一种全息科技数据处理方法与流程
本发明涉及软件架构技术,尤其涉及一种全息科技数据处理方法。
背景技术:
随着“以用户为中心、以服务为导向”的政府形态的提出,对分散在政府各职能部门的科技项目资源进行有效的梳理和整合,设计科技全息数据模型,对于全面掌握项目生命周期全过程的信息,为用户提供个性化、精细化和移动化的服务。
因为数据类型和组织模式多样化、关联关系繁杂、质量良莠不齐等内在的复杂性,使得数据的感知、表达、理解和计算等多个环节面临着巨大的挑战。
技术实现要素:
为了解决以上技术问题,本发明提出了一种全息科技数据处理方法,结合各类科技信息资源,设计全息科技数据模型,对数据模型进行系列处理,提高数据的准确性。
本发明的技术方案是:
一种全息科技数据处理方法,主要包括四个步骤:
1)全息科技数据梳理与描述;
2)全息科技数据模型设计
3)全息科技数据清洗;
4)全息科技数据数据融合。
其中,1)全息科技数据梳理与描述
在科技项目信息数据服务的基础上,建立科技数据分类体系,将业务分成需求征集、重点任务布局、实施方案编制、专项设立、编制项目指南、合规性审核、答辩评审、正式申报、首轮评审、预申报、指南发布、立项结果公示、项目立项、预算经费监管、项目绩效评估、项目成果管理、项目成果转化、科技成果推广宣传、科技奖励阶段;
通过上述梳理,将科技项目管理业务归为项目、机构、人员、产出、环境、条件、事件和项目管理过程这八类要素。
2)全息科技数据模型设计
按照上述构成科技数据的八要素,设计科技全息数据模型;
3)全息科技数据清洗
数据清洗包括清除重复数据、消除噪声数据。
其中,重复数据的清洗:
如果有两个及以上的实例表示的是同一实体,那么即为重复记录。为了发现重复实例,将每一个实例都与其他实例进行对比,找出与之相同的实例;对于实例中的数值型属性,采用统计学的方法来检测,根据不同的数值型属性的均值和标准方差值,设置不同属性的置信区间来识别异常属性对应的记录,识别出数据集合中的重复记录,并加以消除;
相似度计算是重复数据清洗过程中的常用方法,通过计算记的各属性的相似度,再考虑每个属性的不同权重值,加权平均后得到记录的相似度;
如果两条记录相似度超过了设定的阈值,则认为两条记录是匹配的,否则,认为这两条记录指向不同实体。
噪声数据处理:
在数据收集、整理的过程中,产生的噪声数据,即“离群点”;通过值域及文本语义理解判定数据内容值的合理性并修订。
对于数值型数据采用平滑数据的方法,文本内容采用语义判断-相似文本替换的方法。
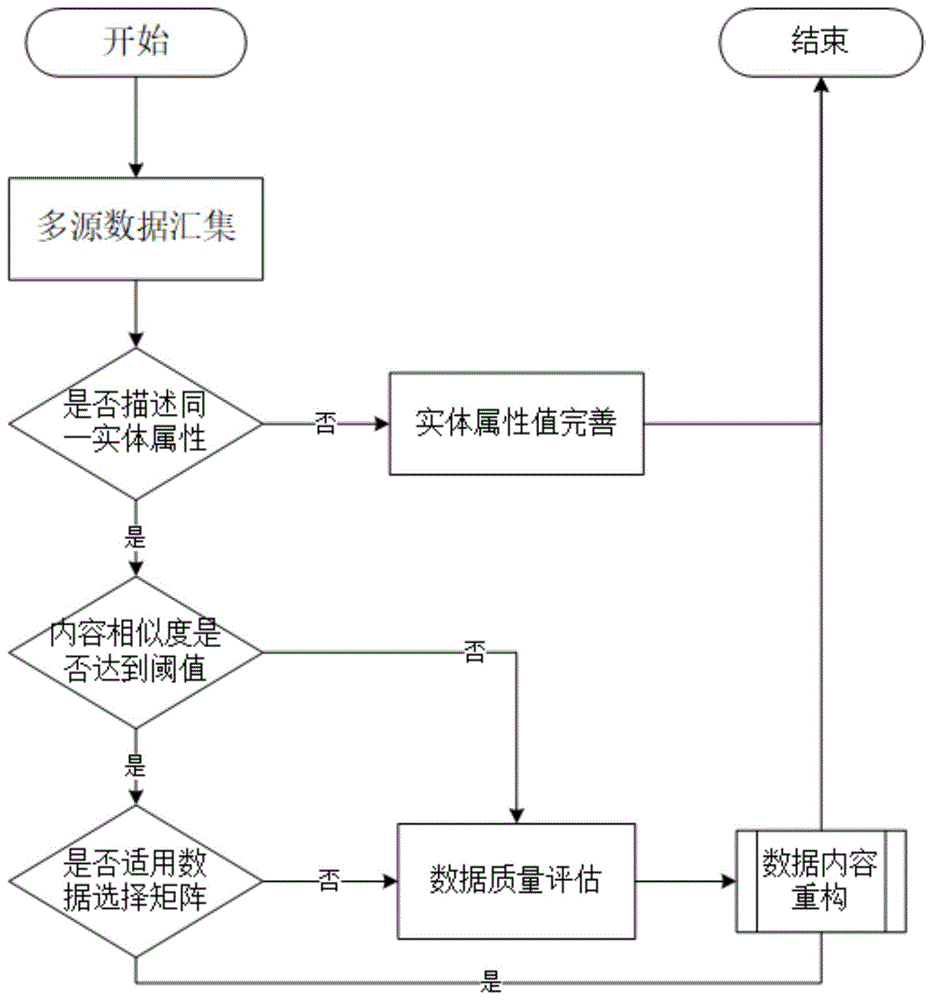
4)全息科技数据数据融合
数据集成是将多文件或多数据库运行环境中的异构数据进行合并处理,解决语义模糊性;该部分主要涉及数据的选择、不一致数据的处理问题。
数据选择指不同来源信息对实体的同一属性进行描述时做的选择;
根据算法矩阵用于判定不同数据源的内容权重值,根据最后权重值计算最终的内容项。
当内容适合使用数据选择矩阵时,可以进行权重计算,数据重构。
当内容不适用数据选择矩阵时,分别对数据源进行数据质量评估,依据数据质量评估矩阵进行数据内容重构。
本发明的有益效果是
有效整合政府各职能部门的科技管理信息资源,建立贯穿科技项目管理生命周期全过程的科技项目全息数据模型,实现不同来源数据清洗、融合,作为数据分析、挖掘前的重要数据准备工作,可以保证数据的准确性和有效性。
附图说明
图1是本发明的数据融合流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的一种全息科技数据处理方法,主要包括四个步骤:
1)全息科技数据梳理与描述;
2)全息科技数据模型设计
3)全息科技数据清洗;
4)全息科技数据数据融合。
其中,1)全息科技数据梳理与描述
在科技项目信息数据服务的基础上,建立科技数据分类体系,将业务分成需求征集、重点任务布局、实施方案编制、专项设立、编制项目指南、合规性审核、答辩评审、正式申报、首轮评审、预申报、指南发布、立项结果公示、项目立项、预算经费监管、项目绩效评估、项目成果管理、项目成果转化、科技成果推广宣传、科技奖励阶段。
通过上述梳理,发现科技项目管理业务涉及项目、机构、人员、产出、环境、条件、事件和项目管理过程这八类要素。如下表所示
2)全息科技数据模型设计
按照上述构成科技数据的八要素,设计科技全息数据模型。
3)全息科技数据清洗
数据清洗包括清除重复数据、消除噪声数据。在分析“脏数据”的产生来源和存在形式后,充分利用新兴的技术手段和方法去清洗“脏数据”,将“脏数据”转化为满足数据质量或应用要求的数据。
重复数据的清洗。如果有两个及以上的实例表示的是同一实体,那么即为重复记录。为了发现重复实例,通常的做法是将每一个实例都与其他实例进行对比,找出与之相同的实例。对于实例中的数值型属性,可以采用统计学的方法来检测,根据不同的数值型属性的均值和标准方差值,设置不同属性的置信区间来识别异常属性对应的记录,识别出数据集合中的重复记录,并加以消除。
相似度计算是重复数据清洗过程中的常用方法,通过计算记的各属性的相似度,再考虑每个属性的不同权重值,加权平均后得到记录的相似度。如果两条记录相似度超过了某一阈值,则认为两条记录是匹配的,否则,认为这两条记录指向不同实体。关于相似度计算可以参见《一种基于数据图谱的科技资源关联推荐方法》中的描述。
缺失数据,在现实世界中,由于手动输入的失误操作、部分信息需要保密或者数据来源不可靠等各种各样的原因,使得数据集中的内容残缺不完整。这部分数据的处理依赖于后面数据融合阶段来完善。
噪声数据处理。在实际应用中因为各种原因,在数据收集、整理的过程中,产生大量的噪声数据,即“离群点”。因为噪声数据不在合理的数据域内,所以通过值域及文本语义理解判定数据内容值的合理性并修订。对于数值型数据采用平滑数据的方法,文本内容采用语义判断-相似文本替换的方法。
4)全息科技数据数据融合
数据集成是将多文件或多数据库运行环境中的异构数据进行合并处理,解决语义模糊性。该部分主要涉及数据的选择、不一致数据的处理问题。
数据选择指不同来源信息对实体的同一属性进行描述时做的选择。本方法形成的一套算法矩阵用于判定不同数据源的内容权重值,根据最后权重值计算最终的内容项。
该内容适合使用数据选择矩阵,可以进行权重计算,数据重构。
该内容不适用数据选择矩阵,分别对数据源进行数据质量评估,依据数据质量评估矩阵进行数据内容重构。
本发明建立了一套用以描述科技管理领域的数据集合和一个描述服务、文件的元数据模型,并通过对数据的处理,形成准确、完整的数据仓库。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!