针对航空安全报告叙述性文本的信息处理方法和装置与流程
本申请涉及航空安全技术领域,特别是涉及针对航空安全报告叙述性文本的信息处理方法和针对航空安全报告叙述性文本的信息处理装置。
背景技术:
安全一直是航空运输业的生命线,只有提前准确的发现并纠正系统中存在的缺陷,控制和消除航空安全隐患,才能积极预防飞行事故,确保飞行安全。航空安全报告系统asrs(aviationsafetyreportingsystem)是美国联邦航空管理局faa(federalaviationadministration)建立的安全自愿报告系统,主要用于收集大量来自航空从业人员(包括飞行员、管制员、乘务员、机务维修人员、保安人员以及其他相关人员)针对涉及到航空器运行过程中的不安全事件,或者当前航空安全系统中存在的潜在矛盾和不足之处,自愿匿名提交的不安全事件和安全隐患报告。这些安全报告是识别航空安全隐患和解释航空飞行事故发生原因的最佳信息来源。
传统的航空安全报告分析主要是对其中的结构化数据进行简单的查询和统计;而对报告中的非结构化部分,也即包含了大量对于事故经过和可能原因的文本描述内容的部分,由于需要航空领域专家花费大量的时间精力去分析研究,将极大受制于人力物力和财力,仅有小部分才可获得有效的分析结果;另外,人工分析这些非结构化数据的准确性和可靠性还严重依赖于分析人员的专业能力和相关经验。随着时间推移,产生的航空安全报告日积月累,目前已经收集了上百万份的各类安全报告,严重超出了专业分析人员的承载能力。
技术实现要素:
本申请提供了针对航空安全报告叙述性文本的信息处理方法和装置,以解决上述技术问题。
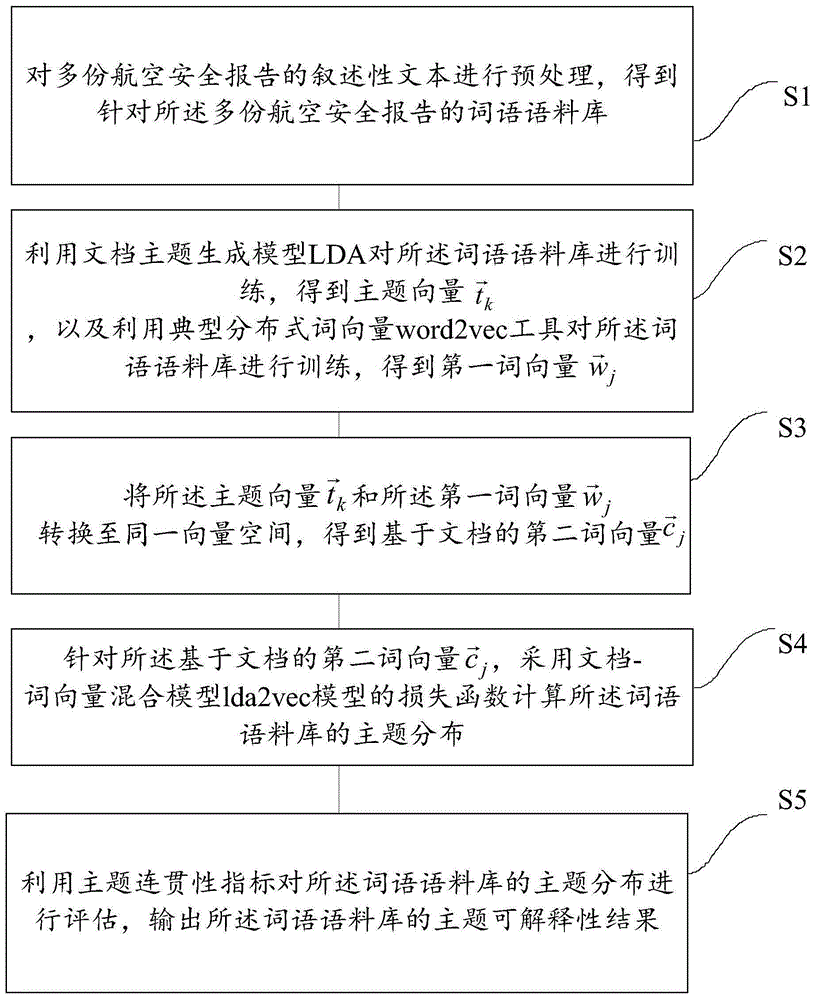
为了解决上述问题,本申请公开了针对航空安全报告叙述性文本的信息处理方法,所述方法包括:
步骤s1:对多份航空安全报告的叙述性文本进行预处理,得到针对所述多份航空安全报告的词语语料库;
步骤s2:利用文档主题生成模型lda对所述词语语料库进行训练,得到主题向量
步骤s3:将所述主题向量
步骤s4:针对所述基于文档的第二词向量
步骤s5:利用主题连贯性指标对所述词语语料库的主题分布进行评估,输出所述词语语料库的主题可解释性结果。
可选的,在步骤s1之前,所述方法包括:
对所述多份航空安全报告进行降维处理,得到叙述性文本;其中,所述叙述性文本包括描述航空安全问题的起因、地点和时间的文本。
可选的,所述步骤s1包括:
利用数据清洗规则对所述多份航空安全报告的叙述性文本进行预处理,得到词语语料库;
其中,所述数据清洗规则包括:
(1)拼写检查和扩展缩略词,根据航空安全报告系统asrs官网提供的缩略词表对部分缩略词进行扩展;
(2)将文本中的大写全部转换为小写;
(3)分词,去除非字母的数据、标点符号和停用词;
(4)词形还原;
(5)过滤词频小于10的单词。
可选的,所述步骤s3包括:
子步骤s31:针对所述主题向量
所述
其中,pjk表示主题k在文档j中所占的比例,k、j均为正整数,0≤pjk≤1且∑kpjk=1;
子步骤s32:利用所述第一词向量
所述
可选的,在步骤s4中,所述lda2vec模型的损失函数包括:
ld=λ∑jk(α-1)logpjk(公式5);
在公式3~5中,所述l表示lda2vec模型的损失函数,所述ld表示狄利克雷dirichlet分布似然下文档的权重损失函数,所述
其中,n表示所述词语语料库的主题数目,λ表示dirichlet优化的整体强度;
σ表示softmax函数,所述softmax函数的表达式为:
可选的,所述λ为200,所述词语语料库的主题分布为:
当所述α<1时,所述的主题分布倾向于稀疏;
当所述α≥1时,所述词语语料库的主题分布倾向于集中;
所述α为n-1。
可选的,在步骤s5中,所述主题连贯性指标的公式包括:
在公式6、7中,v表示描述所述词语语料库的主题的一组词项,所述词项包括多个主题词,ε是保证所述词语语料库的主题分布得分score为实数的平滑因子,vi表示表示一组词项中的第i个词项,vj表示表示一组词项中的第j个词项;
当所述主题词的得分越高,所述v的主题连贯性得分越高,所述词语语料库的主题可解释性越高。
基于同一发明构思,本申请还提出了针对航空安全报告叙述性文本的信息处理装置,所述装置包括:
报告预处理模块,用于对多份航空安全报告的叙述性文本进行预处理,得到针对所述多份航空安全报告的词语语料库;
语料库训练模块,用于利用文档主题生成模型lda对所述词语语料库进行训练,得到主题向量
向量转换模块,用于将所述主题向量
主题分布计算模块,用于针对所述基于文档的第二词向量
主题分布评估模块,用于利用主题连贯性指标对所述词语语料库的主题分布进行评估,输出所述词语语料库的主题可解释性结果。
本申请实施例还提供了一种装置,包括:
一个或多个处理器;和
其上存储有指令的一个或多个机器可读介质,当由所述一个或多个处理器执行时,使得所述装置执行本申请实施例所述的一个或多个的方法。
本申请实施例还提供了一个或多个机器可读介质,其上存储有指令,当由一个或多个处理器执行时,使得所述处理器执行本申请实施例所述的一个或多个的方法。
与现有技术相比,本申请包括以下优点:
本申请基于无监督的机器学习方法,首先通过对多份航空安全报告的叙述性文本预处理后得到词语语料库,利用lda模型和word2vec工具对所述词语语料库分别进行训练,得到主题向量
附图说明
图1是本申请针对航空安全报告叙述性文本的信息处理方法的步骤流程图;
图2是本申请利用lda训练词语语料库计算主题向量
图3是本申请主题连贯性-主题数目的曲线图;
图4是本申请lda模型和lda2vec模型提取的主题连贯性得分对比图;
图5是本申请针对航空安全报告叙述性文本的信息处理装置的结构框图。
具体实施方式
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。
目前随着机器学习(ml)和自然语言技术(nlp)的发展应用,业界许多专家开始尝试运用自然语言处理、机器学习以及文本挖掘等先进技术来分析航空安全报告中非结构化的文本数据。目前,对asrs航空安全报告(报告数据为全英文数据)中非结构化文本数据的研究仍主要针对安全报告问题分类、人为因素分析算法和模型等方面。早在2005年,posse等人基于通用模式规范语言cpsl(commonpatternspecificationlanguage)从安全报告叙述文本中提取人为表现因子的信息;2009年,oza等人基于支持向量机(svm)和非负矩阵分解(nmf-nonnegativematrixfactorization)对航空安全报告文档进行问题分类;2009年,persing等人应用半监督的自然语言处理技术对安全报告中的叙述文本进行原因识别;2011年,switzer等人提出基于主观性词汇中最相关词汇的航空安全报告整形因子(shapingfactor)的分类方法等。但上述这些研究都是依赖于初始数据集标签和训练数据集(包括由专家标记的安全报告),数据集标签和训练数据集的收集工作量大,且仍然严重依赖于分析人员的专业能力和相关经验,无法从根本上解决现有技术问题。
文本的主题分析旨在确定一个文本的主题结构,即识别所讨论的主题,界定主题的外延、跟踪主题的转换、觉察主题间的关系等,它是很多信息处理领域,比如文本理解、语言建模、信息的检索与抽取、文本分类等应用的基础与核心部分。
针对上述现有技术问题和主题分析的特性,本申请基于无监督的机器学习算法建立了一种可以代表领域专家对航空安全报告进行问题分类的算法和模型,可自动识别大量航空安全报告中叙述性文本数据潜在的主题(而非类别),并对识别出的主题进行相关的分析。上述主题表现为描述某一类相似安全事故的事件文档集合(简称为主题)。
接下来,在实施例1中对本申请的实现方式进行详细阐述。
实施例1:
如图1所示,示出了本申请针对航空安全报告叙述性文本的信息处理方法的步骤流程图,所述方法具体可以包括以下步骤:
美国联邦航空管理局faa的航空安全报告系统asrs公布的航空安全报告包含了大量的结构化参数,如机场、飞机、环境信息等,其中叙述(narrative)字段是提交报告的人员对发现的整个不安全事件详细的文本描述,是研究安全报告问题分类中的重点数据。由于报告中的叙述性文本受提交报告的人员的文化水平和职务差异的影响,存在许多的拼写错误和领域缩略词,所以为了达到有效信息的提取综合及无用信息的摈弃之目的,本申请首先对航空安全报告进行处理,提取出有效的叙述性文本。
所述叙述性文本的获取方法具体可以包括:
对所述多份航空安全报告进行降维处理,得到叙述性文本;其中,所述叙述性文本包括描述航空安全问题的起因、地点和时间的文本。
降维处理是现有文本分类处理的常用方法,通过借助特征抽取来提取,以得到该特征维度的文本信息,降维处理算法的原理阐述在此不多赘述。本申请实施例中的降维特征包括航空安全问题的起因、地点和时间等特征,基于上述降维特征进行降维处理,可得到航空安全报告的叙述性文本。
接下来,在步骤s1中,对多份航空安全报告的叙述性文本进行预处理,得到针对所述多份航空安全报告的词语语料库;
预处理的具体实现方法可以包括:
利用数据清洗规则对所述多份航空安全报告的叙述性文本进行预处理,删除文本中与研究内容相关性不强的通用表述文本,得到词语语料库;
其中,所述数据清洗规则包括:
(1)拼写检查和扩展缩略词,根据航空安全报告系统asrs官网提供的缩略词表对部分缩略词进行扩展;
(2)将文本中的大写全部转换为小写;
(3)分词,去除非字母的数据、标点符号和停用词;
(4)词形还原;
(5)过滤词频小于10的单词。
本申请的预处理环节可使用python编程语言和python自然语言工具spacy编写程序,根据数据清洗规则自动批量处理。
步骤s2:利用文档主题生成模型lda对所述词语语料库进行训练,得到主题向量
主题向量
现有技术中判断两个文档相似性的传统方法是通过查看两个文档共同出现的单词的多少,如tf-idf等,但这种方法没有考虑到文字背后的语义关联;有可能在两个文档中共同出现的单词很少甚至没有,但这两个文档却是相似的。所以,本申请在判断文档相关性的时候考虑了文档的语义,利用文档主题生成模型lda(latentdirichletallocation)对所述词语语料库进行训练,可挖掘文档中潜藏的主题信息。
lda即潜在狄利克雷分布模型,能够对词语语料库(大量文档集)进行主题建模。它认为所有的文档共有同样的主题集,但是每个文档以不同的比例展示对应的主题。
根据lda模型特性,定义特征词为w,文档为d={w1,w2,......,wn},其中n、m、t分布代表特征词数、文档集数、潜在主题数,lda模型通过以下步骤生成文档:
(1)在生成第m篇文档的时候,得到主题分布θm;
(2)从θm中生成文档m第n个词的主题zm,n;
(3)在生成语料中第m篇文档的第n个词的时候,取样生成主题zk对应的词语分布
(4)从词语的多项式分布
步骤(1)~(4)的贝叶斯网络图如图2所示。
假定文档集规模为m,其中有隐含主题k个,则文档m中第n个词wn出现的概率为:
通过上述公式可得到所述词语语料库中某个文档的主题向量
第一词向量
典型的分布式词向量word2vec工具使用大小固定的滑动窗口来对文档中的每个词项的上下文进行统计,并给出所述词项在向量空间的映射。词向量中保留的语义信息越多,深度学习模型对语料的特征学习效果越好。word2vec词向量具有线性加减的性质,即词向量可以被相加减使得语义上形成有意义的组合,如:“king”-“man”+“woman”=“queen”。
基于上述原理,本申请实施例利用word2vec工具对所述词语语料库进行训练,可得到第一词向量
步骤s3:将所述主题向量
所述步骤s3的具体实现方法包括:
子步骤s31:针对所述主题向量
所述
其中,pjk表示主题k在文档j中所占的比例,k、j均为正整数,0≤pjk≤1且∑kpjk=1;
子步骤s32:利用所述第一词向量
所述
通过子步骤s31可将主题向量
针对基于文档的第二词向量
如果一篇文档是主题偏重航空业的文章,出现germany(德国)这个词,按照word2vec词向量(第一词向量
步骤s4:针对所述基于文档的第二词向量
所述lda2vec模型的损失函数包括:
ld=λ∑jk(α-1)logpjk(公式5);
在公式3~5中,所述l表示lda2vec模型的损失函数,所述ld表示狄利克雷dirichlet分布似然下文档的权重损失函数,所述
其中,n表示所述词语语料库的主题数目,λ表示dirichlet优化的整体强度;
σ表示softmax函数,所述softmax函数的表达式为:
通过将基于文档的第二词向量
基于步骤4的计算,发明人经过大量实验,在本申请一可选实施例中示出了当λ为200时,所述lda2vec模型对所述词语语料库(多份航空安全报告)的主题分布分析表现最好;为了增强模型的可解释性,α取n-1。
此时,所述航空安全报告的主题分布为:
当所述α<1时,所述词语语料库的主题分布倾向于稀疏;
当所述α≥1时,所述词语语料库的主题分布倾向于集中;
所述α为n-1。
得出所述多份航空安全报告的主题分布后,本发明还对上述模型的行为结果是否符合我们的期望进行验证,验证相关主题数据中至关重要的“有用性”特征,以确保模型与本发明所要解决的技术问题保持一致。
在步骤s5中,本发明优选利用主题连贯性指标对所述词语语料库的主题分布进行评估,输出所述词语语料库的主题可解释性结果。
主题连贯性指标是一种可靠的主题分类质量指标,它通过衡量每个主题中概率最高前n个词项之间的语义相似度来衡量单个主题的得分,即主题词集合的两两分布相似度得分之和。
所述主题连贯性指标的公式包括:
在公式6、7中,v表示描述所述词语语料库的主题的一组词项,所述词项包括多个主题词,ε是保证所述词语语料库的主题分布得分score为实数的平滑因子,vi表示表示一组词项中的第i个词项,vj表示表示一组词项中的第j个词项;
当所述主题词的得分越高,所述v的主题连贯性得分越高,所述词语语料库的主题可解释性越高。
基于步骤s1~步骤s5,为了验证本发明的可行性,接下来采用示例1详细阐述。
文本数据:美国联邦航空管理局faa的航空安全报告系统asrs公布的从2007年1月至2017年12月的59876份航空安全报告数据。
经过步骤1的处理方法,得到词语语料库有16116个唯一的词项。
利用步骤2中lda对所述词语语料库进行训练实验,得到主题向量
根据上述实验,设k为20,lda2vec模型参数α取0.05,λ=200,迭代次数为123,执行步骤3~5,得到所述词语语料库中每个主题的标签、主题连贯性得分、特征词(仅列举前10个),参见表1。
表1主题标签、主题连贯性得分以及top10特征词表
由上表可见:
(1)lda2vec模型能够有效的识别出航空安全报告文本数据的主题,主题涵盖了航空安全问题分类的天气、atc(空中交通管制)、紧急情况、人为因素、跑道等多个方面。
(2)每个主题的主题连贯性都比较高,主题中分布概率最高的25个主题特征词能够表达该主题的内容。
本发明在实现时,首先让专家分析每个主题中概率最高前25个特征词来对该主题进行人工判读标识,通过实践发现,通过本发明利用主题连贯性量化得分后,所筛选出的每个主题的前10个特征词最能准确表达该主题,使得专家更容易理解该主题,表明通过本发明的方法所输出的航空安全报告的主题解释性较好。
比如,以t3为例,前10个特征词分别为:maintenance(维护)、mechanic(机械员)、install(安装)、mel(minimumequipmentlist的缩写,最低限度设备清单)、maint(maintenance的缩写,维修)、find(发现)、check(检查)、inspection(检查)、replace(替换)、remove(移除),通过判断上述10个特征词,可清楚的了解该主题与机场机务维修密切相关,因此可以给该主题贴上一个mechanic(技工)的标签,用来概括该主题的含义。
计算每个主题的主题连贯性得分,即计算每个主题中概率最高的top20的主题词集合的两两分布相似度得分之和,则得分越高,该主题的词汇集合的可解释性越高,主题含义越明确。如t12的主题连贯性得分最高,主题概率最高的前10个词为:route(航线)、flight_plan(飞行计划)、pdc(predepartureclearance的缩写,起飞前放行许可)、clearance(许可)、departure(起飞)、chart(图表)、waypoint(航点)、fmc(flightmanagementcomputer的缩写,飞行管理电脑)、fms(flightmanagementsystem的缩写,飞行管理系统)、file(文件)这类词与飞机起飞过程密切相关。以t8为例,前10个特征词为:hour(小时)、fatigue(疲劳)、day(白昼)、flight(飞行)、sleep(睡眠)、trip(旅程)、schedule(日程表)、time(时间)、fly(飞行)、reserve(备用)。显然,该主题与人为因素引起的安全隐患密切相关。
(3)如图4所示,示出了lda模型和lda2vec模型提取的主题连贯性得分对比图,由图可知,lda2vec模型提取的每个主题的主题连贯性得分均高于lda模型提取的主题,说明lda2vec模型在lda模型的基础上,增加了word2vec词级上的信息后,能够使得主题的连贯性得分更高,挖掘得到的主题更具有可解释性。
综上所述,lda2vec能够有效的识别航空安全报告叙述性文本数据的主题。相比于传统的报告分类,使用无监督的机器学习方法识别航空安全报告中的文本主题更灵活和高效。主题模型能够通过灵活的设置任意的主题数,把任意多个航空安全报告聚类为任意多个的集合(词语语料库),并使用一组有意义且含义清晰、便于人类理解的词项描述该报告集合的特点;这些主题为行业分析人员提供了不同的“望远镜放大倍数”,通过特定的情形设置关注对象所需的不同精度。主题建模能够识别上百万份的大规模航空安全报告叙述性文本的主题,其识别出的主题能够减少对航空领域专家的依赖及其相关工作量,克服航空界传统人工分析结果低效且不易统一的局限,大大提高分析的灵活性、高效性和可解释性。
本申请通过lda2vec模型提取的主题连贯性越高,主题词项越具有可解释性,对分析人员来说越容易理解主题数据中的信息。这给航空安全报告分析工作带来新的启示,本领域技术人员可以通过建立各类安全报告的“危险”主题词项,当系统接收到描述的安全报告文本中存在危险的主题词项或与危险主题词项相近似的词语,如助航失效或缺陷、分析程序不当或其它可能危及飞行安全的环境或状况时,系统会自动给分析人员发出报警提示,这样“危险”的安全报告能够及时的被分析人员处理。
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
实施例2:
如图5所示,基于同一发明构思,示出了本申请针对航空安全报告叙述性文本的信息处理装置的结构框图,所述装置具体可以包括以下模块:
报告预处理模块501,用于对多份航空安全报告的叙述性文本进行预处理,得到针对所述多份航空安全报告的词语语料库;
语料库训练模块502,用于利用文档主题生成模型lda对所述词语语料库进行训练,得到主题向量
向量转换模块503,用于将所述主题向量
主题分布计算模块504,用于针对所述基于文档的第二词向量
主题分布评估模块505,用于利用主题连贯性指标对所述词语语料库的主题分布进行评估,输出所述词语语料库的主题可解释性结果。
本申请实施例还提供了一种装置,包括:
一个或多个处理器;和
其上存储有指令的一个或多个机器可读介质,当由所述一个或多个处理器执行时,使得所述装置执行本申请实施例所述的一个或多个的方法。
本申请实施例还提供了一个或多个机器可读介质,其上存储有指令,当由一个或多个处理器执行时,使得所述处理器执行本申请实施例所述的一个或多个的方法。
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上对本申请所提供的涉及针对航空安全报告叙述性文本的信息处理方法和针对航空安全报告叙述性文本的信息处理装置,进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 还没有人留言评论。精彩留言会获得点赞!