一种面向Wi-Fi信号的手语孤立词识别网络构建及分类方法与流程
本发明属于手语识别技术领域,涉及一种手语孤立词识别技术,尤其涉及一种面向wi-fi信号的手语孤立词识别网络构建及分类方法。
背景技术:
手语作为聋哑人之间交流的语言,其主要通过手部、手臂、以及身体的动作传递信息。手语孤立词识别作为一种特殊的手势识别问题,其相较于一般的手势识别问题,特殊性在于其类别众多且包含了多种肢体动作。就常用的手语词汇就达好几百种,且每一个词汇都是手臂、手指等多种肢体动作的混合,这就对分类识别技术提出了更高的要求。
目前手语孤立词识别技术,主要包括基于视频图像技术和基于穿戴式传感器技术,但是这些技术均存在一些局限性。基于视频图像技术的手语识别方法需要用户在光线充足且在摄像头的视野内,这就使得用户无法在熄灯等光线较暗的情况下使用,且摄像头的使用也容易侵犯用户的隐私。基于穿戴式传感器技术的手语识别方法则需要用户随时佩戴设备,给用户的日常生活会有不同程度的影响。而基于wi-fi的手语孤立词识别技术,可以有效地克服这些局限性。
近年来,基于wi-fi进行动作感知领域中,多使用传统的手工特征(如均值,方差,频域特征等)和传统的机器学习分类算法(如支持矢量机,svm等)。虽然这些方法在简单的十几类的手势分类问题上已经达到了96%以上的成绩,但是在上百类的手语孤立词识别上识别率不高。
技术实现要素:
针对现有技术中存在的基于wi-fi的手语孤立词识别率不高的缺点,本申请的目的在于,提供了一种面向wi-fi信号的手语孤立词识别网络构建及分类方法。
为了实现上述目的,本发明采取以下技术方案予以实现:
一种面向wi-fi信号的手语孤立词识别网络的构建方法,具体包括以下步骤:
步骤1、采集获取csi信号,并对获取的csi信号进行处理,得到降噪后的振幅信息,所述csi表示信道状态信息;
其特征在于,还包括以下步骤:
步骤2、将降噪后的振幅信息按照窗口的大小进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;根据窗口的振幅信息序列中多个窗口的振幅信息,计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,根据窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成得到窗口的振幅信息方差的平均值序列;根据窗口的振幅信息方差的平均值序列中多个窗口的振幅信息方差的平均值的大小,判断得到手语孤立词片段对应的振幅信息;由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息;
步骤3、对得到的手语孤立词动作对应的振幅信息进行奇异值分解,得到去除环境影响的手语孤立词动作对应的振幅信息;对得到的去除环境影响的手语孤立词动作对应的振幅信息进行映射处理,得到图像;
步骤4、由删除全连接层的vgg16网络、lstm层网络和全连接层网络构成得到手语孤立词识别网络;采用手语孤立词识别网络对得到的图像和去除环境影响的手语孤立词动作对应的振幅信息进行处理,得到一维输出向量;根据一维输出向量,采用交叉熵损失函数计算得到损失值;将得到的损失值输入到手语孤立词识别网络中,采用梯度下降算法对手语孤立词识别网络进行训练,得到训练好的手语孤立词识别网络。
进一步的,所述步骤2具体操作如下:
步骤2.1、采用0.2s的时间长度作为窗口大小,对降噪后的振幅信息进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;采用公式(2)计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值;
其中,mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
根据得到的窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,采用公式(3)计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值,由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成窗口的振幅信息方差的平均值序列;
其中,var(i)表示第i个窗口的振幅信息方差的平均值,var(i)≥0;n表示csi流的总条数,k∈[1,k],n∈[1,n],n为正整数;mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
步骤2.2、设置方差阈值θ和动作停顿缓冲区最大时间长度tp,其中θ和tp均为正数;将窗口的振幅信息序列中的第一个窗口的振幅信息作为当前窗口的振幅信息;将窗口的振幅信息方差的平均值序列中第一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值;
步骤2.3、当当前窗口的振幅信息方差的平均值大于θ时,表示手语孤立词动作开始,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息,并设置动作停顿缓存区;并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,执行步骤2.4;
当当前窗口的振幅信息方差的平均值小于θ时,并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.3相同的操作;
步骤2.4、当当前窗口的振幅信息方差的平均值大于θ时,若动作停顿缓冲区为空时,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息;若动作停顿缓冲区不为空时,将动作停顿缓冲区中的振幅信息作为手语孤立片段对应的振幅信息,并将当前窗口的振幅信息作为手语孤立片段对应的振幅信息;将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;
当当前窗口的振幅信息方差的平均值小于θ时,则将当前窗口的振幅信息加入到动作停顿缓存区,当动作停顿缓冲区的时间长度小于tp时,将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;当动作停顿缓冲区的时间长度大于tp时,表示手语孤立词动作结束,删掉动作停顿缓冲区的振幅信息,执行步骤2.5;
步骤2.5、由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息。
进一步的,所述步骤3具体操作如下:
步骤3.1、采用公式(4)对得到的手语孤立词动作对应的振幅信息进行奇异值分解,得到矩阵s;将矩阵s中的最大奇异值设置为0,得到矩阵s’;根据矩阵s’,采用公式(5)计算得到去除环境影响的手语孤立词动作对应的振幅信息;
s=usvt(4)
其中,s表示手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s表示n*l的矩阵;v为l*l的矩阵;vt为v的转置;n和l均为正整数;
s'=us'vt(5)
其中,s’表示去除环境影响的手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s’为n*l的矩阵,n和l均为正整数;
步骤3.2、采用公式(6)将去除环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,得到多个映射整数,并按照采集csi信号的天线对的顺序将多个映射整数对应到rgb三通道中,得到图像;
其中,gnl表示第n条csi流的第i个振幅值经过映射后的值,gnl为正整数;s’nl表示第n条csi流的第i个振幅值映射前的值,s’nl为正数;max(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最大振幅值,且max(s')为正数;min(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最小振幅值,且min(s')为正数;
进一步的,所述步骤4中由删除全连接层的vgg16网络、lstm层网络和全连接层网络构成得到手语孤立词识别网络;采用手语孤立词识别网络对得到的图像和去除环境影响的手语孤立词动作对应的振幅信息进行处理,得到一维输出向量,具体操作如下:
所述删除全连接层的vgg16网络为采用已知的imagenet数据集预训练过的vgg16网络模型参数进行更新的网络;所述全连接层网络包括批正则化层和3个全连接层,所述3个全连接层之间分别设有dropout层,所述批正则化层用于加快手语孤立词识别网络收敛;所述dropout层用于避免手语孤立词识别网络产生过拟合;
采用所述删除全连接层的vgg16网络对图像进行计算,得到图像特征;采用所述lstm层网络对去除环境影响的手语孤立词动作对应的振幅信息进行计算,得到时序特征;采用全连接层网络对得到的图像特征与时序特征整体进行融合,得到一维输出向量。
进一步的,所述步骤1具体操作如下:
步骤1.1、将wi-fi发送设备作为wi-fi发送端,将wi-fi接收设备作为wi-fi接收端,当用户在wi-fi发送端和wi-fi接收端之间做出已知手语孤立词动作时,wi-fi接收端按照wi-fi发送端与wi-fi接收端之间的天线对的顺序采集获取csi信号;所述csi信号为与手语孤立词相对应的csi信号和不做手语孤立词动作时相对应的csi信号;所述csi信号包括3条天线对的信号,每条天线对有30个csi流,总计90条csi流;
步骤1.2、采用公式(1)计算得到csi信号的振幅信息;采用巴特沃斯滤波器对得到的csi信号的振幅信息进行降噪处理,得到降噪后的振幅信息;
a'=||h||(1)
其中,a'表示csi信号的振幅信息,为一个csi流总数*采集csi信号总长度的正数矩阵;h表示csi信号,为csi流总数*采集csi信号总长度的复数矩阵。
一种面向wi-fi信号的手语孤立词分类方法,具体包括以下步骤:
步骤1、采集获取csi信号,并对获取的csi信号进行处理,得到降噪后的振幅信息;
还包括以下步骤:
步骤2、将降噪后的振幅信息按照窗口的大小进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;根据窗口的振幅信息序列中多个窗口的振幅信息,计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,根据窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成得到窗口的振幅信息方差的平均值序列;根据窗口的振幅信息方差的平均值序列中多个窗口的振幅信息方差的平均值的大小,判断得到手语孤立词片段对应的振幅信息;由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息;
步骤3、对得到的手语孤立词动作对应的振幅信息进行奇异值分解,得到去除环境影响的手语孤立词动作对应的振幅信息;对得到的去除环境影响的手语孤立词动作对应的振幅信息进行映射处理,得到图像;
步骤4、采用训练好的手语孤立词识别网络对得到的图像和去除环境影响的手语孤立词动作对应的振幅信息进行分类,得到待识别的手语孤立词动作的类别。
进一步的,所述步骤2具体操作如下:
步骤2.1、采用0.2s的时间长度作为窗口大小,对降噪后的振幅信息进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;采用公式(9)计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值;
其中,mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
根据得到的窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,采用公式(10)计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成窗口的振幅信息方差的平均值序列;
其中,var(i)表示第i个窗口的振幅信息方差的平均值,var(i)≥0;n表示csi流的总条数,k∈[1,k],n∈[1,n],n为正整数;mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
步骤2.2、设置方差阈值θ和动作停顿缓冲区最大时间长度tp,其中θ和tp均为正数;将窗口的振幅信息序列中的第一个窗口的振幅信息作为当前窗口的振幅信息;将窗口的振幅信息方差的平均值序列中第一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值;
步骤2.3、当当前窗口的振幅信息方差的平均值大于θ时,表示手语孤立词动作开始,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息,并设置动作停顿缓存区;并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,执行步骤2.4;
当当前窗口的振幅信息方差的平均值小于θ时,并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复与执行步骤2.3相同的操作;
步骤2.4、当当前窗口的振幅信息方差的平均值大于θ时,若动作停顿缓冲区为空时,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息;若动作停顿缓冲区不为空时,将动作停顿缓冲区中的振幅信息作为手语孤立片段对应的振幅信息,并将当前窗口的振幅信息作为手语孤立片段对应的振幅信息;将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;
当当前窗口的振幅信息方差的平均值小于θ时,则将当前窗口的振幅信息加入到动作停顿缓存区,当动作停顿缓冲区的时间长度小于tp时,将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;当动作停顿缓冲区的时间长度大于tp时,表示手语孤立词动作结束,删掉动作停顿缓冲区的振幅信息,执行步骤2.5;
步骤2.5、由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息。
进一步的,所述步骤3具体操作如下:
步骤3.1、采用公式(11)对手语孤立词动作对应的振幅信息进行奇异值分解,得到矩阵s;将矩阵s中的最大奇异值设置为0,得到矩阵s’;根据矩阵s’,采用公式(12)计算得到去除环境影响的手语孤立词动作对应的振幅信息;
s=usvt(11)
其中,s表示手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s表示n*l的矩阵;v为l*l的矩阵;vt为v的转置;n和l均为正整数;
s'=us'vt(12)
其中,s’表示去除环境影响的手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s’为n*l的矩阵,n和l均为正整数;
步骤3.2、采用公式(13)将去除环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,得到多个映射整数,并按照采集csi信号的天线对的顺序将多个映射整数对应到rgb三通道中,得到图像;
其中,gnl表示第n条csi流的第i个振幅值经过映射后的值,gnl为正整数;s’nl表示第n条csi流的第i个振幅值映射前的值,s’nl为正数;max(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最大振幅值,且max(s')为正数;min(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最小振幅值,且min(s')为正数。
进一步的,所述步骤4具体操作如下:
将得到的图像和去除环境影响的手语孤立词动作对应的振幅信息输入到训练好的手语孤立词识别网络,采用训练好的手语孤立词识别网络中的删除全连接层的vgg16网络对图像进行计算,得到图像特征;采用训练好的手语孤立词识别网络中的lstm层网络对去除环境影响的手语孤立词动作对应的振幅信息进行计算,得到时序特征;采用训练好的手语孤立词识别网络中全连接层网络对得到的图像特征与时序特征进行融合,得到一维输出向量,所述一维输出向量中最大值所在的列数表示待识别的手语孤立词动作的类别,得到待识别的手语孤立词动作的类别。
进一步的,所述步骤1具体操作如下:
步骤1.1、将wi-fi发送设备作为wi-fi发送端,将wi-fi接收设备作为wi-fi接收端,当用户在wi-fi发送端和wi-fi接收端之间做出待识别的手语孤立词动作时,wi-fi接收端按照wi-fi发送端与wi-fi接收端之间的天线对的顺序采集获取csi信号;所述csi信号为与手语孤立词相对应的csi信号和不做手语孤立词动作时相对应的csi信号;所述csi信号包括3条天线对的信号,每条天线对有30个csi流,总计90条csi流;
步骤1.2、采用公式(8)计算得到csi信号的振幅信息;采用巴特沃斯滤波器对得到的csi信号的振幅信息进行降噪处理,得到降噪后的振幅信息;
a'=||h||(8)
其中,a'表示csi信号的振幅信息,为一个csi流总数*采集csi信号总长度的正数矩阵;h表示csi信号,为csi流总数*采集csi信号总长度的复数矩阵。
与现有技术相比,本发明的有益效果如下:
1、本发明提供了一种面向wi-fi信号的手语孤立词识别网络的构建方法,使用卷积神经网络提取图像特征,使用lstm层网络提取时序特征;最终将卷积神经网络的图像特征和时序特征进行融合,使用全连接层网络进行手语孤立词识别分类,并通过对手语孤立词识别网络进行训练,得到手语孤立词识别网络,能够有效提高手语孤立词识别的准确性和鲁棒性。
2、本发明提供了一种面向wi-fi信号的手语孤立词分类方法,基于wi-fi信号,克服了随时佩戴设备与易侵犯隐私的局限性;采用训练好的手语孤立词识别网络,使用卷积神经网络提取图像特征,使用lstm层网络提取时序特征;最终将卷积神经网络的图像特征和时序特征进行融合,使用全连接层网络进行手语孤立词识别分类,有效提高了手语孤立词识别的准确性和鲁棒性。
附图说明
图1是本发明的流程图;
图2是csi信号的振幅信息的示意图;
图3是降噪后的振幅信息的示意图;
图4是划分窗口的示意图;
图5是分割手语孤立词动作的示意图;其中图a为窗口振幅信息方差平均值序列的示意图;图b为手语孤立词动作的示意图;
图6是去除环境影响的手语孤立词动作对应的振幅信息转换为图像的示意图;
图7是手语孤立词识别网络的结构图;
图8是采用5折交叉法的结果对比图。
具体实施方式
如图1-7所示,本发明一种面向wi-fi信号的手语孤立词识别深度网络构建方法,具体包含以下步骤:
步骤1、采集获取csi信号;并对获取的csi信号进行处理,得到降噪后的振幅信息;所述csi表示信道状态信息;
步骤2、将降噪后的振幅信息按照窗口的大小进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;根据窗口的振幅信息序列中多个窗口的振幅信息,计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,根据窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成得到窗口的振幅信息方差的平均值序列;根据窗口的振幅信息方差的平均值序列中多个窗口的振幅信息方差的平均值的大小,判断得到手语孤立词片段对应的振幅信息;由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息;
步骤3、对得到的手语孤立词动作对应的振幅信息进行奇异值分解,得到去除环境影响的手语孤立词动作对应的振幅信息;对得到的去除环境影响的手语孤立词动作对应的振幅信息进行映射处理,得到图像;
步骤4、由删除全连接层的vgg16网络、lstm层网络和全连接层网络构成得到手语孤立词识别网络;采用手语孤立词识别网络对得到的图像和去除环境影响的手语孤立词动作对应的振幅信息进行处理,得到一维输出向量;根据一维输出向量,采用交叉熵损失函数计算得到损失值;将得到的损失值输入到手语孤立词识别网络中,采用梯度下降算法对手语孤立词识别网络进行训练,得到训练好的手语孤立词识别网络。
本发明在构建手语孤立词识别网络时,使用卷积神经网络提取图像特征,使用lstm层网络提取时序特征;最终将卷积神经网络的图像特征和时序特征进行融合,使用全连接层网络进行手语孤立词识别分类,并通过对手语孤立词识别网络进行训练,得到训练好的手语孤立词识别网络,有效提高手语孤立词动作识别的准确性和鲁棒性。
具体的,步骤1的具体操作如下:
步骤1.1、将wi-fi发送设备作为wi-fi发送端,将wi-fi接收设备作为wi-fi接收端,当用户在wi-fi发送端和wi-fi接收端之间做出已知手语孤立词动作时,wi-fi接收端按照wi-fi发送端与wi-fi接收端之间的天线对的顺序采集获取csi信号;所述csi信号为与手语孤立词相对应的csi信号和不做手语孤立词动作时相对应的csi信号;所述csi信号包括3条天线对的信号,每条天线对有30个csi流,总计90条csi流;
步骤1.2、采用公式(1)计算得到csi信号的振幅信息a';采用巴特沃斯滤波器对得到的csi信号的振幅信息a'进行降噪处理,得到降噪后的振幅信息a;
a'=||h||(1)
其中,a'表示csi信号的振幅信息,为一个csi流总数*采集csi信号总长度的正数矩阵;h表示csi信号,为csi流总数*采集csi信号总长度的复数矩阵;
该方式中由于csi信号中包含很多高频噪声,需要对csi信号的振幅信息进行降噪处理,得到降噪后的振幅信息。
具体的,步骤2的具体操作如下:
步骤2.1,采用0.2s的时间长度作为窗口大小,对降噪后的振幅信息a进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;采用公式(2)计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值;由于采集的csi信号长度大多数情况下不能被窗口大小整除,所以最后一个窗口会和之前窗口的长度不同,但这并不影响分割算法的效果。
其中,mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
根据得到的窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,采用公式(3)计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成窗口的振幅信息方差的平均值序列;
其中,var(i)表示第i个窗口的振幅信息方差的平均值,var(i)≥0;n表示csi流的总条数,k∈[1,k],n∈[1,n],n为正整数;mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
步骤2.2,设置方差阈值θ和动作停顿缓冲区最大时间长度tp,其中θ和tp均为正数;将窗口的振幅信息序列中的第一个窗口的振幅信息作为当前窗口的振幅信息;将窗口的振幅信息方差的平均值序列中第一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值;
步骤2.3,当当前窗口的振幅信息方差的平均值大于θ时,表示手语孤立词动作开始,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息,并设置动作停顿缓存区;并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,执行步骤2.4;
当当前窗口的振幅信息方差的平均值小于θ时,并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.3相同的操作;
步骤2.4,当当前窗口的振幅信息方差的平均值大于θ时,若动作停顿缓冲区为空时,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息;若动作停顿缓冲区不为空时,将动作停顿缓冲区中的振幅信息作为手语孤立片段对应的振幅信息,并将当前窗口的振幅信息作为手语孤立片段对应的振幅信息;将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;
当当前窗口的振幅信息方差的平均值小于θ时,则将当前窗口的振幅信息加入到动作停顿缓存区,当动作停顿缓冲区的时间长度小于tp时,将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;当动作停顿缓冲区的时间长度大于tp时,表示手语孤立词动作结束,删掉动作停顿缓冲区的振幅信息,执行步骤2.5;
步骤2.5,由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息。
实际采集时,无法精确获取手语孤立词动作,因此获取的csi信号包括与手语孤立词相对应的csi信号和不做手语孤立词动作时相对应的csi信号,通过分割算法得到手语孤立词动作对应的振幅信息;
由于用户在做手语孤立词动作的时会出现短暂停顿,这些停顿会使振幅方差变小而小于阈值,当直接使用方差阈值分割动作时便会得到不完整的手语孤立词动作片段,因此本发明引入动作停顿缓冲区机制解决此问题。
具体的,步骤3的具体操作如下:
步骤3.1、采用公式(4)对手语孤立词动作对应的振幅信息进行奇异值分解,得到矩阵s;将矩阵s中最大奇异值设置为0,得到的矩阵s’;根据矩阵s’,采用公式(5)计算得到去除环境影响的手语孤立词动作对应的振幅信息;
s=usvt(4)
其中,s表示手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s表示n*l的矩阵;v为l*l的矩阵;vt为v的转置;n和l均为正整数;
s'=us'vt(5)
其中,s’表示去除环境影响的手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s’为n*l的矩阵,n和l均为正整数;
步骤3.2、采用公式(6)将去除环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,得到多个映射整数,按照采集csi信号的天线对的顺序将多个映射整数对应到rgb三通道中,得到图像;所述rgb表示代表红、绿和蓝三个通道的颜色;
其中,gnl表示第n条csi流的第i个振幅值经过映射后的值,gnl为正整数;s’nl表示第n条csi流的第i个振幅值映射前的值,s’nl为正数;max(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最大振幅值,且max(s')为正数;min(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最小振幅值,且min(s')为正数;
步骤3.3、重复执行与步骤1-3.2相同的操作多次,得到多个csi信号对应的图像和除环境影响的手语孤立词动作对应的振幅信息;将得到的多个csi信号进行划分,得到多批csi信号;根据多批csi信号,将得到的多个csi信号对应的图像和除环境影响的手语孤立词动作对应的振幅信息进行划分并编号,得到多批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息;将第一批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息作为当前输入数据。
由于本发明中的卷积神经网络输入格式需为rgb图片格式,且手语孤立词动作是一个浮点数矩阵,需要将去出环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,并转化为rgb图片格式。
具体的,步骤4的具体操作如下:
将当前输入数据输入到手语孤立词识别网络中,所述的手语孤立词识别网络包括删除全连接层的vgg16网络、lstm层网络与全连接层网络,所述删除全连接层的vgg16网络为采用已知的imagenet数据集预训练过的vgg16网络模型参数进行更新的网络;所述全连接层网络包括批正则化层和3个全连接层,所述3个全连接层之间分别设有dropout层;所述批正则化层用于加快手语孤立词识别网络收敛;所述dropout层用于避免手语孤立词识别网络产生过拟合;
所述vgg16网络为2014年牛津大学视觉几何组提出的一种卷积神经网络;所述lstm层网络表示长短期记忆层网络;
采用所述删除全连接层的vgg16网络分别对当前输入数据的多个图像进行计算,得到多个图像特征;采用所述lstm层网络分别对当前输入数据的多个去除环境影响的手语孤立词动作对应的振幅信息进行计算,得到多个时序特征;采用全连接层网络分别对得到的多个图像特征与多个时序特征中每个图像特征和时序特征整体进行融合,得到多个一维输出向量;
采用公式(7)即交叉熵损失函数计算损失值:
其中,l表示损失值,且l>0;i表示包含当前输入数据信息的第i个csi信号;且1≤i≤m,m表示包含当前输入数据信息的csi信号的数量,且为正整数;k表示待识别的类别个数,且为正整数;yi表示包含当前输入数据信息的csi信号中第i个csi信号的one-hot编码的类别标签,且为一个长度为k的一维向量;
步骤4.2、将得到的损失值输入到手语孤立词识别网络中,采用梯度下降算法对手语孤立词识别网络进行调整,得到新的手语孤立词识别网络;将新的手语孤立词识别网络作为手语孤立词识别网络,按照编号的顺序依次将当前输入数据的下一批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息作为当前输入数据,重复执行与步骤4.1-4.2相同的操作多次,得到多个损失值和新的手语孤立词识别网络,直至得到的多个损失值收敛时操作结束;将新的手语孤立词识别网络作为训练好的手语孤立词识别网络。
在实际应用中,为了防止梯度爆炸和过拟合现象,需要全连接层网络中的全连接层前加入批正则化层,并在全连接层中的各层之间分别加入dropout层。在训练手语孤立词识别深度网络时,为了在少量样本的情况下可以使用深度网络提取特征且不出现严重的过拟合现象,需要对手语孤立词识别深度网络进行训练,得到训练好的手语孤立词识别深度网络。
本发明提供了一种面向wi-fi信号的深度网络手语孤立词识别方法,具体包括以下步骤:
步骤1、采集获取csi信号,并对获取的csi信号进行处理,得到降噪后的振幅信息;
步骤2、将降噪后的振幅信息按照窗口的大小进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;根据窗口的振幅信息序列中多个窗口的振幅信息,计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,根据窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成得到窗口的振幅信息方差的平均值序列;根据窗口的振幅信息方差的平均值序列中多个窗口的振幅信息方差的平均值的大小,判断得到手语孤立词片段对应的振幅信息;由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息;
步骤3、对得到的手语孤立词动作对应的振幅信息进行奇异值分解,得到去除环境影响的手语孤立词动作对应的振幅信息;对得到的去除环境影响的手语孤立词动作对应的振幅信息进行映射处理,得到图像;
步骤4、采用训练好的手语孤立词识别网络对得到的图像和去除环境影响的手语孤立词动作对应的振幅信息进行分类,得到待识别的手语孤立词动作的类别。
本发明基于wi-fi信号,克服了随时佩戴设备与易侵犯隐私的局限性,采用训练好的手语孤立词识别网络,使用卷积神经网络提取图像特征,使用lstm层网络提取时序特征;最终将卷积神经网络的图像特征和时序特征进行融合,使用全连接层网络进行手语孤立词识别分类,有效提高手语孤立词识别的准确性和鲁棒性。
具体的,步骤1的具体操作如下:
步骤1.1、将wi-fi发送设备作为wi-fi发送端,将wi-fi接收设备作为wi-fi接收端,当用户在wi-fi发送端和wi-fi接收端之间做出待识别的手语孤立词动作时,wi-fi接收端按照wi-fi发送端与wi-fi接收端之间的天线对的顺序采集获取csi信号;所述csi信号为与手语孤立词相对应的csi信号和不做手语孤立词动作时相对应的csi信号;所述csi信号包括3条天线对的信号,每条天线对有30个csi流,总计90条csi流;
步骤1.2、采用公式(8)计算得到csi信号的振幅信息a';采用巴特沃斯滤波器对得到的csi信号的振幅信息a'进行降噪处理,得到降噪后的振幅信息a;
a'=||h||(8)
其中,a'表示csi信号的振幅信息,为一个csi流总数*采集csi信号总长度的正数矩阵;h表示csi信号,为csi流总数*采集csi信号总长度的复数矩阵;
该方式中由于csi信号中包含很多高频噪声,需要对csi信号的振幅信息进行降噪处理,得到降噪后的振幅信息。
具体的,步骤2的具体操作如下:
步骤2.1,采用0.2s的时间长度作为窗口大小,对降噪后的振幅信息a进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;采用公式(9)计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值;由于采集的csi信号长度大多数情况下不能被窗口大小整除,所以最后一个窗口会和之前窗口的长度不同,但这并不影响分割算法的效果。
其中,mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
根据得到的窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,采用公式(10)计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成窗口的振幅信息方差的平均值序列;
其中,var(i)表示第i个窗口的振幅信息方差的平均值,var(i)≥0;n表示csi流的总条数,k∈[1,k],n∈[1,n],n为正整数;mean(i)n表示的第i个窗口的第n条csi流振幅信息的均值,mean(i)n>0;
步骤2.2,设置方差阈值θ和动作停顿缓冲区最大时间长度tp,其中θ和tp均为正数;将窗口的振幅信息序列中的第一个窗口的振幅信息作为当前窗口的振幅信息;将窗口的振幅信息方差的平均值序列中第一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值;
步骤2.3,当当前窗口的振幅信息方差的平均值大于θ时,表示手语孤立词动作开始,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息,并设置动作停顿缓存区;并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,执行步骤2.4;
当当前窗口的振幅信息方差的平均值小于θ时,并将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.3相同的操作;
步骤2.4,当当前窗口的振幅信息方差的平均值大于θ时,若动作停顿缓冲区为空时,将当前窗口的振幅信息作为手语孤立词片段对应的振幅信息;若动作停顿缓冲区不为空时,将动作停顿缓冲区中的振幅信息作为手语孤立片段对应的振幅信息,并将当前窗口的振幅信息作为手语孤立片段对应的振幅信息;将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;
当当前窗口的振幅信息方差的平均值小于θ时,则将当前窗口的振幅信息加入到动作停顿缓存区,当动作停顿缓冲区的时间长度小于tp时,将当前窗口的振幅信息方差的平均值的下一个窗口的振幅信息方差的平均值作为当前窗口的振幅信息方差的平均值,重复执行与步骤2.4相同的操作,直至最后一个窗口的振幅信息方差的平均值操作完成时结束;当动作停顿缓冲区的时间长度大于tp时,表示手语孤立词动作结束,删掉动作停顿缓冲区的振幅信息,执行步骤2.5;
步骤2.5,由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息。
实际采集时,无法精确获取手语孤立词动作,因此获取的csi信号包括与手语孤立词动作相对应的csi信号和不做手语孤立词动作时相对应的csi信号,通过分割方法得到手语孤立词动作对应的振幅信息;
由于用户在做手语孤立词动作的时会出现短暂停顿,这些停顿会使振幅方差变小而小于阈值,当直接使用方差阈值分割手语孤立词动作时便会得到不完整的手语孤立词动作,因此本发明引入动作停顿缓冲区机制解决此问题。
具体的,步骤3的具体操作如下:
步骤3.1、采用公式(11)对手语孤立词动作对应的振幅信息进行奇异值分解,得到矩阵s;将矩阵s中最大奇异值设置为0,得到的矩阵s’;根据矩阵s’,采用公式(12)计算得到去除环境影响的手语孤立词动作对应的振幅信息;
s=usvt(11)
其中,s表示手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s表示n*l的矩阵;v为l*l的矩阵;vt为v的转置;n和l均为正整数;
s'=us'vt(12)
其中,s’表示去除环境影响的手语孤立词动作对应的振幅信息,为信号流总数n×手语孤立词动作的长度l的矩阵;u为n*n的矩阵;s’为n*l的矩阵,n和l均为正整数;
步骤3.2、采用公式(13)将去除环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,得到多个映射整数,并按照采集csi信号的天线对的顺序将多个映射整数对应到rgb三通道中,得到图像;所述rgb表示代表红、绿和蓝三个通道的颜色;
其中,gnl表示第n条csi流的第i个振幅值经过映射后的值,gnl为正整数;s’nl表示第n条csi流的第i个振幅值映射前的值,s’nl为正数;max(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最大振幅值,且max(s')为正数;min(s')表示去除环境影响的手语孤立词动作对应的振幅信息中的最小振幅值,且min(s')为正数;
由于本发明中的卷积神经网络输入格式需为rgb图片格式,且手语孤立词动作是一个浮点数矩阵,需要将去出环境影响的手语孤立词动作对应的振幅信息映射为0-255之间的整数,并转化为rgb图片格式。
具体的,步骤4的具体操作如下:
将得到的图像和去除环境影响的手语孤立词动作对应的振幅信息输入到训练好的手语孤立词识别网络,采用训练好的手语孤立词识别网络中的删除全连接层的vgg16网络对图像进行计算,得到图像特征;采用训练好的手语孤立词识别网络中的lstm层网络对去除环境影响的手语孤立词动作对应的振幅信息进行计算,得到时序特征;采用训练好的手语孤立词识别网络中全连接层网络对得到的图像特征与时序特征进行融合,得到一维输出向量,所述一维输出向量中最大值所在的列数表示待识别的手语孤立词动作的类别,得到待识别的手语孤立词动作的类别。
由于手语孤立词本身具有时序性,相同的肢体动作不同的顺序可能代表不同的含义,因此时序信息在识别过程中也是相当重要的,为了获取这些时序上的信息,本发明使用lstm层网络提取时序特征;最终将卷积神经网络的图像特征和时序特征进行融合,使用全连接层网络进行手语孤立词识别分类,实现手语孤立词动作的识别;本发明基于wi-fi信号,克服了随时佩戴设备与易侵犯隐私的局限性,并对少量样本能够很好的进行手语孤立词动作的识别,能够有效提高手语孤立词识别的准确性和鲁棒性。
实施例
本实验中,在场景复杂的会议室中架设csi信号采集设备,使用商用wi-fi路由器作为发送端,携带iwl5300的电脑作为接收端,且接收端需要安装特定的网卡驱动(linux-80211n-csitool-supplementary)以便获取csi信号,当用户在wi-fi发送端和wi-fi接收端之间做出手语孤立词动作时,wi-fi接收端的电脑便可获取csi信号;设置信号的采样率为100hz。根据信号的采样率决定划分窗口的大小,一般设置为采样率*0.2,即窗口的时间长度为0.2秒;根据得到的窗口方差序列,一般情况下手语孤立词片段的方差会大于方差最大值的0.3倍,因此取方差阈值为方差峰值的0.3倍;实验中采集的数据包含100个常用手语动作,每类采集10个样本,总计1000个样本;实验中每批输入到手语孤立词识别网络中的样本的数量为64;
具体操作如下:
步骤1、当用户在wi-fi发送端和wi-fi接收端之间做出手语孤立词动作时,wi-fi接收端按照wi-fi发送端与wi-fi接收端之间的天线对的顺序采集获取csi信号;并对获取的csi信号进行降噪处理,得到降噪后的振幅信息a;
步骤2、将降噪后的振幅信息按照窗口的大小进行划分,得到多个窗口的振幅信息;并对多个窗口的振幅信息进行编号,得到窗口的振幅信息序列;根据得到的窗口的振幅信息序列中多个窗口的振幅信息,计算得到窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,根据窗口的振幅信息序列中多个窗口每条csi流的振幅信息的均值,计算得到窗口的振幅信息序列中多个窗口的振幅信息方差的平均值;由窗口的振幅信息序列中多个窗口的振幅信息方差的平均值构成得到窗口的振幅信息方差的平均值序列;根据窗口的振幅信息方差的平均值序列中多个窗口的振幅信息方差的平均值的大小,判断得到手语孤立词片段对应的振幅信息;由手语孤立词片段对应的振幅信息构成得到手语孤立词动作对应的振幅信息;
步骤3、根据得到的手语孤立词动作对应的振幅信息,得到去除环境影响的手语孤立词动作对应的振幅信息,并将去除环境影响的手语孤立词动作对应的振幅信息进行映射处理,在rgb三通道中得到图像;重复执行与步骤1-3相同的操作多次,得到多个csi信号、图像和除环境影响的手语孤立词动作对应的振幅信息;将获取的csi信号进行划分并编号,得到多批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息;将第一批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息作为当前输入数据;
步骤4、采用由删除全连接层的vgg16网络、lstm层网络与全连接层网络构成的手语孤立词识别网络对当前输入数据进行处理,得到多个一维输出向量;根据多个一维输出向量,采用交叉熵损失函数计算得到损失值,将损失值输入到手语孤立词识别网络中,采用梯度下降算法对手语孤立词识别网络进行调整,得到新的手语孤立词网络;按照编号的顺序依次将当前输入数据的下一批csi信号对应的图像和去除环境影响的手语孤立词动作对应的振幅信息作为当前输入数据,将得到新的手语孤立词识别网络作为手语孤立词识别网络,重复执行与步骤4相同的操作多次,得到多个损失值和新的手语孤立词识别网络,直至得到的多个损失值收敛时操作结束;将新的手语孤立词识别网络作为训练好的手语孤立词识别网络,得到训练好的手语孤立词识别网络。
步骤5、采集并处理待识别的csi信号,得到图像和去除环境影响的手语孤立词动作对应的振幅信息,将得到的图像和去除环境影响的手语孤立词动作对应的振幅信息输入到训练好的手语孤立词识别深度网络中进行融合,得到待识别的手语孤立词动作的类别。
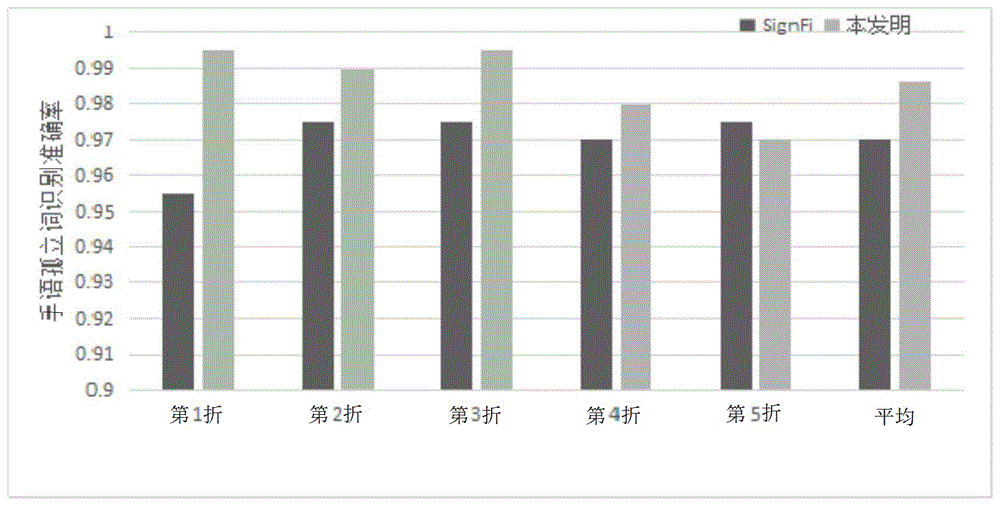
本发明使用5折交叉法在所述采集的数据集上进行实验,实验结果如图8所示,其中第1折、第2折、第3折、第4折的识别准确率与5折的平均识别准确率均高于2018年提出的signfi方法,平均识别准确率达到了98.6%,平均识别错误率仅为1.4%,相比于signfi方法,错误率降低了53%。
- 还没有人留言评论。精彩留言会获得点赞!