一种面向多核图像处理卷积神经网络的数据读取方法与流程
本发明涉及计算机领域,尤其涉及一种面向多核图像处理卷积神经网络的数据读取方法。
背景技术:
卷积神经网络(convolutionalneuralnetwork,cnn)是一种前馈神经网络,与传统的bp神经网络相比,具有识别效率高、旋转缩放不变性好等优点,已在数字图像处理及人脸识别等各个领域得到了广泛的应用。
传统卷积神经网络一般由多个交替的卷积层、池化层以及最后的全连接层组成。卷积神经网络可通过反向传播方法将网络损失传递到网络的所有层。参数更新学习过程通过随机梯度下降算法来实现。卷积神经网络与传统神经网络最大的区别在于,其卷积层采用了一种权值共享局部连接网络,而不是传统的权值独立全连接网络,这使得在层数相同的情况下,卷积神经网络的连接数目要远少于传统神经网络。卷积层的二维数据结构使得卷积神经网络非常适合于处理图像数据信息。此外,池化层的加入使得卷积神经网络对输入数据的几何变化(平移、缩放、旋转等)具有一定程度的稳健性。卷积神经网络由于其强大的数据特征提取能力和非线性学习能力,在性能上超越了大多数传统的机器视觉算法。目前在图像分类、目标识别等研究和应用领域,卷积神经网络已经成为主流方法。
目前常用的卷积神经网络由于计算量特别巨大,一般均采用多个乘累加器(mau)并发运行的方式来降低网络的计算时间。而要为这些mau同时提供计算所需的数据,对系统的总线带宽也提出了很大的挑战。
另一方面,用于图像处理的卷积神经网络的卷积核用到的均为二维甚至三维的数据结构,直接从系统的内存(例如,ddr)中读取这些地址不连续的数据对系统内存的利用率也会产生极大的影响。
技术实现要素:
针对现有技术中存在的上述问题,本发明提出一种数据读取方法,在满足mau计算需求的前提下,将对系统内存的访问大大降低。
根据本发明的一个方面,提供一种数据读取方法,包括:
a)接收卷积计算参数,所述卷积计算参数包括图像尺寸、通道数、卷积核尺寸kxk、和/或步长;
b)确定图像的每行数据切分的次数及最后一次剩余数据的长度,使得切分后的图像块每次产生m次卷积计算所需的数据;
c)根据所确定的切分后的图像块宽度进行图像切分,对于图像块的第一通道,读入切分后的图像块的前k行数据,将其存入数据缓存单元中;
d)读出数据缓存单元中存放的第一行图像数据,然后扩展前m次卷积计算内的所有第一个通道的第一行的数据,共产生m*k个数据;
e)将数据缓存单元中存放的第二行至第k行的图像数据读出并扩展;
f)对于第二通道至最后一个通道,重复步骤c)和步骤e);
g)数据读取单元回到第一通道并读入下一行的数据,覆盖缓存中第一通道中编号最靠前的一行的数据,对数据缓存单元中存储的更新的k行的数据执行步骤d)和步骤e);
h)对于第二通道至最后一个通道,重复步骤g);
i)重复步骤g)和步骤h),直至完成图像块的最后一行。
在本发明的一个实施例中,切分后的图像块的宽度在m到m+k-1之间。
在本发明的一个实施例中,相邻图像块的数据之间有若干像素的重叠。
在本发明的一个实施例中,该数据读取方法还包括:j)判断是否还存在未处理的图像块,如果不存在未处理的图像块,则数据读取操作结束;
如果存在未处理的图像块,则将未处理的图像块作为当前图像块,返回当前图像块的第一通道,读入图像块的前k行数据,将其存入数据缓存单元中,重复步骤步骤d)至步骤g)。
在本发明的一个实施例中,根据卷积核尺寸、图像尺寸、系统的总线位宽及内存等参数确定每次连续产生的卷积计算的次数m。
在本发明的一个实施例中,所述数据扩展及输出单元将扩展后的数据以k倍读入带宽的速度被送至后级的mau。
在本发明的一个实施例中,将当前图像块的全部通道的k行数据存储在数据缓存单元中。
在本发明的一个实施例中,当最后一个图像块的宽度不足m时,则最后一个图像块的行数据一次读到行尾。
在本发明的一个实施例中,该数据读取方法还包括:在进行图像切分之前,在输入图像周围一圈填充宽度为(k-1)/2且值为0的数据。
本发明公开的系统和方法可以充分利用卷积神经网络中相邻卷积核中重复的数据,将对系统内存的访问量降到理论最低值,从而降低了对卷积神经网络对系统带宽的要求。
本发明公开的系统和方法可以充分利用系统对连续地址突发读操作的低延时特性。提高了系统带宽的利用率。
本发明公开的系统和方法采用了切分图像的方法,使得缓存空间的大小与图像的尺寸无关,降低了系统对片上缓存的尺寸要求。
本发明公开的系统和方法优先产生每次卷积计算的所有数据,使得后续的mau每次卷积计算过程中只需结果输出一次最终结果,降低了mau计算过程中存储中间结果所需的缓存空间或系统带宽。
附图说明
为了进一步阐明本发明的各实施例的以上和其它优点和特征,将参考附图来呈现本发明的各实施例的更具体的描述。可以理解,这些附图只描绘本发明的典型实施例,因此将不被认为是对其范围的限制。在附图中,为了清楚明了,相同或相应的部件将用相同或类似的标记表示。
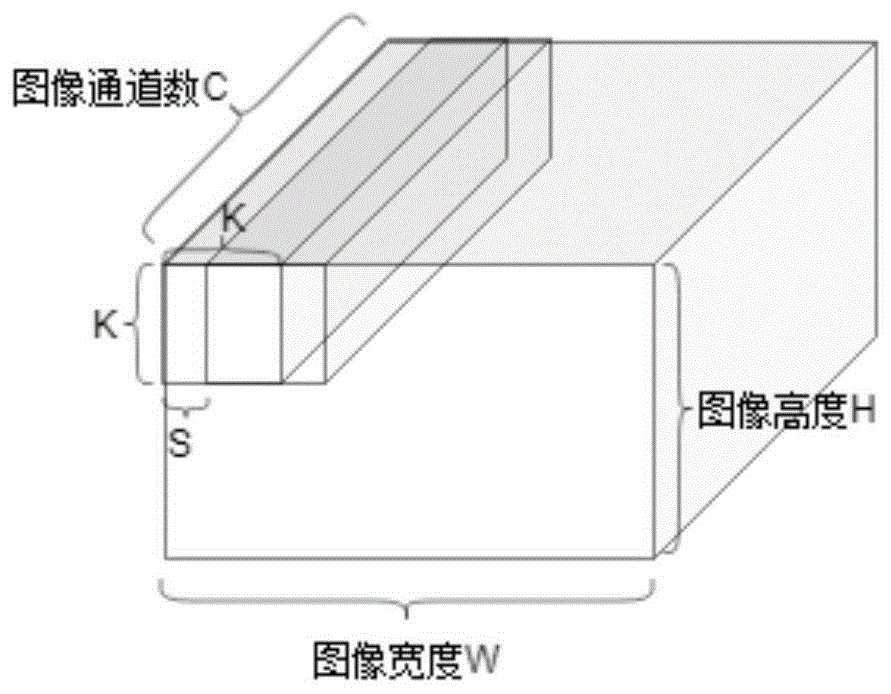
图1示出了根据本发明的卷积网络输入数据各参数的关系示意图。
图2示出根据本发明的一个实施例的数据读取系统200的示意框图。
图3示出根据本发明的一个实施例的数据读取方法的流程图。
图4示出了根据本发明的一个示例的卷积网络输入数据各参数的关系示意图。
图5示出根据本发明的一个实施例的数据扩展及输出单元的结构示意图。
图6示出根据本发明的一个实施例的步骤305中缓存的状态示意图。
图7示出根据本发明的一个实施例的步骤306中缓存的状态示意图。
具体实施方式
在以下的描述中,参考各实施例对本发明进行描述。然而,本领域的技术人员将认识到可在没有一个或多个特定细节的情况下或者与其它替换和/或附加方法、材料或组件一起实施各实施例。在其它情形中,未示出或未详细描述公知的结构、材料或操作以免使本发明的各实施例的诸方面晦涩。类似地,为了解释的目的,阐述了特定数量、材料和配置,以便提供对本发明的实施例的全面理解。然而,本发明可在没有特定细节的情况下实施。此外,应理解附图中示出的各实施例是说明性表示且不一定按比例绘制。
在本说明书中,对“一个实施例”或“该实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。在本说明书各处中出现的短语“在一个实施例中”并不一定全部指代同一实施例。
需要说明的是,本发明的实施例以特定顺序对步骤进行描述,然而这只是为了方便区分各步骤,而并不是限定各步骤的先后顺序,在本发明的不同实施例中,可根据具体的流程的调节来调整各步骤的先后顺序。
卷积计算可看作是加权求和的过程,将图像区域中的每个像素分别与滤波器(即,权矩阵)的每个元素对应相乘,所有乘积之和作为区域中心像素的新值。
滤波器是卷积时使用到的权,用一个矩阵表示,该矩阵与对应的图像区域大小相同,其行、列都是奇数,是一个权矩阵。
假设输入数据的参数为:图像宽度w(像素数),图像高度h(像素数),图像通道数c,卷积核尺寸为kxk,步长为s=1。图1示出了根据本发明的卷积网络输入数据各参数的示意图。完成所有计算需要wxh次卷积计算(每行w次卷积,共h行),这里,为了维持输出图像尺寸不变,需要在输入图像周围一圈填充宽度为(k-1)/2且值为0的数据。而每次卷积需要的数据量为kxkxc。因此所有卷积计算需要的总数据量(不包含权重数据)为wxhxkxkxc=k2xhxwxc。可见,由于相邻卷积核间的数据会重复使用,使得总数据量远远超过了实际的输入图像数据(hxwxc)。
另一方面,输入图像数据的地址是一般是沿行方向连续递增的。每个卷积计算在换行或者换通道时数据的地址会发生较大范围的跳变,这对常用的系统内存访问(例如,ddr)是非常不友好的,会产生较长的读延时从而导致系统的整体性能下降。
图2示出根据本发明的一个实施例的数据读取系统200的示意框图。如图2所示,低缓存占用的图像处理卷积神经网络的数据读取系统包括配置单元210、数据读取单元220、数据缓存单元230、数据扩展及输出单元240。
配置单元210接收上层模块传来的图像及卷积核参数信息。这些参数信息可包括图像在系统存储空间中的地址,图像的尺寸,卷积核的尺寸等。配置单元根据这些参数和系统的特性确定每行数据切分的次数及最后一次剩余数据的长度,使得每个切分后的图像块可以产生m次卷积计算所需的数据。
数据读取单元220对于宽度较大的图像进行切分,使得每个切分后的图像块可以产生m次卷积计算所需的数据。每个切分后的图像块的宽度在m到m+k-1之间,由切分后的图像块的位置而决定。然后,按行读入切分后图像。m可以根据系统的总线位宽及内存的特性而改变,目的是使得每次读入的连续地址的数据长度可以充分利用系统内存的突发读取能力,抵消切换地址带来的读延时开销。
数据读取单元220读入的数据将先暂存在数据缓存单元230中,并供数据扩展及输出单元240使用。由于纵向相邻的卷积核会有部分数据重复,数据缓存单元可以降低这部分数据对系统总线的占用。
数据扩展及输出单元240将横向的数据扩展成卷积核所需要的数据,并输出给mau供卷积计算使用。由于横向相邻的卷积核也有部分数据重复,这里可以利用数据的重复性增大内部带宽,从而提高数据到mau上的吞吐率。
下面结合具体图像示例及图3详细描述根据本发明的数据读取系统的操作过程。图3示出根据本发明的一个实施例的数据读取方法的流程图。
假设输入图像为224x224,通道数为16,卷积核尺寸为3x3,步长为1。每次连续产生m=128次卷积计算所需的数据,各个参数关系如图4所示。
首先,在步骤301,接收卷积计算参数。可由系统处理器(cpu)将卷积计算参数写入配置单元。这些卷积计算参数信息可包括图像在系统存储空间中的地址、图像的尺寸、卷积核的尺寸、步长等。配置单元确定每行数据切分的次数及最后一次剩余数据的长度,使得每个切分后的图像块可以产生m次卷积计算所需的数据。每个切分后的图像块的宽度在m到m+k-1之间,由切分后的图像块的位置而决定。m可以根据系统的总线位宽及内存的特性而改变,目的是使得每次读入的连续地址的数据长度可以充分利用系统内存的突发读取能力,抵消切换地址带来的读延时开销。
例如,在本示例中,为了产生128次卷积计算所需的数据,第一次切分出的图像宽度为m+1=129。剩余宽度不足128,则一直读到行尾。
在步骤302,由数据读取单元根据所确定的切分后的图像块宽度进行图像切分,并读入切分后的图像块的前k行数据,将其存入数据缓存单元中。通过对图像进行切分,改变数据读入顺序,对于较宽的图像不再是简单的从左边一直读到右边。数据缓存空间的大小与图像的尺寸无关,降低了系统对片上缓存的尺寸要求。
例如,在本示例中,数据读取单元首先读入前k=3行数据每行读入m+1=129个,并存入数据缓存单元中。
在步骤303,数据扩展及输出单元读出缓存中存放的第一行图像数据,然后扩展前m次卷积计算内的所有第一个通道的第一行的数据,共产生m*k个数据。扩展后的数据以k倍读入带宽的速度被送至后级的mau。
例如,在本示例中,数据扩展及输出单元读出缓存中存放的第一行的129个数据,然后扩展前m=128次卷积计算内的所有第一个通道的第一行的数据,共产生m*k=128*3个数据。扩展的方法如图5所示。图5示出根据本发明的一个实施例的数据扩展及输出单元的结构示意图。这些数据可以以3倍读入带宽的速度被送至后级的mau。数据扩展模块的结构示意图如图5所示。为了便于图示,在图5中示出4个数据输出接口,本领域的技术人员应该意识到数据接口的数量不限于4个。数据接口的数量一般可由内部带宽决定。例如,当系统带宽是128位且每个数据为8位时,输出接口就是16组,每组宽度为3个数据24位。
在步骤304,重复步骤303,将第二行至第k行的数据读出并扩展。至此,前m次卷积计算内的第一通道的所有kxk数据均已生成。
例如,在本示例中,将第二行和第三行的数据读出并扩展,至此,前m=128次卷积计算内的第一通道的所有3x3个数据均已生成。
在步骤305,对于第二通道至最后一个通道,重复步骤302至步骤304。至此,前m次卷积计算内的第二通道至最后一个通道的所有kxk数据均已生成。此时缓存的状态如图6所示。如图6所示,数据缓存单元存储切分后的图像块的第一通道至最后一个通道的第一行至第k行数据。
在步骤306,数据读取单元回到第一通道并读入下一行的数据,覆盖缓存中第一通道中编号最靠前的一行的数据。例如,在本示例中,数据读取单元读入第四行的数据,将第一通道第一行的数据覆盖,如图7所示。
在步骤307,数据扩展及输出单元读出缓存中存放的更新的k行的数据并扩展。其扩展和输出方法类似于步骤303至304。
例如,在本示例中,数据扩展及输出单元读出缓存中存放的第二、三、四行的数据并扩展,作为第二行的前128次卷积计算所需的第一通道的数据。
在步骤308,对于第二通道至最后一个通道,重复步骤306至步骤307。至此,第二行数据的前m次卷积计算内的第二通道至最后一个通道的所有kxk数据均已生成。
在步骤309,重复步骤306至步骤308,直至完成图像的最后一行。产生的图像所有行的前m次卷积计算所需的数据。
在步骤310,判断是否还存在未处理的图像块。如果不存在未处理的图像块,则数据读取操作结束。
如果存在,将未处理的图像块作为当前图像块,在步骤311,回到第一个通道第一行,向数据缓存单元读入当前图像块的前k行数据,其中当前图像块与前一图像块有若干像素的重叠。例如,在本示例中,因为第一通道第一行的第129次卷积计算需要用到第128个点,所以,需要重复读入第128个点和第129个点的数据。
在步骤312,数据扩展及输出单元读出缓存中存放的k行的数据并扩展。其扩展和输出方法类似于步骤303至304。例如,在本示例中,从数据缓存单元中读出前3行每行第128到第224个点的数据并扩展,产生第一行的第129到第224次卷积计算所需的第一通道的数据。
在步骤313,对第二通道到最后一个通道,重复步骤311至步骤312。例如,在本示例中,产生第一行第129~224次卷积所需的所有数据。
在步骤314,对当前图像块的其余数据行,重复步骤306-308。例如,在本示例中,得出每行第129~224次卷积计算所需的所有数据,然后返回步骤310。
上述实施例以3*3的卷积核为例,本领域的技术人员应该意识到,卷积核还可以使其它尺寸,并且本领域的技术人员可以根据卷积核尺寸、图像尺寸、系统的总线位宽及内存等参数确定每次连续产生的卷积计算的次数、图像切分尺寸。
本发明公开的系统和方法可以充分利用卷积神经网络中相邻卷积核中重复的数据,将对系统内存的访问量降到理论最低值,从而降低了对卷积神经网络对系统带宽的要求。
本发明公开的系统和方法可以充分利用系统对连续地址突发读操作的低延时特性。提高了系统带宽的利用率。
本发明公开的系统和方法采用了切分图像的方法,使得缓存空间的大小与图像的尺寸无关,降低了系统对片上缓存的尺寸要求。
本发明公开的系统和方法优先产生每次卷积计算的所有数据,使得后续的mau每次卷积计算过程中只需结果输出一次最终结果,降低了mau计算过程中存储中间结果所需的缓存空间或系统带宽。
尽管上文描述了本发明的各实施例,但是,应该理解,它们只是作为示例来呈现的,而不作为限制。对于相关领域的技术人员显而易见的是,可以对其做出各种组合、变型和改变而不背离本发明的精神和范围。因此,此处所公开的本发明的宽度和范围不应被上述所公开的示例性实施例所限制,而应当仅根据所附权利要求书及其等同替换来定义。
- 还没有人留言评论。精彩留言会获得点赞!