渐进式目标精细识别与描述方法与流程
本发明属于计算机视觉领域,具体地说,涉及视频目标精细识别与描述方法。
背景技术:
随着视频设备的不断普及和视频监控技术的日益成熟,视频监控的应用越来越广泛,监控视频数据量呈现出爆炸式的增长,已经成为大数据时代的重要数据对象。例如,遍布上海市的百万级监控探头每分钟产生tb级的视频数据,为实时掌握社会动态和保障公共安全提供了宝贵的视频资源。
然而,由于视频数据本身的非结构化特性,使得其处理和分析相对困难。目前对视频数据的目标识别仍然主要以人工分析为主,辅以简单的智能化分析手段,存在“视频数据在、目标找不到”,“找得到、找太久”等海量视频数据目标识别的瓶颈。同时,目前的视频智能化分析手段还存在识别不精确、特征描述方法不统一等问题,这些问题严重制约了视频目标识别技术进一步发展和应用。因此,面对海量的视频大数据,如何实现精细化的视频目标特征表示是视频智能分析亟待解决的关键问题。
将视频信息转化为表征检测目标的文本信息是解决上述问题的一个有效途径。基于该类方法的视频表示研究大多基于两类方法:(1)视频目标标注:基于机器学习算法为视频中对象自动添加类别标记,用类别标记表示视频目标;(2)视频目标理解:基于计算机视觉和自然语言理解技术,通过提取视频中对象的局部特征,形成对视频目标的自然语言描述。视频目标标注对视频的描述单一化,缺乏对对象特征和对象间关联性的描述;视频目标理解虽然可能包含更多的信息,但由于现实场景复杂多变,难以统一定义,目前只能在特定场景下取得一定的效果,还无法服务于实际应用。
因此,这些问题的存在导致视频的智能化分析还处于较低的水平。针对现有视频目标识别方法中标注单一化,各部件空间关系难以准确定义和描述等问题,我们需要一种能够对复杂场景中对目标实现精细化识别的方法。
技术实现要素:
本发明的目的在于公开一种渐进式目标精细识别与描述方法,针对当前视频监控中存在的问题和困难,围绕视频目标多层次深度特征提取和精细化目标识别与描述展开研究工作。主要包括三个步骤:
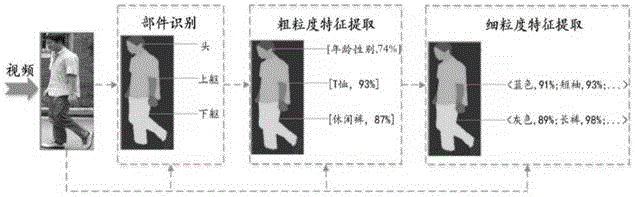
步骤一:部件识别
对视频目标进行检测与分割,从而识别目标的各个部件;
步骤二:多粒度特征提取
基于部件识别进一步提取视频目标的多粒度特征;
步骤三:精细化描述
融合多粒度特征来实现目标的精细识别,并生成精细化描述文本信息。
针对步骤二,本发明公开了一种基于部件的多层次深度特征提取算法,其特征在于,可以对同一目标基于部件提取多层次深度特征。其中“多层次”体现在从多个粒度层将对象的部件信息附加在类别标记上,“深度”体现在不同粒度层的特征都是利用深度学习方法提取的。此算法目的在于输出以类别标记为核心的部件多粒度特征来帮助描述视频目标。
针对步骤三,本发明公开了一种基于模板匹配的视频目标精细化描述算法,其特征在于,这是一种视频部件多粒度特征表示模型,将不同层次的特征对应到不同的粒层,并设计不同粒层之间的信息合并机制。此算法目的在于融合部件多粒度信息,生成结构化的视频目标精细描述文本。
本发明公开了一种渐进式目标精细识别与描述方法,具体实施步骤如下:
步骤一:部件识别
1.1对采集的视频进行关键帧的提取,生成关键帧图像训练集;
1.2使用深度学习方法对关键帧图像集进行训练,利用区域建议神经网络(fasterr-cnn)检测出关键帧里的所有目标;
1.3基于目标检测结果,使用基于实时目标检测的区域建议神经网络(fasterr-cnn)再对目标进行部件检测,得到目标部件图像集。
步骤二:多粒度特征提取
2.1基于目标头部部件,使用卷积神经网络(cnn)提取人脸视觉特征来对目标进行年龄识别和性别识别;
2.2基于目标身体部件,使用cnn提取部件粗粒度特征来进行身体部件的衣着服饰类别识别;
2.3基于目标身体部件,提取目标部件图像的细粒度特征——最大颜色域特征来对目标进行身体部件的衣着基本颜色识别。
步骤三:精细化描述
3.1对步骤二得到的目标部件多粒度特征进行融合,使用自然语言处理技术生成视频目标精细识别的描述语句。
有益效果
1、本发明针对现有视频目标识别方法标注单一化,各部件难以准确描述等问题,提出渐进式目标精细识别与描述方法,对同一视频中多个对象同时学习并标记其部件多粒度信息。
2、本发明使用基于部件的多层次深度特征提取算法,基于目标身体部件分割提取部件的多粒度特征来更加精确地发现目标各身体部件的细节特征,使得视频目标描述不再局限于整体视角上的分析,为目标精细化描述内容的精确性和丰富性提供了保证。
3、本发明使用基于模板匹配的视频目标精细化描述算法,融合视频目标部件的多粒度特征,建立多粒度视频表示理论和方法,为视频内容表示提供新的思路。同时,结合自然语言处理技术,形成视频目标描述性更加完备的文本信息。
4、本发明将丰富和拓展机器学习理论和方法,同时也为未来推动视频智能化分析发展奠定理论和应用基础。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1渐进式目标精细化识别算法流程图
图2渐进式目标精细化识别算法示意图
图3目标部件检测识别深度学习模型图
图4基于部件的多层次深度特征提取与表示示意图
图5目标精细化识别示例图
图6综合示意图
具体实施方式
以下将配合附图及实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题以及达成技术功效的实现过程能充分理解并据以实施。
本发明公开了一种渐进式目标精细识别与描述方法,其特征在于,以视频目标识别为背景,从视频目标多层次深度特征提取和精细化目标识别与描述的理论和方法开展研究工作。首先,对视频目标进行检测与分割,从而识别目标的各个部件;其次,在完成部件分割与识别后,进一步提取不同部件的多粒度特征;最后,融合多粒度特征来实现对目标的精细识别与描述,并生成精细化描述文本信息。
本发明公开了一种渐进式目标精细识别与描述方法,包括以下步骤:
步骤一:部件识别
1.1在本实施例中,所述视频来源于上海市重要交通卡口的监控视频,视频的分辨率为1280*720p。监控视频场景复杂,包含不同形态、不同尺寸的目标行人。首先对采集的监控视频进行关键帧的提取。关键帧需要满足存在行人且行人形态、尺寸丰富;然后生成关键帧图像集,并按照8:1:1的比例划分成训练集、验证集和测试集。
1.2使用深度学习方法对关键帧图像集进行训练,构造区域建议神经网络(fasterr-cnn)。在训练过程中,设定的输出类别为视频目标行人。区域建议神经网络(fasterr-cnn)对视频帧中的行人进行检测并生成行人检测框。
1.3在行人检测的基础上,使用目标检测网络fasterr-cnn检测并识别目标的不同身体部件,如具体地识别同一对象的头部、上下半身部件等,网络模型如图3所示。
首先,使用经典的卷积神经网络提取视频中的关键帧的特征图,该特征图后续候选框生成网络层(regionproposalnetwork,rpn)和全连接层共享;然后,候选框生成网络层通过3x3卷积,再分别生成前景候选框和背景候选框以及边框回归的偏移量;通过softmax判断候选框是否属于前景或背景,再利用边框回归修正候选框的大小和位置,最后获得精确的候选框。候选框生成网络层的损失函数如下:
其中,i表示小窗口中候选框的索引,pi表示候选框i被预测为某个物体的概率,如果候选框为正例,那么
接着,用一个感兴区池化层收集特征图和候选框,综合这些信息后,提取从rpn网络得到的候选框的特征图,送入后续全连接层判定目标类别。最后利用候选框的特征图来计算特征图中的类别,同时再次使用边界回归获得检测框最终的精确位置。
经过fasterrcnn,我们实现目标部件的检测识别与分割。
步骤二:多粒度特征提取
2.1基于行人部件检测结果,采用年龄性别识别网络(age_genderidentificationnetwork,agi-net)识别行人的年龄与性别。将检测的行人头部部件作为agi-net的输入,提取脸部特征作为年龄与性别识别的依据。如图4所示。
本发明提出的agi-net通过改进的facenet网络结构(vgg-16结构)对输入的脸部图像来预测目标的年龄性别。在agi-net模型中,性别识别部分是识别结果为男或者女的二分类模型。定义g为标注的真实性别,g*为模型输出的预测性别,则损失函数的公式定义如下:
loss=-[glogg*+(1-g)log(1-g*)](4)
年龄识别部分则需要对年龄进行定量估计,假设年龄值离散化为|y|个年龄范围,每个年龄范围yi涵盖的年龄为yimin~yimax,训练样本中使用投票法预测在年龄范围yi数量为yi。
年龄范围|y|需要满足:(a)均匀范围,即其中每个年龄范围涵盖了相同的年数;(b)平衡范围,即每个年龄范围涵盖的训练样本大致相同。通过这种方式训练cnn进行年龄段分类,|y|个年龄范围神经元经过softmax归一化输出的概率公式为:
其中o={1,2,...,|y|}是|y|维的输出层,oi∈o是年龄范围神经元i经过softmax归一化的输出概率。
2.2基于行人部件检测结果,采用衣着服饰类别网络(cloth-detectionnetwork,cd-net)识别行人的衣着种类。将检测的行人头部、上半身、下半身作为cd-net的输入,学习部件服饰特征来进行身体部件的衣着服饰类别识别。如图4所示。
本发明提出的cd-net通过将分割好的目标身体部件,通过卷积层、池化层提取到深度特征,最后通过全连接层将特征向量映射到一个与类别数相同维数的向量上,从而得到服装的类别。
对于多分类问题,容易出现的类别混淆问题,我们使用基于lda的标签组合算法。将服饰类别划分为几个主题,对于每一张图片d,θd={pt1,pt2,...,ptk}代表图片d的主题分布,ptk代表这张图片d属于主题k的概率。ptk的计算公式如下:
ptk=ntk/nd(4)
其中,ntk表示主题为k的图片数,nd表示图片d的数量将服饰类别分成几个大标签。同样将训练集按lda算法得到主题分解成标签子集,分别训练卷积神经网络,得到标签子网络。然后通过级联分类的思想,级联模型第一层基网络(bm-convnet)输出为原始服饰类别预测概率值。级联第二层为标签子网络(lda-convnet-k,k为lda算法得到的主题数)。级联网络的算法流程如下:
步骤6.1,样本输入第一层基网络bm-convnet,得到预测结果l:
l={l1,l2,...,ln}(5)
其中,n为服饰类别数。预测概率p:
p={p1,p2,...,pn}(6)
步骤6.2,对于预测概率值大于阈值pmin的类别li,将测试样本输入第二层对应的子网络lda-convnet-k,得到预测结果l:
其中,m为lda-convnet-k的预测类别数,及其预测概率pk:
然后,通过概率覆盖的思想,即以第二次预测概率为最终概率;对于未接受二次预测的类别,以模型第一层的预测概率为最终概率。最后准确预测服饰类别。概率pi计算公式如下:
2.3基于行人部件检测结果,使用基于最大颜色域识别的方法对行人身体部件的衣着基本颜色识别。具体地,采用衣着颜色识别模块(moduleofcoloridentification,mci)来识别行人的衣着颜色细节。将检测的行人头部、上半身、下半身作为mci的输入,其步骤为:
a、将图片颜色转为hsv;
b、参考hsv颜色分类定义hsv颜色字典;
c、将过滤后的颜色进行二值化处理;
d、进行图像形态学腐蚀膨胀;
e、统计白色区域面积,面积最大的则为该物体的最大颜色域。
统计出的部件最大颜色域可以作为目标身体部件颜色识别的依据。
步骤三:精细化描述
3.1在本实例中,对目标使用基于模板匹配的精细化描述算法对目标进行描述。
采用自然语言处理技术对步骤二检测的目标部件多粒度特征进行融合。,在本实施例中采用的是基于模板匹配的方法。首先,根据步骤一识别的目标的不同身体部件定义不同的模板;然后,根据粗粒度类别信息模板的不同,将步骤二得到的多粒度特征根据分类器得到的粗细粒度的信息整合进模板中,最后生成该视频目标的文本描述信息。
本实施例的综合示意图如图6所示。
上述说明展示并描述了本发明的若干具体实施方案,但如前所述,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
创新点
本项目的特色在于从视频智能分析实际需求出发,通过对视频中目标部件级、目标级逐步递进的识别,达到对目标的精细描述,进而实现更精准的视频目标检测与识别。这是一条全面贯通的视频目标识别途径,在进行目标检测的同时形成丰富的目标及其部件的特征描述,对于实际应用而言,更具有可解释性和可描述性。
创新之一:目标部件多粒度特征提取与表示
本项目突破传统目标识别方式,通过基于部件的多层次深度特征提取算法,从多个粒度层提取视频目标部件不同粒度上的特征,目标多粒度部件特征可进一步为目标的精细化识别提供支持。
创新之二:视频目标渐进式精细识别与描述
传统的视频目标识别往往只能提供目标的全局信息作为描述信息,忽略了目标的部件级细节特征,例如视频目标的空间位置或视频目标的人脸识别。本项目拟从目标的年龄、性别、身体部件衣着颜色和身体部件衣着类别四个粒度层检测视频目标特征。通过基于模板匹配的视频目标精细化描述算法将不同层次的特征对应到不同的粒层,并设计不同粒层之间信息合并机制。该算法融合部件多粒度信息,生成结构化的视频目标精细描述文本,为视频目标深度解析提供了可行的解决方案,能更好地满足视频目标检测与分析的实际需求。
- 还没有人留言评论。精彩留言会获得点赞!