一种多维度数据评估差异性的系统和方法与流程
本发明涉及数据分析的技术领域,尤其是涉及一种多维度数据评估差异性的系统和方法。
背景技术:
在数据经济时代,各行各业正以数据为核心,运用数据的特征去重塑自身模式。依据信息技术的新生产模式、交付方式、生活体验和管理决策能力,我国目前已经逐渐形成“数据社会化”的雏形。所谓“数据社会化”,就是数据能够平等地被社会各层面使用,它打破了现实中的物理疆界,渗透到社会每个角落。数据驱动虚拟世界与现实社会之间实现生态交互,让社会资源能够在同一平台上被重新整合、共享、分析,最终实现其社会应用价值。
数据社会化过程中最核心内容就是数据。但数据源头存在的采集场景割裂、最强相关数据稀缺、数据质量不高等种种问题,数据呈现高度离散化状态,数据间联合分析的实例较少,数据具有较强的隔离性,极大阻碍了大数据应用的发展与推进。本文认为造成上述问题主要有两方面原因,一是对个体单元(如自然人、法人、企业、设备等)不同项点(如信用评估、价值评估、违约评估)的评估,缺乏较为统一的理论模型,无法将不同来源、多维度的数据进行有效的统一,二是由于个体单元的数据指标与数据量存在极大不均衡,无法进行等量数据评估;且数据总量越庞大,该不均衡性约明显,因此对传统的基于矢量工具的大样本数据分析方法提出了严峻的挑战。本文针对以上两大问题,提出了一种对所有个体单元进行无差别对待的,评价单一个体数据和整体多维度数据之间差异性的方法,能够用于评价例如个人信用度在社会整体信用度中的偏向性。
技术实现要素:
本发明的其中一个目的是提供一种多维度数据评估差异性的方法。
本发明的上述发明目的是通过以下技术方案得以实现的:一种多维度数据评估差异性的方法,包括:
步骤一、将多维度数据进行归类划分处理;
将多维度数据按照数据来源个体的不同划分一级个体,所有具有共性的一级个体归为同一个二级个体,所有的二级个体整合作为全集;
并将相同个体的不同指标数据做划分,并将所有指标数据根据相应数值在同指标数值中的占比通用化处理形成统一的指标密度;
步骤二、绘制所有二级个体的“二级个体单指标密度曲线”;
步骤三、根据“二级个体单指标密度曲线”绘制所有二级个体的“二级个体多指标曲面”;
步骤四、根据“二级个体多指标曲面”绘制“全集指标基准曲面”;
步骤五、抽取拟合后的“二级个体单指标密度曲线”与“二级个体多指标曲面”的高度关联指标集合;
步骤六、抽取拟合后的“二级个体多指标曲面”与“全集指标基准曲面”上的高度关联指标集合;
步骤七、构建“个体评估指标曲面”;
步骤八、构建“评估指标基准曲面”;
步骤九、评估一级个体数据和全集数据的差异性。
通过采用上述技术方案,对多维度数据进行筛选分析,并评估一级个体数据和全集数据的差异性。
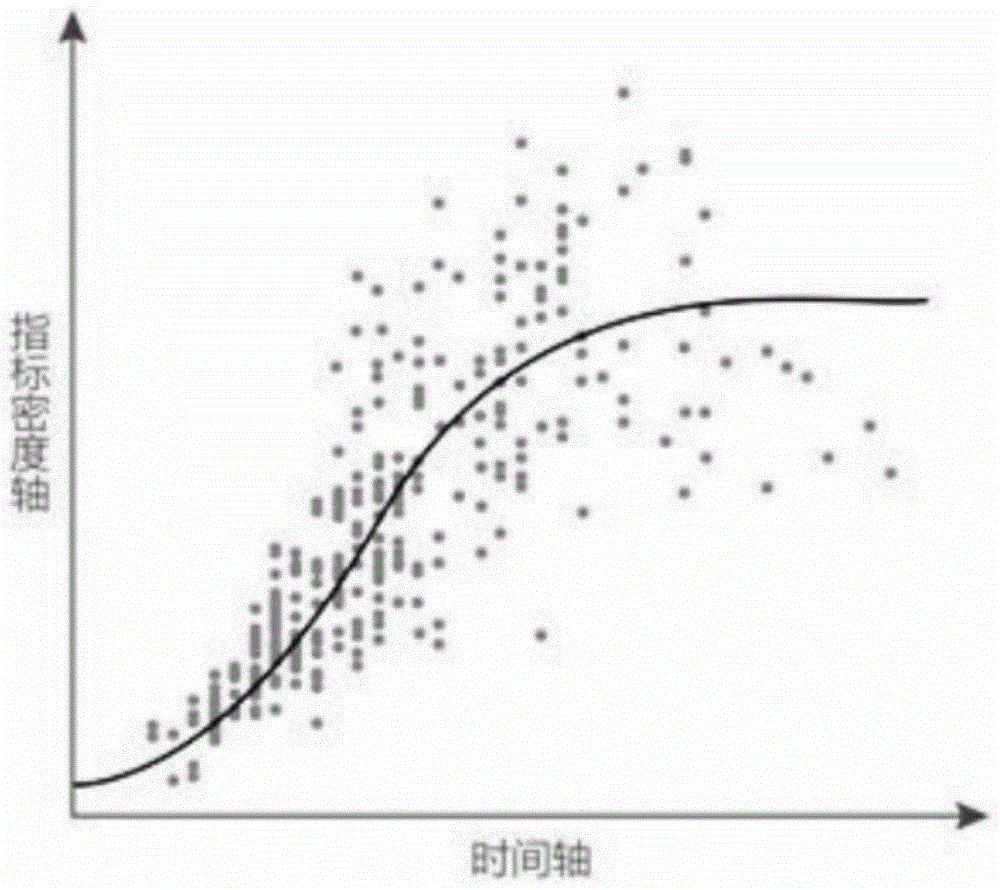
本发明进一步设置为:步骤二中,将相同二级个体内的所有一级个体的同指标数据在“时间——指标密度”的坐标系上集合,利用移动最小二乘法基于点的拟合原理,在离散点之间定义拟合点,划分支持域半径,赋予支持域内各点的权值,使临近点的权值变化逐步衰减,实现了拟合曲线的局部逼近,最终形成“二级个体单指标密度曲线”。
通过采用上述技术方案,得出二级个体的某项指标沿时间线变化的曲线。
本发明进一步设置为:步骤三中,将相同二级个体的所有“二级个体单指标密度曲线”在“时间——指标密度——个体指标类型”的坐标系上集合,将同一个体的所有“个体单指标曲线”通过最小二乘法得到所求的系数,生成拟合方程,代入原始数据得到拟合结果,最终拟合成“二级个体多指标曲面”。
通过采用上述技术方案,计算得到同一个体的不同指标沿时间线综合变化形成的曲面。
本发明进一步设置为:步骤四中,将所有“二级个体多指标曲面”利用最小二乘法,先将拟合区域网格化,然后求出网格点上节点值,最后连接网格节点形成拟合成一条整体曲面,最终形成“全集指标基准曲面”。
通过采用上述技术方案,计算得到全集数据的不同指标沿时间线综合变化形成的曲面。
本发明进一步设置为:步骤五中,将每个“二级个体单指标密度曲线”与“二级个体多指标曲面”相比较,计算每个“二级个体单指标密度曲线”与“二级个体多指标曲面”的偏差度p1,当p1小于等于设定值a1时,则将该“二级个体单指标密度曲线”归入高度关联指标集合m1;当p1大于设定值a1时,则不将该“二级个体单指标密度曲线”归入高度关联指标集合m1。
通过采用上述技术方案,当求得的p1值大于设定值a1时,判断该指标曲线与多指标曲线的关联程度较低,判断个体的该指标为不符合筛选要求的指标,排除该数据,增加计算结果的精确度。
本发明进一步设置为:步骤六中,将每个“二级个体多指标曲面”与“全集指标基准曲面”相比较,计算每个“二级个体多指标曲面”与“全集指标基准曲面”的偏差度p2;当p2小于等于设定值a2时,则将该“二级个体单指标密度曲线”归入高度关联指标集合m2;当p2大于设定值a2时,则不将该“二级个体单指标密度曲线”归入高度关联指标集合m2。
通过采用上述技术方案,当求得的p2值大于设定值a1时,判断该多指标曲面与全集指标基准的关联程度较低,判断该个体为不符合筛选要求的个体,排除该数据,增加计算结果的精确度。
本发明进一步设置为:步骤七中,当m1内的“二级个体单指标密度曲线”所属的二级个体的“二级个体多指标曲面”同时属于m2时,抽取该“二级个体单指标密度曲线”构建“二级个体多指标曲面”的方法,将所有抽取的“二级个体单指标密度曲线”通过最小二乘法拟合成“个体评估指标曲面”。
通过采用上述技术方案,通过筛选后的数据形成每个个体的“个体评估指标曲面”。
本发明进一步设置为:步骤八中,按照“全集指标基准曲面”的构建方式,将所有参与评估的“个体评估指标曲面”通过最小二乘法拟合成“评估指标基准曲面”。
通过采用上述技术方案,通过筛选后的数据形成“评估指标基准曲面”,由于采用的是有效数集,因此结果更精确。
本发明进一步设置为:步骤九中,将一级个体数据和“评估指标基准曲面”对比,计算一级个体的所有指标在时间线上与“评估指标基准曲面”的累积矢量偏差值。
通过采用上述技术方案,计算一级个体数据和全集数据的差异性。
本发明的另一个目的是提供一种多维度数据评估差异性的系统。
本发明的上述发明目的是通过以下技术方案得以实现的:一种多维度评估差异性的系统,包括输入模块、数据统计模块、数据筛选模块、数据分析模块;
输入模块,用于输入需要分析的数据;
数据建模模块,根据相同个体的同一数据随时间发生的变化建立二维模型,并根据同一个体的不同数据建立三维模型;
筛选模块,筛选关联度高的数据;
数据分析模块,将所有个体的高关联度数据进行分析,判断单个个体在整体中的偏向性。
通过采用上述技术方案,通过上述系统与方法对多维度数据进行分析,并评价其中所有单一个体的数据偏向性。
综上所述,本发明的有益技术效果为:
1.可以对多维度数据进行筛选分析,并评估一级个体数据和全集数据的差异性;
2.通过筛选后的数据形成“评估指标基准曲面”,由于采用的是有效数集,因此结果更精确。
附图说明
图1是二级个体单指标密度曲线图;
图2是二级个体多指标曲面图;
图3是全集指标基准曲面图;
图4是个体评估指标曲面图;
图5是评估指标基准曲面图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
一种多维度评估差异性的系统,包括输入模块、数据统计模块、数据筛选模块、数据分析模块。
输入模块,用于输入需要分析的数据。
数据建模模块,根据相同个体的同一数据随时间发生的变化建立二维模型,并根据同一个体的不同数据建立三维模型。
筛选模块,筛选关联度高的数据。
数据分析模块,将所有个体的高关联度数据进行分析,判断单个个体在整体中的偏向性。
一种多维度数据评估差异性的方法,包括:
步骤一、将多维度数据进行归类划分处理;
将多维度数据按照数据来源个体的不同划分一级个体,所有具有共性的一级个体归为同一个二级个体,所有的二级个体整合作为全集。
相同个体的不同指标数据划分为a类数据、b类数据、c类数据……。并将所有指标数据根据相应数值在同指标数值中的占比通用化处理形成统一的指标密度。
步骤二、绘制所有二级个体的单类指标曲线;
将相同二级个体内的所有一级个体的同指标数据在“时间x——指标密度y”的坐标系上集合,如图1所示,利用移动最小二乘法基于点的拟合原理,在离散点之间定义拟合点,划分支持域半径,赋予支持域内各点的权值,使临近点的权值变化逐步衰减,实现了拟合曲线的局部逼近,最终形成“二级个体单指标密度曲线”f。
步骤三、绘制所有二级个体的多指标曲面;
将相同二级个体的所有“二级个体单指标密度曲线”在“时间x——指标密度y——个体指标类型z”的坐标系上集合,如图2所示,将同一个体的所有“个体单指标曲线”通过最小二乘法得到所求的系数,生成拟合方程,代入原始数据得到拟合结果,最终拟合成“二级个体多指标曲面”s。
步骤四、绘制“全集指标基准曲面”;
将所有“二级个体多指标曲面”集合,如图3所示,利用最小二乘法,先将拟合区域网格化,然后求出网格点上节点值,最后连接网格节点形成拟合成一条整体曲面,最终形成“全集指标基准曲面”b。
步骤五、抽取拟合后的“二级个体单指标密度曲线”与“二级个体多指标曲面”的高度关联指标集合;
将每个“二级个体单指标密度曲线”与“二级个体多指标曲面”相比较,计算每个“二级个体单指标密度曲线”与“二级个体多指标曲面”的偏差度:
其中t为数据统计的总时间跨度。
当p1小于等于设定值a1时,则将该“二级个体单指标密度曲线”归入高度关联指标集合m1。
当p1大于设定值a1时,则不将该“二级个体单指标密度曲线”归入高度关联指标集合m1。
步骤六、抽取拟合后的“二级个体多指标曲面”与“全集指标基准曲面”上的高度关联指标集合;
将每个“二级个体多指标曲面”与“全集指标基准曲面”相比较,计算每个“二级个体多指标曲面”与“全集指标基准曲面”的偏差度:
当p2小于等于设定值a2时,则将该“二级个体单指标密度曲线”归入高度关联指标集合m2。
当p2大于设定值a2时,则不将该“二级个体单指标密度曲线”归入高度关联指标集合m2。
步骤七、构建“个体评估指标曲面”;
当m1内的“二级个体单指标密度曲线”所属的二级个体的“二级个体多指标曲面”同时属于m2时,抽取该“二级个体单指标密度曲线”构建“二级个体多指标曲面”的方法,如图4所示,将所有抽取的“二级个体单指标密度曲线”通过最小二乘法拟合成“个体评估指标曲面”s’。
步骤八、构建“评估指标基准曲面”;
如图5所示,按照“全集指标基准曲面”的构建方式,将所有参与评估的“个体评估指标曲面”通过最小二乘法拟合成“评估指标基准曲面”b’。
步骤九、评估一级个体数据和全集数据的差异性;
将一级个体数据和“评估指标基准曲面”对比评估其偏差值。
一级个体的某项指标在某个时间点与“评估指标基准曲面”的矢量偏差值为:
一级个体的某项指标在时间线上与“评估指标基准曲面”的累积矢量偏差值为:
一级个体的所有指标在时间线上与“评估指标基准曲面”的累积矢量偏差值为:
本具体实施方式的实施例均为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!