一种从文本抽取地址的方法与流程
本发明涉及文本数据挖掘抽取技术领域,具体为一种从文本抽取地址的方法。
背景技术:
文本数据挖掘是一种利用计算机处理技术从文本数据中抽取有价值的信息和知识的应用驱动型学科,文本数据挖掘处理的数据类型是文本数据,属于数据挖据的一个分支,与机器学习、自然语言处理、数理统计等学科具有紧密联系,文本挖掘在很多应用中都扮演重要角色,例如数据采集、信息抽取(例如互联网搜索)等。
文本信息抽取是文本数据挖掘的一个基础技术,文本信息抽取是从文本数据中抽取特定信息的一种技术,文本数据是由一些具体的单位构成的,例如句子、段落、篇章,文本信息正是由一些小的具体的单位构成的,例如字、词、词组、句子、段落或是这些具体的单位的组合,抽取文本数据中的联系方式、邮箱地址、社交号码、短语、人名、地名等都是文本信息抽取,当然,文本信息抽取技术所抽取的信息可以是各种类型的信息。
而在抽取文本数据中的地址,通过目前已有的技术方案实现时,其精准率比较低,在抽取文本数据中的地址的过程中,有时会导致提取的信息出错、用户无法使用的问题,严重地影响了在抽取文本数据时的工作效率及准确性,故亟需一种高效稳定的从文本中抽取地址的操作方法。
技术实现要素:
(一)解决的技术问题
本发明提供了一种从文本抽取地址的方法,具备抽取数据时精准度较高、不会出现抽取的信息出错、工作效率及稳定性较高的优点,解决了在文本数据中抽取地址的问题:通过目前已有的技术方案实现时,其精准率比较低,在抽取文本数据中的地址的过程中,有时会导致提取的信息出错、用户无法使用的情况。
(二)技术方案
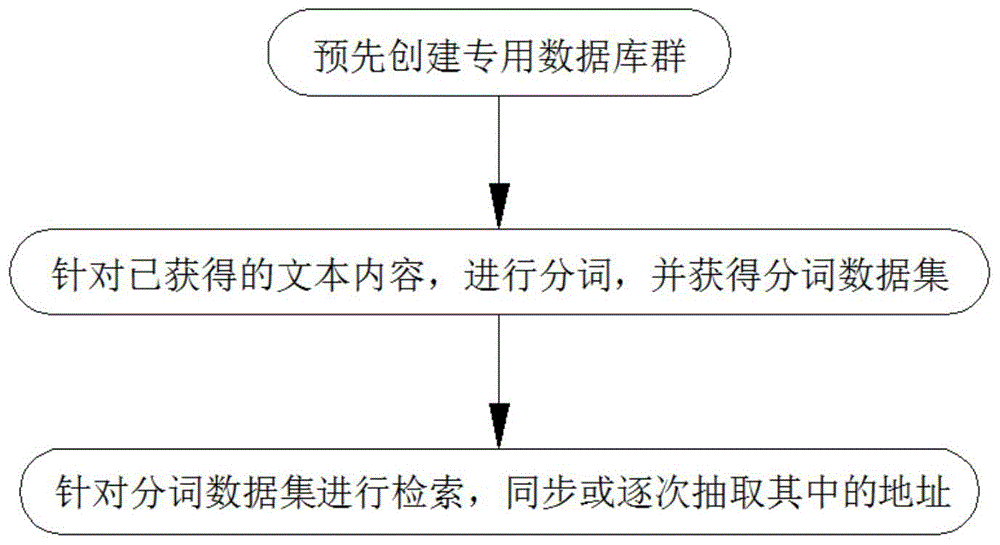
本发明提供如下技术方案:一种从文本抽取地址的方法,包括以下操作步骤:
s1、预先创建专用数据库群;
s2、针对已获得的文本内容,进行分词,获得分词数据集;
s3、针对分词数据集进行检索,同步或逐次地抽取其中的地址。
优选的,所述专用数据库群均支持用户自定义增减数据。
优选的,所述文本内容均为电子格式的面向计算机信息处理的文字组合。
优选的,所述专用数据库群,包括自定义地址数据库、标准地址数据库、全国行政区划及其简称库、地址触发词组合库、全国单位名称和简称及地址库、天干序词库、地址专用标点符号库、数词库、方位名词库、楼宇小区名称及其简称库和趋向动词库。
优选的,所述自定义地址数据库,包括:
①自定义地址专用词语组合占比阈值,所述自定义地址专用词语组合占比阈值是指用户预先设置一个阈值,当自定义地址组合专用词库、全国单位名称和简称及地址库、天干序词库、地址专用标点符号库、数词库、方位名词库、楼宇小区名称及其简称库、趋向动词库中的字词在文本中占有的比例高于阈值,即默认文本为地址;若低于阈值,判断为非法地址;
②自定义地址组合专用词库,所述自定义地址组合专用词库分为自定义地址末端词库和自定义地址交通词库。
优选的,所述地址触发词组合库包括:触发词库和触发词后面的专用标点符号,所述触发词库分为单独触发词和组合触发词两种类型。
优选的,所述同步或逐次地抽取其中的地址,包含以下四个规则:
规则一,根据预先创建的专用数据库群中的全国单位名称和简称及地址库,检索有无企业、事业单位、政府机构、社会团体的地址,如有,抽取为地址;
规则二和规则三,检索有无同时符合条件的文字组合,如有,抽取为地址;
规则四,包括以下检索步骤:
步骤ⅰ、根据预先创建的专用数据库群中的触发词库,检索触发词库中有无触发词,如有,则继续检索,若无,则不再检索;
步骤ⅱ、根据预先创建的专用数据库群中的触发词后面的专用标点符号,检索地址触发词的右侧有无触发词后面的专用标点符号,如有,则抽取触发词后面的专用标点符号右侧的第一个单句作为地址。
优选的,所述单句的抽取方法如下:
首先,检索触发词后面的专用标点符号;
之后,检索触发词往右的第一个触发词后面的专用标点符号之外的其他标点符号或空格;
最后,抽取触发词后面的专用标点符号和触发词往右的第一个触发词后面的专用标点符号之外的其他标点符号或空格两者之间的文本内容,作为所述单句。
(三)有益效果
本发明具备以下有益效果:
1、本发明提供的一种从文本抽取地址的方法,通过创建专用的数据库群,同时获取分词数据集,之后再将分词数据集按照一定的规则同步或逐次进行检索,利用逐步分次的检索文本信息的方式,使得从文本抽取的地址精准度更高,同时减少许多不必要的检索内容,提高了在抽取文本数据时的工作效率。
2、本发明提供的一种从文本抽取地址的方法,通过抽取触发词后面的专用标点符号和触发词往右的第一个触发词后面的专用标点符号之外的其他标点符号或空格两者之间的文本内容,作为第一个单句地址的方式,有效地避免了在抽取文本中的地址信息时出现错误,而导致用户无法使用的问题,进一步提高了该操作方法从文本中抽取的地址的精准度。
附图说明
图1为本发明方法的流程图;
图2为本发明方法规则一的流程图;
图3为本发明方法规则二或三的流程图;
图4为本发明方法规则四的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,一种从文本抽取地址的方法,包括以下操作步骤:
s1、预先创建专用数据库群;
s2、针对已获得的文本内容,进行分词,获得分词数据集;
s3、针对分词数据集进行检索,同步或逐次地抽取其中的地址。
本技术方案中,专用数据库群均支持用户自定义增减数据。
本技术方案中,文本内容均为电子格式的面向计算机信息处理的文字组合。
本技术方案中,专用数据库群,包括自定义地址数据库、标准地址数据库、全国行政区划及其简称库、地址触发词组合库、全国单位名称和简称及地址库、天干序词库、地址专用标点符号库、数词库、方位名词库、楼宇小区名称及其简称库和趋向动词库。
本技术方案中,自定义地址数据库,包括:
①自定义地址专用词语组合占比阈值,自定义地址专用词语组合占比阈值是指用户预先设置一个阈值,当自定义地址组合专用词库、全国单位名称和简称及地址库、天干序词库、地址专用标点符号库、数词库、方位名词库、楼宇小区名称及其简称库、趋向动词库中的字词在文本中占有的比例高于阈值,即默认文本为地址,若低于阈值,判断为非法地址;
②自定义地址组合专用词库,自定义地址组合专用词库分为自定义地址末端词库和自定义地址交通词库。
其中,自定义地址组合专用词库分为自定义地址末端词库和自定义地址交通词库,且自定义地址末端词库包括:路、街、巷、弄、胡同、楼、大厦、社区、公寓、花园、中心、号、单元、栋、幢、车库、停车场、楼房、小区、社区、家属楼、宿舍楼、宿舍、环、广场、公寓、期、室、房、间、附近、边上、隔壁、条、庄、院、层、负、底商和附属等;而自定义地址交通词库包括:往、朝、顺、拐、进、走、行走、步行、大概、大约、巷子、楼、小路、小巷子、行走、开车、开、隔壁、上楼、坐电梯、乘坐、坐、地铁、公交站、公共汽车、站、线、路、交叉、十字、丁字、t字、路口、入口、市场、口等。
其中,标准地址数据库分为:①标准地址第一末端词库,包括:全国道路街道名称的汇总数据;②标准地址第二末端词库,包括:单个第二末端词和组合第二末端词;③标准地址第三末端词库,包括单个第三末端词和组合第三末端词。
其中,单个第二末端词包括:弄、段、胡同、巷等;组合第二末端词是指在单个第二末端词左侧加上前缀词组合而成的词;单个第三末端词包括:号等;组合第三末端词是指在单个第三末端词左侧加上前缀词组合而成的词。
其中,前缀词包括:数字、英文字母、数量词、方位词、天干序词、地址专用标点符号,及其任意组合。
其中,全国行政区划及其简称库分为一级省级行政区划及其简称库、二级地级行政区划及其简称库、三级县级行政区划及其简称库、四级乡镇级行政区划及其简称库、五级村级行政区划及其简称库和六级组级行政区划及其简称库。
其中,一级省级行政区划及其简称库包括:省、自治区、直辖市、特别行政区和全国省级行政区域名称库;二级地级行政区划及其简称库包括:地级市、地区行政公署管辖区域、自治州、盟行政公署管辖区域和全国地级行政区域名称库;三级县级行政区划及其简称库包括:市辖区、县、自治县、县级市、旗、自治旗、林区、特区和全国县级行政区域名称库;以此类推,直到六级组级行政区划及其简称库。
本技术方案中,地址触发词组合库包括:触发词库和触发词后面的专用标点符号,触发词库分为单独触发词和组合触发词两种类型。
其中,触发词后面的专用标点符号包括:【:】、【→】、【-】、【_】、【\】、【/】、【——】等。
其中,单独触发词包括:地址、位置、地方、地点、导航、目的地、办公地、办公室、办公楼、写字楼、单位、住址、档口;组合触发词是指单独触发词和下列文字的向右序列组合:在、是、为、位于、找、到、请到、请找、路线等等。
其中,单独触发词、组合触发词中的文字及触发词后面的专用标点符号均支持用户自定义增减数据。
其中,全国单位名称和简称及地址库包括:企业、事业单位、政府机构、社会团体的名称和简称及其地址。
其中,天干序词库,包括:甲、乙、丙、丁、戊、己、庚、辛、壬、癸。
其中,地址专用标点符号库包括:【-】、【_】、【\】、【/】、【——】、括号等,括号符号包括:小括号符号、中括号符号、大括号符号、六角括号符号、书名号符号、竖型上下括号符号、特殊括号符号。
请参阅图2-3,本技术方案中,同步或逐次地抽取其中的地址,包含以下四个规则:
规则一,根据预先创建的专用数据库群中的全国单位名称和简称及地址库,检索有无企业、事业单位、政府机构、社会团体的地址,如有,抽取为地址,若无,则不进行抽取;
规则二和规则三,检索有无同时符合条件的文字组合,如有,抽取为地址,若无,则不进行抽取;
规则四,包括以下检索步骤:
步骤ⅰ、根据预先创建的专用数据库群中的触发词库,检索触发词库中有无触发词,如有,则继续检索,若无,则不再检索;
步骤ⅱ、根据预先创建的专用数据库群中的触发词后面的专用标点符号,检索地址触发词的右侧有无触发词后面的专用标点符号,如有,则抽取触发词后面的专用标点符号右侧的第一个单句作为地址。
其中,规则二的判定条件如下:
条件一:从高到低序列组合,从高到低,是指从全国行政区划及其简称库中一级省级行政区划到六级组级行政区划、再到标准地址数据库中标准地址第一末端词、标准地址第二末端词、标准地址第三末端词的从左向右组合序列方式;
条件二:至少包含二级县级行政区划、三级县级行政区划、四级乡镇级行政区划、五级村级行政区划、六级组级行政区划、标准地址第一末端词、标准地址第二末端词、标准地址第三末端词中的2个。
其中,规则三的判定条件如下:
条件一:文本由中文、英文字母、阿拉伯数字、标点符号,任意组合而成,且不低于2个字;
条件二:序列组合的字符串之间的标点符号,只能是地址专用标点符号;
条件三:自定义地址组合专用词库、全国单位名称和简称及地址库、天干序词库、地址专用标点符号库、数词库、方位名词库、楼宇小区名称及其简称库、趋向动词库中的字词,在文本中占有的比例,高于用户预设的自定义地址专用词语组合占比阈值。
本技术方案中,单句的抽取方法如下:
首先,检索触发词后面的专用标点符号;
之后,检索触发词往右的第一个触发词后面的专用标点符号之外的其他标点符号或空格;
最后,抽取触发词后面的专用标点符号和触发词往右的第一个触发词后面的专用标点符号之外的其他标点符号或空格两者之间的文本内容,作为单句。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!