一种高压断路器机械缺陷集成学习诊断方法与流程
本发明涉及一种旋转压缩变换的集成学习方法,具体涉及一种优化特征变换空间的高压断路器机械缺陷集成学习诊断方法。
背景技术:
高压断路器是区域性电网中最重要的开关设备。电力系统实际运行过程中,随着高压断路器运行时间的增加,电器与绝缘部件会有所老化,机械部件也会出现不同程度磨损,这可能会导致断路器功能失效。某种功能失效或者某种功能出现不允许的性能偏差都被称为故障,故障是设备存在的一种或者多种现象。最常见的显性故障,是通过人体的一般性感知或者正常的操作便能发现的故障,如储能不到位、拒分、拒合等一些隐性故障,是必须通过仪表或者其他设备的检测才能发现的故障,例如,分闸线圈匝间短路、分合闸速度超标以及主触头电阻变大等。对于高压断路器来讲,状态监测技术还不完善,是目前研究的热点之一。据国际大电网会议13.06工作组(参见参考文献《高压断路器机械特性监测及故障模式识别方法研究》邓帮飞,重庆大学硕士学位论文;参考文献[2]:《高压断路器事故调查》刘亚芳,国际电力1997年第3期)对包括22个国家的102个电力部门所作的第一次国际调查结果表明,在1974-1977年间,63kv及以上电压等级断路器故障中,机械性故障占70.3%。可见,对于高压断路器实施动机械特性的监测,及时了解其运行状况,掌握其运行特性变化及变化趋势,对提高其运行可靠性极为重要。
目前,能够有效反应高压断路器机械特性检测和状态诊断方法主要基于高压断路器的动触头行程信号、分合闸操作机构线圈电流信号以及机械振动信号三类。其中触头行程和线圈电流检测技术发展较早,较为成熟,但在现在应用测试过程中存在诸多不便,且部分机械缺陷难以辨识。高压断路器机械振动检测,相比于触头行程和线圈电流检测具有安装方便、检测机械缺陷种类多等优点,在近20年的发展过程中,振动信号采集系统的相关工作已比较成熟,但对振动信号特征提取与故障分类方法仍处于试验研究阶段,存在诊断准确率低、通用性差等问题,这也导致目前相关研究尚无成熟产品和应用方案,并未见在工程中成功应用的报道。因此,开展高压断路器机械状态评估与故障诊断技术的研究,研发高效、高精度的断路器机械状态检测方法具有重大而深远的意义。
技术实现要素:
本发明的目的在于:提供一种优化特征变换空间的高压断路器机械缺陷集成学习诊断方法,该方法首先基于多类高压断路器机械缺陷的振动信号数据样本,并对其构建传统的小波包能量熵,组成振动信号原始特征空间;然后,对于振动信号原始特征空间,以有放回随机抽样方式形成多个与振动信号原始特征空间等容量的特征子集(袋内数据)以及相应的与振动信号原始特征空间的差集(袋外数据);接着,对每个特征子集内的特征数据设计自编码器旋转压缩原始特征空间,并在变换后特征空间下训练决策树初步诊断模型,基于袋外数据评估诊断模型诊断结果,利用粒子群算法迭代优化旋转压缩变换及诊断模型参数,形成最优旋转压缩决策子树模型;最后,以投票机制融合全部最优旋转压缩决策子树模型的诊断结果,完成高压断路器机械缺陷最终诊断。
本发明采用的技术方案为:一种优化特征变换空间的高压断路器机械缺陷集成学习诊断方法,所述方法包括步骤如下:
步骤1:获取机械振动信号数据样本及原始特征空间构建;
采集高压断路器在不同机械缺陷下合闸过程的机械振动信号,基于高压断路器合闸过程表现为冲击性自由衰减信号,即信号为突变、频率随时间变化和非线性特点,因此利用小波包时频域分析,计算小波包能量熵,度量机械振动信号特征,组成机械振动信号原始特征空间。
步骤2:基于有放回随机抽样方式组成多个特征子集;
在原始特征空间下,有放回随机抽样数据样本,组成和原始特征空间中数据样本数一致的多个特征子集,特征子集中可能存在重复的特征数据,并定义每个特征子集为各自袋内数据,各特征子集与原始特征空间的差集为各自袋外数据,并且特征子集个数为最终形成最优旋转压缩决策子树的数量,即集成学习模型的容量。
步骤3:以每个特征子集和差集训练成最优旋转压缩决策子树模型;
步骤3.1基于每个特征子集建立自编码器,将原始特征空间旋转、压缩、非线性映射为新特征空间描述;
步骤3.1.1初始化自编码器的结构和相关参数;
步骤3.1.2将特征子集输入到自编码器中训练,使得自编码器的输出等于(近似等于)自编码器的输入,提取自编码器中间隐含层(自编码器一般只有1个输入层、1个隐含层和一个输出层)作为新特征集下的袋内数据,即完成原始特征空间的旋转、压缩以及非线性映射;所有新特征集构成新特征空间。
步骤3.1.3记录自编码器从输入到中间隐含层的映射关系,即自编码器旋转、压缩参数;
步骤3.2在新特征空间下以袋内数据构建决策树分类诊断模型;
步骤3.2.1将步骤3.1.2中得到的新特征空间下的袋内数据,放入决策树的树根节点;
步骤3.2.2以袋内数据中某个特征的某个数值点对袋内数据进行分割,基于基尼指数评估该特征在这一数值点的分割效果,寻找用于分割新特征空间下的袋内数据类别的最佳特征变量及数值点,将袋内数据分成两个子部分;
步骤3.2.3判断分割后的两个子部分的纯度(基尼指数),若某个子部分的基尼指数小于要求值,则此子部分不再分割,并定义为叶节点,这个子部分样本最多的类别就是这个叶节点的输出类别;若某个子部分的基尼指数大于要求值则以步骤3.2.2的方式再次进行分割,直至满足要求,如此形成了基于新特征集下袋内数据的决策树分类诊断模型;
步骤3.3以袋外数据对生成的自编码器旋转压缩决策子树分类诊断模型进行评估,采用粒子群算法优化自编码器的超参和决策树分类诊断模型的参数,获得最优旋转压缩变换决策子树;所述超参包括自编码器的旋转和压缩参数。
步骤4:基于多个最优旋转压缩变换决策子树诊断模型,以投票机制构成最终的高压断路器机械缺陷诊断模型;
基于不同的抽样特征子集不断重复步骤3中训练-评估-优化过程,获得多个最优旋转压缩变换决策子树模型,并统计多个最优旋转压缩变换决策子树模型的分类结果,以少数服从多数的投票机制集成融合,完成高压断路器机械缺陷的最终诊断。
与现有技术相比,本发明的优点和有益效果是:
1、本发明技术方案中,采用了自编码器对原始特征空间进行了旋转压缩变换,增强相同故障的聚合性和不同故障之间的差异性,相比于其他的基于自编码器变换方法,本发明采用了粒子群算法对自编码器超参进行了迭代优化,避免人为调整参数的局限性,有利于高压断路器机械缺陷诊断精度的提高;
2、本发明技术方案中,采用样本袋装、决策树集成的诊断方法,有效降低了振动分散性对诊断结果的影响,相比于其他的基于集成学习方法,本发明利用自编码器对原始特征空间进行了优化变换,使得集成学习中每个子分类器(决策子树)均表现出增强型决策,强化了各决策子树的表征能力,同时提高了集群诊断的辨识精度;
3、本发明技术方案中,设计决策树分类诊断模型中旋转压缩映射变换的评估方法,为粒子群优化过程提供了评价标准,相比于其他的粒子群优化和单一模型诊断方法,本发明灵活运用了袋外数据不参与决策树分类诊断模型训练的优势,提出袋内训练-袋外评估的迭代优化方案,有效地度量了自编码器对原始特征空间的旋转、压缩映射变换程度的优劣,形成了最优旋转压缩变换决策子树,为进一步提高机器学习诊断能力提供发展方向。
附图说明
下面结合附图对本发明进一步说明。
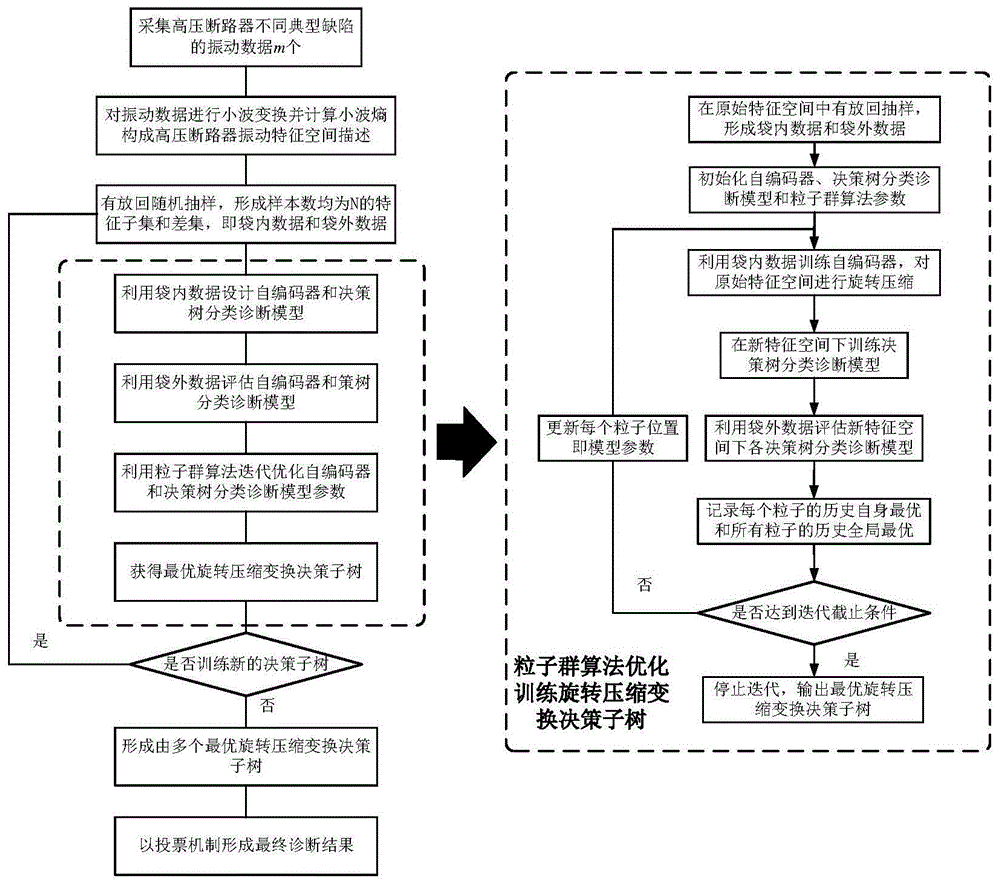
图1是本发明提供的高压断路器机械缺陷集成学习诊断方法流程图;
图2是旋转压缩变换最优特征空间的集成学习方法结构图;
图3是最优旋转压缩优化特征空间的决策子树结构图;
图4是最优旋转压缩优化特征空间的决策子树生成流程图;
图5是旋转压缩映射的自编码器结构图;
图6是决策树结构图;
图7是粒子群算法流程图。
具体实施方式
下面将结合实施例和附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明提供了一种优化特征变换空间的高压断路器机械缺陷集成学习诊断方法,图1展示出了本实施例中的所述诊断方法的流程图,图2为本实施例中所述方法的结构框图;所述诊断方法具体包括下述步骤:
步骤1:获取振动信号数据样本及原始特征空间构建;
步骤1.1使用振动信息测量设备采集高压断路器在不同机械缺陷下合闸过程的机械振动信号,得到数据样本数量为m个;
步骤1.2基于高压断路器合闸过程表现为冲击性自由衰减信号,即振动信号为突变、频率随时间变化和非线性特点,因此利用小波包时频域分析,计算小波包能量熵,度量机械振动信号特征,具体步骤如下:
步骤1.2.1对高压断路器机械振动信号xq进行小波包时-频变换,其中q=1,2,…,m表示测量数据样本(简称测量样本)编号,获得时-频能量矩阵aq,t×f,并在时间轴t、频率轴f方向分别等分n1和n2份,每个子时间段元素个数为t/n1,每个子频率段元素个数为f/n2,计算每个时-频块的能量,如公式(1)所示。
其中,eq,i,j表示第q个测量数据样本小波包时-频能量矩阵aq,t×f进行n1×n2分块后第(i,j)个时-频块的能量,
步骤1.2.2根据公式(1)得到第q个测量样本的小波包时-频块的能量eq,i,j,可以计算小波包能量熵,如公式(2)和(3)所示,由此,构成了高压断路器第q个测量样本的振动信号原始特征空间特征描述wpeq={wpeq,i,f,wpeq,t,j},i=1,2,...,n1;j=1,2,...,n2;q=1,2,...,m。
步骤2:基于有放回随机抽样方式组成多组训练子集;
将步骤1中得到的原始特征空间中特征描述wpeq={wpeq,i,f,wpeq,t,j}定义为cq={xq,1,xq,2,...,xq,w},其中,i=1,2,...,n1;j=1,2,...,n2;q=1,2,...,m,cq表示第q个测量样本的小波包能量熵的特征集,w表示第q个测量样本的特征个数,即特征空间维度,定义每个特征集cq的故障类型编号为lg,g=1,2,…,g,表示有g个机械故障的类别个数。
步骤2.1在原始特征空间下有放回随机抽样测量样本,组成和原始特征空间中样本数一致的多个特征子集
步骤2.2将各特征子集incnum与原始特征空间中测量样本作差集,定义其为各自的袋外数据excnum,num=1,2,…,n。
步骤3:以每个特征子集incnum(袋内数据)和差集excnum(袋外数据),训练评估出最优旋转压缩变换决策子树模型,模型结构如图3所示,生成流程如图4所示,具体步骤如下:
步骤3.1基于每个特征子集incnum建立自编码器,将原始特征空间旋转、压缩、非线性映射为新特征空间描述;
步骤3.1.1初始化自编码器的旋转压缩参数,即超参,如图5,如隐含层神经元(y1,y2,…,yp)个数p、激活函数fθ(·)类型、正则化系数λ等;θ的取值是1~p,p为自编码器中编码器的输出个数。
步骤3.1.2将袋内数据特征子集
y=fθ(wx+b)(4)
公式(4)表示自编码器的编码过程,即输入层到隐含层输出过程,公式(5)表示自编码器的解码过程,即隐含层输出到输出层输出过程,其中编码解码激活函数分别为fθ(α)=1/(1+e-α),
其中,
步骤3.1.3记录自编码器从输入层到中间隐含层的映射关系,即自编码器超参{w,b};
步骤3.2在新特征空间下以袋内数据构建决策树分类诊断模型,决策树分类诊断模型结构如图6所示,其中集合s表示新特征空间下的袋内数据,si,j,k表示第i-j-k次分割后的子集。
步骤3.2.1将步骤3.1.2中得到的新特征空间下的袋内数据集合s,放入决策树的树根节点;
步骤3.2.2以树根节点为例说明,袋内数据的样本个数是m,每个样本是由一个w维向量组成,可以理解为一个m×w的矩阵,矩阵行数表示样本个数,列数表示w个特征数,并且每一行(样本)对应一个机械缺陷的类别。选择某个一列(特征yi),至少有n-1种数值δi可以将样本分为2部分,即小于等于δi的一部分s1,大于δi的一部分s2,然后计算每个部分s1和s2中机械缺陷类别的出现概率,利用公式(7)计算出特征yi在δi这个数值点上的gini指数,最后根据公式(8)计算出两个部分s1和s2的加权gini指数gini(s,yi),表示出特征yi在δi这个数值点对袋内数据划分纯度的度量,其中|s|表示集合s中样本的数量。不断更换特征yi上的δi值(最多n-1次)计算,以gini(s,yi)最小判断出特征yi上的最优分割值。
再更换特征yi(w次),根据上述过程计算出每个特征下的最优分割值,并比较每个特征的最优分割值下的gini(s,yi),选择最小值对应的特征和特征分割点为最佳特征变量及数值,将袋内数据集s分成两个子部分s1和s2。公式(7)、(8)如下:。
其中x表示一个变量,其存在k类状态值,pk表示变量x属于第k类的概率值,公式(7)可以表示随机变量的纯度,当变量x仅存在一类状态值,则基尼指数为0,表示纯度最大;当变量x存在类别数k趋近于无穷大,且各类别出现概率一致,则基尼指数为1,表示纯度最小;利用公式(7)可以看出公式(8)表征了由特征变量yi的某个数值δi对新袋内数据特征集进行分割得到两个子部分s1和s2的纯度度量,递归寻找用于分割新特征集下的袋内数据类别的最佳特征变量及数值,将新特征集下的袋内数据集s分成两个子部分s1和s2;
步骤3.2.3判断分割后的两个子部分的纯度(基尼指数),若某个子部分的基尼指数小于要求值γ,则此子部分不再分割,并定义为叶节点,这个子部分样本最多的类别就是这个叶节点的输出类别;若某个子部分的基尼指数大于要求值γ,则以步骤3.2.2的方式继续进行分割,直至满足要求,形成了基于新特征集下袋内数据的决策树分类诊断模型;
步骤3.3以袋外数据对生成的自编码器和决策树分类诊断模型进行评估,采用粒子群算法优化自编码器的超参和决策树诊断模型的参数,流程如图7所示,获得最优旋转压缩变换决策子树,具体如下:
步骤3.3.1设置粒子群算法参数,如粒子数np、最大迭代次数intermax、惯性因子ω及学习因子c1和c2等,定义每个粒子由自编码器超参构成,如隐含层神经元个数p、正则化系数λ以及决策树停止分割的纯度要求值γ等参数,由向量pd=[p,λ,γ,...]表示,初始化所有粒子向量以及每个粒子对应的自编码器参数
步骤3.3.2基于步骤2抽样的特征子集incnum,根据步骤3.1训练所有粒子代表的自编码器,生成各粒子的旋转压缩特征,并利用步骤3.2生成各粒子旋转压缩特征下的决策树分类诊断模型;
步骤3.3.3将步骤2中特征子集incnum对应的袋外数据excnum,放入所有粒子的自编码器和决策树分类诊断模型,获得并记录各粒子的诊断结果;
步骤3.3.4对袋外数据excnum的诊断结果进行排序,记录并更新所有粒子的历史全局最优位置pgbest,以及每个粒子的历史自身最优位置pi,best,其中i表示粒子编号。判断当前粒子是否优于历史自身最优值或是历史全局最优值:若是,则更新每个粒子的自身最优值及历史全局最优值,并判断是否到达迭代截止条件;若不是,则不改变每个粒子的历史自身最优及历史全局最优值,并判断是否到达迭代截止条件。若没有到达迭代截止条件,则以公式(9)对每个粒子进行更新,并以更新后的所有粒子参数,重新返回步骤3.3.2重新进行自编码器训练和决策树分类诊断模型构建,直至达到迭代截止条件停止优化过程。
其中,vi(inter)表示第i个粒子在第inter次迭代时的更新速度,ω表示粒子的惯性常数,c1和c2分别为历史自身最优学习因子和历史全局最优学习因子,r1和r2分别是两个服从正态分布的随机数;
步骤3.3.5根据历史全局最优的粒子参数,重新进行步骤3.3.2训练过程,获得最优旋转压缩变换决策子树;
步骤4:基于多个最优旋转压缩变换决策子树,以投票机制构成最终的高压断路器机械缺陷诊断模型;
基于不同的抽样子集不断重复步骤3中训练-评估-优化过程,获得多个最优旋转压缩变换子树orcttn(optimalrotation&compressiontransformtree),n=1,2,…,n,并统计多个最优旋转压缩变换决策子树的分类结果,以少数服从多数的投票机制集成融合,如公式(10)所示,完成高压断路器机械缺陷的最终诊断。
其中,c表示测试样本小波包能量熵特征向量,lg表示第n个最优旋转压缩变换决策子树的诊断结果(即缺陷类别),i(orcttn,c,lg)表示第g行为1的列向量,
本发明应用实例如下,以某型号高压断路器为实验平台设置正常情况、分闸弹簧疲劳、合闸弹簧疲劳、油缓冲器漏油、传动轴阻尼增加及地脚螺栓松动6种运行工况,一共做了合闸试验各300次,每种运行工况50次,随机选用每种运行工况的70%数据,即35个数据进行训练,剩余数据进行测试验证。训练样本数m=210,在小波包时频矩阵中,沿时间轴等分n1=12,沿频率轴等分n2=13,则共分为12×13个能量块,小波包能量熵构成的原始特征空间维度w为12+13等于25,设置最优旋转压缩子决策树数量n=100,粒子群算法粒子数np=30,最大迭代次数intermax=100,惯性因子ω=0.5,学习因子c1和c2均等于2,每个粒子由隐含层神经元个数p、正则化系数λ以及决策树停止分割的纯度要求值γ三个参数构成。利用本专利所述方法,设计优化旋转压缩特征变换的决策树集成诊断方法,通过测试数据的诊断结果表明,该方法可以降低了振动分散性对诊断结果的影响,强化了高压断路器同类典型工况样本在特征空间的聚合程度以及不同故障间的分离程度,同时解决了诊断模型的超参选择问题,增强了各决策子树的表征能力,有效提升了故障分类的准确率。
最后应当说明的是:所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!