一种基于时空数据的用户多兴趣点多结果识别的方法与流程
本发明涉及一种用户多兴趣点多结果识别的方法,具体是一种基于时空数据的用户多兴趣点多结果识别的方法,属于数据挖掘技术领域。
背景技术:
现代生活中,自驾出行已经成为了人们最重要的交通手段之一。随着车载智能设备与智能手机的发展,越来越多的设备具备卫星定位能力,使得记录行车轨迹成为可能。
现有技术中存在的基于是通过采集用户全时段的数据进行相关判断,随着用户对隐私的重视,全时段的数据越来越难采集。一方面会长时间采用用户的gps数据,另一方面是需要客户的数据量大,隐私信息也多。并且现有技术中,还没有可以商业化的用行程数据直接挖掘家庭工作地址的方法。
技术实现要素:
本发明的目的在于提供一种基于时空数据的用户多兴趣点多结果识别的方法,该方法能够避免长时间采集用户gps数据,需要的数据量少,需要的用户隐私信息也少。
为实现上述目的,本发明提供如下技术方案:一种基于时空数据的用户多兴趣点多结果识别的方法,包括以下步骤:
1)错误数据过滤与重排序;
2)dbscan聚类;
3)聚类结果判断;
4)第一大类循环计算与结果标记(mhwa-loop1);
5)第二大类循环计算与结果标记(mhwa-loop2);
6)特征合并计算与建模结果输出(mhwa-model3)。
作为本发明进一步的技术方案:所述时空数据是用户完整的行程数据,包含用户的每一条历史行程信息,每一条历史行程中包含较精确的起点经纬度、起点gps时间、终点经纬度、终点gps时间,时间精确至年月日时分秒。
作为本发明进一步的技术方案:所述步骤1)中,对用户潜在错误行程数据过滤包含但不限于对总行程数较少的用户进行过滤和对出现逆序的行程进行重排序。因总行程数较少而被过滤掉的用户不进行任何后续步骤,以减少流量和计算成本。
作为本发明进一步的技术方案:所述步骤2)中,进行dbscan聚类是用现有的dbscan算法对用户的终点进行聚类,找出可用于地址挖掘的潜在家庭或工作地址类和类中心的经纬度坐标。
作为本发明进一步的技术方案:所述步骤3)中,根据聚类后的结果进行聚类判断,根据各类计算出来的总停留时间,类间距离等条件,对于聚类数大于等于2的用户进行判断,满足条件则进行本发明中的后续步骤;
作为本发明进一步的技术方案:所述步骤4)中,对总停留时间排名第一的类计算相关变量,从第二类开始循环对比计算并输出判断条件;若满足相应的条件,则将此类标记为1(默认标记为0),依次计算所有的类。
作为本发明进一步的技术方案:所述步骤5)中,在第一次循环后的类中找到标志为0的类,若找不到则放弃判断。对标记为0的类的总停留时间排名第一的类计算相关变量,从第二类开始循环对比计算并输出判断条件;若满足相应的条件,则将此类标记为2(默认标记为0),依次计算所有的类。
作为本发明进一步的技术方案:所述步骤6)中,使用特征合并计算与建模结果输出(mhwa-model)时,对标志为1和2的类,分别计算用于建模的特征变量,输入预训练的逻辑回归模型中,输出概率。
作为本发明进一步的技术方案:所述步骤6)中,根据计算得出的潜在工作地和潜在家庭地概率进行如下判断:若潜在家庭地概率大于一定阈值,则判定该大类下的所有小类为家庭地址;若潜在工作地址概率大于一定阈值,则判定该大类下的所有小类为工作地址;若两个潜在地址概率均小于一定阈值,则放弃判断。
与现有技术相比,本发明的有益效果是:本发明仅通过行程数据就能挖掘出大部分用户的家庭工作地址;通过对主要兴趣点的dbscan聚类挖掘出用户的主要兴趣点作为潜在家庭工作地址。本发明对于所有没达到聚类条件的用户进行过滤,减少流量和计算成本。本发明通过精准的计算相关变量和特征判断,提高识别精度。本发明通过对多个聚类进行循环计算及特征合并建立逻辑回归模型,根据模型输出的概率,判断其是家庭或工作地址。
附图说明
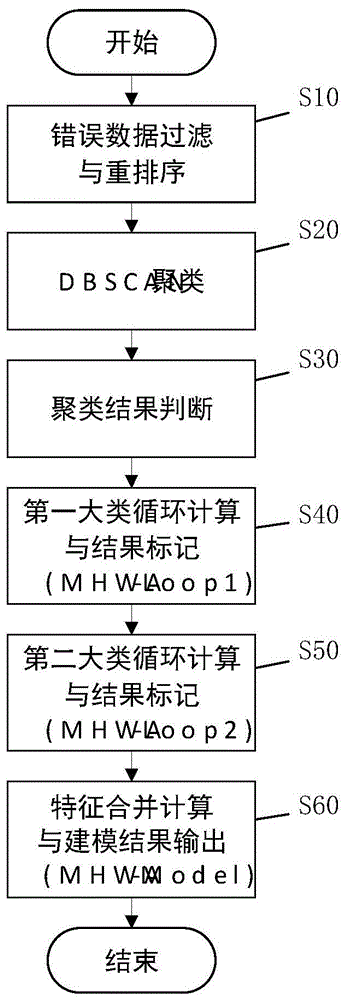
图1为本发明实施例1中实施用行程挖掘多个家庭或工作地址的方法的流程示意图;
图2为本发明实施例1中聚类结果判断的流程示意图;
图3为本发明实施例1中第一大类循环计算与结果标记(mhwa-loop1)流程示意图;
图4为本发明实施例1中第二大类循环计算与结果标记(mhwa-loop2)流程示意图;
图5为本发明实施例1中特征合并计算与建模结果输出(mhwa-model)流程示意图。
具体实施方式
下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于时空数据的用户多兴趣点多结果识别的方法,包括以下步骤:
1)错误数据过滤与重排序;
2)dbscan聚类;
3)聚类结果判断;
4)第一大类循环计算与结果标记;
5)第二大类循环计算与结果标记;
6)特征合并计算与建模结果输出。
所述时空数据是用户完整的行程数据,包含用户的每一条历史行程信息,每一条历史行程中包含较精确的起点经纬度、起点gps时间、终点经纬度、终点gps时间,时间精确至年月日时分秒。
所述步骤1)中,对用户潜在错误行程数据过滤包含但不限于对总行程数较少的用户进行过滤和对出现逆序的行程进行重排序。
所述步骤2)中,进行dbscan聚类是用现有的dbscan算法对用户的终点进行聚类,找出可用于地址挖掘的潜在家庭或工作地址类和类中心的经纬度坐标。
所述步骤3)中,根据聚类后的结果进行聚类判断,对于聚类数大于等于2的用户计算相关特征,并进行判断能否进入到后续步骤中。
所述步骤4)中,对总停留时间排名第一的类计算相关变量,从第二类开始循环对比计算并输出判断条件;若满足相应的条件,则将此类标记为1,默认标记为0,依次计算所有的类。
所述步骤5)中,在第一次循环后的类中找到标志为0的类,若找不到则放弃判断;对标记为0的类的总停留时间排名第一的类计算相关变量,从第二类开始循环对比计算并输出判断条件;若满足相应的条件,则将此类标记为2,依次计算所有的类。
所述步骤6)中,使用特征合并计算与建模结果输出时,对标志为1和2的类,分别计算用于建模的特征变量,输入预训练的逻辑回归模型中,输出概率。
所述步骤6)中,计算得出的潜在工作地和潜在家庭地概率进行如下判断:若潜在家庭地概率大于一定阈值,则判定该大类下的所有小类为家庭地址;若潜在工作地址概率大于一定阈值,则判定该大类下的所有小类为工作地址;若两个潜在地址概率均小于一定阈值,则放弃判断。
实施例1
请参阅图1,本发明实施例中,一种基于时空数据的用户多兴趣点多结果识别的方法,包括以下步骤:
步骤s10,错误数据过滤与重排序。
在本实施例中,针对输入的用户行程数据进行粗过滤和整理,包括去除由于gps定位精度的原因造成里程偏差过大的数据、去除上传时间异常的数据、去除经纬度不在中国范围内的数据等等。为防止用户行程数据出现逆序,既第n+1条行程的开始时间早于第n条行程,需要用户数据按照行程开始时间进行排序。若用户总行程数量小于5条,则不进行后续步骤,放弃判断。
步骤s20,dbscan聚类。
在本实施例中,直接使用现有的dbscan方法对用户过去3个月的所有行程的终点进行聚类,设定的聚类半径阈值为r,聚类范围内最少点数阈值为c。
具体定义的上述阈值包括:
1)聚类半径阈值500米;
2)聚类范围内最少点数为5个点。
步骤s30,聚类判断。
如图2所示,所述聚类判断包含如下步骤:
s3001:聚类大于等于2则继续后续步骤,否则放弃判断,算法结束;
s3002:计算各类的总停留时间,并按照从大到小排序;
s3003:取总停留时间排名最大的两位,如果两者之和大于8小时则进入后续步骤;
s3004:如果这两类的中心聚类大于500km,则进入步骤s40;
s3005:如果存在三个类,第二、三名类的总停留时间差的占小于10%,则进入步骤s40,否则进入后续步骤;
s3006:如果第三名的总停留时间占所有类的总停留时间的比例大于10%,则进入步骤s40,否则放弃判断,算法结束。
步骤s40,第一大类循环计算与结果标记(mhwa-loop1)。
如图3所示,第一大类循环计算与结果标记(mhwa-loop1)包含如下步骤:
s4001:对第一类进行变量计算。类的变量计算包含以下四个步骤:
s40011:将类所有的结束时间转化为以秒为单位的当天时间;
s40012:计算该时间的10%和90%分位数;
s40013:计算该时间属于星期几并统计次数;
s40014:输出10%和90%分位数值和次数最多的两个星期几。
s4002:从总停留时间排名第二的类开始计算;
s4003:条件判断与计算包含以下四个步骤:
s40031:该类的总停留时间要大于4小时,否则放弃判断,默认标记为0;
s40032:统计该类结束时间落在第一类结束时间的10%和90%分位数之间的次数占比作为条件一
s40033:计算该类次数最多的前两个星期几
s40034:判断此类的前两个星期几与第一类相关变量计算的结果是否一致,输出相应的条件判断,用于后续步骤。
s4004:判断条件一是否大于0.5,条件二是否成立;
s4005:对满足条件的类标记为1;
s4006:循环计算判断每一类,计算完毕后进入步骤s50。
步骤s50,第二大类循环计算与结果标记(mhwa-loop2)。
如图4所示,第二大类循环计算与结果标记(mhwa-loop2)包含如下步骤:
s5001:找到标记为0的类,并统计次数;
s5002:若次数大于0,则进入后续步骤;
s5003:标记第一个类为2,默认标记为0;
对第一个类进行s4001步骤所述的变量计算;
s5004:从第二类开始计算;
进入s4002步骤所述的条件计算与判断;
s5005:判断条件一是否大于0.5,条件二是否成立;
s5006:对满足条件的类标记为2;
s5007:循环计算判断每一类,计算完毕后进入步骤s60。
步骤s60,特征合并计算与建模结果输出(mhwa-model)。
如图5所示,特征合并计算与建模结果输出(mhwa-model)包含如下步骤:
s6001:对标记为1和2的的变量进行合并计算,求平均值;
s6002:计算的特征包括:类总停留时间比例、行程次数比例、非工作日停留时间比例等,执行步骤s6003;
s6003:将特征变量带入到逻辑回归模型中,算出概率p,执行步骤s6004;
s6004:判断输出的概率p是否大于等于0.6。若是,则总停留时间排名第一大类全部为该用户的家庭地址所在地,总停留时间排名第二大类全部为该用户工作地址所在地;否则,执行步骤s6005;
s6005:判断输出的概率p是否小于等于0.5。若是,则总停留时间排名第二大类全部为该用户的家地址所在地,总停留时间排名第一大类全部为该用户工作地址所在地;否则,放弃判断。
在本实施例中的用行程挖掘多个家庭或工作地址的方法,首先按照行程点数进行过滤并聚类找出潜在的家庭与工作地址,然后进行聚类判断和相关变量与特征的精确计算与判断,最后通过逻辑回归模型判断此聚类是家庭或工作地址。与现有技术相比,本实施例中的用行程挖掘多个家庭或工作地址的方法解决了必须使用全时段的数据以获得用户家庭工作地址的方法。在用户对数据隐私越来越重视的时代,可以仅通过使用行程数据找到用户大致的家庭住址或工作地址为后期的用户标签和用户画像提供支持。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!