信的息提取:使用文本主题模型lda从评论数据集中获取各个主题以及每个主题的主题词。每个主题代表一个方面。在本发明中一共有k个方面
d.组员影响力w在获取的过程中有以下实施方案:
d1.根据组员分组信息,通过计算一个小组中某组员对小组中其他成员的影响力获取该组员在小组中的整体影响力作为该组员在小中的权重。
d2.动态获取组员影响力:我们根据组员在不同时间段对其他组内成员的影响力来实时获取组员影响力,此时我们可以使用lstm来动态获取组员影响力。
d3.通过注意力机制来获取组员影响力:在该方法中我们可以通过使用注意力机制模型自动学习群组中的每个用户的影响权重
e.利用步骤d中获取的群组成员影响力w和利用步骤c中获取的群组成员对方面的偏好信息求得计算群组对各个方面的偏好,既:获取群组偏好矩阵r。
其中
f.同理根据物品在每个方面的评论次数和物品在群组中被重视的程度计算物品在每个方面的质量,既:获取物品偏好矩阵m。
其中
g.考虑到组间差异性对群组推荐产生的影响,本发明中根据组间共同评分个数来考虑组间差异性,既:获取组-组关系矩阵k。
其中
h.考虑到物品间差异性对可能会对群组推荐产生的影响,本发明中根据物品被用户间共同评分个数来考虑物品间差异性,既:获取物品-物品关系矩阵n。
其中
i.本发明将获取的群组方面偏好矩阵、物品方面质量矩阵、组-组关系矩阵和物品-物品关系矩阵中的每一行同时送入到对偶自编码器模型中获取群组方面偏好隐因子表达式、物品方面质量隐因子表达式、组-组关系隐因子表达式和物品-物品关系隐因子表达式。
j.获取群组偏好隐因子表达式的方案有以下几种:
j1.将群组方面偏好隐因子表达式和组-组关系隐因子表达式进行全连接获取群组偏好隐因子表达式
j2.将群组方面偏好隐因子表达式和组-组关系隐因子表达式进行点集获取群组偏好隐因子表达式
k.获取品质量隐因子表达式的方案有以下几种:
k1.将物品方面质量隐因子表达式和物品-物品关系隐因子表达式进行全连接获取物品质量隐因子表达式。
k2.将物品方面质量隐因子表达式和物品-物品关系隐因子表达式进行点集获取物品质量隐因子表达式。
l.将获取的群组偏好隐因子表达式和物品质量隐因子表达式的转置进行乘积就可以获得群组的物品的预测评分,既获取群组预测评分矩阵
m.通过获取的群组预测评分矩阵根据top-k算法为每个群组推荐k个项目。
n.在本发明中我们只优化模型函数为:
l=α·||r-r'||2+β·||k-k'||2+χ·||m-m'||2+δ·||n-n'||2+λ·π
π=||w1||2+||b1||2+||w′1||2+||b′1||2+||w2||2+||b2||2+||w′2||2+||b′2||2+||w3||2+||b3||2+||w'3||2+||b′3||2+||w4||2+||b4||2+||w'4||2+||b'4||2
o.本发明中所述评估推荐模型的好坏的评价指标为:hr@k、ndcg@k
o1.命中率hr@k:
q1,q2…qk是群组的推荐列表
lu表示用户u对推荐列表中项目实际喜欢个数
o2.ndcg@k
dcgu代表用户u的dcg
计算出群组中各个用户的ndcg值,然后取它们的平均值作为组推荐列表的ndcg。ndcg是介于0~1之间的数,ndcg的数值越大,表明推荐列表中项目的排序越准确,推荐准确度越高。
附图说明
图1为本发明的模型示意图。
具体实施方式
下面结合附图,详细描述本发明的技术方案:
a.从互联网中采集需要用到的数据集,获取用户历史评论和评分数据集,生成群组:据我们所知,现有的数据集要么只有个体用户的评论和评分信息,要么群组的成员信息和群组的频分信息,缺乏我们所需要的数据集。因此我们可以先获取只有个体用户的评论和评分信息的数据集,并对数据集进行预处理,生成用户行为数据存放到用户行为信息数据库。
b.本发明中我们预定义群组大小,然后根据k-mean聚类算法对未分组的用户进行聚类分组,然后将分组信息存储到数据库中。
c.方面信的息提取:通过使用现有的文本主题模型,如lda;获取评论数据集的各个主题以及每个主题的主题词。在本发明中我们定义了两种度量指标:群组方面偏好和物品方面质量,来分别衡量群组对物品特定方面的偏好和物品特定方面的评论感情。
d.组员影响力:根据组员分组信息,通过计算一个小组中某组员对小组中其他成员的影响力获取该组员在小组中的整体影响力作为该组员在小中的权重。
e.利用步骤d中获取的群组成员影响力w和利用步骤c中获取的群组成员对方面的偏好信息求得计算群组对各个方面的偏好,既:获取群组偏好矩阵r。
其中
f.同理根据物品在每个方面的评论次数和物品在群组中被重视的程度计算物品在每个方面的质量,既:获取物品偏好矩阵m。
其中
g.考虑到组间差异性对群组推荐产生的影响,本发明中根据组间共同评分个数来考虑组间差异性,既:获取组-组关系矩阵k。
其中
h.考虑到物品间差异性对可能会对群组推荐产生的影响,本发明中根据物品被用户间共同评分个数来考虑物品间差异性,既:获取物品-物品关系矩阵n。
其中
i.本发明将获取的群组方面偏好矩阵、物品方面质量矩阵、组-组关系矩阵和物品-物品关系矩阵中的每一行同时送入到对偶自编码器模型中获取群组方面偏好隐因子表达式、物品方面质量隐因子表达式、组-组关系隐因子表达式和物品-物品关系隐因子表达式。
j.将群组方面偏好隐因子表达式和组-组关系隐因子表达式进行点集获取群组偏好隐因子表达式
k.将物品方面质量隐因子表达式和物品-物品关系隐因子表达式进行点集获取物品质量隐因子表达式。
l.将获取的群组偏好隐因子表达式和物品质量隐因子表达式的转置进行乘积就可以获得群组的物品的预测评分,既获取群组预测评分矩阵
m.通过获取的群组预测评分矩阵根据top-k算法为每个群组推荐k个项目。
- 还没有人留言评论。精彩留言会获得点赞!