基于类感知特征选择框架的文本分类方法和系统与流程
本发明涉及文本分类技术领域,尤其是一种基于类感知特征选择框架的文本分类方法和系统。
背景技术:
文本分类技术被广泛应用于信息检索、文本挖掘、舆情分析、垃圾邮件识别等实际应用场景中。大部分文本分类技术都是基于分类器实现的,用以训练分类器的训练集包含有多达数十万个的特征词,因此特征抽取是文本分类技术当中的重要环节。
特征抽取的目的是抽取出更能够识别簇类别能力的特征词,现有的特征抽取方法多从全局角度抽取能最佳识别簇类别能力的特征词。以信息增益为例,它的原理是计算每个特征词的信息增益值,信息增益值越大,说明该特征词更倾斜于某一个类别簇,即该词的类区分能力更高。全局特征抽取方法充分考虑到全局类区分能力,因此表现出良好的性能。然而,这种方法对不平衡数据集的区分效果并不好。这是因为,当数据集的类别个数较多且为不平衡数据时,传统特征抽取方法由于只考虑了全局类区分度最高的特征,导致对某些小样本类别簇抽取的特征稀疏,从而导致对小样本簇的分类正确率降低。同时,现有的文本分类方法所依赖的特征抽取方法只考虑特征词的类倾斜度而没有考虑特征词的类间区分能力,这种片面性使得现有文本分类方法的分类准确性受到限制。
技术实现要素:
为了解决上述技术问题,本发明的目在于提供一种文本分类方法及系统。
一方面,本发明实施例包括一种文本分类方法,包括以下步骤:
对多个类别簇进行预处理,得到特征词集合;所述类别簇包含多个同类别的词语,所述多个类别簇用于组成训练集,所述训练集用于对分类器进行训练;
分别计算特征词集合中的各特征词与各类别簇之间的类相关度分值和类区分度分值;
分别将特征词集合中的各特征词分配给具有相应最高类相关度分值的类别簇;
根据各类别簇与分配到的特征词之间的类区分度分值,分别对各类别簇内的词语进行重新排序;
从经过重新排序的各类别簇中分别选取特征子集;选取到的全部所述特征子集用于组成总特征集合;
根据各特征子集与各自相应的特征词之间的类相关度分值,对所述总特征集合内的各特征子集进行重新排序,从而得到最终特征集合;
将所述最终特征集合中的元素作为基底,对待分类文本进行向量表示;
将向量表示后的待分类文本输入到分类器中,输出分类结果。
进一步地,所述分类器为svm分类器、朴素贝叶斯分类器、k最近邻分类器或决策树分类器。
进一步地,所述类相关度分值的计算公式为:
进一步地,所述类区分度分值的计算公式为:
进一步地,所述从经过重新排序的各类别簇中分别选取特征子集这一步骤,所用的公式为:
进一步地,所述fj的大小与n(cj)成正比例关系。
另一方面,本发明实施例还包括一种文本分类系统,包括:
预处理模块,用于对多个类别簇进行预处理,得到特征词集合;所述类别簇包含多个同类别的词语,所述多个类别簇用于组成训练集,所述训练集用于对分类器进行训练;
分值计算模块,用于分别计算特征词集合中的各特征词与各类别簇之间的类相关度分值和类区分度分值;
特征词分配模块,用于分别将特征词集合中的各特征词分配给具有相应最高类相关度分值的类别簇;
第一重排序模块,用于根据各类别簇与分配到的特征词之间的类区分度分值,分别对各类别簇内的词语进行重新排序;
特征子集选取模块,用于从经过重新排序的各类别簇中分别选取特征子集;选取到的全部所述特征子集用于组成总特征集合;
第二重排序模块,用于根据各特征子集与各自相应的特征词之间的类相关度分值,对所述总特征集合内的各特征子集进行重新排序,从而得到最终特征集合;
向量表示模块,用于将所述最终特征集合中的元素作为基底,对待分类文本进行向量表示;
分类器模块,用于将向量表示后的待分类文本输入到分类器中,输出分类结果。
本发明的有益效果是:通过将各特征词分配给相应的类别簇,实现类感知功能;根据类区分度分值进行的排序和根据类相关度分值进行的排序,所得到的最终特征集合既考虑了不同类别簇各自的性质,也考虑了特征词的类内相关程度和类间区分程度。由于输入到分类器的数据是将待分类文本根据最终特征集合进行向量表示后的结果,分类器所处理的数据同时包含了不同类别簇各自的性质以及特征词的类内相关程度和类间区分程度等信息,克服了现有技术的片面性,能够达到更优的文本分类效果,尤其适用于不平衡数据集的分类效果。
附图说明
图1为本发明文本分类方法的实施例流程图。
具体实施方式
本实施例包括一种文本分类方法,参照图1,所述方法包括以下步骤:
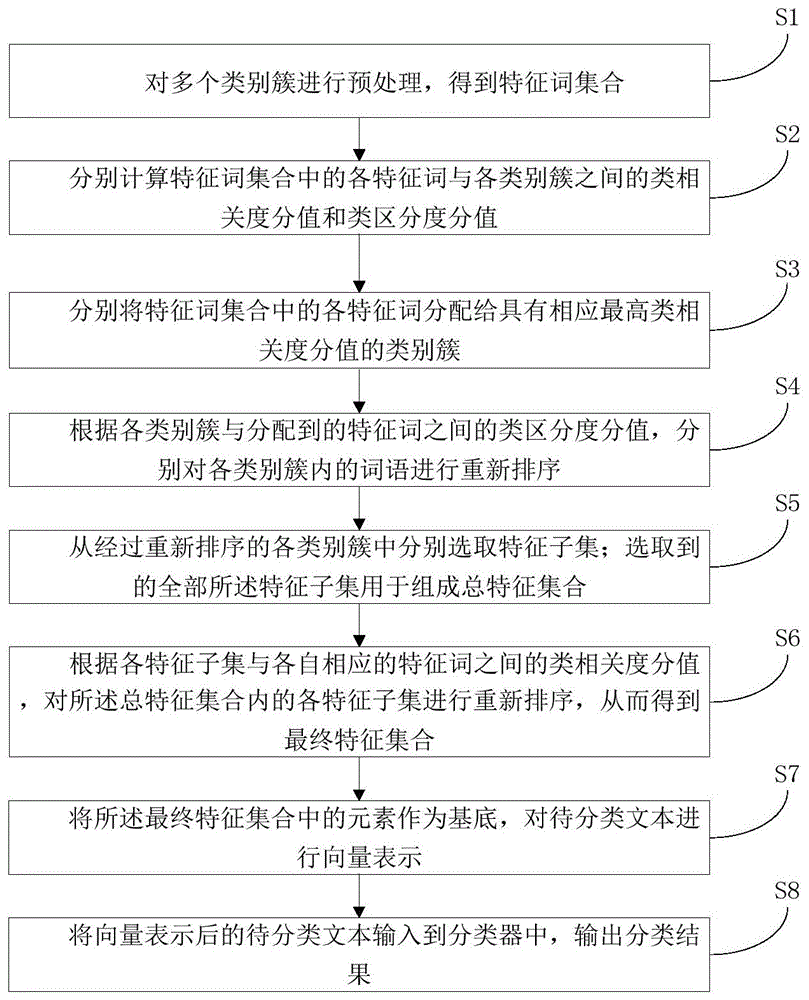
s1.对多个类别簇进行预处理,得到特征词集合;所述类别簇包含多个同类别的词语,所述多个类别簇用于组成训练集,所述训练集用于对分类器进行训练;
s2.分别计算特征词集合中的各特征词与各类别簇之间的类相关度分值和类区分度分值;
s3.分别将特征词集合中的各特征词分配给具有相应最高类相关度分值的类别簇;
s4.根据各类别簇与分配到的特征词之间的类区分度分值,分别对各类别簇内的词语进行重新排序;
s5.从经过重新排序的各类别簇中分别选取特征子集;选取到的全部所述特征子集用于组成总特征集合;
s6.根据各特征子集与各自相应的特征词之间的类相关度分值,对所述总特征集合内的各特征子集进行重新排序,从而得到最终特征集合;
s7.将所述最终特征集合中的元素作为基底,对待分类文本进行向量表示;
s8.将向量表示后的待分类文本输入到分类器中,输出分类结果。
本发明方法中,所用的分类器可以是svm分类器、朴素贝叶斯分类器、k最近邻分类器或决策树分类器中的任一种,优选地使用svm分类器作为本发明方法中的分类器。本发明方法所用的经过训练集的训练,本发明方法不对分类器本身的分类过程以及训练过程进行改进。本实施例中,所用的训练集包含多个类别簇,每个类别簇中包含多个同类别的词语或文本。对每个类别簇进行分词和去停用词等预处理,可以得到多个分别与每个类别簇对应的特征词集合。
本实施例中,将训练集记为c={c1,c2,...,cm},即训练集是由c1,c2,...,cm等m个类别簇组成的。本实施例中要对由d1,d2,...,dn等n个待分类文档组成的待分类文档集合进行分类。
通过步骤s1,对训练集c={c1,c2,...,cm}中的各类别簇进行预处理,得到由多个特征词t1,t2,...,tn组成的特征词集合t={t1,t2,...,tn}。
在步骤s2中,通过以下公式计算特征词集合中的各特征词与各类别簇之间的类相关度分值:
在步骤s2中,通过以下公式计算特征词集合中的各特征词与各类别簇之间的类相关度分值:
在步骤s3中,将特征词集合中的各特征词分配给具有相应最高类相关度分值的类别簇。本实施例中,针对特征词ti和各类别簇计算一系列类相关度分值:score1(ti,c1),score1(ti,c2),……,score1(ti,cm),其中若最大值为score1(ti,c5),则将ti分配给c5。
在步骤s4中,对各类别簇内的词语进行重新排序,具体方式可以是:针对各类别簇内的各个词语,参照步骤s2中的公式计算类区分度分值;对于某个类别簇,按照该类别簇内原有词语以及分配到的特征词的类区分度分值从大到小或从小到大的方式进行重新排序。
步骤s5中,从经过重新排序的各类别簇中分别选取部分或全部词语作为特征子集,即针对一个类别簇选取一个对应的特征子集。本实施例中,从类别簇cj选出的特征子集记为fj,它由多个类相关特征tj1,tj2,...,tjl组成,这些类相关特征tj1,tj2,...,tjl具有步骤s4所确定的顺序,每个类相关特征的标号jl表示从类别簇cj所选取的词语。其中标号l满足
进一步作为优选的实施方式,所述fj的大小与n(cj)成正比例关系,即在步骤s5中,从类别簇cj选出的特征子集fj所包含的词语数量与类别簇cj所包含的词语数量成正比例关系。总体来说,一个类别簇所包含的词语数量越多,从这个类别簇所选出的特征子集就越大。
本实施例中的步骤s1-s8的原理在于:通过步骤s3将各特征词分配给相应的类别簇,实现类感知功能;通过步骤s4中根据类区分度分值进行的排序和步骤s6中根据类相关度分值进行的排序,所得到的最终特征集合既考虑了不同类别簇各自的性质,也考虑了特征词的类内相关程度和类间区分程度。由于输入到分类器的数据是将待分类文本根据最终特征集合进行向量表示后的结果,分类器所处理的数据同时包含了不同类别簇各自的性质以及特征词的类内相关程度和类间区分程度等信息,克服了现有技术的片面性,能够达到更优的文本分类效果。
本实施例还包括一种文本分类系统,包括:
预处理模块,用于对多个类别簇进行预处理,得到特征词集合;所述类别簇包含多个同类别的词语,所述多个类别簇用于组成训练集,所述训练集用于对分类器进行训练;
分值计算模块,用于分别计算特征词集合中的各特征词与各类别簇之间的类相关度分值和类区分度分值;
特征词分配模块,用于分别将特征词集合中的各特征词分配给具有相应最高类相关度分值的类别簇;
第一重排序模块,用于根据各类别簇与分配到的特征词之间的类区分度分值,分别对各类别簇内的词语进行重新排序;
特征子集选取模块,用于从经过重新排序的各类别簇中分别选取特征子集;选取到的全部所述特征子集用于组成总特征集合;
第二重排序模块,用于根据各特征子集与各自相应的特征词之间的类相关度分值,对所述总特征集合内的各特征子集进行重新排序,从而得到最终特征集合;
向量表示模块,用于将所述最终特征集合中的元素作为基底,对待分类文本进行向量表示;
分类器模块,用于将向量表示后的待分类文本输入到分类器中,输出分类结果。
所述各模块可以是具有相应功能的硬件模块,也可以是计算中运行的具有相应功能的软件模块。
以下提供一个更为具体的实施例,该实施例使用本发明的方法、系统实现,从而通过定量的数据来展示本发明的有益效果。
为了测试所提出的基于类感知特征选择框架的文本分类算法,分别选取了经典中文文本数据集和英文文本数据集进行测试,并分别使用支持向量机、朴素贝叶斯、k最近邻和决策树分类器对本发明提出的类感知特征选择框架cafss以及两个经典优秀的传统特征抽取方法信息增益(ig)和卡方统计(chi)进行比较。
支持向量机分类器采用的是libsvm库方法(alibraryforsupportvectormachines)的weka接口。贝叶斯分类器分为基于伯努利模型的朴素贝叶斯分类器和基于多项式模型的多项式朴素贝叶斯分类器,k最近邻分类器采用的是weka包中的ibk分类器,在k最近邻分类器中,所有测试数据k值均取10。决策树分类器采用的是weka包中的j48分类器。
本实施例中所有文本数据均采用向量空间模型表示,每个文本的向量权重采用tfidf特征权重来计算,tfidf的权重计算方法为:
其中n表示训练集中总的文档个数,tf(ti,dj)表示特征ti在文档dj中的词频,df(ti)表示训练集中包含特征ti的文档个数,数据集的所有权重进行了规范化处理。分类结果采用标准分类精度、分类召回率以及分类f1度量值来对结果进行评价,计算公式如下所示:
其中,
本实施例分别选取搜狐研发中心提供的搜狗中文文本分类数据集和复旦中文文本分类数据集进行测试。其中搜狗数据集分别由it、体育、健康、军事、招聘、教育、文化、旅游、财经等9个类别的文本组成,且每个类别均包含了1990个文本,本实施例中随机对数据集抽取90%作为训练集,10%作为测试集,训练集文本总数为16,119,训练集中平均文档长度为252个单词,特征词个数为155,345。复旦大学中文文本分类数据集则包含了art、education、philosophy、history等共20个类别的文本组成,本实施例中按照原始数据集给定的1∶1得到训练集和测试集,其中训练集文档个数为9804,训练集中平均文档长度为559个单词,特征词个数为335,664个。为了测试多类别数据集和少类别数据集的差异,本实施例还抽取了it、军事和财经三个子集作为搜狗少类别数据集进行测试对比,同时还抽取了复旦大学20个类别中的art、history、space、computer、environment、agriculture、economy、politics、sports大小为466~1600之间的9个大类组成复旦9个大类数据集作为对比试验,本实施例中所有结果均为文本向量取100维时的结果。
表1为不同特征抽取算法在两个中文搜狗数据集上的不同分类结果对比。从本实施例结果可以看出,本实施例所提出的基于类感知特征选择框架的文本分类方法无论在9个类别还是3个类别搜狗文本数据集上,均获得比传统优秀特征抽取方法较好的分类性能。本实施例的模拟结果中,信息增益特征抽取方法和卡方统计特征抽取方法在不同的分类方法下结果有优有劣,例如在搜狗9个类别数据集中,信息增益方法在svm分类方法、naivebayesmultinomial和naivebayes上表现优于卡法统计方法,而卡方统计方法在knn、c4.5分类方法上优于信息增益方法。但是,本实施例所提出的类感知特征选择方法则在搜狗两个数据集的五个分类方法上均表现出最优的分类性能,这一结果表明,本实施例提出的两步特征提取方法能比传统的方法选取更好的分类特征。
表1
表2为不同特征抽取策略在复旦文本数据集上的分类结果对比。从本实施例结果可以看出,本实施例所提出的类感知特征抽取框架的文本分类方法在复旦20个类别文本数据集上所获得的分类结果提升明显。例如在svm分类方法上,本实施例方法比传统ig方法和chi方法的分类f1度量值分别提高5.243和2.957个百分点。在naivebayesmultimormal分类方法上,cafss方法比ig和chi方法的分类f1度量值分别提高8.387和4.868个百分点,在复旦9个大类数据集上,svm分类结果在cafss方法上比ig和chi方法上分类f1度量值分别提高6.35和3.76个百分点,naivebayesmultinomial分类结果在tsfs方法上比ig和chi方法上分类f1度量值分别提高10.382和7.095个百分点,这一结果再一次证明本实施例方法的合理性。
表2
本实施例依据传统文本特征选择方法存在的问题,提出了一种新的类感知特征选择框架。在多类别数据集或不平衡数据集中,由于每个类别具有很大的差异:如有大类别(即该类别的样本个数很多)和小类别(即该类别的样本个数很少)的差异;有些类别中的文本特征词显著,并具有较少的噪音文本,而有些类别中的噪音文本多,并且特征词稀疏等。基于此,本实施例提出一种基于类感知特征选择框架的文本分类方法。将本发明方法应用在中文文本分类数据集上的结果表明,本发明所提出的方法比优秀传统特征抽取方法具有对数据集适应性更强,并在不平衡数据集和多类别数据集上取得更优的分类性能。
以上是对本发明的较佳实施进行了具体说明,但对本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!