基于事件相似度的事件日志与过程模型校准方法与流程
本发明属于信息技术领域,尤其涉及一种基于事件相似度的事件日志与过程模型校准方法。
背景技术:
目前用于对事件日志与过程模型的一致性进行检测的方法有很多。为确定日志与模型偏差的程度,adriansyaha等提出最优校准的概念,将最优校准的求解问题转换成求解最优路径问题。其中,具有最小代价的路径对应着日志与模型的最优校准。同时,根据是否区分各个事件的重要性,最优校准又进一步分为基于代价值(cost)的最优校准和基于移动步数(move)的最优校准两种情况。针对企业级数据和模型的校准问题,song等根据模型的结构和行为特点,利用有效的启发式方法大规模缩减搜索空间,从而提高了校准的效率。
适应分布式计算和大数据环境的校准研究也不断出现。jorgemg等将sese结构的过程模型划分为多个子模型分别校准,它可以显著减少校准所需时间,同时也易于进行偏差的诊断。verbeek等应用petri网的分解方法,将用petri网表示的过程模型与其日志之间的校准问题,转化为petri网的子网与日志映射之间的比较,提出了校准分解的可行性、伪校准的代价下限等一系列定理。
在当前关于模型与事件日志的校准中,每一个事件(event)均只涉及活动一个属性。但在实际环境中,已记录的事件日志信息往往涉及到事件的执行者、操作对象和事件发生的时间、地点等的信息,即事件可能具有多个属性,而不仅限于活动一个属性。同时,如果考虑到事件的活动以外的其它属性时,当前用于反映模型与日志偏差的最优校准,未必仍然是最优校准,因此需要新的方法来计算模型与日志的偏差。
技术实现要素:
为解决上述问题,本发明将事件涉及到的多个属性综合加以考虑,提供了一种基于事件相似度的事件日志与过程模型校准方法,能更好地反映事件日志与过程模型间的符合性。
本发明采用的技术方案为:一种基于事件相似度的事件日志与过程模型校准方法,包括以下步骤:
首先,对事件概念进行定义,其中包括过程模型、事件的迹、事件日志以及活动映射;
其次,基于本体树计算两事件各个属性之间的相似度;具体计算过程为:
步骤1.输入迹中的事件eσ和过程模型中的事件en,两事件的活动属性需相同;
步骤2.将两事件用其功能语义fs(eσ)和fs(en)的形式表示,然后将其功能语义中的各个属性分别在本体树上进行标注并计算其相似度;
步骤3.根据两事件各属性的相似度进一步计算两事件的相似度;
最后,基于事件的相似度对事件日志中的迹和模型进行校准;具体计算过程如下:
步骤1.参照标准似然函数,定义相似度似然函数及其代价值;
步骤2.基于相似度似然函数,定义校准的代价值cost(γ);
步骤3.将事件的迹σ转换为事件网,计算过程模型和事件网中具有相同活动属性的事件的同步移动相似度,并构造事件网与过程模型的积网;
步骤4.求出积网中从开始状态到终结状态的不同路径,并将积网中的变迁映射为校准中的移动;
步骤5.根据相似度似然函数下校准代价值的定义,代价值最小的路径即为最优校准γ。
第一步中的定义如下:
定义1.过程模型:将过程模型表示为一个二元组(pn,attr),其中,pn=(p,t;f,m),为一个petri网,其中,p是一个库所集合,t是一个变迁集合,
定义2.事件的迹:当一个事件具有多个属性时,迹表示为一个事件的有限序列,即<(e1,#res(e1)[:value]),…,(en,#res(en)[:value])>,事件日志是迹的多重集;
定义3.活动映射:将具有多个属性的事件用它的活动属性来表示的方法,称为活动映射,记作↓act。
在领域专家参与下参照wordnet和hownet构造本体树,对构造本体树时用到的概念进行定义:
定义4.事件e的功能语义
将事件e的功能语义描述为一个多元组:fs(e)=<activity,resource,[option],constraint>,其中:
activity={c|c∈ca}表示事件e所对应的活动,其中ca表示某领域描述活动的概念集合,记为#act(e);
resource={c|c∈cr}表示事件e所涉及到的资源,其中cr表示某领域描述资源的概念集合,记为#res(e);
option={c|c∈co}表示事件e所涉及到的其它属性,其中co表示某领域描述相应其它属性的概念集合;
constraint=q1∧q2∧…∧qn,表示发生某个事件时应满足的各属性约束条件,其中qi(i=1,2,…,n)表示事件某一属性的具体约束条件;约束条件q1,q2,…,qn之间定义为“并且”关系;
定义5.本体树
令o为领域d上的本体树,则有:
o=<({c},{r})|ci∈d,i=1,2,…,m;rj∈d,j=1,2,…,n>;
其中,c为概念集合,表示领域d上的相关概念,又可分为类别概念和特征概念、实例概念和要素概念;其中类别概念表征具有相同性质对象的集合;特征概念反映了概念c所具有的特征;实例概念表示了概念的相应实例;要素概念表征了概念的所组成要素;r是关系的集合,本体定义的关系有:is-a、instance-of、element-of和trait-of,其中,is-a表示概念间的继承关系,instance-of表示概念和概念具体实例之间的关系,part-of指概念与概念的组成要素之间的关系,trait-of表示概念和概念的特征之间的关系;
定义6.本体语义标注
将给定的概念k替换或部分替换为本体树中的概念的过程,称为概念的本体语义标注,记作remark(k);
定义7.事件的本体语义标注
将事件e的功能语义fs(e)进行本体标注实质上是将事件的各个属性在本体树中进行语义标注的过程;首先,在本体树中,将事件e涉及到的概念#attr(e)进行本体语义标注,若事件e的某个属性有具体的属性值,则根据所标注的trait-of给出其具体值。
基于事件属性在本体树上的标注求相似度的步骤为:
若en为模型中的一个事件,eσ是迹中的一个事件,且有en=eσ,将两事件表示为其功能语义fs(en)和fs(eσ)的形式,并将fs(en)和fs(eσ)中的每一属性在本体树上进行标注;若en和eσ某一属性在本体树中的标注分别表示为x和y,则概念对(x,y)之间的相似度sim(x,y)可分如下情况进行讨论:
(1)若不存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),则sim(x,y)=0;
(2)若存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),且
若y∈descendant(x)或y∈instance-of(x),则sim(x,y)=1;
若
(3)若存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),且
将限定x和y的每一个约束qi,映射为其特征trait-ofi(x)和trait-ofi(y):
(a)若
(b)若
(c)若
若y∈descendant(x)或y∈instance-of(x),则sim(qi(xi,yi))=1;
若
然后,sim(x,y)=average(sim(qi(xi,yi));
在以上计算过程中,函数kind表示事件属性所属种类;若有kind(x)=kind(y),且
参照标准似然函数,令日志移动、模型移动、弱同步移动和强同步移动的代价值cost分别记为(1,1,1,1-sim-event(eσ,en)),称其为相似度似然函数,其中,sim-event(eσ,en)表示事件对(eσ,en)之间的相似度,是上述所给出的事件各属性相似度的平均值;基于相似度似然函数,校准代价值cost(γ)为校准γ中包含的日志移动数、模型移动数、弱同步移动数与强同步移动数*(1-sim-event(eσ,en))之和。
本发明从具有多个属性的事件出发,研究过程模型与事件日志的校准问题。为确保日志与模型中事件描述的一致性,将事件及其属性用其功能语义表示,并在领域本体上加以标注。通过计算事件对之间多个属性的相似度,进而计算具有相同活动属性事件对之间的相似度。基于事件的相似度,给出过程模型与事件日志之间的校准算法。
通过本发明所述校准和简单校准的比较可知,简单校准反映的是偏差的质,而本发明所述的校准在质的基础上反映了偏差的量。因此,本发明所述的校准对校准的描述更加细致,可为改进模型或发现日志中的问题提供更详细的依据。
附图说明
图1是用petri网描述的一个培训课程的过程模型n1;
图2是教学领域的部分功能本体示意图;
图3是实施例所述过程模型示意图;
图4是实施例所述事件网示意图;
图5是实施例所述过程模型与事件网的积网示意图;
图6是简单校准和本发明所述的最优校准比较,其中(a)是简单最优校准,(b)是本发明所述的最优校准;
图7是简单校准和本发明所述校准的结构比较,其中(a)是简单校准的结构图,(b)是本发明所述校准的结构图。
具体实施方式
下面结合附图和实施例对本发明进行详细说明。
基于事件相似度的事件日志与过程模型校准方法,包括以下步骤:
首先,对事件校准过程中涉及的概念进行定义和解释。
定义1.过程模型
将过程模型表示为一个二元组(pn,attr),其中,
(1)pn=(p,t;f,m),为一个petri网,其中,p是一个库所集合,t是一个变迁集合,
(2)attr是一个标签函数,且有attr:t→ξ∪τ,其中,ξ是所有可能发生的事件集合,τ为空事件。标签函数attr将petri网中的每一个变迁映射为事件集ξ或空事件τ中的元素。事件e是ξ中的一个元素,表示为(e,#res(e)[:value]),其中,e为事件分类器,用事件的活动名字来表示,#res(e)[:value]表示e的相应属性及属性值,其中[:value]表示属性值为可选项。
定义2.事件的迹
当一个事件具有多个属性时,迹表示为一个事件的有限序列,即<(e1,#res(e1)[:value]),…,(en,#res(en)[:value])>。事件日志是迹的多重集。
定义3.活动映射
将具有多个属性的事件用它的活动属性来表示的方法,称为活动映射,记作↓act。类似地,活动映射可将事件的迹映射为其相对应的简单迹,也将事件日志映射称为其相对应的简单事件日志,还将过程模型映射为一个简单过程模型。
如无特殊说明,本发明中的事件均指有多个属性的事件。由此,过程模型指的是多属性事件模型,迹指多属性事件的迹,事件日志指多属性事件日志。而将事件中只有活动属性的模型、事件日志、迹和校准分别称为简单模型、简单事件日志、简单迹和简单校准。
下面通过一个实例来说明过程模型和事件的迹等概念。
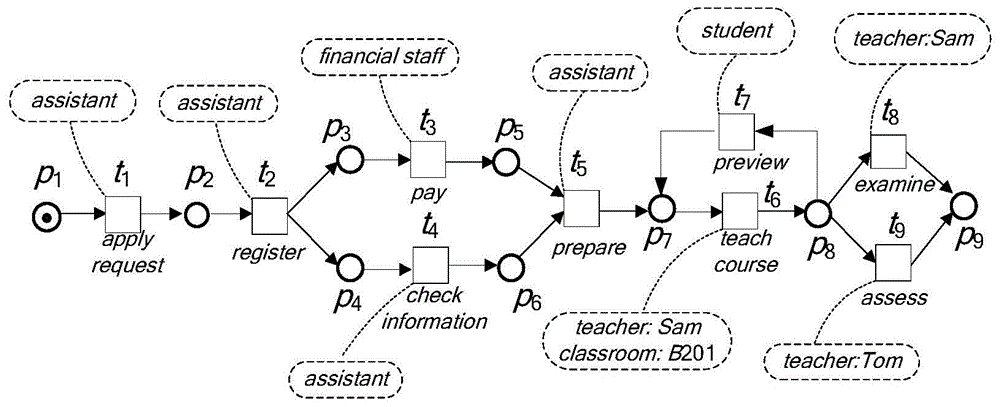
图1用petri网描述了一个培训课程的过程模型n1。其主要活动列举如下:①学员向助理(assistant)咨询相关情况并提交申请(applyrequest);②注册个人信息(register);③助理核实学员个人信息(checkinformation);④学员支付培训费用(payfinancialstaff);⑤助理(assistants)准备相关课程资料(prepare);⑥sam(teacher)在教室b201开展培训;⑦学员预习下一节课程(preview);⑧对培训结果进行考核(examine)或考查(assess)。事件除活动外的属性及属性值在图中用虚框表示,是对事件的限制。在图1中的各个事件,包括活动、资源resource和地点place等属性。
若有迹σ1和σ2,其中σ1=<(applyrequest,assistant:cindy),(register,assistant:jack),(pay,financialstaff),(prepare,assistant),(teachcourse,teacher:sam,classroom:b201),(preview,student),(teachcourse,teacher:sam,classroom:b201),(examine,teacher:sam)>。而迹σ2除teachcourse发生在b202外,其他的与迹σ1相同。
对迹σ1和σ2进行活动映射,得到σ1↓act=σ2↓act=<applyrequest,register,pay,prepare,teachcourse,preview,teachcourse,examine>。即σ1和σ2在n1的简单模型上等价,且与模型的fitness度(适应度)均为1。但考虑到事件的多个属性时,将迹σ2在n1上进行重演,则其fitness度小于1。
其次,基于本体树计算两事件各属性之间的相似度。
属性之间的相似度可利用本体树进行计算。而当前的本体树尚不够完善,故利用wordnet和hownet等以词法所代表的概念为描述对象,以揭示了不同概念之间以及概念属性关系之间关系的词汇语义网,来进行属性的相似度计算。在语义网中,根据需要校准的具体模型和具体事件日志选择其表示的关系。
参照wordnet的构造方法以及语义在服务组合中的应用,可以认为一个过程模型是面向特定领域实现一系列功能的程序。每一项功能可以由一个事件来完成,而一个事件又可由多个属性来表示。此处定义事件的功能语义描述,描述中体现了事件的常用属性,如活动属性和资源属性,其它属性作为可选项。
定义4.事件e的功能语义
事件e的功能语义可以描述为一个多元组:fs(e)=<activity,resource,[option],constraint>,其中:
activity={c|c∈ca}表示事件e所对应的活动,其中ca表示某领域描述活动的概念集合,如teach、exam、assess等,记为#act(e)。
resource={c|c∈cr}表示事件e所涉及到的资源,包含活动发起的主体、事件作用的客体等,其中cr表示某领域描述资源的概念集合,如teacher、student、assistant等,记为#res(e)。
option={c|c∈co}表示事件e所涉及到的其它属性,如地点、时间等,其中co表示某领域描述相应其它属性的概念集合,涉及地点的概念如lab、classroom;涉及时间的概念如year、time等。[option]表示这一项在事件e的功能语义中是可选项。
对于事件的所有属性,定义函数kind来表示事件属性所属种类。如kind(#res(e))=res。
constraint=q1∧q2∧…∧qn,表示发生某个事件时应满足的各属性约束条件,其中qi(i=1,2,…,n,)表示事件发生某一属性的具体约束条件。将不同属性的约束条件之间定义为“并且”关系。如(capacity>50)∧(multi-media=true)为地点选择的两个条件,capacity>50表示其容纳人数应大于50,multi-media=true表示此处应有多媒体设备。
由上可知,事件功能语义描述为一个多元组,多元组的核心是活动activity,资源resource是活动作用的主体或客体,option表示事件的其它属性,constraint是对事件属性进行的限定和规范。
为保证迹和模型校准时采用相同的描述方式,建立领域本体树,将事件的功能描述映射到本体树中。本体树的建立一方面可避免引起语义冲突,另一方面用做事件相似度的计算。
定义5.本体树
令o为领域d上的本体树,则有:
o=<({c},{r})|ci∈d,i=1,2,…,m;rj∈d,j=1,2,…,n>,
其中,c为概念集合,表示领域d上的相关概念,又可分为类别概念和特征概念、实例概念和要素概念。其中类别概念表征具有相同性质对象的集合,如teacher、place、classroom等;特征概念反映了概念c所具有的特征,如classroom的特征有capacity(容纳人数);实例概念表示了概念的相应实例;要素概念表征了概念的所组成要素。
r是关系的集合。在这里,本体定义的关系有:is-a、instance-of、element-of以及trait-of。其中,is-a表示概念间的继承关系,instance-of表示概念和概念具体实例之间的关系,part-of指概念与概念的组成要素之间的关系,trait-of表示概念和概念的特征之间的关系。图2表示了为教学领域的部分功能本体树。
定义6本体语义标注
将给定的概念k替换或部分替换为领域功能本体树中概念的过程,称为概念的本体语义标注,记作remark(k)。
定义7事件的本体语义标注
将事件e的功能语义fs(e)进行本体标注实质上是将事件的各个属性在本体树中进行语义标注的过程。首先,在某领域的本体树中,将事件e涉及到的概念#attr(e)进行本体语义标注remark(#attr(e))。若事件e的某个属性有属性值value(#attr(e)),则根据remark(#attr(e))的trait-of属性给出value(#attr(e))的具体值。如在图1中,过程模型n1的变迁t6所表示的事件e,其#act(e)为teachcourse,#res1(e)为classroom,其值限定为b201。故事件e的功能语义可描述为fs(e)=<teachcourse,classroom,classroom=b201>。根据图2所示的本体树,有remark(classroom)=classroom,b201为classroom的限定值,而classroom有trait-of为capacity和multi-media,则可求得capacity(b201)和multi-media(b201)。
类似地,可将迹中各事件的属性在本体树上加以标注。如迹中存在事件e,其#act(e)为teachcourse,#res1(e)为classroom,其值为b202。故可知,remark(classroom)=classroom,然后求得capacity(b202)和multi-media(b202)。
事件属性在本体树中的语义标注,特别是涉及到属性具体值时,需要人工标注。因此,事件各个属性的语义标注是半自动完成的。同时,各领域的本体树可在领域专家参与下参照wordnet和hownet进行构造。
基于本体树计算事件相似度的过程如下:
对过程模型与迹中事件的相似度计算可转换为事件多个属性之间相似度的计算。可基于本体树进行属性的相似度计算。具体步骤如下:
步骤1、输入迹中的事件eσ和模型中的事件en,两事件的活动属性需相同。
步骤2、分别将两事件eσ和en表示为其功能语义的形式fs(eσ)和fs(en),将功能语义fs(eσ)和fs(en)的各个属性在本体树上进行标注。
步骤3、计算两事件中每一对属性在本体树上的相似度,记录下各属性的种类及各属性相应的相似度,然后以其平均值作为两事件的相似度sim-event(eσ,en)。
下面以模型中事件en、迹中事件eσ(两事件活动属性相同,即en=eσ)为例,分类说明相似度的计算规则:
将两事件的每个属性(也是在功能语义中的属性)在本体树上进行标注并分别表示为(x,y),其中的x和y根据其本体树的特点,可允许有traitof等特征。对概念对(x,y),其相似度sim(x,y)可分如下情况进行讨论:
(1)若不存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),则sim(x,y)=0;
(2)若存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),且
若y∈descendant(x)或y∈instance-of(x),则sim(x,y)=1;
若
(3)若存在y∈(cr(eσ)∪co(eσ)),使得kind(x)=kind(y),且
将限定x和y的每一个约束qi,映射为其特征trait-ofi(x)和trait-ofi(y):
(a)若
(b)若
(c)若
若y∈descendant(x)或y∈instance-of(x),则sim(qi(xi,yi))=1;
若
然后,sim(x,y)=average(sim(qi(xi,yi));
在以上计算过程中,函数kind表示事件属性所属种类;若有kind(x)=kind(y),且
在以上事件的属性概念对(x,y)的相似度计算中,(1)指迹的事件eσ中不存在和模型的事件en中的属性x相对应的概念y,如x中有resource,而y中没有,此时sim(x,y)为0;(2)指当(x,y)为相同的概念对,且约束条件中没有对x的限定,若y是x的子孙结点或是x的实例,则认为概念y符合x,其相似度为1;(如两属性同为概念resource,x在语义树上对应概念place且无具体约束,而y属于classroom或place的具体实例);如果y不是x的子孙结点或实例,则以x,y在语义树上的距离表示其相似度;(如x对应概念lab,而y对应classroom);(3)如果y中存在和x同类的概念,且有对x的限定约束,则将其每一个约束qi映射为其特征trait-ofi(x)和trait-ofi(y)。若对y的约束为空,则在此约束qi上,sim(qi(xi,yi))为dis(x,y);若对y的约束不为空,则比较trait-ofi(y)与trait-ofi(x)。若trait-ofi(y)不满足trait-ofi(x),则sim(qi(xi,yi))=0;若trait-ofi(y)满足trait-ofi(x),若y是x的子孙结点或实例时,则(x,y)在约束qi上的相似度sim(qi(xi,yi))为1,若y不是x的子孙结点或实例,则(x,y)在约束qi上的相似度sim(qi(xi,yi))为dis(x,y)。例如,假设对x的约束条件为classroom=b201,则将其映射trait-of(classroom)为capacity(b201);若对y的约束为空,此时在此约束下,(x,y)的相似度为两者在本体中的距离dis(x,y);假设对y的约束为lab=c305,则将其映射为capacity(c305),然后比较capacity(b201)与capacity(c305)。若capacity(c305)不满足capacity(b201),则在此约束下,(x,y)的相似度为0;若capacity(c305)满足capacity(b201),因y为lab不是classroom的实例或子孙结点,则在此约束下,(x,y)的相似度为dis(x,y);若y是classroom的实例或子孙结点,则在此约束下,(x,y)的相似度为1。当对x存在多个约束时,(x,y)的相似度为每个约束下属性相似度的平均值。在sim(x,y)的计算中,dis(x,y)表示(x,y)在语义树中的距离。满足条件的界定,可根据具体概念的trait-of而定,一般理解为“优于”。如multi-media为true优于multi-media为false。
如图1所示的模型n1中,对变迁t6所对应的事件e,#act(e)=teachercourse,#resource(e)=teacher:sam,#place(e)=classroom:b201。与之相对应的迹中事件e′,#act(e′)=teachercourse,#resource(e′)=teacher:sam,#place(e′)=classroom:b202。由上述步骤可知,对resource属性,sim(x,y)=1,对place属性,#place(e)=#place(e′)=classroom为相同的概念,但对事件e,其约束为q(x)=b201,而对事件e′,其约束为b202,故此判断b202的各个trait-of是否满足b201的要求。假定capacity(b202)<capacity(b201),但multi-media(b201)=true,而multi-media(b202)=false,在约束#place(e)=classroom:b201下,其属性place的相似值为0.5。故两事件相似度计算结果为:sim-event(e,e′)=0.75,com_attr[0]={resource,1},com_attr[1]={place,0.5}。
下面基于事件之间的相似度,给出校准的相关定义。
定义8基于事件相似度的校准
对于事件的迹σ和模型n,基于事件相似度的校准γ是一系列移动的集合。校准使得第一个元素构成的系列为日志中的迹σ(除去>>),第二个元素构成的序列为模型n中变迁所对应事件的发生序列(除去>>)。其中,每一个有效移动是事件对(m,n):
(1)(m,n)称日志移动,如果m∈σ↓act且n=>>;
(2)(m,n)为模型移动,如果m=>>且n∈n↓act;
(3)(m,n)为弱同步移动,如果m∈σ↓act,n∈n↓act,m=n且有sim(m,n)<λ。
(4)(m,n)为强同步移动,如果m∈σ↓act,n∈n↓act,m=n且有sim(m,n)≥λ。
其中,λ是一个可调节的阈值,且0≤λ≤1。
定义9校准的代价值
参照标准似然函数,令日志移动、模型移动、弱同步移动和强同步移动的代价值cost分别记为(1,1,1,1-sim-event(eσ,en)),称其为相似度似然函数。其中,sim-event(eσ,en)表示事件对(eσ,en)之间的相似度。
基于相似度似然函数,一个校准γ的代价值cost(γ)为校准γ中包含的日志移动数、模型移动数、弱同步移动数与强同步移动数*(1-sim-event(eσ,en))之和。
定义10最优校准
令ψ(σ,n)表示迹σ和模型n基于相似度似然函数下的一个校准集合。若存在γ1∈ψ(σ,n),对
校准过程为:首先,将迹σ转换为其对应的事件网,对活动属性相同的事件计算其事件的相似度,并构造事件网与模型网的积网,将积网中的变迁映射为校准中的移动。其次,根据相似度似然函数下校准代价值的定义给出每一步移动的代价值,从积网的初始标识到结束标识有若干条路径,在这些路径中,代价值最小的最优路径对应着迹和模型的最优校准。
图3所示为用标签petri网表示的模型n2。图4所示为迹σ=<(a,resource1:x1),(b,resource2:m1,place1:y1),(c,place2:z1),(e,place3:k1)>所表示的事件网n2′。模型n2和事件网n2′的积网n″如图5所示。在图3和图4中,每一个变迁t的标签为一个事件e,事件e的活动属性e,如a,b,c等。在积网n″中,每一个同步移动均附有该移动中两事件的相似度以及事件的各个属性以及属性间的相似度。将积网中的变迁映射为校准中的移动,并根据相似度似然函数给出不同路径对应校准的代价值,其中代价值最小的路径即为最优校准。
下面就校准与简单校准进行比较。
在对事件相似性讨论的基础上,将基于事件日志l与模型n的校准和简单日志中的迹与简单模型的校准进行比较,可得出以下推论。对事件日志l中的任一条迹σ和模型n,其对应的简单迹与简单模型分别为σ↓act和n↓act。
推论1对事件日志l中的任一条迹σ和模型n,cost(ψ0(σ,n))≥cost(ψ0(σ↓act,n↓act))。
证明:令γ∈ψ0(σ,n),则cost(γ)为日志移动数、模型移动数、弱同步移动数和强同步移动*(1-sim-event(eσ,en))之和。而对γ′∈γ0(σ↓act,n↓act),cost(γ′)为γ中日志移动数与模型移动数之和。因为在两种校准中,关于日志移动和模型移动的定义是相同的,均为(迹中活动,>>)和(>>,模型中活动)。因为0≤sim-event(eσ,en)≤1,所以对模型n和日志l中的迹σ,有cost(γ)≥cost(γ′)。
推论1说明,若考虑到事件除活动以外的属性,事件日志中的迹与模型校准的代价值会增大,即迹和模型相符合的程度会下降。这是因为当考虑事件的多个属性时,此时的校准中存在着弱同步移动和强同步移动。即使移动中的活动相同,仍需要从其它属性的相似度进一步计算其代价值。这从另一个方面说明,简单校准判断的日志与模型偏差的“质”,而校准则在质的基础上,给出日志与模型偏差的“量”。
推论2对γ∈ψ0(σ,n),不一定有γ1∈γ0(σ↓act,n↓act)。其中,γ1里移动中的活动为γ中事件的活动映射。反之亦然。
证明:根据推论1,若γ∈ψ0(σ,n),则对
对其逆命题可类似地给出证明。
推论2说明,考虑到具有多属性事件之间的相似度,校准和简单校准不一定存在对应关系。
推论3对日志l中的迹σ1,若
证明:可与结论2类似地进行证明。
推论3说明,若迹有两个代价值相同的最优校准,则只有这两个最优校准中四种移动的个数分别相同时,它们的最优简单校准也有相同的代价值。但当迹有两个代价值相同的最优简单校准时,其最优校准的代价值未必相同。
如前推论2所述,迹和模型的最优简单校准与最优校准结果可能不一致,结合推论1,最优校准能够更准确地反映日志中的迹和模型的一致性程度。
若有过程模型n和它的事件日志l,其中,事件有活动属性和两种资源属性res1和res2,如教学过程模型的res1为teacher,res2为course。将n和l中的每个事件映射为其活动,得到其对应的简单过程模型n↓act和事件日志l↓act。
(1)事件日志中的最优迹与最优实例
图6(a)所示为简单过程模型n↓act与事件日志l↓act中每条迹的最优简单校准及其代价值。如图6(a)中所示,通过比较每个实例(case)迹的最优校准代价值,可得到事件日志中代价值最小的迹σi↓act,使得cost(γi)=min(cost(γj)),1≤j≤n。称迹σi↓act为l↓act上的最优迹,σi↓act所对应的实例casei为最优实例。
图6(b)所示为过程模型n与事件日志l中每条迹的多属性事件的最优校准及其代价值。与最优简单校准相类似,根据最优校准的代价值,可得到事件日志l中最优代价值最小的最优迹和其对应的最优实例。同时,可从res1和res2的角度进行评价,对涉及到res1的实例对应的事件日志记作l(res1),可得到l(res1)中的最优迹和最优实例。类似地,对事件日志l(res2),也可得到l(res2)中的最优迹和最优实例。
因此可知,与最优简单校准相比较,校准可以从更多的角度来评价事件日志中的迹和实例。
(2)简单校准与校准结构的比较
图7给出了简单校准与校准的结构示意图。在图7(a)中,简单校准中的每个移动是迹与模型中的事件对(除去>>)和代价值。在图7(b)所示的校准中,令其弱同步移动和强同步移动的代价值均为零,并“缩小”来看,即可得到其对应的简单校准。当“放大”多属性事件的校准时,则可进一步发现其同步移动相似度可能不为1的原因。因此,多属性事件的校准一方面从“质”上反映日志和模型偏差出现的位置及数量,另一方面也从“量”上更细致地反映偏差出现的位置及原因,如place不一致。因此,本发明所述的校准是简单校准的更细致表示,也为改进模型或发现日志中的问题提供更详细的依据。
- 还没有人留言评论。精彩留言会获得点赞!