一种基于社交网络的数据采集与分析方法与流程
本发明涉及数据处理技术领域,尤其涉及一种基于社交网络的数据采集与分析方法。
背景技术:
随着web2.0网络应用与移动终端设备的发展,社交网络的普及率与使用率日益提高。相比传统网络应用形式,社交网络具有用户主体性强、网络特征多样、数据内容丰富、群体交互密切、信息传播迅速等特点。中国互联网用户数量已经跃居全球首位,互联网用户在社交网站或者各大门户网站平台每天产生大量的网络行为数据。特别是微信、微博、手环等即时通讯、自媒体工具以及个人状态感应设备的使用,更使得每个用户随时都可以产生数据,整个社会深度跨入“社交网络大数据”时代。信息技术的迅速发展,大幅度的提高了科研人员的计算能力,各类型的硬件存储设备也不断升级,逐步满足数据的存储要求。在软件层面,算法、架构和编程语言也层出不穷。软硬件技术的发展,更给大数据挖掘提供了可能。
对社交网络大数据进行挖掘,能获得反映真实世界及其中的人的各种宝贵信息。但同时,社会媒体中的数据也存在多源异构、个体间关系繁杂、信息传播突发等特点,给社会媒体分析提出了技术上的挑战。分析社交网络的结构规律、挖掘用户行为的特定模式、探索网络信息传播的内在机理、研究高效的社交网络分析与网络信息传播预测方法,有利于提升对在线社会媒体的科学认知水平和有效利用能力,所以通过数据挖掘方法获取社交网络中的大量其它有价值的信息,已成为非常值得研究的问题。
由于近年来深度学习的流行,而深度学习又需要数据去训练,因此对数据的采集需求又进一步加强。而当前传统系统和方法都不具备大数据分析处理能力,并且数据采集一直存在成本偏高和花费时间长的缺陷。传统数据挖掘技术采用可构建预测模型的算法,包括线性回归,决策树学习器,贝叶斯分类器和支持向量机等,但此类算法依然有待继续改善。
技术实现要素:
针对现有技术的不足,本发明所解决的技术问题是如何低成本地从大规模社交网络中进行用户的主题提取,获取较全面的用户信息,实现社交网络用户画像。
为解决上述技术问题,本发明采用的技术方案是一种基于社交网络的数据采集与分析方法,包括以下步骤:
(1)以数据采集模块采用python中的scrapy框架,构建微博爬虫系统,使用分布式爬虫算法获取微博社交网络中用户账号信息、用户原创内容以及用户社交关系数据;
所述分布式爬虫算法,具体应用过程如下:
1)使用python中的scrapy框架,构建微博爬虫系统;
2)爬取用户微博账号,以user_id表示其字段类别,下载微博主页页面地址对应的网页文件,在回调函数中完成数据解析和判别;
3)账号自动登录,通过从数据库获取事先准备的多个微博账号和密码,使用selenium+phantomjs模拟登录微博平台,进行系统登录;
4)验证码的自动识别与验证,在登录过程中,获取验证码图片后,调用云打码平台提供的接口,提供验证码,接收云打码返回的验证码字符串,再在phantomjs中模拟登录;登录过程中建立cookie池,通过爬虫框架中间件请求设计好的基于flask框架的接口,随机从数据库中返回json格式的新cookie,提供给scrapy使用,来解决更换cookie的问题;
5)进行查重处理,在解析用户数据过程并进行存储的过程中,进行查重处理,即在分词之前,对文本进行一些预处理,解析每一个html格式的网页,提取用户个人及其所发表的关键文本信息,通过md5算法进行文本的哈希运算进行文本信息的重复性判断和去重处理。
所述用户账号信息具体包括微博用户的性别、年龄、学历、地域、教育背景、工作经历、婚姻状态。
(2)数据存储模块将网络爬取的用户数据保存到json格式和nosql类型的mongodb数据库中;
(3)数据处理模块基于自然语言处理技术,对用户原创内容的进行语义分析,设计短文本主题提取算法,进行用户的主题提取,从时间序列、地域等角度对大量用户数据进行多维度挖掘分析,实现社交网络用户大数据的判别利用,具体过程如下:
1)对存储的数据进行数据清理;
2)使用隐式狄利克雷分布算法作为主题提取算法,将分词之后单个用户的微博数据合并,使用隐式狄利克雷分布算法进行主题提取训练;
3)针对合适时间粒度的微博进行主题提取,实现对微博文本数据进行主题提取和分类。
(4)最后数据分析模块研究实现缺失属性信息推断算法,获取较全面的用户信息,实现社交网络用户画像,具体过程如下:
对文本多样性及社交媒体结构复杂性问题,采用多源融合、多特征融合及机器学习分类功能为一体的算法,利用训练得到的模型和用户的已知特征,预测用户的未知特征,最终实现用户缺失的属性信息的推断。
与现有技术相比,本发明通过大数据挖掘,获取有价值的信息,降低了企业或其他单位大数据分析的成本,实用性强,易于推广。
附图说明
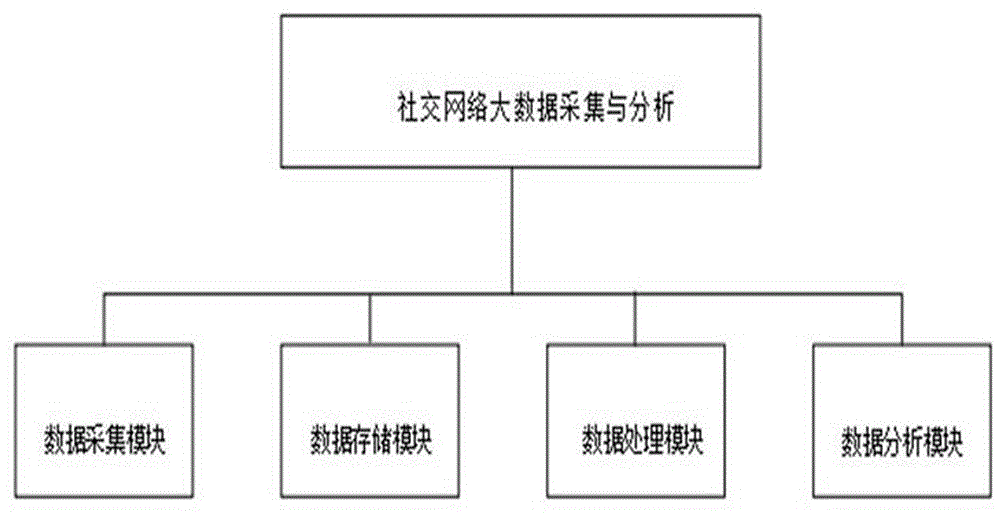
图1为本发明系统结构示意图;
图2为本发明流程示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的说明,但不是对本发明的限定。
图1示出了一种本发明系统结构示意,系统由以下几个功能组件构成:数据采集模块、数据存储模块、数据处理模块以及数据分析模块。
图2示出了本发明流程示意,种基于社交网络的数据采集与分析方法,包括以下步骤:
(1)以数据采集模块采用python中的scrapy框架,构建微博爬虫系统,使用分布式爬虫算法获取微博社交网络中用户账号信息、用户原创内容以及用户社交关系数据;
所述分布式爬虫算法,具体应用过程如下:
1)使用python中的scrapy框架,构建微博爬虫系统;
2)爬取用户微博账号,以user_id表示其字段类别,下载微博主页页面地址对应的网页文件,在回调函数中完成数据解析和判别;
3)账号自动登录,通过从数据库获取事先准备的多个微博账号和密码,使用selenium+phantomjs模拟登录微博平台,进行系统登录;
4)验证码的自动识别与验证,在登录过程中,获取验证码图片后,调用云打码平台提供的接口,提供验证码,接收云打码返回的验证码字符串,再在phantomjs中模拟登录;登录过程中建立cookie池,通过爬虫框架中间件请求设计好的基于flask框架的接口,随机从数据库中返回json格式的新cookie,提供给scrapy使用,来解决更换cookie的问题;
5)进行查重处理,在解析用户数据过程并进行存储的过程中,进行查重处理,即在分词之前,对文本进行一些预处理,解析每一个html格式的网页,提取用户个人及其所发表的关键文本信息,通过md5算法进行文本的哈希运算进行文本信息的重复性判断和去重处理。
所述用户账号信息具体包括微博用户的性别、年龄、学历、地域、教育背景、工作经历、婚姻状态。
(2)数据存储模块将网络爬取的用户数据保存到json格式和nosql类型的mongodb数据库中;
数据存储模块针对微博用户数据及其结构特征,采用类json格式和nosql类型的mongodb数据库进行数据存储,数据库设计依据如下:
(1)用户账号属性字段名称:user_info_page,含义:用户资料页面;
(2)用户账号属性字段名称:user_id,含义:用户id;
(3)用户账号属性字段名称:user_name,含义:用户名;
(4)用户账号属性字段名称:user_auth,含义:用户认证;
(5)用户账号属性字段名称:gender,含义:性别;
(6)用户账号属性字段名称:area,含义:地区;
(7)用户账号属性字段名称:birthday,含义:生日;
(8)用户账号属性字段名称:auth_info,含义:认证信息;
(9)用户账号属性字段名称:user_phone_url,含义:用户手机版主页地址;
(10)用户账号属性字段名称:user_internet_url,含义:用户互联网版主页地址;
(11)用户账号属性字段名称:vip_level,含义:vip等级;
(12)用户账号属性字段名称:brief_introduction,含义:简介;
(13)用户账号属性字段名称:emotional_situation,含义:感情状况;
(14)用户账号属性字段名称:user_label,含义:用户标签;
(15)用户账号属性字段名称:educational_experience,含义:学习经历;
(16)用户账号属性字段名称:work_experience,含义:工作经历;
(17)用户账号属性字段名称:master,含义:达人;
(18)用户账号属性字段名称:user_weibo_count,含义:微博总数;
(19)用户账号属性字段名称:user_follower_count,含义:关注者总数;
(20)用户账号属性字段名称:user_follower_url,含义:关注者列表url;
(21)用户账号属性字段名称:user_fan_count,含义:粉丝总数;
(22)用户账号属性字段名称:user_fan_url,含义:粉丝列表url;
(23)用户账号属性字段名称:user_grouping_count,含义:用户组数;
(24)用户账号属性字段名称:user_grouping_url,含义:用户组url;
(25)用户账号属性字段名称:user_album_url,含义:相册地址。
(3)数据处理模块基于自然语言处理技术,对用户原创内容的进行语义分析,设计短文本主题提取算法,进行用户的主题提取,从时间序列、地域等角度对大量用户数据进行多维度挖掘分析,实现社交网络用户大数据的判别利用,具体过程如下:
1)对存储的数据进行数据清理;
2)使用隐式狄利克雷分布算法作为主题提取算法,将分词之后单个用户的微博数据合并,使用隐式狄利克雷分布算法进行主题提取训练;
3)针对合适时间粒度的微博进行主题提取,实现对微博文本数据进行主题提取和分类。
数据处理模块,在分词之前,将会在数据预处理阶段进行处理。文件中每个用户自注册微博起发表的所有微博都被爬取,每条微博被存储为一条数据记录。分词后的每个词对应微博的发表时间、对应的用户,对应用户的微博等信息,都会在分词后的结果中进行记录。分词之后,可以依据关键词对用户数据作分类,对这一类关键词相关的用户,进行重点记录和标注。考虑到微博这类社交媒体用户原创内容的“短文”特征及长期数据的“长文”特征,需选定合适的时间粒度,将微博数据合并后再进行主题提取。
聚类技术是信息检索领域的一个重要方面,利用它有效缩减搜索空间,加快检索速度,提高检索精度。先利用向量空间模型,把文档转换成高维空间中的向量,然后对这些向量聚类。由于微博中文文档没有词的边界,所以先用中文分词软件对文档进行分词处理,然后再把文档转换成向量,使用tf-idf,通过特征词抽取后形成样本矩阵,再进行聚类,然后使用lda隐式狄利克雷分布算法作为主题提取算法,对微博文本数据进行主题提取和分类。微博文档是由多个隐含主题构成,又是由若干个特定特征词构成,lda模型忽略特征词的先后次序,从而简化主题模型的复杂性。将分词之后单个用户的微博数据合并,使用lda算法进行主题提取训练,然后再针对合适时间粒度的微博进行主题提取。
(4)最后数据分析模块研究实现缺失属性信息推断算法,获取较全面的用户信息,实现社交网络用户画像,具体过程如下:
对文本多样性及社交媒体结构复杂性问题,采用多源融合、多特征融合及机器学习分类功能为一体的算法,利用训练得到的模型和用户的已知特征,预测用户的未知特征,最终实现用户缺失的属性信息的推断。
数据分析模块面对文本多样性及社交媒体结构复杂性问题,采用多源融合、多特征融合及机器学习分类功能为一体的算法,设计缺失属性信息推断算法,获取较全面的用户人口统计学信息,实现社交网络用户画像分析。以用户性别为例,首先提取用户自己填写的资料,比如注册时或者活动中填写的性别资料,这些数据准确率一般很高。其次提取用户的称谓,如文本中有提到的对方称呼,例如:xxx先生/女士,也比较具有参考作用。再根据用户姓名、名字特征等预测用户性别,这是一个二分类问题,可以提取用户的名字部分,然后用朴素贝叶斯分类器训练一个分类器。另外还有一些特征可以综合利用,比如在爬取的用户社交网络关系数据中,有用户“关注”和“粉丝”两类数据,可以得到用户的关系网络。用户的社交圈,很多程度上也能反映用户的性别,因此社交网络关系数据可以在多源融合的用户性别推断中占有较大的比重。把这些特征加入到逻辑回归分类器(logisticregressionclassifier)进行训练,也能提高一定的数据覆盖率。通过将数据集拆分成训练集和测试集,来作为训练的输入和模型测试的输入。以训练集作为输入,训练性别预测分类模型,并做封闭和开放测试,当封闭测试准确率和召回率均大于等于一定标准(如0.90)时,开放测试准确率和召回率大于等于一定标准值(如0.80)时,则训练结束。否则,继续迭代。在数据来源较多时,由于从每种来源提取的数据可信度是不同的,所以各个来源提取的数据应该给出一定的权重,约定一般为0-1之间的一个概率值,这样系统在做数据的自动合并时,可以做加权求和,并对结果进行归一化输出和存储,最后即可推断出用户缺失属性,获取较全面的用户信息,实现社交网络用户画像。
与现有技术相比,本发明通过大数据挖掘,获取有价值的信息,降低了企业或其他单位大数据分析的成本,实用性强,易于推广。
以上结合附图对本发明的实施方式做出了详细说明,但本发明不局限于所描述的实施方式。对于本领域技术人员而言,在不脱离本发明的原理和精神的情况下,对这些实施方式进行各种变化、修改、替换和变型仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!