基于参数共享深度学习网络的立体图像视觉显著提取方法与流程
本发明涉及一种图像视觉显著提取技术,尤其是涉及一种基于参数共享深度学习网络的立体图像视觉显著提取方法。
背景技术:
图像显著性检测是一种搜索图像中更重要区域的技术,其大多数用于图像预处理阶段寻找优先处理的图像部分,是一种对人类视觉机制进行模仿的仿生学机制。立体视觉显著性检测是对图像显著性检测的拓展,其面临的问题主要在于如何应用额外的深度信息来辅助显著性检测。
经典的利用手工特征进行立体视觉显著性检测的方法在利用深度信息时直接利用滤波等方法进行深度特征的提取,如齐峰等人提出的立体视觉显著性检测方法。该方法首先将输入的彩色图像转换为cielab图像;然后构建颜色特征、纹理特征和深度特征,颜色特征是直接通过输入的彩色图像获得的,纹理特征是通过取亮度通道的边沿得到的,深度特征是对深度信息进行归一化得到的;再通过对不同特征进行log-gabor滤波后线性融合得到视觉显著图。该类方法虽然可以快速地得到具有一定质量的视觉显著图,但由于输入的特征有限,因此对视觉显著性的区分能力有限,无法应对复杂的场景。
技术实现要素:
本发明所要解决的技术问题是提供一种基于参数共享深度学习网络的立体图像视觉显著提取方法,其提取的立体视觉特征符合显著语义,且其具有较强的提取稳定性和较高的提取准确性。
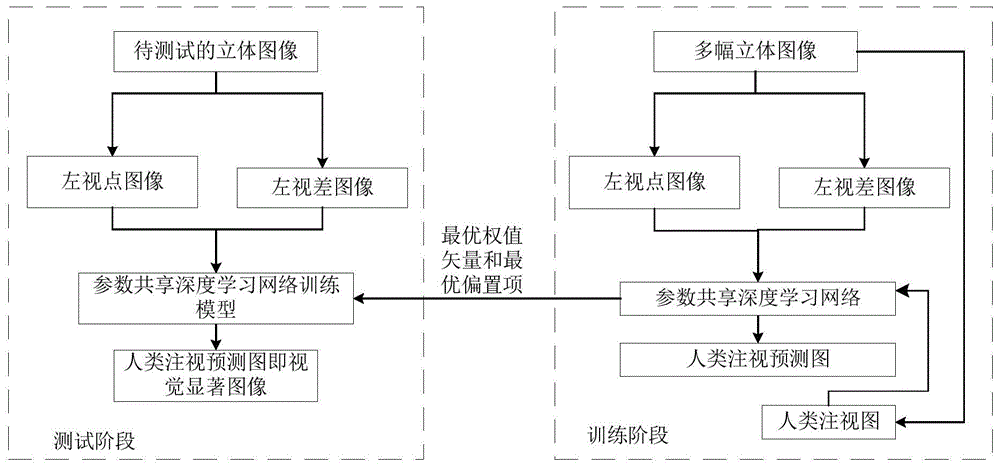
本发明解决上述技术问题所采用的技术方案为:一种基于参数共享深度学习网络的立体图像视觉显著提取方法,其特征在于包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取n幅宽度为r且高度为l的立体图像,将第n幅立体图像的左视点图像、左视差图像和人类注视图对应记为{il,n(x,y)}、{id,n(x,y)}和{if,n(x,y)};再将每幅立体图像的左视点图像缩放到480×640像素尺寸,得到每幅立体图像的左视点图像对应的480×640像素尺寸图像,将{il,n(x,y)}对应的480×640像素尺寸图像记为{il,n(x480,y640)};并将每幅立体图像的左视差图像缩放到480×640像素尺寸,得到每幅立体图像的左视差图像对应的480×640像素尺寸图像,将{id,n(x,y)}对应的480×640像素尺寸图像记为{id,n(x480,y640)};将每幅立体图像的人类注视图缩放到30×40像素尺寸,得到每幅立体图像的人类注视图对应的30×40像素尺寸图像,将{if,n(x,y)}对应的30×40像素尺寸图像记为{if,n(x30,y40)};其中,n为正整数,n≥100,n为正整数,n的初始值为1,1≤n≤n,1≤x≤r,1≤y≤l,il,n(x,y)表示{il,n(x,y)}中坐标位置为(x,y)的像素点的像素值,id,n(x,y)表示{id,n(x,y)}中坐标位置为(x,y)的像素点的像素值,if,n(x,y)表示{if,n(x,y)}中坐标位置为(x,y)的像素点的像素值,1≤x480≤480,1≤y640≤640,il,n(x480,y640)表示{il,n(x480,y640)}中坐标位置为(x480,y640)的像素点的像素值,id,n(x480,y640)表示{id,n(x480,y640)}中坐标位置为(x480,y640)的像素点的像素值,1≤x30≤30,1≤y40≤40,if,n(x30,y40)表示{if,n(x30,y40)}中坐标位置为(x30,y40)的像素点的像素值;
步骤1_2:构建参数共享深度学习网络:参数共享深度学习网络包括输入层、参数共享特征提取框架、显著图生成框架;输入层由彩色图输入层和视差图输入层组成;参数共享特征提取框架由resnet-50网络中的第1块resnet-50卷积网络块、第2块resnet-50卷积网络块、第3块resnet-50卷积网络块、第4块resnet-50卷积网络块、第5块resnet-50卷积网络块依次设置组成;显著图生成框架由连接层和卷积层组成,其中,卷积层的卷积核大小为(3,3)、卷积步长为(1,1)、卷积核数目为1、激活函数为relu函数;
在输入层中,对于彩色图输入层,彩色图输入层的输入端接收一幅输入立体图像的左视点图像对应的480×640像素尺寸图像,彩色图输入层的输出端输出左视点图像对应的480×640像素尺寸图像给参数共享特征提取框架;对于视差图输入层,视差图输入层的输入端接收一幅输入立体图像的左视差图像对应的480×640像素尺寸图像,视差图输入层的输出端输出左视差图像对应的480×640像素尺寸图像给参数共享特征提取框架;其中,要求输入立体图像的宽度为r且高度为l;
在参数共享特征提取框架中,在参数共享的前提下,第1块resnet-50卷积网络块的输入端接收彩色图输入层的输出端输出的左视点图像对应的480×640像素尺寸图像,同时接收视差图输入层的输出端输出的左视差图像对应的480×640像素尺寸图像;第1块resnet-50卷积网络块的输出端输出与左视点图像相应的64幅特征图,同时输出与左视差图像相应的64幅特征图,将输出的与左视点图像相应的64幅特征图构成的集合记为vl,1,将输出的与左视差图像相应的64幅特征图构成的集合记为vd,1;其中,vl,1和vd,1中的特征图的宽度均为480且高度均为640;
在参数共享的前提下,第2块resnet-50卷积网络块的输入端接收vl,1中的所有特征图,同时接收vd,1中的所有特征图;第2块resnet-50卷积网络块的输出端输出与左视点图像相应的256幅特征图,同时输出与左视差图像相应的256幅特征图,将输出的与左视点图像相应的256幅特征图构成的集合记为vl,2,将输出的与左视差图像相应的256幅特征图构成的集合记为vd,2;其中,vl,2和vd,2中的特征图的宽度均为240且高度均为320;
在参数共享的前提下,第3块resnet-50卷积网络块的输入端接收vl,2中的所有特征图,同时接收vd,2中的所有特征图;第3块resnet-50卷积网络块的输出端输出与左视点图像相应的512幅特征图,同时输出与左视差图像相应的512幅特征图,将输出的与左视点图像相应的512幅特征图构成的集合记为vl,3,将输出的与左视差图像相应的512幅特征图构成的集合记为vd,3;其中,vl,3和vd,3中的特征图的宽度均为120且高度均为160;
在参数共享的前提下,第4块resnet-50卷积网络块的输入端接收vl,3中的所有特征图,同时接收vd,3中的所有特征图;第4块resnet-50卷积网络块的输出端输出与左视点图像相应的1024幅特征图,同时输出与左视差图像相应的1024幅特征图,将输出的与左视点图像相应的1024幅特征图构成的集合记为vl,4,将输出的与左视差图像相应的1024幅特征图构成的集合记为vd,4;其中,vl,4和vd,4中的特征图的宽度均为60且高度均为80;
在参数共享的前提下,第5块resnet-50卷积网络块的输入端接收vl,4中的所有特征图,同时接收vd,4中的所有特征图;第5块resnet-50卷积网络块的输出端输出与左视点图像相应的2048幅特征图,同时输出与左视差图像相应的2048幅特征图,将输出的与左视点图像相应的2048幅特征图构成的集合记为vl,5,将输出的与左视差图像相应的2048幅特征图构成的集合记为vd,5;其中,vl,5和vd,5中的特征图的宽度均为30且高度均为40;
在显著图生成框架中,连接层的输入端接收vl,5中的所有特征图和vd,5中的所有特征图,连接层的输出端输出4096幅特征图;卷积层的输入端接收连接层的输出端输出的所有特征图,卷积层的输出端输出1幅特征图,该幅特征图即为输入立体图像的人类注视预测图;其中,连接层的输出端输出的特征图的宽度均为30且高度均为40,人类注视预测图的宽度为30且高度为40;
步骤1_3:将步骤1_1中选取的每幅立体图像作为输入立体图像,将每幅输入立体图像的人类注视图对应的30×40像素尺寸图像作为监督,将每幅输入立体图像的左视点图像对应的480×640像素尺寸图像及左视差图像对应的480×640像素尺寸图像输入到参数共享深度学习网络中进行训练,得到每幅输入立体图像的人类注视预测图;
步骤1_4:重复执行步骤1_3共m次,得到参数共享深度学习网络训练模型及其最优权值矢量和最优偏置项;其中,m为正整数,m>1;
所述的测试阶段过程的具体步骤为:
步骤2_1:令{itest(x',y')}表示待测试的立体图像,将{itest(x',y')}的左视点图像和左视差图像对应记为{itest,l(x',y')}和{itest,d(x',y')};再将{itest,l(x',y')}缩放到480×640像素尺寸,得到{itest,l(x',y')}对应的480×640像素尺寸图像,记为{itest,l(x'480,y'640)};并将{itest,d(x',y')}缩放到480×640像素尺寸,得到{itest,d(x',y')}对应的480×640像素尺寸图像,记为{itest,d(x'480,y'640)};其中,1≤x'≤r',1≤y'≤l',r'表示{itest(x',y')}的宽度,l'表示{itest(x',y')}的高度,itest(x',y')表示{itest(x',y')}中坐标位置为(x',y')的像素点的像素值,itest,l(x',y')表示{itest,l(x',y')}中坐标位置为(x',y')的像素点的像素值,itest,d(x',y')表示{itest,d(x',y')}中坐标位置为(x',y')的像素点的像素值,1≤x'480≤480,1≤y'640≤640,itest,l(x'480,y'640)表示{itest,l(x'480,y'640)}中坐标位置为(x'480,y'640)的像素点的像素值,itest,d(x'480,y'640)表示{itest,d(x'480,y'640)}中坐标位置为(x'480,y'640)的像素点的像素值;
步骤2_2:将{itest,l(x'480,y'640)}和{itest,d(x'480,y'640)}输入到参数共享深度学习网络训练模型中,并利用最优权值矢量和最优偏置项进行预测,得到{itest(x',y')}的人类注视预测图即视觉显著图像,记为{itest,f(x'30,y'40)};其中,1≤x'30≤30,1≤y'40≤40,itest,f(x'30,y'40)表示{itest,f(x'30,y'40)}中坐标位置为(x'30,y'40)的像素点的像素值。
所述的步骤1_2中,第1块resnet-50卷积网络块由依次设置的卷积层和标准化层组成,卷积层的卷积核大小为(7,7)、卷积步长为(1,1)、卷积核数目为64、激活函数为relu函数;卷积层的输入端接收彩色图输入层的输出端输出的左视点图像对应的480×640像素尺寸图像或视差图输入层的输出端输出的左视差图像对应的480×640像素尺寸图像,卷积层的输出端输出64幅特征图,标准化层的输入端接收卷积层的输出端输出的所有特征图,标准化层的输出端输出与左视点图像相应的64幅特征图或与左视差图像相应的64幅特征图,标准化层的输出端输出的与左视点图像相应的64幅特征图构成的集合为vl,1、与左视差图像相应的64幅特征图构成的集合为vd,1;
第2块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,1或vd,1,降尺寸卷积子块的输出端输出256幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出256幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出与左视点图像相应的256幅特征图或与左视差图像相应的256幅特征图,第2块等尺寸卷积子块的输出端输出的与左视点图像相应的256幅特征图构成的集合为vl,2、与左视差图像相应的256幅特征图构成的集合为vd,2;
第3块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,2或vd,2,降尺寸卷积子块的输出端输出512幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出512幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出512幅特征图,第3块等尺寸卷积子块的输入端接收第2块等尺寸卷积子块的输出端输出的所有特征图,第3块等尺寸卷积子块的输出端输出与左视点图像相应的512幅特征图或与左视差图像相应的512幅特征图,第3块等尺寸卷积子块的输出端输出的与左视点图像相应的512幅特征图构成的集合为vl,3、与左视差图像相应的512幅特征图构成的集合为vd,3;
第4块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块、第4块等尺寸卷积子块、第5块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,3或vd,3,降尺寸卷积子块的输出端输出1024幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出1024幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出1024幅特征图,第3块等尺寸卷积子块的输入端接收第2块等尺寸卷积子块的输出端输出的所有特征图,第3块等尺寸卷积子块的输出端输出1024幅特征图,第4块等尺寸卷积子块的输入端接收第3块等尺寸卷积子块的输出端输出的所有特征图,第4块等尺寸卷积子块的输出端输出1024幅特征图,第5块等尺寸卷积子块的输入端接收第4块等尺寸卷积子块的输出端输出的所有特征图,第5块等尺寸卷积子块的输出端输出与左视点图像相应的1024幅特征图或与左视差图像相应的1024幅特征图,第5块等尺寸卷积子块的输出端输出的与左视点图像相应的1024幅特征图构成的集合为vl,4、与左视差图像相应的1024幅特征图构成的集合为vd,4;
第5块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,4或vd,4,降尺寸卷积子块的输出端输出2048幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出2048幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出与左视点图像相应的2048幅特征图或与左视差图像相应的2048幅特征图,第2块等尺寸卷积子块的输出端输出的与左视点图像相应的2048幅特征图构成的集合为vl,5、与左视差图像相应的2048幅特征图构成的集合为vd,5。
与现有技术相比,本发明的优点在于:
1)本发明方法在训练阶段构建了一个参数共享深度学习网络,其包括参数共享特征提取框架,使得彩色图特征与视差图特征的提取使用相同的参数,大量的减少了参数量,并有效的减少了储存开销。
2)本发明方法中的参数共享特征提取框架由resnet-50网络中的第1块resnet-50卷积网络块、第2块resnet-50卷积网络块、第3块resnet-50卷积网络块、第4块resnet-50卷积网络块、第5块resnet-50卷积网络块依次设置组成,利用5块resnet-50卷积网络块能够更充分地提取出彩色图特征与视差图特征,从而提升了利用参数共享深度学习网络训练模型预测的人类注视预测图即视觉显著图像的预测准确度。
3)本发明方法是一种端到端的深度学习方法,在训练阶段可以便捷地训练得到参数共享深度学习网络训练模型。
4)本发明方法提取的立体视觉特征符合显著语义,且其具有较强的提取稳定性。
附图说明
图1为本发明方法的总体流程框图;
图2为本发明方法构建的参数共享深度学习网络的组成结构示意图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于参数共享深度学习网络的立体图像视觉显著提取方法,其总体流程框图如图1所示,其特征在于包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取n幅宽度为r且高度为l的立体图像,将第n幅立体图像的左视点图像、左视差图像和人类注视图对应记为{il,n(x,y)}、{id,n(x,y)}和{if,n(x,y)};再将每幅立体图像的左视点图像缩放到480×640像素尺寸,得到每幅立体图像的左视点图像对应的480×640像素尺寸图像,将{il,n(x,y)}对应的480×640像素尺寸图像记为{il,n(x480,y640)};并将每幅立体图像的左视差图像缩放到480×640像素尺寸,得到每幅立体图像的左视差图像对应的480×640像素尺寸图像,将{id,n(x,y)}对应的480×640像素尺寸图像记为{id,n(x480,y640)};将每幅立体图像的人类注视图缩放到30×40像素尺寸,得到每幅立体图像的人类注视图对应的30×40像素尺寸图像,将{if,n(x,y)}对应的30×40像素尺寸图像记为{if,n(x30,y40)};其中,n为正整数,n≥100,如取n=1000,n为正整数,n的初始值为1,1≤n≤n,1≤x≤r,1≤y≤l,il,n(x,y)表示{il,n(x,y)}中坐标位置为(x,y)的像素点的像素值,id,n(x,y)表示{id,n(x,y)}中坐标位置为(x,y)的像素点的像素值,if,n(x,y)表示{if,n(x,y)}中坐标位置为(x,y)的像素点的像素值,1≤x480≤480,1≤y640≤640,il,n(x480,y640)表示{il,n(x480,y640)}中坐标位置为(x480,y640)的像素点的像素值,id,n(x480,y640)表示{id,n(x480,y640)}中坐标位置为(x480,y640)的像素点的像素值,1≤x30≤30,1≤y40≤40,if,n(x30,y40)表示{if,n(x30,y40)}中坐标位置为(x30,y40)的像素点的像素值;在此,可在中国台湾省交通大学提供的三维人眼跟踪数据库(3deye-trackingdatabase)中选取立体图像,并将选取的所有立体图像的左视点图像、左视差图像和人类注视图构成训练集。
步骤1_2:构建参数共享深度学习网络:如图2所示,参数共享深度学习网络包括输入层、参数共享特征提取框架、显著图生成框架;输入层由彩色图输入层和视差图输入层组成;参数共享特征提取框架由resnet-50网络中的第1块resnet-50卷积网络块、第2块resnet-50卷积网络块、第3块resnet-50卷积网络块、第4块resnet-50卷积网络块、第5块resnet-50卷积网络块依次设置组成,在resnet-50网络中,第1块resnet-50卷积网络块、第2块resnet-50卷积网络块、第3块resnet-50卷积网络块、第4块resnet-50卷积网络块、第5块resnet-50卷积网络块均是特定的网络块,各自的内部组成结构是确定的;显著图生成框架由连接层和卷积层组成,其中,卷积层的卷积核大小为(3,3)、卷积步长为(1,1)、卷积核数目为1、激活函数为relu函数。
在输入层中,对于彩色图输入层,彩色图输入层的输入端接收一幅输入立体图像的左视点图像对应的480×640像素尺寸图像,彩色图输入层的输出端输出左视点图像对应的480×640像素尺寸图像给参数共享特征提取框架;对于视差图输入层,视差图输入层的输入端接收一幅输入立体图像的左视差图像对应的480×640像素尺寸图像,视差图输入层的输出端输出左视差图像对应的480×640像素尺寸图像给参数共享特征提取框架;其中,要求输入立体图像的宽度为r且高度为l。
在参数共享特征提取框架中,在参数共享的前提下,第1块resnet-50卷积网络块的输入端接收彩色图输入层的输出端输出的左视点图像对应的480×640像素尺寸图像,同时接收视差图输入层的输出端输出的左视差图像对应的480×640像素尺寸图像;第1块resnet-50卷积网络块的输出端输出与左视点图像相应的64幅特征图,同时输出与左视差图像相应的64幅特征图,将输出的与左视点图像相应的64幅特征图构成的集合记为vl,1,将输出的与左视差图像相应的64幅特征图构成的集合记为vd,1;其中,vl,1和vd,1中的特征图的宽度均为480且高度均为640。
在参数共享的前提下,第2块resnet-50卷积网络块的输入端接收vl,1中的所有特征图,同时接收vd,1中的所有特征图;第2块resnet-50卷积网络块的输出端输出与左视点图像相应的256幅特征图,同时输出与左视差图像相应的256幅特征图,将输出的与左视点图像相应的256幅特征图构成的集合记为vl,2,将输出的与左视差图像相应的256幅特征图构成的集合记为vd,2;其中,vl,2和vd,2中的特征图的宽度均为240且高度均为320。
在参数共享的前提下,第3块resnet-50卷积网络块的输入端接收vl,2中的所有特征图,同时接收vd,2中的所有特征图;第3块resnet-50卷积网络块的输出端输出与左视点图像相应的512幅特征图,同时输出与左视差图像相应的512幅特征图,将输出的与左视点图像相应的512幅特征图构成的集合记为vl,3,将输出的与左视差图像相应的512幅特征图构成的集合记为vd,3;其中,vl,3和vd,3中的特征图的宽度均为120且高度均为160。
在参数共享的前提下,第4块resnet-50卷积网络块的输入端接收vl,3中的所有特征图,同时接收vd,3中的所有特征图;第4块resnet-50卷积网络块的输出端输出与左视点图像相应的1024幅特征图,同时输出与左视差图像相应的1024幅特征图,将输出的与左视点图像相应的1024幅特征图构成的集合记为vl,4,将输出的与左视差图像相应的1024幅特征图构成的集合记为vd,4;其中,vl,4和vd,4中的特征图的宽度均为60且高度均为80。
在参数共享的前提下,第5块resnet-50卷积网络块的输入端接收vl,4中的所有特征图,同时接收vd,4中的所有特征图;第5块resnet-50卷积网络块的输出端输出与左视点图像相应的2048幅特征图,同时输出与左视差图像相应的2048幅特征图,将输出的与左视点图像相应的2048幅特征图构成的集合记为vl,5,将输出的与左视差图像相应的2048幅特征图构成的集合记为vd,5;其中,vl,5和vd,5中的特征图的宽度均为30且高度均为40。
在显著图生成框架中,连接层的输入端接收vl,5中的所有特征图和vd,5中的所有特征图,连接层的输出端输出4096幅特征图;卷积层的输入端接收连接层的输出端输出的所有特征图,卷积层的输出端输出1幅特征图,该幅特征图即为输入立体图像的人类注视预测图;其中,连接层的输出端输出的特征图的宽度均为30且高度均为40,人类注视预测图的宽度为30且高度为40。
在本实施例中,步骤1_2中,第1块resnet-50卷积网络块由依次设置的卷积层和标准化层组成,卷积层的卷积核大小为(7,7)、卷积步长为(1,1)、卷积核数目为64、激活函数为relu函数;卷积层的输入端接收彩色图输入层的输出端输出的左视点图像对应的480×640像素尺寸图像或视差图输入层的输出端输出的左视差图像对应的480×640像素尺寸图像,卷积层的输出端输出64幅特征图,标准化层的输入端接收卷积层的输出端输出的所有特征图,标准化层的输出端输出与左视点图像相应的64幅特征图或与左视差图像相应的64幅特征图,标准化层的输出端输出的与左视点图像相应的64幅特征图构成的集合为vl,1、与左视差图像相应的64幅特征图构成的集合为vd,1。
在本实施例中,步骤1_2中,第2块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,1或vd,1,降尺寸卷积子块的输出端输出256幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出256幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出与左视点图像相应的256幅特征图或与左视差图像相应的256幅特征图,第2块等尺寸卷积子块的输出端输出的与左视点图像相应的256幅特征图构成的集合为vl,2、与左视差图像相应的256幅特征图构成的集合为vd,2。在此,降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块的参数采用默认值。
在本实施例中,步骤1_2中,第3块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,2或vd,2,降尺寸卷积子块的输出端输出512幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出512幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出512幅特征图,第3块等尺寸卷积子块的输入端接收第2块等尺寸卷积子块的输出端输出的所有特征图,第3块等尺寸卷积子块的输出端输出与左视点图像相应的512幅特征图或与左视差图像相应的512幅特征图,第3块等尺寸卷积子块的输出端输出的与左视点图像相应的512幅特征图构成的集合为vl,3、与左视差图像相应的512幅特征图构成的集合为vd,3。在此,降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块的参数采用默认值。
在本实施例中,步骤1_2中,第4块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块、第4块等尺寸卷积子块、第5块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,3或vd,3,降尺寸卷积子块的输出端输出1024幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出1024幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出1024幅特征图,第3块等尺寸卷积子块的输入端接收第2块等尺寸卷积子块的输出端输出的所有特征图,第3块等尺寸卷积子块的输出端输出1024幅特征图,第4块等尺寸卷积子块的输入端接收第3块等尺寸卷积子块的输出端输出的所有特征图,第4块等尺寸卷积子块的输出端输出1024幅特征图,第5块等尺寸卷积子块的输入端接收第4块等尺寸卷积子块的输出端输出的所有特征图,第5块等尺寸卷积子块的输出端输出与左视点图像相应的1024幅特征图或与左视差图像相应的1024幅特征图,第5块等尺寸卷积子块的输出端输出的与左视点图像相应的1024幅特征图构成的集合为vl,4、与左视差图像相应的1024幅特征图构成的集合为vd,4。在此,降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块、第3块等尺寸卷积子块、第4块等尺寸卷积子块、第5块等尺寸卷积子块的参数采用默认值。
在本实施例中,步骤1_2中,第5块resnet-50卷积网络块由依次设置的降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块组成;降尺寸卷积子块的输入端接收vl,4或vd,4,降尺寸卷积子块的输出端输出2048幅特征图,第1块等尺寸卷积子块的输入端接收降尺寸卷积子块的输出端输出的所有特征图,第1块等尺寸卷积子块的输出端输出2048幅特征图,第2块等尺寸卷积子块的输入端接收第1块等尺寸卷积子块的输出端输出的所有特征图,第2块等尺寸卷积子块的输出端输出与左视点图像相应的2048幅特征图或与左视差图像相应的2048幅特征图,第2块等尺寸卷积子块的输出端输出的与左视点图像相应的2048幅特征图构成的集合为vl,5、与左视差图像相应的2048幅特征图构成的集合为vd,5。在此,降尺寸卷积子块、第1块等尺寸卷积子块、第2块等尺寸卷积子块的参数采用默认值。
步骤1_3:将步骤1_1中选取的每幅立体图像作为输入立体图像,将每幅输入立体图像的人类注视图对应的30×40像素尺寸图像作为监督,将每幅输入立体图像的左视点图像对应的480×640像素尺寸图像及左视差图像对应的480×640像素尺寸图像输入到参数共享深度学习网络中进行训练,得到每幅输入立体图像的人类注视预测图。
步骤1_4:重复执行步骤1_3共m次,得到参数共享深度学习网络训练模型及其最优权值矢量和最优偏置项;其中,m为正整数,m>1,在本实施例中取m=20。
所述的测试阶段过程的具体步骤为:
步骤2_1:令{itest(x',y')}表示待测试的立体图像,将{itest(x',y')}的左视点图像和左视差图像对应记为{itest,l(x',y')}和{itest,d(x',y')};再将{itest,l(x',y')}缩放到480×640像素尺寸,得到{itest,l(x',y')}对应的480×640像素尺寸图像,记为{itest,l(x'480,y'640)};并将{itest,d(x',y')}缩放到480×640像素尺寸,得到{itest,d(x',y')}对应的480×640像素尺寸图像,记为{itest,d(x'480,y'640)};其中,1≤x'≤r',1≤y'≤l',r'表示{itest(x',y')}的宽度,l'表示{itest(x',y')}的高度,itest(x',y')表示{itest(x',y')}中坐标位置为(x',y')的像素点的像素值,itest,l(x',y')表示{itest,l(x',y')}中坐标位置为(x',y')的像素点的像素值,itest,d(x',y')表示{itest,d(x',y')}中坐标位置为(x',y')的像素点的像素值,1≤x'480≤480,1≤y'640≤640,itest,l(x'480,y'640)表示{itest,l(x'480,y'640)}中坐标位置为(x'480,y'640)的像素点的像素值,itest,d(x'480,y'640)表示{itest,d(x'480,y'640)}中坐标位置为(x'480,y'640)的像素点的像素值。
步骤2_2:将{itest,l(x'480,y'640)}和{itest,d(x'480,y'640)}输入到参数共享深度学习网络训练模型中,并利用最优权值矢量和最优偏置项进行预测,得到{itest(x',y')}的人类注视预测图即视觉显著图像,记为{itest,f(x'30,y'40)};其中,1≤x'30≤30,1≤y'40≤40,itest,f(x'30,y'40)表示{itest,f(x'30,y'40)}中坐标位置为(x'30,y'40)的像素点的像素值。
为了验证本发明方法的可行性和有效性,进行实验。
在此,采用中国台湾省交通大学提供的三维人眼跟踪数据库(3deye-trackingdatabase)来分析本发明方法的准确性和稳定性。这里,利用评估视觉显著提取方法的3个常用客观参量作为评价指标,即pearson相关系数(pearsonlinearcorrelationcoefficient,plcc)、kullback-leibler散度系数(kullback-leiblerdivergence,kld)、auc参数(theareaunderthereceiveroperatingcharacteristicscurve,auc)。
利用本发明方法获取中国台湾省交通大学提供的三维人眼跟踪数据库中的每幅立体图像的人类注视预测图即视觉显著图像,并与三维人眼跟踪数据库中的每幅立体图像的主观视觉显著图像即人类注视图(三维人眼跟踪数据库中存在)进行比较,plcc和auc值越高、kld值越低说明本发明方法提取的视觉显著图像与主观视觉显著图像的一致性越好。反映本发明方法的视觉显著提取性能的plcc、kld和auc相关指标如表1所列。从表1所列的数据可知,按本发明方法提取得到的视觉显著图像与主观视觉显著图像的准确性和稳定性是很好的,表明客观提取结果与人眼主观感知的结果较为一致,足以说明本发明方法的可行性和有效性。
表1利用本发明方法提取得到的视觉显著图像与主观视觉显著图像的准确性和稳
定性
- 还没有人留言评论。精彩留言会获得点赞!