一种基于条件生成对抗网络的道路场景去雾方法与流程
本发明涉及图像处理技术领域,尤其是涉及一种基于条件生成对抗网络的道路场景去雾方法。
背景技术:
随着计算机视觉的发展及其在交通、安全监控领域的应用,图像去雾已成为计算机视觉的重要研究领域。在雾霾天气导致能见度较低的恶劣气象条件下,由摄像机采集到的图片受大气中悬浮颗粒物(如雾、霾等)的影响,导致图片质量不佳,难以辨别图片中的物体特征,甚至影响例如室外监控、目标识别和交通导航中图片的质量。因此,有雾图像特征清晰化有着重要的研究意义。
目前,图像去雾的方法主要有两类:图像增强和模型去雾。图像增强类算法直接从图像处理角度出发,通过增强含雾图像的对比度,突出图片的特征或有效信息,一定程度上改善图片的视觉效果。但是该类方法忽略了图像降质的真正原因,所以对于场景复杂的图片无法提高图片的质量,甚至可能丢失图像的某些信息。常用的图像增强类算法包括直方图均衡、多尺度retinex、同态滤波、tan等。kim等和stark提出局部直方图均衡法,其主要是定义一个图像的子块,从而确定其直方图,再对该子块进行直方图均衡,子块的中心灰度被替换为直方图均衡后的灰度,如此根据每个像素的邻域对像素进行处理,有利于突出图像特征。多尺度retinex算法将有雾图像中的照射分量和反射分量分离,消除以雾为主的照射分量对图像的影响,达到去雾的效果。但是在用该算法进行图像增强时,要计算照度分量,这在数学上是个欠定问题,只能通过近似估计。
模型去雾类算法通过建立大气散射模型,研究图像退化的物理原理,得出大气中悬浮颗粒物对光的散射作用以及对图片的影响,复原出更真实的图片,且在复杂场景中去雾效果较好,图像信息较完整。常用的模型去雾类算法有tarel、fattal、he等。nayer等把大气对景物反射的光线的影响分为大气对景物光线的衰减和环境光的叠加,并分别进行推导,从而在根本上去雾,得到原始的无雾图片,且丢失的信息较少。he通过对大量无雾图像统计特征的观察,提出了暗道先验(darkchannelprior,dcp)的算法,其认为雾的浓度近似于最暗通道的数值,即在非天空的清晰区域,在rgb三个通道中有一个颜色通道的亮度很低甚至接近于0。该算法对非天空区域的图片有着良好的去雾效果,而对于有天空的这类的亮区域结果并不理想,且该算法计算量太大,效率较低。
近年来,随着深度学习(deeplearning)的不断发展,其在各领域取得了较多的成果,其中也包含了对去雾的研究。但是由于数据的的缺失,这样的基于深度学习的方法并不多见。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于条件生成对抗网络的道路场景去雾方法。
本发明的目的可以通过以下技术方案来实现:
一种基于条件生成对抗网络的道路场景去雾方法,用以降低雾霾天气对道路场景获得图像的干扰,包括以下步骤:
1)采用reside数据集构建训练集和测试集;
2)将训练集中的有雾图片x作为生成器g的输入并生成g(x),即无雾图片
3)将生成的无雾图片
4)迭代设定轮次后,得到最优生成网络;
5)将得到的最优生成网络应用于真实有雾图像,进行去雾处理。
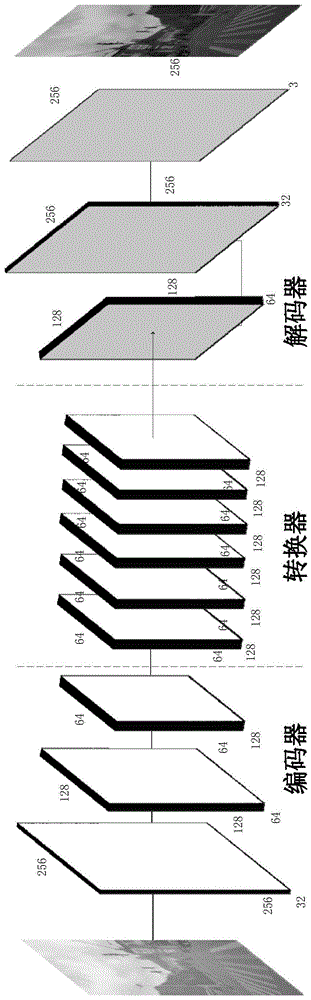
所述的步骤2)中,生成器g包括第一编码器、转换器和解码器。
所述的第一编码器由3层卷积层构成,用以提取输入图像的特征向量,所述的转换器由6层的resnet模块构成,用以将源域中图片的特征向量转换到目标域中的特征向量,所述的解码器由3层反卷积层构成,用以从特征向量中还原得到低级特征。
所述的步骤3)中,判别器d由第二编码器组成,该第二编码器由4层反卷积层构成,实现对图片的下采样,得到示意图片真假的概率。
所述的步骤3)中,判别器d采用patchgan结构,该patchgan结构用以对图片70×70的patch进行判别。
所述的步骤4)中,网络训练的目标函数为:
其中,l(g,d)为损失函数,d(x,y)为真实图像的得分,d(x,g(x))为生成图像的得分,
与现有技术相比,本发明具有以下优点:
一、由于本发明采用生成对抗网络技术,能够更好地获取到雾天场景的特征,因此对多种雾天场景,如雾天街道场景,雾天的公园等,具有更好的鲁棒性。
二、本发明由于引入了resnet模块,取得了更好的去雾效果,并且采用了patchgan结构的判别器,仅对图片70×70的patch进行判别,而不是整张图片,这能够减少图像处理时间。
附图说明
图1为条件生成对抗网络的生成器结构。
图2为条件生成对抗网络的判别器结构。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
下面结合附图,通过实例进一步描述本发明,但不以任何方式限制本发明范围。
本发明以reside数据集为例,具体操作如下:
步骤一:采用reside数据集,其中包含训练集和测试集;
步骤二:将训练集中的有雾图片x作为输入传送给生成器g生成g(x),即无雾图片
步骤三:将生成的无雾图片
步骤四:迭代200轮后,得到最优生成模型;
步骤五:将得到的最优生成模型用于真实有雾图像,进行去雾处理。
在本实施中,生成器由三个部分组成:编码器、转换器和解码器;编码器由3层卷积层组成,实现输入图像特征的提取;转换器由6层的resnet模块构成,实现将源域中图片的特征向量转换到目标域中的特征向量;解码器由3层反卷积层构成,实现从特征向量中还原出低级特征。
在本实施中,判别器仅由编码器组成;编码器为4层反卷积层,实现对图片不断的下采样,最终得到一个概率示意图片真假;判别器采用patchgan结构;patchgan结构仅对图片70×70的patch进行判别,而不是整张图片,这样本发明在得到相同去雾效果的条件下,使得图像处理时间更短。
在本实施中,网络结构的损失函数为:
目标函数中,生成器g要最小化该目标函数,判别器d要最大化该目标函数:
经过上述步骤,得到一个最优的生成模型,可以用来对其他场景的有雾图片进行去雾。
- 还没有人留言评论。精彩留言会获得点赞!