海林格距离为参考标准的过采样的方法与流程
本发明涉及特定数据集下不平衡学习中过采样技术领域,具体涉及海林格距离为参考标准的过采样的方法。
背景技术:
不平衡数据(imbalancedata)即数据集类别的样本不均衡。以二分类问题为例,数据集中的多数类与少数类样本的比例大于不平衡率ir(imbalanceratio)时,这样的数据被称为不平衡数据。通常认为ir等于1.45或1.5的数据集为平衡的数据集。数据集的不平率
不平衡学习是在不平衡数据下对数据进行处理,使得分类预测能够得到更高的准确度。不平衡学习的方法有很多,例如,代价敏感(cost-sensitive)、采样方法(samplingmethod)、集成学习(ensemblelearning)等等。
过采样(oversampling)是不平衡学习中采样方法的一种,过采样主要是增加少数类的样本数量。即从少数类集合中随机选取样本点为参考点,以参考点为基础合成新的样本点,将新的样本点加入小类中,使小类的数量增加。
syntheticminorityoversamplingtechnique是一种合成采样方法,简称smote,它已经被证明在很多领域都比较有效。它主要是基于现存的少数类样本,计算样本特征空间之间的相似度,然后创建人工合成样本。
海林格距离(hellingerdistance)又称bhattacharyyadistance。在概率和统计学中,hellingerdistance被用来衡量两个概率分布之间的相似性,在不平衡学习中,海林格距离可用来衡量两个类之间的相似程度,计算得到属性的重要程度,这为实现本发明提供了可能。
技术实现要素:
针对当前过采样技术smote合成样本点会导致重叠、过度拟合和轻度泛化的问题,本发明提供海林格距离为参考标准的过采样的方法,该方法能避免样本点重叠,提高过采样技术smote合成的样本点的拟合性和泛化性。
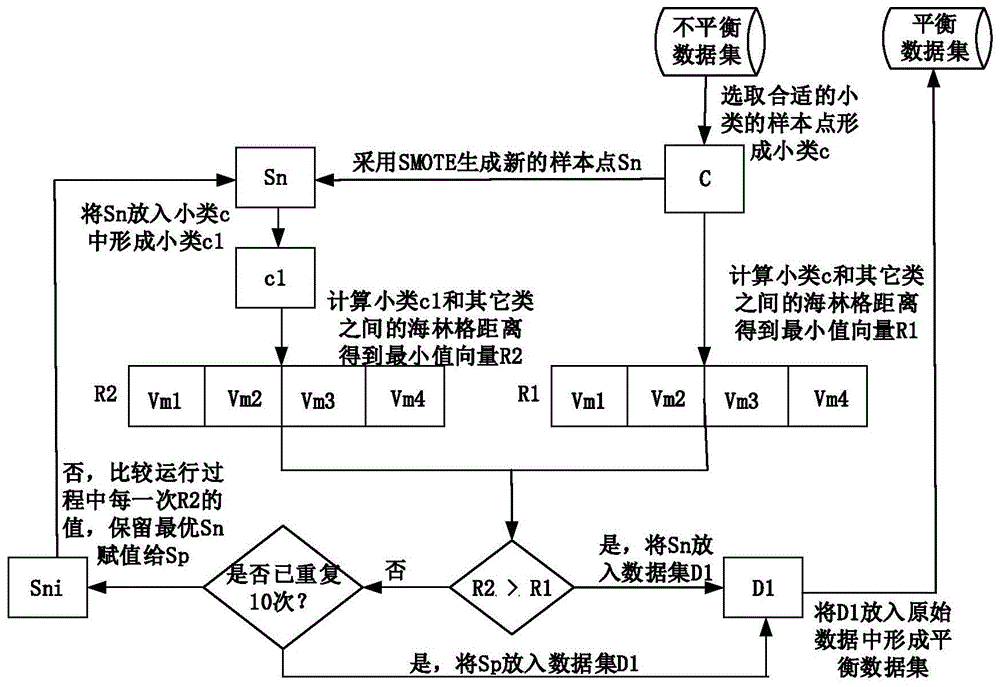
本发明思路:伪随机选取小类中某一样本点为参考点,对参考点采用syntheticminorityoversamplingtechnique技术产生新的样本点,在合成样本点过程中,计算参考点所在小类与其它类的海林格距离,形成海林格距离矩阵,计算海林格距离矩阵列向量的最小值;将每次产生的样本点单独放入小类中,再次计算参考点所在小类和其它类的海林格距离,形成海林格距离矩阵,计算海林格距离矩阵列向量的最小值。比较合成样本点前和合成样本点后的海林格距离的最小值,判断合成样本点的质量。
具体步骤为:
第1步在小类中选取参考点s,以k近邻方式,通过参考点s随机选取目标点g,其中参考点s和目标点g属于同一类别。
第2步计算与样本点s属于同一类的k近邻数量k1和与目标点g属于同一类的k近邻数量k2。其中k近邻数量kn根据数据集情况自行确定,一般取kn=10。
第3步判断参考点s和目标点g是否满足基本要求。若k2>k1或者k1>kn/2并且k2>kn/2,执行第4步,否则重复执行第1步、第2步和第3步,直至满足条件。
第4步合成样本点前的海林格距离计算:计算合成样本点前参考点s所在小类和其它各个类之间的海林格距离,形成距离矩阵m1。
第5步取m1矩阵中每一列的最小值,形成行向量r1。
第6步计算合成样本点后的海林格距离,将新产生的样本点加入当前小类中,形成新的小类c1,计算c1和其它各个类之间的海林格距离,形成距离矩阵m2。
第7步取m2矩阵中每一列的最小值,形成行向量r2。
第8步比较r1和r2大小来判定新合成样本点的质量。
本发明所述的海林格距离为参考标准的过采样的方法,其中海林格距离能够衡量两个类之间的相似程度,若两个类之间的相似程度越大,越难分类,通过比较合成样本点前和合成样本点后的海林格距离,在满足合成样本点的基础上,使合成的样本点保持或者降低两个类之间的相似程度,达到提高新合成样本点质量的目的,适用于在特定多类不平衡数据集下避免smote技术合成样本点后的重叠问题,提高smote技术合成的样本点的拟合性和泛化性。
附图说明
图1是本发明实施例的具体步骤流程图。
图2是本发明实施例采用的smote技术图。
图3是本发明实施例smote合成样本点后效果图。
图4是本发明实施例以海林格为参考标准的效果图。
图5是本发明实施例在精度(precision)评价标准下的效果图。
图6是本发明实施例在mauc评价标准下的效果图。
具体实施方式:
本实施例采用uci(http://mlr.cs.umass.edu/ml/dataets.html)和keil(htt://sc2s.ugr.es/keel/datasets.php)上公布的不平衡数据集,过采样方法采用syntheticminorityoversamplingtechnique技术。由于平台上数据集中样本数量太多,不方便展示,为方便说明具体步骤,本实施例采用人为定义的一个数据集d,如图2所示,数据集d有4个属性,由4个类组成,2个大类a和b,样本数量分别为19和20;2个小类c和d,样本数量分别为5和10。其中k近邻中k取5。
具体步骤为:
第1步样本点的选取,从第一个小类c中选取一个样本点s作为参考点,以k近邻方式,通过参考点s随机选取目标点g,其中目标点g和参考点s属于小类c,如图1所示。
第2步计算与参考点s属于同一类的k近邻数量k1和与目标点g属于同一类的k近邻数量k2。其中k近邻数量kn=5。
第3步判断参考点s和目标点g是否满足基本要求。若k2>k1或者k1>3并且k2>3,执行第4步,否则重复执行第1步、第2步和第3步,直至满足条件。
第4步海林格距离计算:计算合成样本点前参考点s所在小类和其它各个类之间的海林格距离,形成距离矩阵m1。
第4.1步计算公式和构造m1如下:
海林格距离公式:
我们将当前考虑的小类c作为正类,其它类a,b,d作为负类。
其中dh(tpr,fpr)表示正类t和负类f之间的海林格距离;tpr表示正类被正确分为正类的概率,fpr表示负类被正确分为负类的概率。
第4.2步通过混淆矩阵计算可得tpr和fpr。其中混淆矩阵如下:
第4.3步计算小类c和a,b,d的海林格距离。重复4.1和4.2步,可计算出小类c和a,b,d的海林格距离:
d(c,a)=[va1va2va3va4]
d(c,b)=[vb1vb2vb3vb4]
d(c,d)=[vd1vd2vd3vd4]
其中,va1表示在第一个属性上正类c和负类a的海林格距离。
第4.4步形成距离矩阵m1。每有一个属性对应一个海林格距离值,数据集d有4个属性,即有4个海林格距离值。
第4.5步计算矩阵m1每一列的最小值,得到行向量r1,
计算之后可得,r1=[vm1vm2vm3vm4],其中vm1表示m1第一列的最小值。
第4.6步通过syntheticminorityoversamplingtechnique合成新的样本点sn。样本点合成公式如下:sn=s+α*(g-s),α的取值范围是(0,1)。
第4.7步计算合成样本点sn之后的海林格距离。将sn放入正类c中,执行第4.1步,4.2步,4.3步,4.4步和4.5步,形成矩阵m2和行向量r2。
第4.8步判断合成点sn的质量。比较r2和r2的大小,若r2>r1,说明合成的点的质量好,执行第5步,否则执行第4.9步。
第4.9步执行第4.6步、第4.7步,将sn保留为初始的最优值,即sp=sn。合成样本点sni,m2i和r2i,若r2i>r1,执行第5步,否则比较r2i和r2的大小,若r2i>r2,令r2=r2i,sp=sni。最多执行max{i}次第4.9步之后执行第5步。其中sp表示合成的最优样本点,sni表示第i次合成的样本点,m2i表示第i次合成样本点之后得到的海林格距离矩阵,r2i表示对应的m2i的每一列的最小值形成的行向量,i=1,2,3……10,max{i}表示i的最大值。
第5步,sn放入dn中,重复执行的1步,第2步,第3步和第4步,直至小类c的样本数量等于数量最大的大类的样本数量,即大类b的数量。
第6步,选择下一个小类执行第1步、第2步、第3步、第4步和第5步,直到所有小类都选择完。
第7步,将dn中数据放入d中,形成平衡数据集,如图4所示。
- 还没有人留言评论。精彩留言会获得点赞!