一种基于空间分维理论寻找相似流域的方法与流程
本发明涉及水文技术领域,具体涉及一种基于空间分维理论寻找相似流域的方法。
背景技术:
我国河流众多,流域面积200至3000km2的中小流域近9000个。近年来,受气候变化影响,由局地强降水造成的中小河流突发性洪水频繁发生,已成为造成人员伤亡的主要灾种。中小流域由于通常处于地形复杂、坡度陡峻的偏远山区,急促上涨的洪水极易形成危害当地的居民人身安全和社会经济的洪涝灾害,因此对中小流域突发性洪水进行快速预警成为亟待解决的重要问题。
水文模型式用以进行洪水预报的重要工具,在构建水文模型时,首先需要的就是基于流域中的降雨,蒸发以及流量等观测资料来率定模型参数。然而山区性中小流域往往地处偏远,观测站点稀疏,难以取得丰富的水文气象资料来进行模型的构建。对于这种情况,常用的方法就是采用自然地理特征相似的流域中的资料来代替缺少资料的流域进行模型参数的率定。因此寻找到合适的相似流域就成为无资料地区水文模型构建的关键步骤。然而目前已有的寻找相似流域的方法大都是采用流域平均坡度,坡向以及高程作为特征值。这种方法仅仅能够反映出流域的大致的自然地理特征,而对流域内部的地理特征空间差异却难以考虑,从而对相似流域的寻找带来较大的不确定性。基于遥感、地理信息以及数字流域等技术的发展,采用数值矩阵描述地表高程变化的栅格数字高程模型(dem,digitalelevationmodel)逐步成熟,并得到了广泛的应用。尤其是在地形复杂的山区性中小流域中,dem数据因其能够较为准确地考虑流域内地形变化而具有重要的应用价值。如何利用dem数据在山区性流域中的优势来相似流域的判断方法进行完善,从而在一定程度上提高对于流域内部自然地理特征空间分异性的重视,也是流域相似性研究过程中的重点和难点之一。
为了进一步促进流域相似性研究,需要更深地入研究考虑流域内部自然地理特征空间分异性的相似流域判别方法。
分维又叫做分形维数,是分形理论中最重要的一个概念,它是对非光滑、非规则、破碎的等极其复杂的分形客体进行定量刻画的重要参数,它表征了分形体的复杂程度、粗糙程度。分维越大,客体就越复杂、越粗糙,反之亦然。通常人们熟知的整型维数只能表示几何物体占据客观世界中的几个特定的维度,如一维,二维,三维等。然而随着图形学和数学的不断发展,人们发现许多不能够简单使用整数维度来描述的图形或者是函数,如蜿蜒曲折的海岸线的维度就是介于一维和二维之间。
分形几何及其分维概念否定了在传统几何中点、线、面、体等之间性质全然不同的绝对分明的界限,深刻地提示了点线面体之间、整形(即规则图形)与分形之间、维数的离散与连续之间的辩证关系。提出了一种描述几何物体在发展变化过程中的动态维数度量方法。对于自然状态下的流域而言,由于受到内外营力的共同作用,流域内各个区域内的地形特征如坡度,坡向以及高程等一直处于不断发展变化的过程中,因此简单地采用一个平均的数值已经不能准确地来描述流域的地形特征,从而在流域相似性研究的时候容易造成误判,进而导致水文模型构建的不合理,使得最终的洪水预报结果存在较大误差,为山区性中小流域的山洪防治留下隐患。
因而对于流域内自然特征的空间分异性特征的忽略不利于流域相似性研究的发展。
针对以上不足,如何考虑流域内自然特征的空间分异性特征,计算坡度,坡向以及高程等因子的空间分维数,进而对流域之间的相似程度进行量化,正发明人需要解决的问题。
技术实现要素:
本发明所要解决的技术问题是针对背景技术中所涉及到的缺陷,提供一种基于空间分维理论寻找相似流域的方法,具有数据来源稳定可靠、计算效率高、结果客观合理等优点,有利于流域相似性的进一步深入研究。
本发明为解决上述技术问题采用以下技术方案:
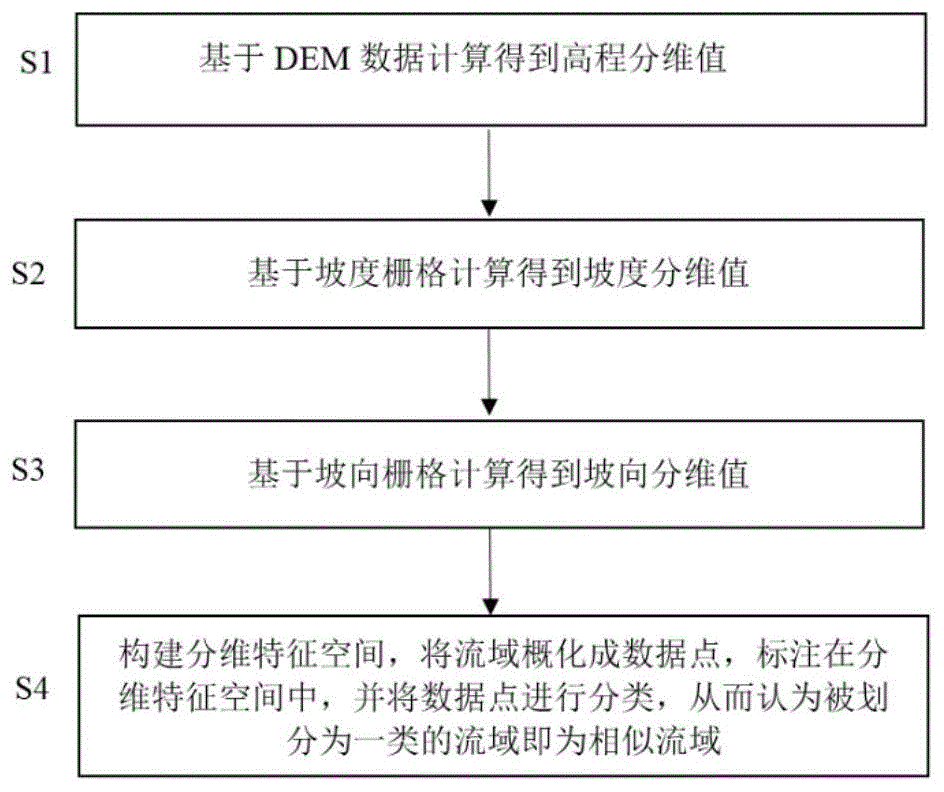
一种基于空间分维理论寻找相似流域的方法,包括以下步骤:
步骤1),基于数字高程模型数据、即dem数据将流域划分为若干正交的栅格单元,得到每一个栅格单元中的高程,从而得到流域的高程栅格raster_ele,并计算得到高程分维值fra_ele;
步骤2),计算每一个栅格单元中的坡度,得到流域的坡度栅格raster_slope,并计算得到坡度分维值fra_slope;
步骤3),计算每一个栅格单元中的坡向,得到流域的坡向栅格raster_slopedir,并计算得到坡向分维值fra_slopedir;
步骤4),构建分维特征空间,将流域概化成数据点,标注在分维特征空间中,并将数据点进行分类,被划分为一类的流域即为相似流域,具体如下:
步骤4.1),以三个相互正交的单位向量
步骤4.2),依据流域的高程分维值、坡度分维值以及坡向分维值将流域概化成数据点,标注在分维特征空间中;
步骤4.3),基于谱聚类(spectralclustering)数据分析方法,将分维特征空间中的数据点之间进行分割归类,被划分为一类的流域即为相似流域。
作为本发明一种基于空间分维理论寻找相似流域的方法进一步的优化方案,所述步骤1)的具体步骤如下:
步骤1.1),基于dem数据将流域划分为若干正交的栅格单元,得到每一个栅格单元中的高程,从而得到流域的高程栅格raster_ele;
步骤1.2),在高程栅格raster_ele的基础上,以分辨率为采样步长,得到逐行的高程剖面,并计算逐行的高程剖面的空间分维值fcele,即对每一行高程剖面,以其每一个栅格单元的高程值为纵坐标、以栅格单元的边长累积值作为横坐标构建高程剖面曲线curc_elei,并采用盒维数法计算行高程剖面曲线curc_elei的空间分维值fcelei,最终得到高程分维的列向量col_ele:
col—ele={fcele0,fcele1,…fcelei,…fcelei}
式中:i为行高程剖面的编号,其值从0到i,i为高程栅格的总行数;
步骤1.3),在高程栅格raster_ele的基础上,以分辨率为采样步长,得到逐列的高程剖面,并计算逐列的高程剖面的空间分维值frele,即对每一列高程剖面,以其每一个栅格单元的高程值为纵坐标,以栅格单元的边长累积值作为横坐标构建高程剖面曲线curr_elej,并采用盒维数法计算行高程剖面曲线curr_elej的空间分维值fcelei,最终得到高程分维的行向量row_ele:
row—ele={frele0,frele1,…frelej,…frelej}
式中:j为列高程剖面的编号,其值从0到j,j为高程栅格的总列数;
步骤1.4),在行向量row_ele和列向量col_ele的基础上计算得到高程分维值fra_ele:
作为本发明一种基于空间分维理论寻找相似流域的方法进一步的优化方案,所述步骤2)的具体步骤如下:
步骤2.1),计算每一个栅格单元中的坡度,得到流域的坡度栅格raster_slope;
以栅格单元cell为中心,通过周围栅格单元的高程值与该栅格单元的高程值的对比,找出与其相比最低的栅格单元celld,并计算cell和celld之间的高程差dhmax和水平投影距离dis,结合dhmax和dis计算栅格单元cell的坡度s:
s=dhmax/dis
步骤2.2),在坡度栅格raster_slope的基础上,以分辨率为采样步长,得到逐行的坡度剖面,并计算逐行的坡度剖面的空间分维值fcslope,即对每一行坡度剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡度剖面曲线curc_slopem,并采用盒维数法计算行坡度剖面曲线curc_slopem的空间分维值fcslopem,最终得到坡度分维的列向量col_slope:
col_slope={fcslope0,fcslope1,…fcslopem,…fcslopem}
式中:m为行坡度剖面的编号,其值从0到m,m为坡度栅格的总行数;
步骤2.3),在坡度栅格raster_slope的基础上,以分辨率为采样步长,得到逐列的坡度剖面,并计算逐列的坡度剖面的空间分维值frslope,即对每一列坡度剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡度剖面曲线curr_slopen,并采用盒维数法计算行坡度剖面曲线curr_slopen的空间分维值fcslopen,最终得到坡度分维的行向量row_slope:
row_slope={frslope0,frslope1,…fcslopen,…frslopen}
式中:n为列坡度剖面的编号,其值从0到n,n为坡度栅格的总列数;
步骤2.4),在行向量row_slope和列向量col_slope的基础上计算得到坡度分维值fra_slope:
作为本发明一种基于空间分维理论寻找相似流域的方法进一步的优化方案,所述步骤3)的具体步骤如下:
步骤3.1),计算每一个栅格单元中的坡向,得到流域的坡向栅格raster_slopedir;
步骤3.2),在坡向栅格raster_slopedir的基础上,以分辨率为采样步长,得到逐行的坡向剖面,并计算逐行的坡向剖面的空间分维值fcslopedir,即对每一行坡向剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡向剖面曲线curc_slopedirp,并采用盒维数法计算行坡向剖面曲线curc_slopedirp的空间分维值fcslopedirp,最终得到坡向分维的列向量col_slopedir:
col_slopedir={fcslopedir0,fcslopedir1,…fcslopedirp,…fcslopedirp}
式中:p为行坡向剖面的编号,其值从0到p,p为坡向栅格的总行数;
步骤3.3),在坡向栅格raster_slopedir的基础上,以分辨率为采样步长,得到逐列的坡向剖面,并计算逐列的坡向剖面的空间分维值frslopedir,即对每一列坡向剖面,以其每一个栅格单元的坡向值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡向剖面曲线curr_slopedirq,并采用盒维数法计算行坡向剖面曲线curr_slopedirq的空间分维值fcslopedirq,最终得到坡向分维的行向量row-slopedir:
row_slopedir={frslopedir0,frslopedir1,…fcslopedirq,…frslopedirq}
式中:q为列坡向剖面的编号,其值从0到q,q为坡向栅格的总列数;
步骤3.4),在行向量row_slopedir和列向量col_slopedir的基础上计算得到坡向分维值fra_slopedir:
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明提供的一种基于空间分维理论寻找相似流域的方法,以坡度,坡向以及高程为基础,量化了分维空间中坡度,坡向以及高程的分维数,进而采用数据挖掘的方法对相似的之间进行聚类判别。这样既保证了计算结果的精度与可靠性,同时解决了采用相似流域的资料来进行无资料地区的水文模型构建问题。且本方法主要应用流域数字高程模型,数据来源稳定可靠,方法中变量之间的函数关系明确,有利于相似流域的快速自动归类判别,通过数字流域技术以简化提取步骤,同时,保证了结果的客观合理性,有利于相似流域判别方法的快速直接调用,可以进一步促进数字水文学以及山区性中小流域山洪防治研究的深入发展。
附图说明
图1为本发明的流程示意图;
图2为大河坝流域高程栅格示意图;
图3为大河坝流域坡度栅格示意图;
图4为大河坝流域坡向栅格示意图;
图5为大河坝流域高程横向剖面示意图;
图6为大河坝流域高程纵向剖面示意图;
图7为大河坝流域坡度横向剖面示意图;
图8为大河坝流域坡度纵向剖面示意图;
图9为大河坝流域坡向横向剖面示意图;
图10为大河坝流域坡向纵向剖面示意图。
具体实施方式
下面结合附图以大河坝流域为例对本发明的技术方案做进一步的详细说明:
如图1所示,本发明公开了一种基于空间分维理论寻找相似流域的方法,包括以下步骤:
步骤1),基于数字高程模型数据、即dem数据将流域划分为若干正交的栅格单元,得到每一个栅格单元中的高程,从而得到流域的高程栅格raster_fle,并计算得到高程分维值fra_ele,具体如下:
步骤1.1),基于dem数据将流域划分为若干正交的栅格单元,得到每一个栅格单元中的高程,从而得到流域的高程栅格raster_fle,如图2所示;
dem(数字高程模型,digitalelevationmodel)是用数值矩阵形式表示地面高程的一种实体地面模型。它将地面概化成彼此相邻的正交栅格单元,栅格单元(一般为方形)的边长即是dem数据的分辨率,而栅格单元属性值的即是该栅格单元中的地表的高程。
借鉴dem数据的结构,采用与dem数据相同的分辨率将流域划分为若干正交的栅格单元,每一个栅格单元中的属性值即是高程,从而得到流域的高程栅格raster_ele;
步骤1.2),在高程栅格raster_fle的基础上,以分辨率为采样步长,得到逐行的高程剖面,如图5所示,并计算逐行的高程剖面的空间分维值fcele,最终得到高程分维的列向量col_fle;
col_ele={fcele0,fcele1,…fcelei,…fcelei}
式中:i为行高程剖面的编号,其值从0到i,i为高程栅格的总行数。以分辨率为采样步长,以这一行中每一个栅格单元的高程值为纵坐标,以栅格单元的边长累积值作为横坐标构建高程剖面曲线curc_elei,并采用盒维数法计算行高程剖面曲线curc_elei的空间分维值fcelei。采用同样的方法遍历所有的行高程栅格单元,得到高程分维的列向量col_fle。
步骤1.3),在高程栅格raster_ele的基础上,以分辨率为采样步长,得到逐列的高程剖面,如图6所示,并计算逐列的高程剖面的空间分维值frele,最终得到高程分维的行向量row_ele;
row_ele={frele0,frele1,…frelej,…frelej}
式中:j为列高程剖面的编号,其值从0到j,j为高程栅格的总列数。以分辨率为采样步长,以这一行中每一个栅格单元的高程值为纵坐标,以栅格单元的边长累积值作为横坐标构建高程剖面曲线curr_elej,并采用盒维数法计算行高程剖面曲线curr_elej的空间分维值fcelei。采用同样的方法遍历所有的行高程栅格单元,得到高程分维的列向量col_fle。
步骤1.4),在行向量row_fle和列向量col_ele的基础上计算得到高程分维值fra_ele;
步骤2),计算每一个栅格单元中的坡度,得到流域的坡度栅格raster_slope,并计算得到坡度分维值fra_slope,具体如下:
步骤2.1),计算每一个栅格单元中的坡度,得到流域的坡度栅格raster_slope,如图3所示;
以栅格单元cell为中心,通过周围栅格单元的高程值与该栅格单元的高程值的对比,找出与其相比最低的栅格单元celld,并计算cell和celld之间的高程差dhmax和水平投影距离dis,结合dhmax和dis计算栅格单元cell的坡度s:
s=dhmax/dis
按照以上方法遍历流域中每一个栅格单元,从而得到坡度栅格raster_slope。
步骤2.2),在坡度栅格raster_slope的基础上,以分辨率为采样步长,得到逐行的坡度剖面,并计算逐行的坡度剖面的空间分维值fcslope,即对每一行坡度剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡度剖面曲线curc_slopem,并采用盒维数法计算行坡度剖面曲线curc_slopem的空间分维值fcslopem,最终得到坡度分维的列向量col_slope:
col_slope={fcslope0,fcslope1,…fcslopem,…fcslopem}
式中:m为行坡度剖面的编号,其值从0到m,m为坡度栅格的总行数;
步骤2.3),在坡度栅格raster_slope的基础上,以分辨率为采样步长,得到逐列的坡度剖面,并计算逐列的坡度剖面的空间分维值frslope,即对每一列坡度剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡度剖面曲线curr_slopen,并采用盒维数法计算行坡度剖面曲线curr_slopen的空间分维值fcslopen,最终得到坡度分维的行向量row_slope:
row_slope={frslope0,frslope1,…fcslopen,…frslopen}
式中:n为列坡度剖面的编号,其值从0到n,n为坡度栅格的总列数;
步骤2.4),在行向量row_slope和列向量col_slope的基础上计算得到坡度分维值fra_slope:
步骤3),计算每一个栅格单元中的坡向,得到流域的坡向栅格raster_slopedir,并计算得到坡向分维值fra_slopedir,具体如下:
步骤3.1),计算每一个栅格单元中的坡向,得到流域的坡向栅格raster_slopedir,如图4所示;
步骤3.2),在坡向栅格raster_slopedir的基础上,以分辨率为采样步长,得到逐行的坡向剖面,并计算逐行的坡向剖面的空间分维值fcslopedir,即对每一行坡向剖面,以其每一个栅格单元的坡度值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡向剖面曲线curc_slopedirp,并采用盒维数法计算行坡向剖面曲线curc_slopedirp的空间分维值fcslopedirp,最终得到坡向分维的列向量col_slopedir:
col_slopedir={fcslopedir0,fcslopedir1,…fcslopedirp,…fcslopedirp}
式中:p为行坡向剖面的编号,其值从0到p,p为坡向栅格的总行数;
步骤3.3),在坡向栅格raster_slopedir的基础上,以分辨率为采样步长,得到逐列的坡向剖面,并计算逐列的坡向剖面的空间分维值frslopedir,即对每一列坡向剖面,以其每一个栅格单元的坡向值为纵坐标,以栅格单元的边长累积值作为横坐标构建坡向剖面曲线curr_slopedirq,并采用盒维数法计算行坡向剖面曲线curr_slopedirq的空间分维值fcslopedirq,最终得到坡向分维的行向量row_slopedir:
row_slopedir={frslopedir0,frslopedir1,…fcslopedirq,…frslopedirq}
式中:q为列坡向剖面的编号,其值从0到q,q为坡向栅格的总列数;
步骤3.4),在行向量row_slopedir和列向量col_slopedir的基础上计算得到坡向分维值fra_slopedir:
步骤4),构建分维特征空间,将流域概化成数据点,标注在分维特征空间中,并将数据点进行分类,被划分为一类的流域即为相似流域,具体如下:
步骤4.1),以三个相互正交的单位向量
步骤4.2),依据流域的高程分维值、坡度分维值以及坡向分维值将流域概化成数据点,标注在分维特征空间中;
步骤4.3),如图10所示,基于谱聚类(spectralclustering)数据分析方法,将分维特征空间中的数据点之间进行分割归类,被划分为一类的流域即为相似流域。
本技术领域技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!