利用多模型之间语义关联优化数据理解处理的方法与流程
本发明涉及数据挖掘领域,尤其涉及一种利用多模型之间语义关联优化数据理解处理的方法。
背景技术:
当前大量无标记、内容未知的原始数据需要采用机器学习的方式进行尽可能完善的识别和标记。然而如果对每段未知内容的原始数据逐一采用各类机器学习模型进行识别,将带来巨大的计算开销和不必要的计算资源浪费。对此,现有的优化数据理解处理的方法基本从如下几个方面入手:优化模型结构、压缩模型大小以及构建多任务模型。但这些方法均为专注于单一模型的优化,而忽略了大规模数据理解处理中通常需要采用的多个模型进行数据内容识别的问题,而如何优化基于多模型的数据识别理解目前尚无相关技术。
技术实现要素:
基于现有技术所存在的问题,本发明的目的是提供一种利用多模型之间语义关联优化数据理解处理的方法,能对多个模型进行数据内容理解时,优化基于多模型的数据识别理解。
本发明的目的是通过以下技术方案实现的:
本发明实施方式提供一种利用多模型之间语义关联优化数据理解处理的方法,包括:
配置多个数据理解模型,选定多段原始数据;
使用配置的全部数据理解模型分别为各段原始数据进行标注,得到每个数据理解模型对于每段原始数据的处理结果作为多段训练数据;
使用所述多段训练数据对动态贝叶斯网络和强化学习决策网络进行训练,得到模型语义关联网络;
利用所述模型语义关联网络形成多模型数据理解处理优化控制规则,使用该多模型数据理解处理优化控制规则根据输入数据选择最优的数据理解模型进行数据理解处理。
由上述本发明提供的技术方案可以看出,本发明实施例提供的利用多模型之间语义关联优化数据理解处理的方法,其有益效果为:
通过动态贝叶斯网络和强化学习网络对多段训练数据训练得到模型语义关联网络,实现了利用自动标注的数据挖掘出模型间的语义关联,进而利用挖掘出模型间的语义关联实现多模型数据理解处理优化算法,能根据输入数据选择最优的数据理解模型进行数据理解处理,解决了大规模数据理解处理中,对每段数据无法实现自适应选择最佳的数据理解模型的问题,实现了以最少的计算开销对未知内容数据的尽可能完善的识别和理解。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
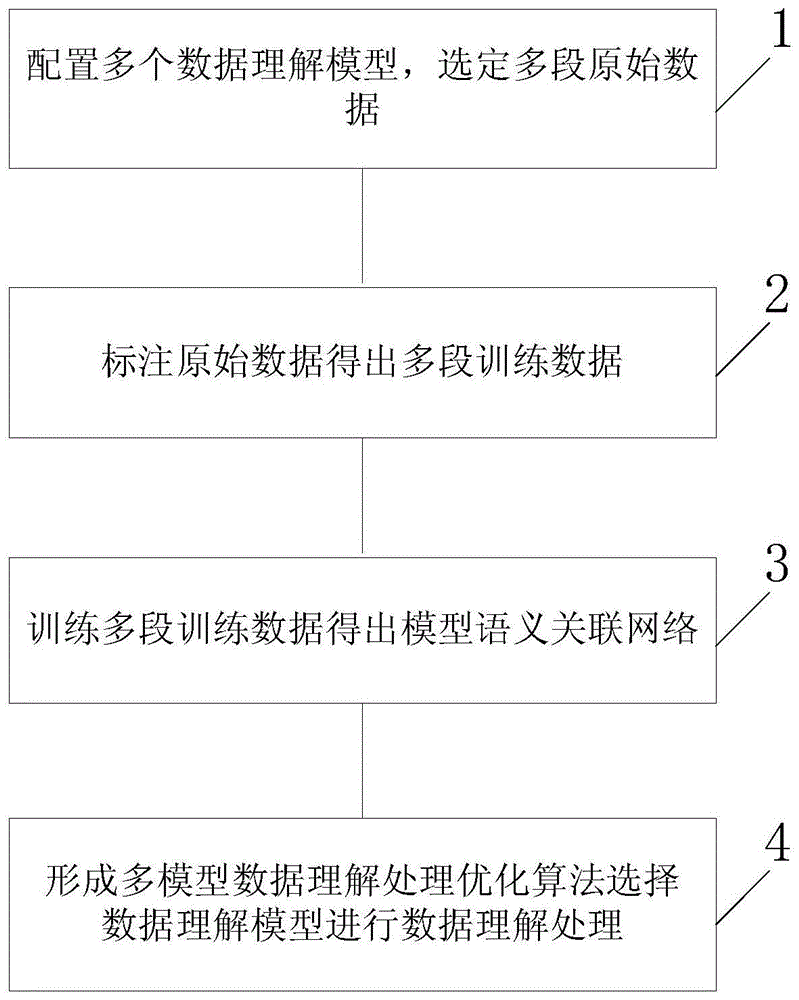
图1为本发明实施例提供的利用多个模型之间语义关联优化数据理解处理的方法流程图。
具体实施方式
下面结合本发明的具体内容,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
如图1所示,本发明实施例提供一种利用多模型之间语义关联优化数据理解处理的方法,包括:
配置多个数据理解模型选定多段原始数据作为训练数据;
使用配置的全部数据理解模型为各段原始数据进行标注,得到每个数据理解模型对于每段原始数据的处理结果,得到多段训练数据;
使用所述多段训练数据对动态贝叶斯网络和强化学习决策网络进行训练,得到模型语义关联网络;
利用所述模型语义关联网络形成多模型数据理解处理优化算法,使用该多模型数据理解处理优化算法对进行数据理解处理的数据理解模型进行选择。
上述方法中,数据理解模型:是指数据理解处理中能对输入数据产生理解结果的数据处理程序。
上述方法中,数据理解模型为:包含当前各类数据理解模型,如人脸识别模型、物品识别模型,场景识别模型,动作识别模型,自然语言理解模型等中的一种或多种。
上述方法中,模型语义关联网络是指不同模型对于输入数据的理解结果之间隐含关联性形成的网络。
上述方法中,多模型数据理解处理优化控制规则为:根据不同的输入数据,自适应地选择最优的数据理解模型执行对输入数据的理解处理。优选的,可根据该多模型数据理解处理优化控制规则制成优化算法或择优决策程序。
本发明的方法能有效地挖掘出多个机器学习模型之间的语义关联,并利用语义关联训练得到选优决策模型,控制多模型的数据理解处理,解决了大规模数据理解处理中对每段数据的模型自适应选择问题,以最少的计算开销实现对未知内容数据的尽可能完善的识别和理解。
下面对本发明实施例具体作进一步地详细描述。
本发明实施例提供一种利用多模型之间语义关联优化数据理解处理的方法,用在多模型对数据进行识别和标记中,包括以下步骤:
步骤1,模型间语义关联挖掘:模型,指数据理解处理中能够对输入数据产生理解结果的程序(例如:人脸识别模型,动作识别模型);模型间的语义关联指不同模型对于输入数据的理解结果之间隐含的关联性(例如:对于物体检测没有识别到人物的图片,运行动作识别、姿态模拟模型不会产生有效理解结果;对于场景检测为教室的图片,物体检测出野生动物的几率很小);本发明提出了一种模型间语义关联挖掘方法,通过动态贝叶斯网络和强化学习网络,利用大量自动标注数据挖掘出普适性强的模型间语义关联网络,利用训练得到的模型间语义关联网络形成多模型数据理解处理优化算法,利用该算法可制成优选决策模型,实现可以根据不同的输入数据,自适应地选择最佳数据理解模型执行数据理解处理;
步骤2,多模型数据理解处理优化算法:多模型数据理解指对于输入数据有多个可以运行的理解模型,这些模型可能会产生有效的理解结果,也有可能不会。本发明提出一种多模型数据理解处理优化算法,通过将这一过程抽象为动态子模函数优化及调度优化的混合问题,设计出基于模型语义关联的自适应优化算法。
本发明适用于各种需要使用多个模型进行数据分析的场景。例如:数据交易平台,平台需要使用多种模型理解用户上传的原始数据,由于计算资源是有限的,需要尽可能选择运行那些可以得到有价值的结果的模型。使用本发明的方法,可以大幅提高数据分析的效率,在使用同等计算开销时可以大幅提高运行结果的价值(或,使用大幅减少的计算开销获得同等价值的结果)。
本发明方法的优点在于:利用了模型间的语义关联来为每段未知内容数据进行理解模型的最优化选择,以最少的模型运行开销,实现对数据尽可能完善的语义识别理解。该方法有效地提高了数据理解速度,显著减少计算开销,可应用于各类基于机器学习模型的数据理解应用。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
技术特征:
技术总结
本发明公开了一种利用多模型之间语义关联优化数据理解处理的方法,包括:配置多个数据理解模型,选定多段原始数据;使用配置的全部数据理解模型分别为各段原始数据进行标注,得到每个数据理解模型对于每段原始数据的处理结果作为多段训练数据;使用所述多段训练数据对动态贝叶斯网络和强化学习决策网络进行训练,得到模型语义关联网络;利用所述模型语义关联网络形成多模型数据理解处理优化控制规则,使用该多模型数据理解处理优化控制规则根据输入数据选择最优的数据理解模型进行数据理解处理。该方法利用了模型间的语义关联来为每段未知内容数据进行理解模型的最优化选择,以最少的模型运行开销,实现对数据尽可能完善的语义识别理解。
技术研发人员:张兰;李向阳;袁牧
受保护的技术使用者:中国科学技术大学
技术研发日:2019.03.25
技术公布日:2019.07.02
- 还没有人留言评论。精彩留言会获得点赞!