一种基于网页文本的学者观点抽取方法与流程
本发明涉及一种基于网页文本的学者观点抽取方法,自动爬取学者在网络上发表的言论信息,抽取其中的观点语句并进行摘要总结,适用于Internet网络信息采集、数据分析、摘要生成;属于数据挖掘、情感分析、信息检索技术领域。
背景技术:
随着网络技术的快速发展,越来越多的专家学者在互联网上表达自己的观点。抽取和分析学者的观点,有利于对社会热点事件的影响做出更准确的判断。然而,互联网每天产生的信息量巨大,要从这些大规模的网络数据中人工发现某个学者的观点并进行分析是一件非常困难的事情。因此,需要利用信息处理技术自动地抽取网络中学者发表的观点,分析学者观点的主要关注内容以及观点的情感倾向等信息,然后对学者的观点进行总结并形成观点的摘要,进而为相关部门了解学者对热点事件的态度提供数据支持。
现有的观点抽取主要包括基于统计的方法、基于机器学习的方法和基于图模型的方法。基于统计的方法往往依赖于文章的表层特征,例如,利用句子在段落中的位置、段落在文章中的位置、词频的大小、句子与标题的相似度等特征评估句子的重要性。该方法虽然简单但却有很高的准确率,甚至超过后来很多更复杂的算法。基于机器学习方法主要利用决策树、隐马尔科夫、条件随机场模型等模型在语料库上训练观点抽取模型,该类方法的性能严重依赖语料库的质量。基于图模型的方法的基本思路是把文章的句子或者段落作为一个分析对象,每一个分析对象作为图中的一个点,点与点之间的关系通过寻找两个分析对象是否在某个特征上相似或者重合来确定是否连接。建立完基础的图之后,通过图模型上的迭代算法来计算图中各个节点的权值,按照权值的大小排序之后选择权重大的分析对象作为结果。该方法只能选取一些重要的句子,但是这些句子不一定表达人物的观点。因此,基于网页文本的学者观点抽取及摘要生成方法亟待改善,需要利用自然语言处理技术抽取学者观点语句的主要元素,通过情感分析技术判断观点的情感倾向和极性,基于文本挖掘技术对观点句进行总结,提高学者观点抽取与分析的可用性。
技术实现要素:
本发明要解决的技术问题:克服现有观点抽取技术的不足,提供一种基于网页文本的学者观点抽取方法,融合了网络信息采集、数据挖掘、情感分析、自然语言处理等技术,充分考虑了网页文本数据中学者观点的特点,提高了学者观点抽取的可用性。
本发明的技术解决方案:
一种基于网页文本的学者观点抽取方法,包括以下步骤:
步骤A.学者网页信息采集:用户提供学者列表及各个学者的单位名称,以每位学者的姓名、所在单位的基本信息为检索关键词,通过网络爬虫技术,自动地从大学和研究所的官方主页、学者个人主页、百度百科、学术文献网网络渠道获取与所述学者网页信息,并将所述学者网页信息存储于学者原始信息数据库中;
步骤B.文本数据预处理:对步骤A得到的所述学者网页信息中的文本数据进行清洗,删去与观点不相关的文本;同时对一些特殊字符进行特别地处理,特殊文符包括单引号、双引号和空白字符,以减少噪音数据的影响;然后对学者的每篇网页文本,根据标点符号来进行语句的分割;经过分割后,一个网页文本被分割成多个语句;对于每个语句,用开放的工具包进行分词、词性标注、句法分析和命名实体识别,把抽取到的各种信息存储到数据库中;
步骤C.观点抽取分析:对于步骤B中分割的每条语句,基于句法分析结果识别所述语句是否为观点句,观点句表示某人发表的对某件事或某个对象的看法和立场的语句;如果是观点语句,则提取观点持有者,观点持有者表示发表该观点句的人物名称;如果观点持有者不属于用户提供的学者列表中的人物,则删除。然后,基于情感词典来分析观点句的情感倾向及极性强度,再结合转折型关联词、否定短语信息计算观点句的情感值,该情感值是一个整数值,用来表示观点语句的情感强度大小;基于观点语句的情感值可对观点语句进行排序;
步骤D.观点摘要生成:基于步骤C抽取的网页文本中的观点语句、观点持有者及观点语句的情感值,对网页中同一个学者发表的所有观点语句进行聚类,对每个聚类中观点语句基于情感值进行排序,然后按照顺序进行合并,组成一个观点段落,然后对所有聚类生成的观点段落进行合并,形成该学者的观点摘要。
步骤B中,对于学者的每篇网页文,根据“。”、“!”、“?”、“;”、“...”标点符号将文本分割为多个语句,对于每个语句,用开放的工具包来进行分词、词性标注任务,根据词性,进行人名识别、情感词抽取。
步骤C中,基于句法分析结果识别当前语句是否为观点句,由句子的句法树可得到句子的主语部分、谓语部分和宾语部分,如果这条语句的谓语为下列词语中的一个:“认为”、“强调”、“指出”、“提出了”,则该条语句为观点句,识别出观点句后再抽取发表该观点的人物名称,即观点持有者:如果该语句为主动语态且主语为人名,则该人物为观点持有者;如果该语句为被动语句且宾语为人名,则该人名为观点持有者。
步骤C中,对每个观点句的情感分析及情感极性强度值计算,考虑了转折型关联词、否定短语对观点句情感值的影响,利用转折句型抽取观点句中能有效表达情感信息的语句部分,然后利用否定词修正情感值的计算结果。
步骤D中,对学者在同一个网页中的所有观点语句具体为:利用聚类算法对学者在同一个网页中的所有观点语句进行聚类,对每个聚类中的语句根据情感倾向和情感值进行排序,对排序好的语句进行连接得到一个段落;最后对所有聚类的段落进行合并形成观点摘要。
本发明与现有技术相比的优点在于:目前的观点抽取方法主要基于固定的抽取模式或利用训练语料学习抽取模型,这些方法缺乏对网络中人物观点语句特点的分析,不能对观点要素进行有效分析和抽取。因此这些方法抽取的观点语句不能有效反应人物对某件事的真实看法和态度。本发明提出了一种基于网页文本的学者观点抽取方法,自动采集网络中的学者相关的网页信息,利用自然语言处理技术和文本挖掘技术从网页文本中抽取出学者的观点语句以及观点的要素信息,分析观点的情感及极性强度,利用摘要模板自动对观点语句进行综合,提高了学者观点抽取结果的可读性和用户的满意度。
附图说明
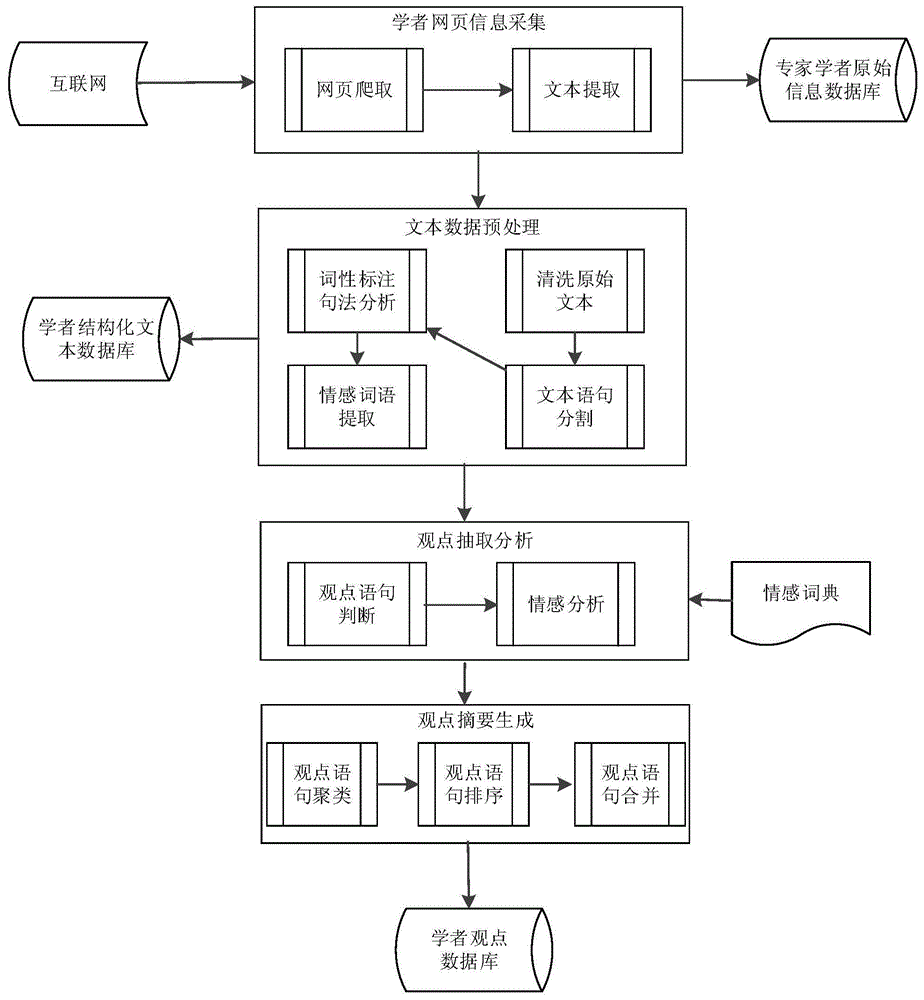
图1是基于网页文本的学者观点抽取的本发明所述方法流程示意图。
具体实施方式
下面结合附图及本发明的实施方式对本发明的方法作进一步详细的说明。
如图1所示,本发明一种基于网页文本的学者观点抽取方法,具体实现步骤如下:
步骤一:学者网页信息采集
首先获取与给定学者相关的网页信息。根据用户提供的学者姓名、所在单位名称等基本信息构建检索关键词,如“陈晓明北京大学中国语言文学系”,利用基于Python语言的Scrapy爬虫工具自动地从大学和研究所的官方主页、百度百科、学术文献网等网络渠道获取与给定学者相关的网页信息,存储网页中的文本数据。
步骤二:文本数据预处理
对步骤一得到的学者原始网页文本数据进行预处理。首先,对文本数据进行清洗,删去一些与学者观点无关的文本,如HTML标签、JavaScript脚本、CSS样式等。同时对一些特殊字符进行特别地处理:因为单引号、双引号、空格、制表符都与学者观点无关,删去单引号、双引号;其它空白字符如空格、制表符等均删去;将换行字符转为句号,句号可以用来分割文本中的句子。
然后对每篇网页文本,根据标点符号来进行语句的分割,使用的标点符号包括:“。”、“!”、“?”、“;”、“...”等,经过分割后,一个网页文本被分割成许多的语句。对于每个语句,用开放的jieba工具包来进行分词和词性标注,利用斯坦福大学的语法树分析工具分析句子的主语、谓语、宾语等部分,并对这些部分进行存储。对于标记为名词的词语利用条件随机场模型进行命名实体识别,对识别出为命名实体的词语进行存储。对所有词性为名词、形容词和副词的词语进行存储,这些词语用于判断语句的情感倾向和情感强度值。
步骤三:观点抽取分析
利用步骤二得到的预处理后的结构化文本数据,判断每个语句是否为观点句。一条语句为观点句的依据是它的谓语为下列词语中的一个:“认为”、“强调”、“指出”、“提出了”。识别出观点句后再抽取观点持有者,即发表该观点的人物:如果该语句为主动语态且主语为人名,则该人物为观点持有者;如果该语句为被动语句且宾语为人名,则该人名为观点持有者。
然后基于情感词典,即知网情感词典(HOWNET),来分析观点语句的情感倾向及情感强度值。情感词典包括了情感短语表、程度副词表、转折词语表和否定短语表:
(1)情感短语表包含了情感词、情感倾向(正向、中立、负向)。
(2)程度副词表包含了程度词、语气程度(强、中、弱)。强程度副词包括:更、更加、极、极度、尤其、特别、格外等词语。中程度副词包括:比较、大致、大体上等词语。弱程度副词包括:有点、有些、稍微等词语。
(3)转折词语表包含了转折词、转折类型(让步型、转折型)。如:“虽然”、“尽管”是让步型,“但是”、“仍然”是转折型。
(4)否定词语表则包含了一系列否定词。
由于程度副词会影响情感极性,本发明首先根据观点句中包含的情感词及程度副词来计算观点的情感值,按照情感词和程度副词的组合情况,定义7个情感强度值,情感强度值计算方法如下:
(1)包含:正向情感词和强程度语气词,则情感分值=+3;
(2)包含:正向情感词和中程度语气词,则情感分值=+2;
(3)包含:正向情感词和弱程度语气词,则情感分值=+1;
(4)包含:中立情感词,则情感分值=0;
(5)包含:负向情感词和弱程度语气词,则情感分值=-1;
(6)包含:负向情感词和中程度语气词,则情感分值=-2;
(7)包含:负向情感词和强程度语气词,则情感分值=-3。
由于句子的情感会因为转折词而发生变化,然后,本发明再结合转折型关联词、否定短语来计算观点句的情感值,具体处理方式如下:
转折句(包含了“虽然”和“但是”这些词语的语句)和让步句(包含了“尽管”和“仍然”这些词语的语句)表达观点的主要部分是转折词引导的部分,即“但是”和“仍然”引导的那部分语句,所以先通过转折词语识别转折句,如果一个句子中同时有让步型和转折型的转折词语,那么舍弃掉让步型词语“虽然”和“尽管”引导的语句部分,而只保留转折型词语“但是”和“仍然”引导的语句部分作为观点语句。然后,如果否定词出现在情感词前面时,则该观点句的情感值取反(即该情感值乘以负1)。
步骤四:观点摘要生成
基于步骤三生成的观点句及其情感值,利用文本聚类方法将网页中同一个学者发表的所有观点句组合成一个观点摘要。步骤如下:
(1)对每一个网页文本,把同一个学者发表的所有观点语句从数据库中提取出来,构成观点语句集D。
(2)利用K-means聚类方法对语句集D进行聚类,聚类的个数n设置为:的整数,其中|D|为语句集D包含的语句的个数,聚类结果为{d1,d2,…,dn},其中每一个di(1≤i≤n)表示一个观点语句类。
(3)对于每一个语句类di按照如下方法生成两段话:把情感值为正值的观点句按照情感值的大小进行降序排序,然后把这些观点句依次连接成一段表示正面情感的段落,各个观点句间用“。”相连;另一方面把情感值为负值的观点句按照情感值的大小进行升序排序,然后把这些观点句依次连接成一段表示负面情感的段落,各个观点句间用“。”相连。最后,把表示正面情感的段落和表示负面情感的两个段落拼接成一个段落:即表示正面情感的段落排在前面,中间插入一个转折词及符号“然而,”,再接上表示负面情感的段落。
(4)对基于聚类di(1≤i≤n)生成的所有段落进行合并形成观点摘要。合并的步骤是:按照每个聚类di(1≤i≤n)所包含的语句的个数进行降序排序;然后,对所有聚类段落按照排序好的顺序依次进行拼接,拼接后的文本即为学者的观点摘要。
总之,本发明综合利用了网络信息采集、数据挖掘、情感分析、自然语言处理等技术,从网络中自动提取出学者发表的观点及情感倾向,并生成观点摘要,有了解学者的社会活动和影响有重要意义。
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!