一种多源视频中复杂行为识别的方法与流程
本发明涉及计算机视觉领域,尤其涉及一种多源视频中复杂行为识别的方法。
背景技术:
现有的一些技术训练端到端的卷积神经网络模型能对视频进行行为识别,但是其输入数据大多为人工切分后的视频片段,对于实时的视频流不能进行自动切分和识别。对于包含复杂行为的视频数据,不仅在时间维度上,在空间维度上也需要进行切分。对于一个包含有多人多个活动的视频画面,由于模型是端到端训练的,现有的方法无法对这样的视频自动的分别进行切割、识别。同时,为了精确识别多种活动,一般使用复杂的神经网络模型,这导致了处理效率低下的问题,无法达到实时处理,难以真正应用在现实场景中。
技术实现要素:
基于现有技术所存在的问题,本发明的目的是提供一种多源视频中复杂行为识别的方法,能从多个源的视频中,准确且及时的识别出复杂行为。
本发明的目的是通过以下技术方案实现的:
本发明实施方式提供一种多源视频中复杂行为识别的方法,包括:
步骤1,元信息提取:分别从多源视频各视频画面中识别提取元信息;
步骤2,完整活动场景重建:将从每一个视频中提取的元信息进行融合建立完整的活动场景;
步骤3,行为模式学习:在所述步骤2建立的完整活动场景中,按所需识别行为,标注目标行为包含所需识别行为的视频作为训练数据,通过训练数据训练得到行为识别规则;
步骤4,复杂行为识别:依据所述步骤3训练完成的行为识别规则,在所述步骤2建立的完整活动场景中,对每个个体的行为进行识别,并根据交互模式识别群体行为,在所述完整活动场景中自动划分活动区域,在各个活动区域内,对个体行为进行识别。
由上述本发明提供的技术方案可以看出,本发明实施例提供的多源视频中复杂行为识别的方法,其有益效果为:
通过从多个源视频中分别提取元信息并加以融合,建立完整的复杂行为场景,使用基于规则的识别,实现对多源视频中复杂行为进行高效精准的识别。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
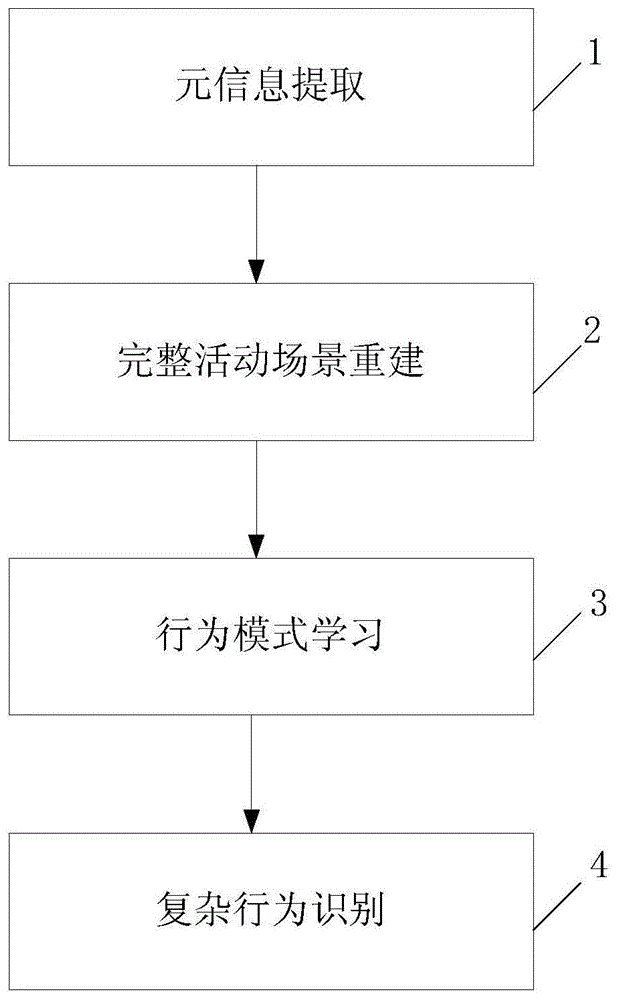
图1为本发明实施例提供的多源视频中复杂行为识别的方法流程意图。
具体实施方式
下面结合本发明的具体内容,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
如图1所示,本发明实施方式提供一种多源视频中复杂行为识别的方法,能对多源视频画面的复杂行为进行自动地信息提取和融合,并基于模式识别进行复杂行为自动识别,实现对视频信息的高效自动化利用,包括:
步骤1,元信息提取:分别从多源视频各视频画面中识别提取元信息;
步骤2,完整活动场景重建:将从每一个视频中提取的元信息进行融合建立完整的活动场景;
步骤3,行为模式学习:在所述步骤2建立的完整活动场景中,按所需识别行为,标注目标行为包含所需识别行为的视频作为训练数据,通过训练数据训练得到行为识别规则;
步骤4,复杂行为识别:依据所述步骤3训练完成的行为识别规则,在所述步骤2建立的完整活动场景中,对每个个体的行为进行识别,并根据交互模式识别群体行为,在所述完整活动场景中自动划分活动区域,在各个活动区域内,对个体行为进行识别。
上述方法步骤1中,分别从多源视频识别提取各视频画面中的元信息为:
人脸信息、人体骨架信息、物体识别信息中的至少一种。
上述方法步骤2中,将从每一个视频中提取的元信息进行融合,建立完整的活动场景为:
上述方法步骤4中,根据交互模式识别群体行为包括:
所述交互模式包括:人与人进行交互的行为和人与物进行交互的行为;如:多人讨论;人物间冲突斗殴;盗窃嫌疑人移动物品等;
通过识别群体行为为哪种交互模式来确定群体的行为是人与人进行交互的行为或人与物进行交互的行为。
上述方法步骤4中,在所述完整活动场景中自动划分活动区域为:在所述完整活动场景中,将没有交互关系的群体自动划分为不同的活动区域。具体的,会根据完整活动场景中个体的空间关系,进行活动的识别,没有交互关系的群体被视为不同的活动区域,从而划分出多个活动区域。
上述方法步骤4中,在各个活动区域内,对个体行为进行识别还包括:当各活动区域内的个体行为发生改变时,重新对个体行为进行识别后,自动更新识别结果。
本发明的方法,可以融合多源视频信息进行大规模复杂场景统一识别,并在时空维度上自动进行切分,由于使用基于规则的识别方法相较现有方法运行速度快,同时需要更少的训练数据,实现了高效识别多源视频复杂行为的目标。该方法灵活度高,可以针对具体应用进行元信息抽取调整,识别规则根据应用需求定制,可以适用于各种需要进行行为识别的应用场景,特别是需要多摄像头进行行为识别的场景,例如:公共区域、医院、工厂、学校和监狱等。
下面对本发明实施例具体作进一步地详细描述。
本发明实施例提供的多源视频中复杂行为识别的方法,主要包括以下步骤:
步骤1,使用多种视觉识别模型进行元信息提取;
步骤2,通过对多源视频中的元信息进行融合,重建完整活动场景;
步骤3,针对具体应用的需求(即所需识别行为),使用已经标注好的视频作为数据训练行为识别规则;
步骤4,依据训练完成的行为识别规则,在得到的完整活动场景上,对每个个体的行为进行识别,并根据交互模式识别群体复杂行为。
其中,各步骤具体如下:
步骤1,元信息提取:采用元信息提取的方法,对于每一个视频源,针对应用的需求,提取完成需求识别所需要的元信息。
对于行为识别而言,视频画面中的很多信息是冗余的,使用全部画面信息进行活动识别可能会提高一些识别精度,但是浪费了大量的算力,本发明识别的第一步仅识别所需要的元信息,例如,应用的需求是识别幼儿园中的活动,则元信息应包括:人脸信息、人体骨架信息、物体识别信息等;这样节省了识别所用的算力,减小了计算开销。优选的,所用的多种视觉识别模型可采用现有技术的人脸识别模型;物体检测模型;骨架提取模型;场景分类模型等。
步骤2,完整活动场景重建:对于每一个视频源,元信息被并行地抽取出来,为综合识别多源视频中的完整复杂行为,对多源视频信息进行融合,来建立完整的活动场景;
仍以识别幼儿园中的活动为例:假设整个幼儿园中有10间教室,一共部署了20个摄像头,这一步骤将从20个视频源中提取到的元信息进行融合,得到完整的幼儿园活动场景信息。
步骤3,行为模式学习:在建立了完整活动场景后,针对应用需求,需要对目标行为的模式进行学习;这一步骤需要标注好的目标行为视频作为训练数据;
继续以幼儿园中的活动为例:假设关注的是儿童跌倒、幼师踢打儿童、儿童互相打闹等行为,则标注相关的视频(即标注包含有这些行为的视频)作为训练数据,通过这些训练数据训练得到行为识别规则,行为识别规则可以是:描述两个对象之间交互行为的动作规则。如,以幼儿园为例,若以视频中的幼师踢打儿童为训练数据,学习到的规则可描述为:一个做踢脚动作的人,脚部位置接触到一个儿童。
步骤4,复杂行为识别:依据训练完成的行为识别规则,在得到的完整活动场景上,对每个个体的行为进行识别,并根据交互模式识别群体行为,实现活动区域的自动划分;当个体行为发生改变时,识别结果自动更新,即实现时间维度上的自动切分,这使得该方法可以很好地应用于实时视频流的处理任务。
本发明的方法可应用于幼儿园场景、通用安保场景和养老看护场景等,幼儿园场景上述已介绍,下面说明另外两种场景的应用情况:
(1)通用安保场景:在几乎所有公共场所都有监控“意外事件”的需求。意外事件例如打架斗殴、踩踏事件、盗窃等违法行为。这样的场景中,为了覆盖各个区域,基本都部署很多个摄像头。本发明的方法能够高效准确地融合这些来自多个视频流的画面信息,并且准确地识别用户感关注的那些“事件/活动”,进而实现提前应对处理,避免出现后续问题。
(2)养老看护场景:老人可能在一些较为私密的空间发生意外,如在卫生间滑倒。为避免隐私泄露,传统的视频监控不会部署在这样的私密空间。本发明的方法可以在端设备上先进行一步预处理,将必要的元信息抽取出来,仅传输识别所需的画面特征,而这些特征是不包含原始画面信息的,也就是说不会泄露用户的隐私。这样的特性使得应用本发明方法的系统可以部署在任意场景,在保护用户隐私的前提下实时监测意外行为的发生。
本发明的方法灵活度高,可根据具体应用需求进行元信息抽取调整,行为识别规则可根据应用需求定制,能适用于各种需要进行行为识别的应用场景,特别是需要多摄像头进行行为识别的场景,如:公共区域、医院、工厂、学校和监狱等,具有广阔的应用前景。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!