一种基于深度学习的交警手势识别方法及无人车与流程
本发明属于图像识别技术领域,具体地说,是涉及一种用于识别交警手势的方法及应用该方法设计的无人车。
背景技术:
近年来,无人驾驶技术飞速发展,无人驾驶汽车成为研究焦点。在社会经济高度发展的今天,私家车持有量急剧增长,城市交通问题日趋严重。仅依靠交通信号灯难以准确判断复杂多变的路况,尤其是面对突发事故与拥挤路段,交警手势指挥仍是必不可少的交通管控手段。准确的识别交警手势并选择正确的行驶行为是无人驾驶技术的重要研究内容,也是无人车能够真正“上路”必须解决的问题。
现有的交警手势识别技术大多依托于复杂的硬件设备或者存在识别准确率低、速度慢等问题,例如:
申请号为200810137513.1的中国发明专利申请,公开了一种基于手势识别的多功能无线交警手势识别系统,依靠佩戴式手套获取交警手部挥动时产生的加速度信号来识别交警手势,使用该方法除了需要频繁更换电池所带来的使用不便等问题外,也限制了交警指挥的自由度;
申请号为201110089635.x的中国发明专利申请,公开了一种基于手势识别和zigbee的道路交通控制系统,通过不同方向轴上的加速度数据判断出相应的交警手势,但也是依托穿戴式器具实现;
申请号为201620250125.4的中国实用新型专利申请,公开了一种面向无人驾驶车的多维非穿戴式交警手势识别系统,包括交警手势数据获取装置、交警手势识别装置和无人驾驶车响应装置,通过无线通信方式使无人车接收手势识别装置的识别结果,识别是通过对深度图像建立词袋模型,并利用svm技术实现的,深度图像的获取需要专用的设备;
申请号为201110045209.6的中国发明专利申请,公开了基于一种骨架化和模板匹配的交警手势识别方法,提取关键交警手势静态图像进行识别,然而在实际的交警连续手势动作中提取关键帧存在困难,识别准确率较低,因此实用效果较差;
申请号为201610737545.x的中国发明专利申请,公开了一种基于光流图深度学习模型的人体交互动作识别方法,使用farneback法计算稠密光流,使用resnet训练特征,然而farneback法和resnet均为计算量大、速度较慢的方法,因此不适合实时的交警手势识别。
技术实现要素:
本发明的目的在于提供一种基于深度学习的交警手势识别方法,需要依赖的硬件设备简单,并具有较高的识别精度和效率。
为解决上述技术问题,本发明采用以下技术方案予以实现:
一方面,本发明提出了一种基于深度学习的交警手势识别方法,包括:(1)制作训练数据集:针对每一种交警手势采集多段视频数据,将每一段视频数据记作视频段v={f0,f1,...fp,...fn},形成训练数据集;其中,fp表示第p帧图像数据,每一个视频段v均对应单一语义的交警手势,并对相同交警手势所对应的视频段赋予同一指令标注;(2)离线训练数学模型:a、针对每一个视频段v,分别采用以下步骤生成对比结果:使用光流提取网络motionnet模型提取出视频段v中相邻帧之间的光流特征图,形成光流特征集;根据光流特征集和视频段v中的帧图像数据,利用卷积神经网络vgg16模型计算出时间流特征图和空间流特征图;对时间流特征图和空间流特征图进行卷积融合,生成融合结果;将融合结果与视频段v所对应的指令标注进行对比,生成对比结果;b、计算对比结果的误差率,直到误差率降低到预期值以下时,停止训练,保存训练后的光流提取网络motionnet模型和卷积神经网络vgg16模型;(3)识别交警手势:拍摄现场的交警手势,生成手势视频v;使用训练后的光流提取网络motionnet模型提取出手势视频v中相邻帧之间的光流特征图,形成光流特征集;根据手势视频v中的帧图像数据及其对应的光流特征集,使用训练后的卷积神经网络vgg16模型计算时间流特征图和空间流特征图,并通过卷积融合生成手势识别结果。
另一方面,本发明还提出了一种无人车,包括摄像头、车载工作站和自动操控台;其中,所述摄像头用于拍摄现场的交警手势,生成手势视频v;所述车载工作站接收所述手势视频v,并使用其存储的经训练后的光流提取网络motionnet模型提取出手势视频v中相邻帧之间的光流特征图,形成光流特征集;然后,根据手势视频v中的帧图像数据及其对应的光流特征集,使用其存储的经训练后的卷积神经网络vgg16模型计算时间流特征图和空间流特征图,并通过卷积融合生成手势识别结果;所述自动操控台根据所述手势识别结果控制无人车遵循交警手势行驶。
与现有技术相比,本发明的优点和积极效果是:本发明基于深度学习方法提出的交警手势识别技术,仅依靠一个普通rgb摄像头和车载工作站即可自动识别出交警手势,无需复杂的外部设备,成本低,使用方便,占用空间小,对于不同环境下的交警手势识别都具有较高的准确率和识别效率。将该技术应用于无人驾驶车,可以使无人驾驶车具备自动识别交警手势并适应复杂多变的道路环境的能力,从而显著提升了无人驾驶车的智能性,推动了无人驾驶技术的应用与发展。
结合附图阅读本发明实施方式的详细描述后,本发明的其他特点和优点将变得更加清楚。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
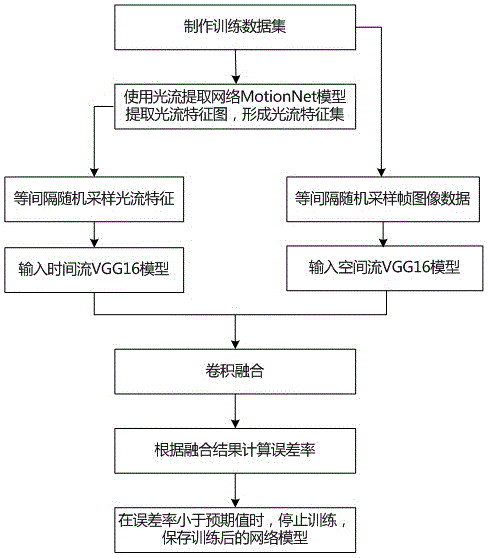
图1是本发明所提出的基于深度学习的交警手势识别方法中训练数学模型阶段的流程图;
图2是本发明所提出的基于深度学习的交警手势识别方法中实际应用阶段的流程图;
图3是本发明所提出的无人车的一种实施例的硬件架构图。
具体实施方式
下面结合附图对本发明的具体实施方式进行详细地描述。
近年来深度学习技术飞速发展,在图像检测、识别与理解方面取得了重大突破,相比传统计算机视觉技术,识别的鲁棒性与准确率明显提高。基于此,本实施例提出了一种基于深度学习的交警手势识别方法,仅依靠普通rgb摄像头和车载工作站即可自动出识别交警手势,且具有较高的识别精度及效率,可以适应不同天气、不同时段和不同路况下的自动驾驶应用领域。
本实施例的交警手势识别方法主要包括离线训练和实时应用两大阶段。其中,在离线训练阶段,可以使用一个rgb摄像头采集交警手势视频数据,形成训练数据集,进行深度学习网络模型的离线训练;在实时应用阶段,可以使用rgb摄像头在采集到现场的交警手势后,利用车载工作站存储的深度学习网络模型进行实时识别,进而生成交警手势的识别结果,控制无人车产生相应的行驶行为。
下面结合图1,首先对本实施例的交警手势识别方法在离线训练阶段所执行的步骤进行详细阐述。
在离线训练阶段,主要包括制作训练数据集和离线训练数学模型两个过程:
s1、制作训练数据集:
针对每一种交警手势采集多段视频数据,将每一段视频数据记作视频段v={f0,f1,...fp,...fn},形成训练数据集;其中,fp表示第p帧图像数据。在本实施例中,每一个视频段v均对应单一语义的交警手势,对相同交警手势所对应的视频段赋予同一指令标注。例如,对于第一种交警手势(如停止)所对应的每一个视频段均赋予指令标注1;对于第二种交警手势(如直行)所对应的各个视频段均赋予指令标注2;等等。
目前我国的交警手势包括8种,分别为停止信号、直行信号、左转弯信号、右转弯信号、左转弯待转信号、变道信号、减速慢行信号、靠边停车信号,可以针对这8种交警手势分别赋予指令标注1-8。若路口没有交警,则指令标注为0。
本实施例为了提高交警手势识别的准确度,在采集交警手势的视频数据时,优选在不同天气条件下的不同时间段,针对每一种交警手势进行视频数据的多次采集,形成多个视频段v,由此构成训练数据集,用于深度学习网络模型的离线训练。例如,可以使用rgb摄像头,在晴、雨、雾、雪四种天气条件下,且分别在早8点、晚6点的高峰时段以及下午3点、晚10点的非高峰时段,分别针对每一种交警手势各采集10组交警手势视频数据,形成1280个视频段v。每一个视频段v的视频长度可以设定为2秒,优选按30fps的帧率进行采集,摄像头的分辨率可以设定为688×488。
为了扩充数据集,可以对每一个视频段v中的所有图像帧进行平移、缩放,继而再额外得到50个相关视频,由此构成训练数据集,用于训练深度学习网络模型。
s2、离线训练数学模型:
s2.1使用光流提取网络motionnet模型提取出视频段v中相邻帧之间的光流特征图,形成光流特征集of。
具体包括以下过程:
s2.1.1、针对视频段v中的每一对相邻帧图像数据fp与fp+1,利用光流提取网络motionnet模型提取出每一对相邻帧之间的光流特征图;
光流提取网络motionnet模型(可参见文献《hiddentwo-streamconvolutionalnetworksforactionrecognition》,作者yizhu等,发表自ieee国际计算机视觉与模式识别会议)由光流网络flownet2.0改进而来,改进内容包括:(1)删除第一个具有较大感受野的卷积层,并将第二个卷积层的步长减小为1;(2)同时将所有7×7、5×5的卷积核修改为3×3;(3)在扩张卷积部分的每个反卷积层之间插入卷积层,以获得更平滑的光流特征。
s2.1.2、利用相邻帧之间的光流特征图以及后一帧图像数据fp+1,反向计算出前一帧图像数据fp';
由于光流特征图反映的是相邻两帧图像在水平方向(x方向)和垂直方向(y方向)上的移动矩阵,因此,可以利用相邻帧之间的光流特征图以及后一帧图像数据fp+1反向计算出前一帧图像数据,记为fp'。
s2.1.3、针对每一帧图像计算fp'与fp之间的误差l;
本实施例优选采用加权和的方式计算误差l,具体方法为:
计算像素误差:
其中,n为一帧图像的总像素个数,n为一帧图像的像素行数,m为一帧图像的像素列数,n=n×m;ρ为charbonnier误差;fp(i,j)代表第p帧图像中第i行、第j列的像素值;
计算孔径误差:
其中,
计算结构相似性误差:
其中,fp'(i,j)为fp'在第i行、第j列的像素值;ssim为结构相似性函数。
计算fp'与fp之间的误差l:l=λ1·lpixel+λ2·lsmooth+λ3·lssim;
其中,λ1、λ2、λ3为加权系数,赋予经验值,且λ1+λ2+λ3=1。
s2.1.4、以l作为光流提取网络motionnet模型的目标函数进行反向传播,迭代至l收敛时,停止对motionnet模型的训练。
s2.1.5、利用训练后的motionnet模型提取出每一对相邻帧之间的光流特征图,形成光流特征集of。
s2.2、根据光流特征集of和视频段v中的帧图像数据,采用卷积神经网络vgg16模型计算出时间流特征图xa和空间流特征图xb;
vgg16是一种卷积神经网络,包括时间流vgg16模型和空间流vgg16模型。在利用vgg16模型计算时间流特征图xa和空间流特征图xb时,优选采用以下方法:
s2.2.1、针对每一个视频段v及与其对应的光流特征集of,采用等间隔分段、段内随机采样的方法,提取出m帧图像数据和m个光流特征图,分别形成帧集合v’和特征集合of’。具体过程为:
将光流特征集of等分为m段,每段随机采样一个光流特征图,形成特征集合of’={t1,t2,...tm}。同理,将视频段v等分为m个视频片段,每段随机采样一个帧图像,形成帧集合v’={v1,v2,...vm}。
s2.2.2、将特征集合of’中的光流特征图作为时间流vgg16模型的输入,将帧集合v’中的帧图像数据作为空间流vgg16模型的输入,分别进行五组卷积池化后,计算出时间流特征图xa和空间流特征图xb。
s2.3、对时间流特征图xa和空间流特征图xb进行卷积融合,生成融合结果;
在本实施例中,可以在vgg16模型的relu_6层处,对时间流特征图xa和空间流特征图xb进行卷积融合:yconv=fconv(xa,xb),以生成融合结果。
在进行卷积融合时,首先将两路特征图xa和xb堆叠在一起,使用1×1×2d卷积核f对通道进行卷积。这里,卷积核f用于将维数减小两倍,并且能够在相同的空间(像素)位置处对两个特征图xa和xb的加权组合进行建模。当用作网络中的可训练滤波器内核时,f能够学习最小化关节损失函数的两个特征图的对应关系。
s2.4、将融合结果与视频段v所对应的指令标注进行对比,生成对比结果;
利用计算出的融合结果与视频段v所对应的指令标注进行对比,判断融合结果是对还是错,从而生成代表对错的对比结果。
s2.5、针对训练数据集中的每一个视频段v分别采用上述步骤s2.1-s2.5,计算出每一个视频段v所对应的对比结果。
s2.6、计算对比结果的误差率,直到误差率降低到预期值以下时,停止训练,将训练后的光流提取网络motionnet模型和卷积神经网络vgg16模型作为最终的深度学习网络模型,保存在车载工作站。
由此,离线训练阶段完成。
下面结合图2,对本实施例的交警手势识别方法在实际应用阶段所执行的步骤进行详细阐述。
s3、拍摄现场的交警手势,生成手势视频v;
在本实施例中,可以在无人车上安装摄像头和车载工作站,如图3所示,所述摄像头优选采用rgb车载摄像头,摄像头的分辨率优选设置在688×488,按30fps的帧率拍摄交警手势视频。本实施例设置车载工作站通过摄像头实时监测无人车到路口的距离,当无人车行驶至路口前30米时,车载工作站控制摄像头拍摄路口图像,保存至车载工作站,形成手势视频v。
s4、使用训练后的光流提取网络motionnet模型提取出手势视频v中相邻帧之间的光流特征图,形成光流特征集;
在车载工作站中存储有经训练后的motionnet模型,车载工作站利用所述经训练后的motionnet模型提取出手势视频v中每一对相邻帧之间的光流特征图,形成光流特征集of。
s5、根据光流特征图获取手势视频v中交警手势的起止帧;
在本实施例中,为了提高交警手势识别结果的准确度,需要在拍摄到的手势视频v中识别出交警手势的起止帧,具体过程如下:
s5.1、设手势视频v中的前后两帧图像数据在垂直方向的光流特征矩阵分别为y1、y2,计算其差值矩阵w=y2-y1;
s5.2、计算差值矩阵w的l21范数:
其中,i,j分别表示差值矩阵w的行和列;
s5.3、将l21范数||w||21与设定阈值进行比较,判断当前帧是否为交警手势的起止帧;
在本实施例中,车载工作站从手势视频v的第一帧开始向后,逐次提取前后两帧图像数据,执行步骤s5.1、s5.2,计算出l21范数||w||21;若l21范数||w||21大于设定阈值,则判定当前两帧图像数据中的后一帧为交警手势的起始帧;否则,重复执行步骤s5.1-s5.3的判断过程。在获取到交警手势的起始帧后,继续执行步骤s5.1-s5.3的判断过程,若再次满足l21范数||w||21大于设定阈值的条件,则判定当前两帧图像数据中的前一帧为交警手势的终止帧。若在手势视频v中未发现起止帧,则认为路口没有交警,直接将手势识别结果置为0,跳转至步骤s9。
s6、从所述手势视频v中提取出介于所述起止帧之间的帧图像数据,形成帧集v’;从所述手势视频v所对应的光流特征集中提取出介于所述起止帧之间的帧图像数据所对应的光流特征图,形成特征集t’。
s7、根据帧集v’中的帧图像数据以及特征集t’中的光流特征图,使用训练后的卷积神经网络vgg16模型计算时间流特征图和空间流特征图;
在本实施例中,车载工作站首先对所述帧集v’和特征集t’,采用等间隔分段、段内随机采样的方法,提取出m帧图像数据和m个光流特征图;具体过程为:
将特征集t’等分为m段,每段随机采样一个光流特征图,提取出m帧图像数据。同理,将特征集t’等分为m个视频片段,每段随机采样一个帧图像,提取出m个光流特征图。
车载工作站将所述m个光流特征图作为训练后的时间流vgg16模型的输入,将所述m帧图像数据作为训练后的空间流vgg16模型的输入,分别进行五组卷积池化后,计算出时间流特征图和空间流特征图。
在此步骤中,vgg16网络不进行反向传播。
s8、对计算出的时间流特征图和空间流特征图进行卷积融合,生成手势识别结果;
在本实施例中,车载工作站在vgg16模型的relu_6层处,对计算出的时间流特征图和空间流特征图进行卷积融合,生成手势识别结果,即,生成1-8中的其中一个数字;然后,根据指令标注即可判断出是哪一种交警手势。
s9、根据手势识别结果,产生相应的行驶决策;
在本实施例中,车载工作站将识别出的交警手势发送至无人车中的自动操控台,如图3所示,自动操控台根据所述交警手势控制无人车遵循交警手势行驶。
本实施例基于深度学习方法设计的无人车交警手势识别方法,通过离线训练的方式降低了车载工作站的存储要求,所需依赖的硬件设备简单,占用空间小,成本低,对于不同环境下的交警手势具有较高的识别度。
当然,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!