多解码器全卷积神经网络及其相应的细观结构识别方法与流程
本发明属于陶瓷基复合材料预制体细观结构识别领域,具体涉及一种用于编织陶瓷基复合材料xct切片语义分割的多解码器全卷积神经网络。
背景技术:
陶瓷基复合材料(cmcs)复杂预制体的结构包括2.5d编织、三维四向编织等结构,其结构及预制体的细观组分决定了材料的力学性质及失效机制,在有限元分析模型中尽可能准确的考虑材料的内部真实结构已成为一种趋势。
xct扫描是一种无损检测方法,可以在不破坏材料的基础上准确观测到材料内部的真实细观结构。将扫描出的陶瓷基复合材料预制体的一系列xct切片进行细观结构识别,即识别出预制体的每一种细观结构包括纤维、基体、孔洞。在计算机识别领域,将图片的每一个像素赋予相应类别的技术称为语义分割。语义分割后,得到的图片中不同的颜色代表不同的类别,使得更好地快速了解预制体的内部结构,对复杂预制体准确建立三维模型具有重要意义。
对于2.5d编织结构一些学者通过ostu最大阈值分割法对于2.5的编织结构xct图片进行细观结构,并建立三维模型。如中国专利申请号为“201610838554.8”,发明名称为“一种复合材料细观结构的计算机图像识别技术和三维建模方法”的专利。该方法首先识别2.5d编织结构xct图片基体部分,编号基体部分,利用基体左右对称性对其进行配对,选择基体合适的上下边界点进行边界拟合,基体上下之间的是经纱,左右之间是纬纱。然而,该方法由于对基体的识别采用了对称性,这就使得倘若切片中的基体部分只包括左半部分或者右半部分时,识别算法即失效。并且,其只是适用于2.5d结构,适用范围窄。
对于三维四向编织结构,一些学者根据预先设定的几何参数建立三维编织复合材料单胞理论模型,与经过阈值和去噪处理的xct切片图进行计算比对,更改理论模型的预设值,通过优化算法得到最后的识别效果图。如中国专利申请号为“201810537212.1”,发明名称为“一种复合材料细观结构的计算机图像识别技术和三维建模方法”的专利。然而,在使用阈值分割的识别过程中,xct图片中的不同细观结构的灰度变化范围是很大的,对于每一张切片寻找一个最优的阈值进行分割是困难的。并且,其识别方法只适用在三维结构中。
随着深度学习在物体识别和语义分割方面的成功以及数据集的不断增加,在计算机视觉领域深度学习中的卷积神经网络吸引了越来越多的人进行研究。
语义分割神经网络包括fcn、segnet、u-net等,以上网络均是单解码器全卷积神经网络。其中,fcn和u-net是将深层与浅层的特征通道相连接,segnet是将解码器部分的特征映射与编码器部分最大池化索引相结合来锐化物体边缘,得到具有浅层边缘和深层高级语义信息的特征图。然而,不管是深层与浅层的通道连接的解码器,还是采用池化索引方法的解码器,均会造成不同类型信息的丢失,不能最大保证信息的全面性。实验证明,将以上网络直接应用在陶瓷基复合材料复杂预制体的细观结构识别上得到的准确度是不理想的。
综上,目前的识别算法很多都是适用在某一种或者某一类的编织结构中,适用范围窄。并且,将深度学习卷积神经网络的内容应用在陶瓷基复合材料预制体的识别方面研究未见报道。因此,基于深度学习的陶瓷基复合材料复杂预制体xct切片的语义分割需要进一步研究。
技术实现要素:
本发明针对现有技术中的不足,提供一种多解码器全卷积神经网络用于陶瓷基复合材料预制体xct切片的语义分割,并确定了网络结构的初始化方法、类别平衡、训练方法等,解决了不同解码器带来的特征图中边缘模糊或者内容信息丢失的问题,结合深度学习和语义分割任务提高细观结构识别的准确率,增强算法的鲁棒性。
该多解码器全卷积神经网络可以用于不同编织类型的陶瓷基复合材料预制体,包括2.5维编织、三维四向编织结构等全部类型,适用范围广,识别的细观结构包括纤维束(经纱和纬纱),孔洞,基体。
为实现上述目的,本发明采用以下技术方案:
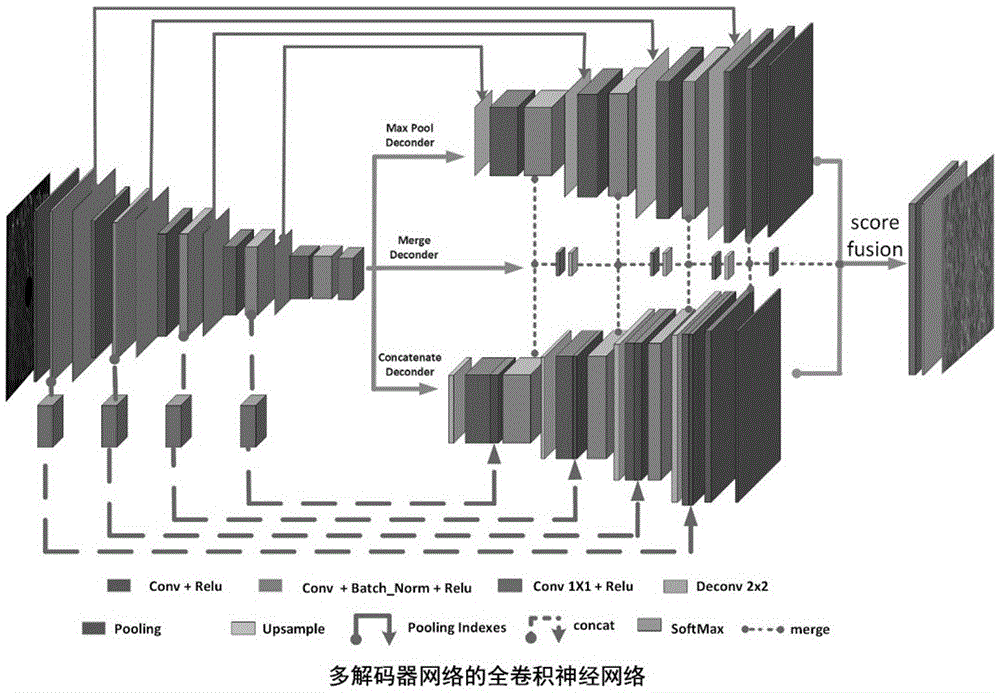
多解码器全卷积神经网络,其特征在于:由一个编码器网络和三个解码器网络组成;
所述编码器网络依次由五个编码器和一个用来压缩特征通道的1x1卷积层构成,前四个编码器均依次由两个卷积层和一个池化层构成,第五个编码器由两个卷积层构成,每个编码器的两个卷积层特征通道数目相同,每个编码器的第一个卷积层之后采用非线性处理,第二个卷积层之后采用批正则化和非线性处理,之后进行最大池化来缩小图片分辨率;
所述三个解码器网络分别为:最大池化索引解码器网络、通道连接解码器网络、通道融合解码器网络;
所述最大池化索引解码器网络依次由四个最大池化索引解码器构成,每个最大池化索引解码器均依次由一个上采样层和两个卷积层构成,每个最大池化索引解码器的两个卷积层特征通道不同;首先采用双线性上采样放大图片,并将编码器网络在池化过程中得到的池化索引与索引值赋予上采样特征通道的对应位置;在前三个最大池化索引解码器中,每个最大池化索引解码器第一个卷积层的数据来自于前一层上采样层得到的特征通道,之后采用非线性处理,第二个卷积层之后采用批正则化以及非线性处理;其中,第四个最大池化索引解码器卷积层之后仅采用非线性处理,其他操作与前三个最大池化索引解码器相同;
所述通道连接解码器网络依次由四个通道连接解码器构成,每个通道连接解码器均依次由一个反卷积层和两个卷积层构成,每个通道连接解码器的两个卷积层特征通道数目相同,与前四个编码器对称;首先采用反卷积放大图片,每个通道连接解码器第一个卷积层的数据来自于反卷积层放大后的特征通道以及编码器网络对称位置的特征通道,且来自编码器的特征通道使用1x1卷积进行通道压缩,然后将两者特征通道进行连接,并采用非线性处理;在前三个通道连接解码器中,每一个通道连接解码器最后一个卷积层采用批正则化和非线性处理;其中,第四个通道连接解码器卷积层之后仅采用非线性处理,其他操作与前三个通道连接解码器相同;
所述通道融合解码器网络依次由四个通道融合解码器构成,前三个通道融合解码器均依次由一个卷积层和一个反卷积层构成,第四个通道融合解码器由一个卷积层组成,每个卷积层和反卷积层之后均采用非线性处理,每个通道融合解码器的数据由每个最大池化索引解码器和每个通道连接解码器的最后一个卷积层特征通道融合而成,即对应通道相加,并采用1x1卷积将通道压缩为要分类的细观结构数目,然后和上一个通道融合解码器得到的特征通道相加。
同时,本发明还提出了基于如上所述的多解码器全卷积神经网络的语义分割的陶瓷基复合材料预制体的细观结构识别方法,其特征在于,包括以下步骤:
步骤一、构造用于训练陶瓷基复合材料的xct图像数据集;
步骤二、对于语义分割数据集进行数据增强的预处理,使得图像数据集更加全面;
步骤三、使用不同的网络对不同编织结构的预制体进行语义分割;
步骤四、建立用于陶瓷基复合材料预制体语义分割的多解码器全卷积神经网络的网络模型,进行调试,确保模型可以正常运行;
步骤五、按照上述网络模型,在caffe神经网络框架中,构建多解码器全卷积神经网络;
步骤六、使用adam随机梯度算法对多解码器全卷积神经网络进行训练,使用msra方法对神经网络的权重进行初始化,使用constant方法对神经网络的的偏置值进行初始化,训练完成后得到权重文件;
步骤七、根据每个像素的细观结构概率确定对应像素的类别,最后得到完整的语义分割图。
为优化上述技术方案,采取的具体措施还包括:
进一步地,所述步骤一中,采集一系列的陶瓷基复合材料复杂预制体的xct切片和真值图,构造用于训练多解码器全卷积神经网络的语义分割数据集。
进一步地,所述步骤二中,数据增强预处理方式具体包括裁剪、缩放、旋转、亮度变化以及对比度增强。
进一步地,所述步骤三中,不同编织结构包括2.5d编织结构、三维四向编织结构。
进一步地,所述步骤五中,训练次数设定为30k次。
本发明的有益效果是:
1、通过联合最大池化索引解码器、通道连接解码器、通道融合解码器三者,充分地运用了浅层的低级边缘信息和深层的语义信息,实现对陶瓷基复合材料预制体的xct切片进行语义分割,并提高了单解码器的准确率。
2、通过采用深度学习的全卷积神经网络并构建陶瓷基复合材料的标签数据集,此方法可以适用于多种类别的陶瓷基复合材料复杂预制体的细观结构识别,适用范围广,可靠性好,节省人力物力财力。同时为复杂预制体的三维建模提供了准确的内部细观结构数据。
3、通过选择性的使用批正则化技术,尽可能保证卷积之后特征图的原分布状态,一定程度上降低了误分辨率。
附图说明
图1是多解码器全卷积神经网络的整体网络结构图。
图2a是多解码器全卷积神经网络用于2.5d编织结构预制体的识别过程图。
图2b是多解码器全卷积神经网络用于三维四向编织结构预制体的识别过程图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
如图1所示,本发明提出一种多解码器全卷积神经网络和基于该网络的语义分割的陶瓷基复合材料预制体的细观结构识别方法,包括以下步骤:
一、构造用于训练陶瓷基复合材料的xct图像数据集。
采集一系列的陶瓷基复合材料复杂预制体的xct切片和真值图,构造用于训练多解码器全卷积深度网络的语义分割数据集q。
二、对于语义分割数据集进行数据增强的预处理,使得图像数据集更加全面。
数据增强预处理方式具体包括裁剪、缩放、旋转、亮度变化以及对比度增强。
三、使用不同的网络对不同编织结构的预制体进行语义分割。
由于不同编织结构具有不同的细观结构。例如对于纤维束来说,2.5d的纤维束分为经纱和纬纱,而三维四向却只有纤维束。此外,由于2.5d的xct切片灰度相差很大,通用一个多编码器全卷积神经网络会降低预测果的准确性,因此每一种编织结构使用一个多编码器全卷积神经网络。
四、建立用于陶瓷基复合材料预制体语义分割的多解码器全卷积神经网络的网络模型,进行调试,确保模型可以正常运行,整个网络的训练在rtx2080显卡上进行。此网络由一个编码器网络和三个解码器网络组成。
如表1所示,编码器网络由五个编码器(共十个卷积层),一个用来压缩通道的1x1卷积层以及四个池化层构成。每个编码器由两个卷积层构成,且这两个卷积层特征通道数目相同。每个编码器的第一个卷积层之后采用非线性处理relumax(x,0),第二个卷积层之后采用批正则化以及非线性处理relumax(x,0),之后进行最大池化来缩小图片分辨率,池化窗口2x2,步长为2,即长和宽都变为原来的1/2。在这五个编码器中,前两个编码器卷积层核大小分别为7x7,5x5,步长为1,补白分别为3、2,通道数目为64、96;后三个编码器的核大小为3x3,步长为1,补白为1,通道为128,256,512;第11个卷积层的核大小是1x1,目的在于压缩特征通道为256,这是因为在第四次最大池化时,得到的池化索引信息将会与最大池化索引解码器网络的第一个最大池化索引解码器进行对应,然而第五个编码器的特征通道增加为512,导致特征通道和最大池化索引通道数目不符,所以需要对其进行通道压缩。补白的作用在于保持特征图的尺寸不变,仅在池化或者上采样或者反卷积时发生图片尺寸的倍数变化。步长是指每次移动卷积核的像素距离。
表1编码器结构
多解码器神经网络中的解码器包括三部分:最大池化索引解码器,通道连接解码器,通道融合解码器。
如表2所示,最大池化索引解码器网络由四个最大池化索引解码器组成,共八个卷积层以及四个上采样层组成,其中,卷积核大小均为3x3,步长为1,补白为1。每个最大池化索引解码器依次由一个上采样层和两个卷积层构成,两个卷积层特征通道分别为256、128,128、96,96、64,64、64,每个最大池化索引解码器的两个卷积层特征通道的不同是因为最大池化索引都与上一个编码器的特征通道相同。首先采用双线性上采样放大图片,即长和宽每次都变为原来的2倍,并将编码器网络在池化过程中得到的池化索引与索引值赋予上采样的对应位置。前三个最大池化索引解码器中,第一个卷积层的数据来自于前一层上采样层得到的特征通道,之后采用非线性处理relumax(x,0),第二个卷积层之后采用批正则化以及非线性处理relumax(x,0)。其中,第四个最大池化索引解码器的卷积层之后仅采用非线性处理,其他操作与前三个最大池化索引解码器相同。
表2最大池化索引解码器网络结构
如表3所示,通道连接解码器网络由四个通道连接解码器,共四个反卷积层和八个卷积层构成,其中,卷积层核大小均为3x3,步长为1,补白为1;反卷积核大小为2x2,步长为2,用于放大图片。每个通道连接解码器依次由一个反卷积层和两个卷积层构成,且这两个卷积层特征通道数目相同,其特征通道分别为256,128,96,64,与编码器网络对称。首先采用反卷积放大图片,即长和宽每次放大原来的2倍,步长为2,核大小为2x2;每个通道连接解码器第一个卷积层的数据来自反卷积层放大后的的特征通道以及编码器网络对称位置的特征通道,且来自编码器的特征通道使用1x1卷积进行通道压缩变为原来的为1/4,减小了参数量,将两者特征通道进行连接,其特征通道分别为576,160,120,并采用非线性处理relumax(x,0);前三个通道连接解码器中,最后一个卷积层采用批正则化和非线性处理。最后一个通道连接解码器的卷积层后仅采用非线性处理,通道连接后的特征通道为80,其他操作与前三个通道连接解码器相同。
表3通道连接解码器网络结构
如表4所示,通道融合解码器网络由三个通道融合解码器组成,共四个1x1卷积层和三个反卷积层,前三个通道融合解码器均依次由一个卷积层和一个反卷积层构成,第四个通道融合解码器由一个卷积层组成,每个卷积层和反卷积层之后均采用非线性处理relumax(x,0)。每个通道融合解码器的数据由每个最大池化索引解码器和每个通道连接解码器的最后一个卷积层特征通道融合而成,即对应通道相加(即与通道融合解码器序号相同的最大池化索引解码器和通道连接解码器),并采用1x1卷积将通道压缩为要分类的细观结构数目,然后和上一个(从第二个开始)通道融合解码器得到的特征通道相加。
表4通道融合解码器网络结构
对卷积层交叉采用批正则化,是因为每一次批正则化操作都会改变原有卷积后的数据分布规律,造成语义分割的结果图产生小范围不连续的现象。然而,其确实可以加快全卷积神经网络的训练速度。
在以上三个解码器得到的特征尺寸与原图片大小相同后,对最大池化索引解码器和通道连接解码器的特征通道分别进行1x1卷积通道压缩,变为要分类的细观结构数目,并将三个解码器的特征数目叠加,得到三倍数目的细观结构特征通道,再次使用1x1卷积压缩特征通道为要分类的细观结构数目。最终分类结构如表5所示。
表5最终分类结构
使用交叉熵损失函数计算神经网络的损失,使用softmax对特征通道进行分类。
卷积层使用msra方式进行权重的初始化,偏置的初始化使用constant。补白操作在于每次卷积处理后图片的大小不变。
五、按照上述在caffe神经网络框架中,构建多解码器全卷积神经网络。
六、使用adam随机梯度算法对上述网络进行训练,使用msra方法对神经网络进行初始化,训练次数设定为30k次,训练完成后得到权重文件。
七、根据每个像素的细观结构概率确定对应像素的类别,最后得到完整的语义分割图。
接下来结合图2a、2b具体说明多解码器全卷积神经网络用于2.5d、三维四向编织结构xct图片的识别过程。
1、建立用于训练多解码器全卷积神经网络的xct图像数据集。构造不同编织结构的语义分割xct切片数据集,包括2.5d、三维四向编织结构预制体的xct切片图和真值图,数据集增强后图片50k张,三维四向编织30k张,30k张,设定测试集1k张,2.5d、三维四向均为0.5张。
2、由于不同编织结构具有不同的细观结构,2.5d存在经纱和纬纱,而三维四向却只有纤维束。此外,由于2.5d和的xct切片灰度相差很大,通用一个多编码器全卷积神经网络会降低预测果的准确性,因此每一种编织结构使用一个多编码器全卷积神经网络。
3、在训练中,使用类别平衡法,即通过以下方式计算每类的频率:设总图片数目为num,每张图片尺寸为m*n,某一类图片存在于num_class张图片中,在整个数据集中基体的像素总数为num_pixel:
1)确定类别数目;
4)median_frequency为所有类数的中位数,真值图的灰度值是从0开始的。
4、卷积层权重的初始化使用“msra”方法,偏置的初始化使用“constant”方法,确定激活函数为relu,池化过程为最大池化,损失函数为交叉熵损失函数,上采样为双线性插值上采样。
5、按照发明内容的多解码器全卷积神经网络建立多编码器网络模型,进行调试,确保模型可正常运行。
6、使用adam随机梯度算法对上述网络进行训练,训练次数设定为30k次,训练完成后得到权重文件。
7、选择特定的文件夹,用于储存生成的权值文件。
8、制作用于训练和验证的文本文件,训练文本文件中包括了训练集的图片路径,验证文本文件中包括了验证图片的路径。
9、神经网络训练完成后,选择特定的文件夹,对验证集图片进行语义分割,保存在上述文件夹中。
10、在训练过程完成后,读取特定文件夹的带预测图片进行语义分割,得到预测的图片,并输出到特定的文件夹,此时图片还是灰度图。采用编写的程序,将预测得到的灰度图变为rgb彩色图片,更直观地观察预制体的细观结构。
11、在得到语义分割的预测图之后,使用miou来对多编码器全卷积神经网络进行性能评价。如果结果证明存在过拟合或者欠拟合存在,则调节训练策略,使得性能达到最优。
本发明通过建立多解码器全卷积神经网络对陶瓷基复合材料不同复杂预制体进行细观结构识别,最后可以充分利用卷积网络浅层的边缘信息和深层的语义信息,避免了由于语义鸿沟造成的分割准确率不高的缺点。采用深度学习的全卷积神经网络并构建陶瓷基复合材料的标签数据集,适用于多种类别的陶瓷基复合材料复杂预制体的细观结构识别,同时为复杂预制体的三维建模提供了准确的内部细观结构数据。
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!